MongoDB集群之分片技术应用 —— 学习笔记
课程链接:https://www.imooc.com/learn/501
一、什么是分片?
分片:将数据进行2拆分,将数据水平的分散到不同的服务器上。
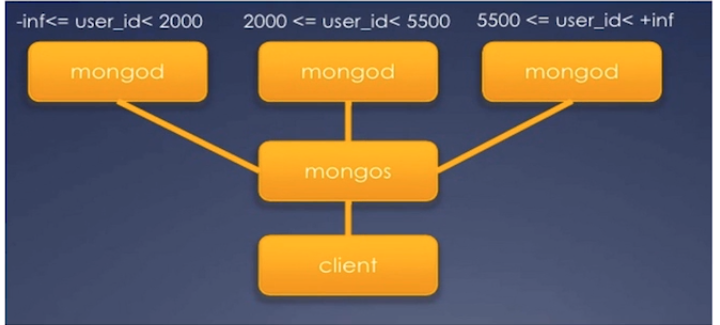
二、为什么要分片?
- 架构上:读写均衡、去中心化
- 结构上:12节点(version<=2.6)
- 硬件上:内存、硬盘容量限制
分片目的
改善单台机器数据的存储及数据吞吐性能。
提高在大量数据下随机访问性能。
分片(Shard)、副本集(Replication)集群对比

成员节点介绍
- Shard节点:存储数据的节点(单个mongod或者副本集)
- Config server:存储元数据,为mongos服务,将数据路由到Shard。
- Mongos:接受前端请求,进行对应消息路由。
成员组合图:

成员节点启动参数
Shard节点:
mongod --shardsvrmongod --shardsvr --rpelSet 副本集
Config server:
mongod --configsvr
Mongos:
mongos —— configdb <configdb server>
课程使用系统:Red Hat Enterprise Linux Server release 6.4 (Santiago)
课程使用MongoDB版本:v3.0.4
启动Shard(10.156.11.233):
mongod --shardsvr --logpath=/opt/data/logs/shard.log -logappend --dbpath=/opt/mdb/ --fork --port 27017
查看mongod Shard有没有启动起来:
ps -aux | grep mongod
netstat -luntp | grep 27017
启动Config(10.156.11.233):
mongod --configsvr --logpath=/opt/data/logs/config.log --logappend --dbpath=/opt/config --fork --port 27018
查看mongod Config有没有启动起来:
netstat -luntp | grep mongo
ps -aux | grep mongod
启动Mongos(10.156.11.232):
mongos --port 27017 --logappend --logpath=/opt/data/logs/mongos.log --configdb 10.156.11.233:27018 --fork
查看Mongos有没有启动起来:
netstat -luntp | grep 27017
ps -aux | grep mongos
添加分片过程
步骤一、连接到mongos
步骤二、Add Shards
步骤三、Enable Sharding
步骤四、对一个集合进行分片
步骤二、Add Shards
- 单个数据库实例:
{ addShard: "<hostname> <:port>", maxSize: <size>, name: "<shard_name>"} - 副本集群:
{ addShard: "<replica_set>/<hostname> <:port>", maxSize:<size>, name: "shard_name" } - 如果你的mongos和shard在同一台机器上,添加分片不能使用“localhost”,建议使用IP。
步骤四、对一个集合进行分片
- db.runCommand
({shardcollection: " <namespoace>", key: " <key>"}) - unique: " true/false"
启动对shard key的唯一性约束 - shard key选择
在10.156.11.232上的操作
这台电脑之前已经启动了mongos服务
输入如下指令登陆mongos:
mongo 127.0.0.1:27017
在mongos命令行下执行如下命令,将10.156.11.232上的mongod添加进来:
mongos> use admin
mongos> db.runCommand({"addShards":"10.156.11.233:27017"})
其他:
查看目前有几个数据库的mongos命令:
