Storm实践(一):基础知识
storm简介
Storm是一个分布式实时流式计算平台,支持水平扩展,通过追加机器就能提供并发数进而提高处理能力;同时具备自动容错机制,能自动处理进程、机器、网络等异常。
它可以很方便地对流式数据进行实时处理和分析,能运用在实时分析、在线数据挖掘、持续计算以及分布式 RPC 等场景下。Storm 的实时性可以使得数据从收集到处理展示在秒级别内完成,从而为业务方决策提供实时的数据支持。
storm vs spark streaming
storm适用场景
- 需要纯实时,不能忍受1秒以上延迟的场景下使用,比如金融系统
- 对于延迟需求很高的纯粹的流处理工作负载
- 需求主要集中在流处理与CEP(即复杂事件处理)式处理层面
- 若还需要针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),也可以考虑用Storm
- 如果一个大数据应用系统,它就是纯粹的实时计算,不需要在中间执行SQL交互式查询、复杂的transformation算子等,那么用Storm是比较好的选择
spark streaming适用场景
- 如果对上述适用于Storm的几点,一条都不满足的实时场景,即:不要求纯实时,不要求动态调整并行度等,那么可以考虑使用Spark Streaming
- 考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即:如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性 Spark Streaming与Storm的优劣分析事实上,Spark Streaming绝对谈不上比Storm优秀。
- 必须利用交互式shell通过API调用实现数据探索
技术特点对比
| 对比项 | storm | spark |
|---|---|---|
| 处理方式 | 流式数据处理、移动数据(数据流入计算节点) | 批处理数据、移动计算(针对数据形成任务进行计算) |
| 延迟性 | >=100ms | 2s左右 |
| 吞吐量 | Low | High |
| 容错性 | ack组件进行数据流的跟踪,开销大 | 通过lineage以及在内存维护两份数据备份进行容错 |
| 事务性 | 通过跟踪机制能保证每个记录至少被处理一次,如果需要保证状态只更新一次的话,需要由用户自己来实现。 | 保证数据只被处理一次,并且是在批处理的层次级别。对于statefull的计算,对事务性比较高的话,Spark streaming要更好一些。 |
| 动态调整并行度 | 支持 | 不支持 |
| 数据处理保证 | at least once(实现采用record-level acknowledgments),Trident可以支持storm 提供exactly once语义。 | exactly once(实现采用Chandy-Lamport 算法,即marker-checkpoint ) |
如果对延迟要求不高的情况下,建议使用Spark Streaming,丰富的高级API,使用简单,天然对接Spark生态栈中的其他组件,吞吐量大,部署简单,UI界面也做的更加智能,社区活跃度较高,有问题响应速度也是比较快的,比较适合做流式的ETL,而且Spark的发展势头也是有目共睹的,相信未来性能和功能将会更加完善。
storm基本概念
storm做使用过程中,虽然定义了一些基本概念,其实只定义了一些接口,让大家去实现即可。spark streaming相当于是定义了一些数据结构,需要大家灵活掌握和使用,入门难度相对比较大。
tuple元组
tuple是storm的主要数据结构,并且是storm中使用的最基本单元、数据模型和元组
tuple描述
tuple就是一个值列表,tuple中的值可以是任何类型的,动态类型的tuple的fields可以不用声明,默认情况下,storm中的tuple支持私有类型、字符串、字节数组等作为它的字段值,如果使用其他类型,就需要序列化该类型。
tuple的字段默认类型有:integer、float、double、long、short、string、byte、binary
tuple可以理解成键值对,例如、创建一个bolt要发送2个字段(命名为double和triple),其中键就是定义declareOutputFields方法中的fields对象,值就是在emit方法中发送的values对象。
spout:接收数据的入口
- 继承BaseRichSpout(无多余代码,推荐)/实现IRichSpout接口
- open(Map conf, TopologyContext context, SpoutOutputCollector collector):初始化
- nextTuple():通过output collector发射emit元组tuples.它不能阻塞,当没有数据发送时,spout将sleep休眠短暂的时间。
