Hive实现WordCount详解
一、WordCount原理
初学MapReduce编程,WordCount作为入门经典,类似于初学编程时的Hello World。WordCount的逻辑就是给定一个/多个文本,统计出文本中每次单词/词出现的次数。网上找的一张MapReduce实现WordCount的图例,基本描述清楚了WordCount的内部处理逻辑。本文主要是从Hive使用的角度处理WordCount,就不赘述,之前的一篇博文有MapReduce实现WordCount的代码,可参考 https://www.cnblogs.com/walker-/p/9669631.html。
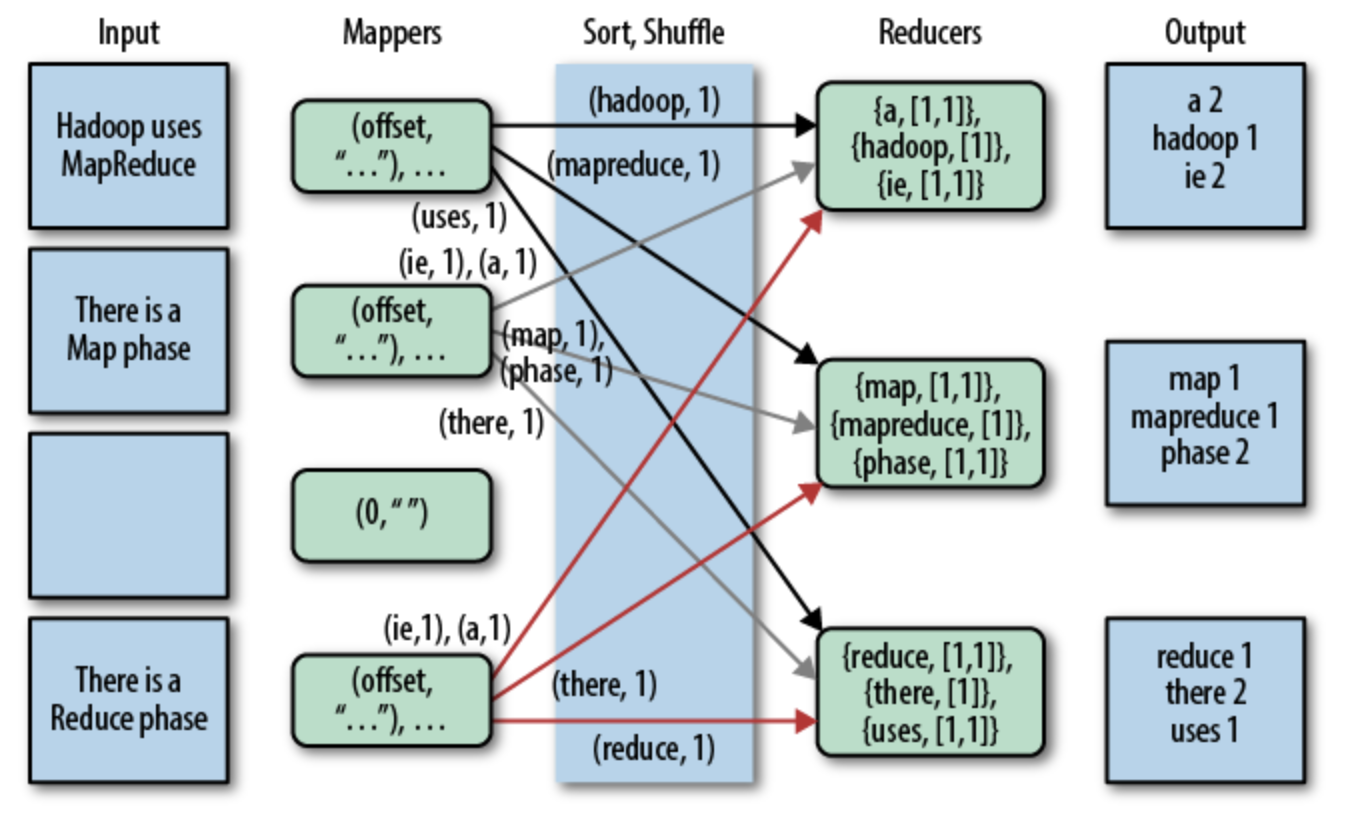
图1 MapRecude实现Word Count图例
二、Hive实现WordCount
2.1 SQL实现
先直接上SQL语句,可以看出SQL实现确实比MapReduce实现要清爽得多。大概实现流程分为三步:
- 分割本文。根据分割符对文本进行分割,切分出每个单词;
- 行转列。对分割出来的词进行处理,每个单词作为一行;
- 统计计数。统计每个单词出现的次数。
SELECT word, count(1) AS count FROM
(SELECT explode(split(line, '\r')) AS word FROM docs) w
GROUP BY word
ORDER BY word;
2.2 实现细节
1. 准备文本内容
新建一个 /home/kwang/docs.txt 文本,文本内容如下:
hello world
hello kwang rzheng
2. 新建hive表
这里由于hive环境建表默认格式是ORC,直接load数据hive表无法直接读取,故建表时指定了表格式。
CREATE TABLE `docs`(
`line` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';
3. 加载数据到hive表中
加载数据到hive表中有两种方式,一种是从Linux本地文件系统加载,一种是从HDFS文件系统加载。
(1)从Linux本地文件系统加载
LOAD DATA LOCAL INPATH '/home/kwang/docs.txt' OVERWRITE INTO TABLE docs;
(2)从HDFS文件系统加载
首先需要将文件上传到HDFS文件系统
$ hadoop fs -put /home/kwang/docs.txt /user/kwang/
其次从HDFS文件系统加载数据
LOAD DATA INPATH 'docs.txt' OVERWRITE INTO TABLE docs;
加载数据到hive表后,查看hive表的内容,和原始文本格式并没有区别,将文本按行存储到hive表中,可以通过 'select * from docs;' 看下hive表内容:
hello world
hello kwang rzheng
4. 分割文本
分割单词SQL实现:
SELECT split(line, '\s') AS word FROM docs;
分割后结果:
["hello","world"]
["hello","kwang","rzheng"]
可以看出,分割后的单词仍是都在一行,无法实现想要的功能,因此需要进行行转列操作。
5. 行转列
行转列SQL实现:
SELECT explode(split(line, ' ')) AS word FROM docs;
转换后的结果:
hello
world
hello
kwang
rzheng
6. 统计计数
SELECT word, count(1) AS count FROM
(SELECT explode(split(line, ' ')) AS word FROM docs) w
GROUP BY word
ORDER BY word;
统计后结果:
hello 2
kwang 1
rzheng 1
world 1
至此,Hive已实现WordCount计数功能。
【参考资料】
[1]. https://www.oreilly.com/library/view/programming-hive/9781449326944/ch01.html
Hive实现WordCount详解的更多相关文章