mongos> show dbs;
创建名为“shardtest”的数据库的mongos命令:
mongos> use shardtest
测试在数据库shardtest中的集合userid中插入测试数据的例子:
mongos> for(i=0;i<10000;i++){db.shardtest.userid.insert({"user_id":i})};
采用如下命令来Enable刚才创建的名为“shardtest”的Sharding:
mongos> use admin
mongos> db.runCommand({enablesharding:"shardtest"})
不过这个时候它会报一个这样的错误:
{ "ok": 0, "errmsg": "already enabled" }
使用如下命令启用shardtest数据库的userid集合对应的分片,将根据键user_id来进行分片:
mongos> db.runCommand({"shardcollection":"shardtest.userid",key:{"user_id":1}})
其中,"user_id"对应的1表示是按照升序来进行分片。
分片测试
在mongos命令行执行如下命令:
mongos> use config
mongos> db.shards.find()
- 查看集合状态:
> use shardtest
> db.userid.stats()
- 查看分片状态:
db.printShardingStatus()
- 写入数据测试:
for (var i=1;i<10000000;i++>){db.userid.insert(user_id:i)}
什么是分片片键:
集合里面选一个键,用该键的值作为数据拆分的依据。

什么是Chunk:
MongoDB分片后,存储数据的但愿快,默认大小:64MB。
Chunk拆分
数据块(chunk)的拆分:
记录每个块中插入多少数据,一旦达到某个阈值,执行检查是否需要拆分块,需要则更新config服务器上这个块的元信息。
Balancing
数据块平衡:
均衡器负责数据的迁移,会周期性的检查分片是否存在不均衡,如果存在则会进行块的迁移。
注意:均衡器进行均衡的条件是 块数量的多少 ,而不是块大小。
哈希分片
哈辛分片(hash key):
分片过程中利用哈希索引作为分片的单个键。
- 哈希分片的片键只能使用一个字段
- 哈希片键最大的好处就是保证数据在各个节点分布基本均匀
shardcollection ==> {userid:"hashed"}
233上进行如下操作来进行分片:
mongos> db.userid_hash.insert({userid:11})
mongos> db.userid_hash.insert({userid:22})
mongos> use shardtest
mongos> db.userid_hash.ensureIndex({userid:"hash"})
mongos> use admin
mongos> db.runCommand({"shardcollection":"shardtest.userid_hash","key":{userid:"hashed"}})
插入一些数据进行测试:
mongos> use shardtest
mongos> for(i=0;i<100000;i++>{db.userid_hash.insert({userid:i})})
查看效果:
mongos> use shardtest
mongos> db.userid_hash.stats()
mongos> db.printShardingStatus()
如何选择合适片键
选择片键的好坏很大程度上影响集群的性能,容量和功能。
考虑因素一、数据块的大小
印象:片键相同导致数据块不拆分,容易形成大的数据块,导致数据不均。
考虑因素二、数据写均匀分布
影响:单调递增的_id或时间戳作为片键,这样将会导致你一直往最后一个副本集中添加数据。
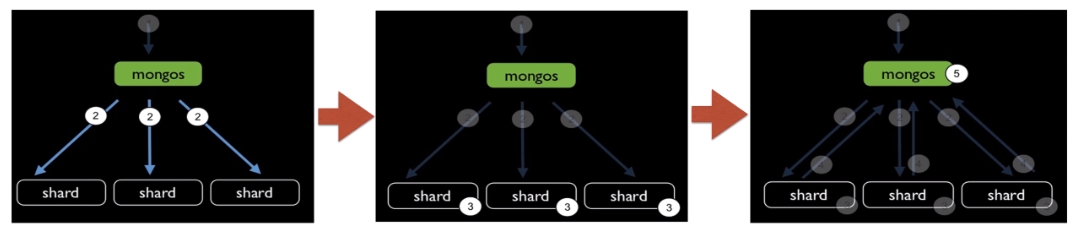
请求查询机制
方式一、Routed Request

方式二、Scatter Gather Request
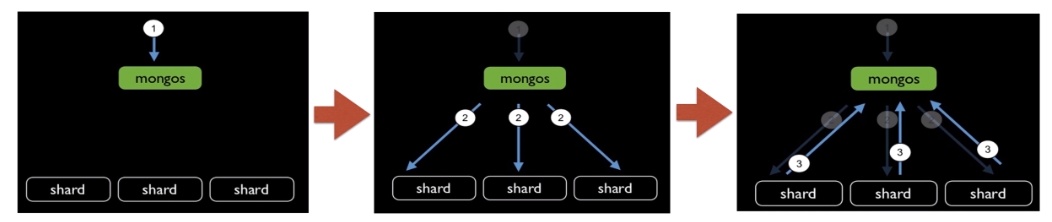
方式三、Distributed Merge Sort Req
手动分片
为什么要手动分片?