- declareOutputFields():声明传递的数据字段名称。
//demo
public class AccessPointSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void nextTuple() {
String message = "Test Message!";
collector.emit(new Values(message));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("message"));
}
}
发送消息用的emit()在这里提供了四种不同的实现方式,但是要注意的是,只有提供了messageId参数,Storm才会追踪这条消息是否发送成功。
发射tuple时,如果spout提供一个message-id,则通过这个id来追踪该tuple
接下来,storm跟踪该tuple的树形结构是否成功创建,并根据messageid调用spout中的ack函数,以确认tuple是否被完全处理,如果tuple超时,则调用spout的fail方法。
bolt
bolt是数据数据的最小单元。
- Bolts的主要方法是execute,它以一个tuple作为输入,bolts使用OutputCollector来发射tuple,bolts必须要为它处理的每一个tuple调用OutputCollector的ack方法,以通知Storm这个tuple被处理完成了,从而通知这个tuple的发射者spouts。
- 一般处理流程:接收数据tuple-->处理数据-->发射数据(可选),处理完成后要发送ack通知storm.
通常情况下,实现一个Bolt,可以实现IRichBolt接口或继承BaseRichBolt,如果不想自己处理结果反馈,可以实现IBasicBolt接口或继承BaseBasicBolt,它实际上相当于自动做掉了prepare方法和collector.emit.ack(inputTuple);
topology
Storm中的拓扑,实际上就是一个有向图的计算。拓扑中节点包含数据的逻辑处理;节点之间的边显示数据如何在节点直接流动。简单拓扑图如下所示:
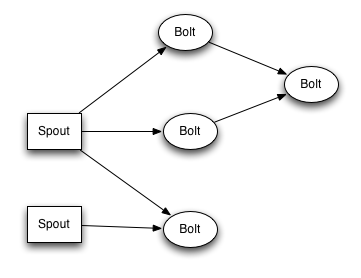
复杂拓扑:
Understanding the Parallelism of a Storm Topology
理解 Storm 拓扑的并行度(parallelism)概念
在一个 Storm 集群中,Storm 主要通过以下三个部件来运行拓扑:
- 工作进程(worker processes)
- 执行器(executors)
- 任务(tasks)
它们关系如下图所示:

在 Worker 中运行的是拓扑的一个子集。一个 worker 进程是从属于某一个特定的拓扑的,在 worker 进程中会运行一个或者多个与拓扑中的组件相关联的 executor。一个运行中的拓扑就是由这些运行于 Storm 集群中的很多机器上的进程组成的。
一个 executor 是由 worker 进程生成的一个线程。在 executor 中可能会有一个或者多个 task,这些 task 都是为同一个组件(spout 或者 bolt)服务的。
task 是实际执行数据处理的最小工作单元(注意,task 并不是线程) —— 在你的代码中实现的每个 spout 或者 bolt 都会在集群中运行很多个 task。在拓扑的整个生命周期中每个组件的 task 数量都是保持不变的,不过每个组件的 executor 数量却是有可能会随着时间变化。在默认情况下 task 的数量是和 executor 的数量一样的,也就是说,默认情况下 Storm 会在每个线程上运行一个 task。
拓扑示例
Config conf = new Config();
conf.setNumWorkers(2); // use two worker processes
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); // set parallelism hint to 2
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout");
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)
.shuffleGrouping("green-bolt");
StormSubmitter.submitTopology(
"mytopology",
conf,
topologyBuilder.createTopology()
);
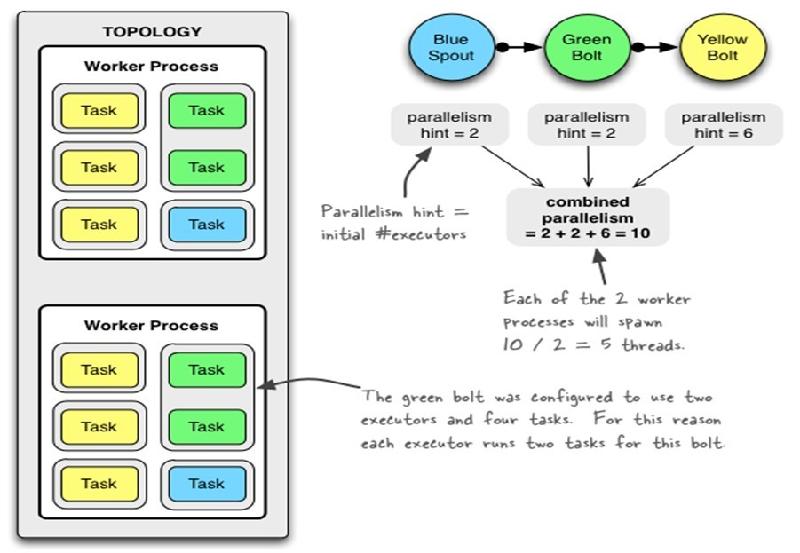
图中是一个包含有两个 worker 进程的拓扑。其中,蓝色的 BlueSpout 有两个 executor,每个 executor 中有一个 task,并行度为 2;绿色的 GreenBolt 有两个 executor,每个 executor 有两个 task,并行度也为2;而黄色的YellowBolt 有 6 个 executor,每个 executor 中有一个 task,并行度为 6,因此,这个拓扑的总并行度就是 2 + 2 + 6 = 10。具体分配到每个 worker 就有 10 / 2 = 5 个 executor。
它们之间的关系如下所示:
- Topology----(N)--work processes----(N)--executors(threads)----(N)--tasks(default one task per executor,也可以一个executor跑多个task,task对应spout、Bolt)
总并行度等于总executors
emit中的几个ID
//tuple是必传,其他可以为空
public List<Integer> emit(String streamId, List<Object> tuple, Object messageId) {
return _delegate.emit(streamId, tuple, messageId);
}
- componentId:spout.bolt(setspout()、setBolt()) ----名称
- tuple: streamId:一般省略 (每个消息流在定义的时候会被分配给一个id,因为单向消息流使用的相当普遍, OutputFieldsDeclarer定义了一些方法让你可以定义一个stream而不用指定这个id。在这种情况下这个stream会分配个值为‘default’默认的id )
- messageId:emit() 作用:如果指定了,则是可靠的spout,tuple被处理完后会调用ack or fail。
_collector.emit(new Values(sentence), sentence);
_collector.emit(new Values(sentence)),则后面需要
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
Stream Grouping
Part of defining a topology is specifying for each bolt which streams it should receive as input. A stream grouping defines how that stream should be partitioned among the bolt's tasks.拓扑中规定了Bolt接收哪个流作为输入数据。流分组定义做bolt中如何对流分组。真实的流分组情况如下所示:
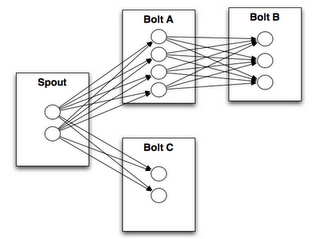
- Shuffle grouping: Tuples are randomly distributed across the bolt's tasks in a way such that each bolt is guaranteed to get an equal number of tuples.
- Fields grouping: The stream is partitioned by the fields specified in the grouping. For example, if the stream is grouped by the "user-id" field, tuples with the same "user-id" will always go to the same task, but tuples with different "user-id"'s may go to different tasks.
- Partial Key grouping: The stream is partitioned by the fields specified in the grouping, like the Fields grouping, but are load balanced between two downstream bolts, which provides better utilization of resources when the incoming data is skewed. This paper provides a good explanation of how it works and the advantages it provides.