为了减少自动平衡过程带来的IO等资源消耗。
前提:
- 关闭自动平衡,关闭auto balence;
- 充分了解数据,并对数据进行预先划分。
步骤一、关闭自动平衡
关闭方式:sh.stopBalancer()
(启动方式:sh.startBalancer())
此时平衡器状态:CurrentLy enabled: no
步骤二、分片切割
> use admin
> db.runCommand({"enablesharding":"myapp"})
> db.runCommand({"shardcollection":"myapp.users","key":{"email":1}})
for (var x=97;x<97+26;x++) {
for (var y=97;y<97+26;y+=6) {
var prefix = String.fromCharCode(x) + String.fromCharCode(y);
db.runCommand({
split: "myapp.users",
middle: { email: prefix }
});
}
}
步骤三、手动移动分割快
var shServer = [
"ShardServer 1",
"ShardServer 2",
"ShardServer 3",
"ShardServer 4",
"ShardServer 5",
]
for (var x=97;x<97+26;x++) {
for (var y=97;y<97+26;y+=6) {
var prefix = String.fromCharCode(x) + String.fromCharCode(y);
db.runCommand({
moveChunk: "myapp.users",
find: { email: prefix },
to: shServer[(y-97)/6]
});
}
}
实践:
首先登陆233的mongos
执行如下命令来关闭平衡:
mongos> sh.stopBalancer()
然后执行下面代码:
mongos> for (var x=97;x<97+26;x++) {
for (var y=97;y<97+26;y+=6) {
var prefix = String.fromCharCode(x) + String.fromCharCode(y);
db.runCommand({
split: "myapp.users",
middle: { email: prefix }
});
}
}
mongos> var shServer = [
"10.156.11.232:27016",
"10.156.11.232:27017",
"10.156.11.232:27016",
"10.156.11.232:27017",
"10.156.11.232:27016",
]
mongos> for (var x=97;x<97+26;x++) {
for (var y=97;y<97+26;y+=6) {
var prefix = String.fromCharCode(x) + String.fromCharCode(y);
db.runCommand({
moveChunk: "myapp.users",
find: { email: prefix },
to: shServer[(y-97)/6]
});
}
}
常用部署场景
场景一

场景二
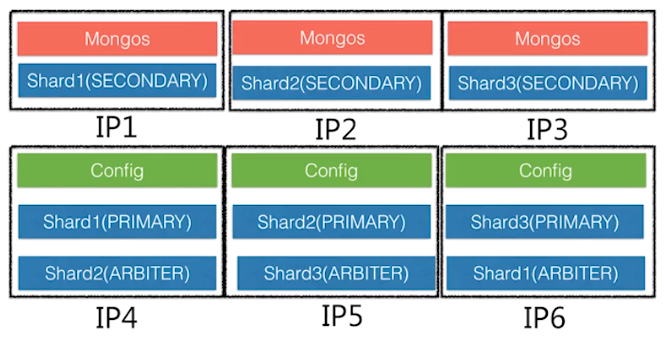
考虑因素:
一、预估数据增长量
二、预估集群的访问量
三、预估投入成本(硬件、人员维护等)
场景一部署
机器规划:
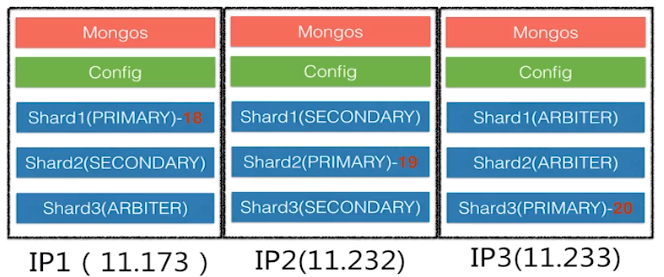
三台电脑均相同方式启动如下服务:
mongod --fork --logpath=/opt/data/logs/mongod27018.log -logappend --dbpath=/opt/mdb27018/ --port 27018 --replSet imooc1
mongod --fork --logpath=/opt/data/logs/mongod27019.log -logappend --dbpath=/opt/mdb27019/ --port 27019 --replSet imooc1
mongod --fork --logpath=/opt/data/logs/mongod27020.log -logappend --dbpath=/opt/mdb27020/ --port 27020 --replSet imooc1