- All grouping: The stream is replicated across all the bolt's tasks. Use this grouping with care.
- Global grouping: The entire stream goes to a single one of the bolt's tasks. Specifically, it goes to the task with the lowest id.
- None grouping: This grouping specifies that you don't care how the stream is grouped. Currently, none groupings are equivalent to shuffle groupings. Eventually though, Storm will push down bolts with none groupings to execute in the same thread as the bolt or spout they subscribe from (when possible).
- Direct grouping: This is a special kind of grouping. A stream grouped this way means that the producer of the tuple decides which task of the consumer will receive this tuple. Direct groupings can only be declared on streams that have been declared as direct streams. Tuples emitted to a direct stream must be emitted using one of the [emitDirect](javadocs/org/apache/storm/task/OutputCollector.html#emitDirect(int, int, java.util.List) methods. A bolt can get the task ids of its consumers by either using the provided TopologyContext or by keeping track of the output of the emit method in OutputCollector (which returns the task ids that the tuple was sent to).
- Local or shuffle grouping: If the target bolt has one or more tasks in the same worker process, tuples will be shuffled to just those in-process tasks. Otherwise, this acts like a normal shuffle grouping.
Storm里面有8种类型的stream grouping:
- Shuffle Grouping: 随机分组, 随机派发stream里面的tuple, 保证每个bolt接收到的tuple数目相同。
- Fields Grouping:按字段分组, 比如按userid来分组, 具有同样userid的tuple会被分到相同的Bolts, 而不同的userid则会被分配到不同的Bolts。
- Partial Key grouping:The stream is partitioned by the fields specified in the grouping, like the Fields grouping, but are load balanced between two downstream bolts, which provides better utilization of resources when the incoming data is skewed. This paper provides a good explanation of how it works and the advantages it provides.它是部分按字段分组,和按字段分组类似,但是能负载均衡到多个bolts.当输入数据倾斜,资源利用率更好。
- All Grouping: 广播发送, 对于每一个tuple, 所有的Bolts都会收到。
- Global Grouping: 全局分组, 这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
- Non Grouping: 不分组, 这个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。
- Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者决定由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来或者处理它的消息的taskid (OutputCollector.emit方法也会返回taskid)
- Direct Grouping: 直接分组, 这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
- Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
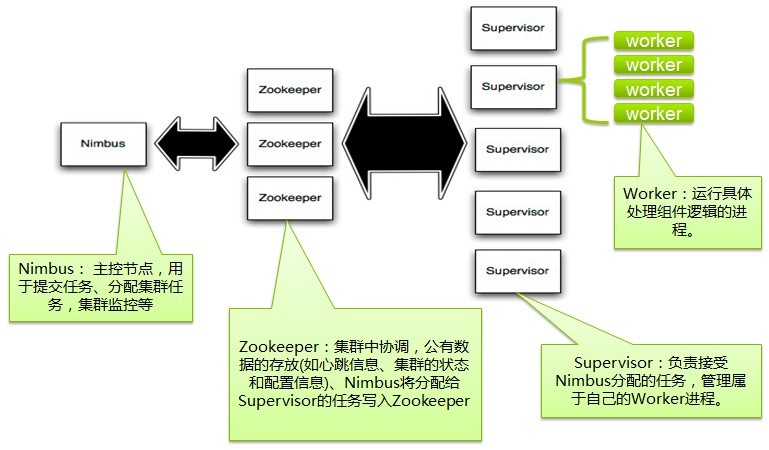
storm集群的组件
storm代码如何打jar包
这里不能像MR一样,将需要jar包放在jar包lib目录下。
本人尝试了4种方式:
- 把jar放入~/.storm. The storm jars and configs in ~/.storm are put on the classpath. ----此种方式不行
- fatjar,要指定mainclass
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<!--<mainClass>com.ziyun.storm.accesspoint.AccessPointTopo</mainClass>-->
<mainClass />
<!--<mainClass>com.ziyun.mq.demo.Publisher</mainClass>-->
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<finalName>${project.artifactId}-${project.version}</finalName>
<appendAssemblyId>false</appendAssemblyId>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
- 瘦jar, 依赖jar要在集群中分发,需要对jar包进行细致管理和分发。
<!--依赖jar包单独生成到指定目录-->
<plugin>
<artifactId>maven-dependency-plugin</artifactId>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>prepare-package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<outputDirectory>${project.build.directory}/lib</outputDirectory>
<overWriteReleases>false</overWriteReleases>
<overWriteSnapshots>false</overWriteSnapshots>
<overWriteIfNewer>true</overWriteIfNewer>
</configuration>
</execution>
</executions>
</plugin>
- 生成一个zip包,(打包时storm代码和依赖jar包分成两个文件夹),上传代码后解压。再配合这两个参数一起使用,即将依赖jar包添加到classpath中。
storm jar /ddhome/usr/job/storm/zy-storm-accesspoint-1.0.0.jar com.ziyun.storm.accesspoint.AccessPointTopo --jars "./lib/*"
个人建议:改写python脚本(storm/bin/storm.py),将jar包中lib加入classpath,如同MR将依赖jar包放在父jar的lib目录下即可运行。
注意:跟端口有关的操作,要查看提供方的防火墙端口是否开放!!!
参考文献
- storm Tutorial
- Storm 的可靠性保证测试--美团
- Flink,Storm,Spark Streaming三种流框架的对比分析
- Spark、Hadoop、Storm对比
- 流处理旅程——storm之tuple介绍
- Storm tuple发送机制
- Problems running Storm with additional classpath
tips:本文属于自己学习和实践过程的记录,很多图和文字都粘贴自网上文章,没有注明引用请包涵!如有任何问题请留言或邮件通知,我会及时回复。
Storm实践(一):基础知识的更多相关文章
- 《Python编程:从入门到实践》基础知识部分学习笔记整理
简介 此笔记为<Python编程:从入门到实践>中前 11 章的基础知识部分的学习笔记,不包含后面的项目部分. 书籍评价 从系统学习 Python 的角度,不推荐此书,个人更推荐使用< ...
- 学习nginx从入门到实践(四) 基础知识之nginx基本配置语法
nginx基本配置语法 1.http相关 展示每次请求的请求头: curl -v http://www.baidu.com 2.nginx日志类型 error.log. access.log log_ ...
- 0.Python 爬虫之Scrapy入门实践指南(Scrapy基础知识)
目录 0.0.Scrapy基础 0.1.Scrapy 框架图 0.2.Scrapy主要包括了以下组件: 0.3.Scrapy简单示例如下: 0.4.Scrapy运行流程如下: 0.5.还有什么? 0. ...
- Storm基础知识
上一篇文章我们介绍一个简单的Storm起源,今天我去学习Storm一些主要的知识,他的基本使用基本的了解.幸运的是,,不是太困难,假设我们理解Hadoop的MapReduce模型的话.看这个也是很类似 ...
- golang+webgl实践激光雷达(一)激光扫描仪基础知识
一.前言 最近做一个测量料堆形状的项目,通过前期调研,最后决定用激光测距原理进行测量.通过旋转云台+激光扫描仪实现空间三维坐标的测量.其中激光扫描仪扫射的是一个二维的扫描面,再通过云台旋转,则形成一个 ...
- IM开发基础知识补课(五):通俗易懂,正确理解并用好MQ消息队列
1.引言 消息是互联网信息的一种表现形式,是人利用计算机进行信息传递的有效载体,比如即时通讯网坛友最熟悉的即时通讯消息就是其具体的表现形式之一. 消息从发送者到接收者的典型传递方式有两种: 1)一种我 ...