在173节点,执行如下命令进入mongod:
mongo 127.0.0.1:27018
在命令行执行如下指令:
cfg = {
_id: 'imooc1', members: [
{ _id: 0, host: '10.156.11.173:27018' },
{ _id: 1, host: '10.156.11.232:27018' }
]
}
rs.initiate(cfg)
rs.addArb("10.156.11.233:27018")
另外两台电脑的配置类似,此处略。
通过如下命令查看每一个副本集的成员状态:
re.status()
接下来完成对分片的配置(也就是启动configsvr),
在清空之前,我要确认我的configsvr的logpath目录存在,并且log信息是空的:
rm -rf /opt/data/config/*
然后启动configsvr:
mongod --configsvr --logpath=/opt/data/logs/config.log --logappend /opt/data/config --fork --port 27016
在三台电脑上都这么进行启动configsvr的操作。
接下来启动mongos,
这一步需要将所有的configsvr的配置都加上,
如下:
mongos --port 27017 --logappend --logpath=/opt/data/logs/mongos.log --configdb 10.156.11.233:27016,10.156.11.232:27016,10.156.11.173:27016 --fork
同样的,我们可以登陆mongos服务:
mongo 127.0.0.1:27017
这样我们就顺利地把mongos服务启动起来。
接下来登陆到(233上的)mongos上,把我们的成员节点添加进来:
在命令行下执行mongo进入mongos命令行,然后执行如下命令来进行分片配置操作:
mongos> use admin
mongos> db.runCommand({addshard:"imooc1/10.156.11.173:27018,10.156.11.232:27018",name:"shard1",maxsize:20480});
mongos> db.runCommand({addshard:"imooc2/10.156.11.232:27019,10.156.11.233:27019",name:"shard2",maxsize:20480});
mongos> db.runCommand({addshard:"imooc3/10.156.11.233:27020,10.156.11.173:27020",name:"shard3",maxsize:20480});
创建一个测试库:
mongos> use myimooc
mongos> db.user.insert({userid:1,name:"zifeiy",email:"zifeiy@123.com"})
mongos> db.runCommand({ enablesharding:"zifeiy"})
mongos> db.runCommand({"shardcollection":"zifeiy.user","key":{email:1}});
MongoDB集群之分片技术应用 —— 学习笔记的更多相关文章
- MongoDB集群搭建-分片
MongoDB集群搭建-分片 一.场景: 1,机器的磁盘不够用了.使用分片解决磁盘空间的问题. 2,单个mongod已经不能满足写数据的性能要求.通过分片让写压力分散到各个分片上面,使用分片服务器自身 ...
- Mongodb集群与分片 1
分片集群 Mongodb中数据分片叫做chunk,它是一个Collection中的一个连续的数据记录,但是它有一个大小限制,不可以超过200M,如果超出产生新的分片. 下面是一个简单的分片集群 ...
- MongoDB集群之分片
原文:点击打开链接 MongoDB分片 分片(sharding)是将数据拆分,将其分散在不同的机器上的过程.MongoDB支持自动分片 片键(shard key)设置分片时,需要从集合里面选一个键,用 ...
- mongodb集群配置分片集群
测试环境 操作系统:CentOS 7.2 最小化安装 主服务器IP地址:192.168.197.21 mongo01 从服务器IP地址:192.168.197.22 mongo02 从服务器IP地址: ...