- APP测试入门篇之APP基础知识(001)
前言 最近两月比较多的事情混杂在一起,静不下心来写点东西,月初想发表一遍接口测试的总结,或者APP测试相关的内容,一晃就月底了,总结提炼一时半会也整不完.放几个早年总结内部培训PPT出来 ...
- Oracle数据库基础知识
oracle数据库plsql developer 目录(?)[-] 一 SQL基础知识 创建删除数据库 创建删除修改表 添加修改删除列 oracle cascade用法 添加删除约束主键外 ...
- C#基础知识一之base关键字
前言 其实很早就想写关于C#基础,总是自己给自己找借口,或者去网上搜搜看看,现在想想觉得自己有点懒惰... 作为开发人员,基础知识是重中之重的,只有巩固.理解.实践才能提高自身的技能.同时也希望通过 ...
- JVM 基础知识
JVM 基础知识(GC) 2013-12-10 00:16 3190人阅读 评论(1) 收藏 举报 分类: Java(49) 目录(?)[+] 几年前写过一篇关于JVM调优的文章,前段时间拿出来看了看 ...
随机推荐
- ip地址查询python3小工具_V0.0.1
看到同事在一个一个IP地址的百度来确认导出表格中的ip地址所对应的现实世界的地址是否正确,决定给自己新开一个坑.做一个查询ip“地址”的python小工具,读取Excel表格,在表格中的后续列输出尽可 ...
- PYTHON 100days学习笔记001:初识python
现在学习这个确实时间很紧,但是迟早得学,以后PYTHON自动化运维,PYTHON自动测试都需要用的到,甚至可以往数据分析方向发展,刚好最近有数据观组织的python100天计划,就参加了,做好笔记,一 ...
- #学习笔记:CentOS7学习之十三(2):磁盘介绍与管理
1.磁盘分区工具与挂载 1.1 硬盘分区符认识: MBR概述:全称为Master Boot Record,即硬盘的主引导记录. 硬盘的0柱面.0磁头.1扇区称为主引导扇区(也叫主引导记录MBR).它由 ...
- (模板)hdoj1007(分治求平面最小点对)
题目链接:https://vjudge.net/problem/HDU-1007 题意:给定n个点,求平面距离最小点对的距离除2. 思路:分治求最小点对,对区间[l,r]递归求[l,mid]和[mid ...
- AirFlow功能展示个人笔记
DAGs 查看您可以一目了然地查看成功.失败及当前正在运行的任务数量. 选中其中一个DAG 树视图 跨越时间的 DAG 的树表示.如果 pipeline(管道)延迟了,您可以很快地看到哪里出现了错误的 ...
- Oracle-DQL 6- 子查询
子查询: --查询emp表中工资高于allen的员工信息SELECT sal FROM empWHERE ename = 'ALLEN'; SELECT * FROM empWHERE sal > ...
- web/服务器知识
一 PV 推到出 QPS 你想建设一个能承受500万PV/每天的网站吗? 500万PV是什么概念?服务器每秒要处理多少个请求才能应对?如果计算呢?? PV是什么:PV是page view的简写.PV是 ...
- [Err] 1054 - Unknown error 1054
[Err] 1054 - Unknown error 1054:很小的一个错误,缺耽误很长的时间,字段不匹配: 解决方法:一一对照字段,数据库字段要和类中的字段要对应,或者sql语句中使用的字段!仔细 ...
- JZOJ.1150【贪心算法】IQ
欢迎转载,请附上原链接https://www.cnblogs.com/Code-Garden/p/11276741.html(也没人会看) 一道对我来说较难的贪心题 题目描述 根据世界某权威学会的一项 ...
- NPOI_winfrom导出Excel表格(一)(合并单元格、规定范围加外边框、存储路径弹框选择)
1.导出 private void btn_print_Click(object sender, EventArgs e) { DataTable dtNew = new DataTable(); d ...