- Mongodb集群与分片 2
前面我们介绍了简单的集群配置实例.在简单实例中,虽然MongoDB auto-Sharding解决了海量存储问题,和动态扩容问题,但是离我们在真实环境下面所需要的高可靠性和高可用性还有一定的距离. 下 ...
- mongodb 集群部署--分片服务器搭建
部署分片服务器 1.分片 为了突破单点数据库服务器的I/O能力限制,对数据库存储进行水平扩展,严格地说,每一个服务器或者实例或者复制集就是一个分片. 2.优势 提供类似现行增·长架构 提高数据可用性 ...
- ubuntu docker 下mongodb集群和分片
首先我们计划启动了三个mongo服务:master,salve,arbiter 1.准备工作 新建文件夹如图(每个文件夹下面有db和configdb文件夹): 生成认证文件并修改权限 openssl ...
- 搭建高可用mongodb集群—— 分片
从节点每个上面的数据都是对数据库全量拷贝,从节点压力会不会过大? 数据压力大到机器支撑不了的时候能否做到自动扩展? 在系统早期,数据量还小的时候不会引起太大的问题,但是随着数据量持续增多,后续迟早会出 ...
- 搭建高可用mongodb集群(四)—— 分片(经典)
转自:http://www.lanceyan.com/tech/arch/mongodb_shard1.html 按照上一节中<搭建高可用mongodb集群(三)-- 深入副本集>搭建后还 ...
随机推荐
- python练习题(一)
背景: 和公司的二位同事一起学习python,本着共同学习.共同成长.资源共享的目标,然后从中学习,三人行必有我师 练习题更新中······ 题目: 输入一个值num,如果 num 大于 10,输出: ...
- JavaScript是如何工作的01:引擎,运行时和调用堆栈的概述!
概述 几乎每个人都已经听说过 V8 引擎,大多数人都知道 JavaScript 是单线程的,或者它使用的是回调队列. 在本文中,我们将详细介绍这些概念,并解释 JavaScrip 实际如何运行.通过了 ...
- java 设计模式 --委派模式
委派模式(Delegate)原理: 类B和类A是两个互相没有任何关系的类,但是B具有和A一模一样的方法和属性:并且调用B中的方法/属性就是调用A中同名的方法和属性. B好像就是一个受A授权委托的中介, ...
- PHP实现多文件上传的一些简单方法
下面我们就通过具体的代码示例,为大家介绍PHP实现多文件上传的一些简单方法. 第一种方法:利用单个文件上传方法 一段简单的form表单代码如下: <!DOCTYPE html> <h ...
- java application指的到底是什么?
在Java语言中,能够独立运行的程序称为Java应用程序(Application).Java语言还有另外一种程序——Applet程序.Applet程序(也称Java小程序)是运行于各种网页文件中,用于 ...
- CF455C Civilization
嘟嘟嘟 水题一道,某谷又恶意评分. 合并无非是将两棵树的直径的中点连一块,记原来两棵树的直径为\(d_1, d_2\),那么新的树的直径就是\(max(d_1, d_2, \lceil \frac{d ...
- 【概率论】4-7:条件期望(Conditional Expectation)
title: [概率论]4-7:条件期望(Conditional Expectation) categories: - Mathematic - Probability keywords: - Exp ...
- P1966 火柴排队——逆序对(归并,树状数组)
P1966 火柴排队 很好的逆序对板子题: 求的是(x1-x2)*(x1-x2)的最小值: x1*x1+x2*x2-2*x1*x2 让x1*x2最大即可: 可以证明将b,c数组排序后,一一对应的状态是 ...
- codeforces#1120C. Compress String(dp+后缀自动机)
题目链接: https://codeforces.com/contest/1120/problem/C 题意: 从前往后压缩一段字符串 有两种操作: 1.对于单个字符,压缩它花费$a$ 2.对于末尾一 ...
- radio回显的
JS回显 var jksp=document.getElementsByName("spjdcyModel.jksp"); // alert(jksp[0].value); //a ...