- JStorm第一个程序WordCount详解
一.Strom基本知识(回顾) 1,首先明确Storm各个组件的作用,包括Nimbus,Supervisor,Spout,Bolt,Task,Worker,Tuple nimbus是整个storm任务 ...
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- hadoop集群配置方法---mapreduce应用:xml解析+wordcount详解---yarn配置项解析
注:以下链接均为近期hadoop集群搭建及mapreduce应用开发查找到的资料.使用hadoop2.6.0,其中hadoop集群配置过程下面的文章都有部分参考. hadoop集群配置方法: ---- ...
- Hive的配置详解和日常维护
Hive的配置详解和日常维护 一.Hive的参数配置详解 1>.mapred.reduce.tasks 默认为-1.指定Hive作业的reduce task个数,如果保留默认值,则Hive 自 ...
- 图解大数据 | 海量数据库查询-Hive与HBase详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/84 本文地址:http://www.showmeai.tech/article-det ...
- [Hive] - Hive参数含义详解
hive中参数分为三类,第一种system环境变量信息,是系统环境变量信息:第二种是env环境变量信息,是当前用户环境变量信息:第三种是hive参数变量信息,是由hive-site.xml文件定义的以 ...
- Hadoop之WordCount详解
花了好长时间查找资料理解.学习.总结 这应该是一篇比较全面的MapReduce之WordCount文章了 耐心看下去 1,创建本地文件 在hadoop-2.6.0文件夹下创建一个文件夹data,在其中 ...
随机推荐
- JDK源码那些事儿之LinkedBlockingQueue
今天继续讲解阻塞队列,涉及到了常用线程池的其中一个队列LinkedBlockingQueue,从类命名部分我们就可以看出其用意,队列中很多方法名是通用的,只是每个队列内部实现不同,毕竟实现的都是同一个 ...
- javascript权威指南第21章 Ajax和Comet
function createXHR(){ if(typeof XMLHttpRequest !='undefined'){ return new XMLHttpRequest(); }else if ...
- 动态 DP 总结
目录 例题1:模拟赛题 代码: 例题2 例题3:带修改树上最大独立集. 代码: 注:部分参考 https://www.luogu.org/blog/gkxx-is-here/what-the-hell ...
- Mysql5.7.27.msi的下载与安装
1.下载地址链接:https://dev.mysql.com/downloads/windows/installer/8.0.html 2. 点击下载后可以选择不用登录直接下载 3.下载的mysql安 ...
- 008_硬件基础电路_RC消火花电路分析方法和思路
如上图所示是一种RC消火花电路.电路中,+V是直流工作电压,S1是电源开关,M是直流电机,R1和C1构成RC消火花电路. 1.电路分析需要了解火花产生的原因直流电机的内部是一个线圈结构,根据线圈的有关 ...
- spark提交任务报错: java.lang.SecurityException: Invalid signature file digest for Manifest main attributes
spark提交任务报错: java.lang.SecurityException: Invalid signature file digest for Manifest main attributes ...
- MongoDB 分片键分类与数据分发
In sharded clusters, if you do not use the _id field as the shard key, then your application must en ...
- KMP解决字符串最小循环节相关问题
经典问题 : 给出一个由某个循环节构成的字符串,要你找出最小的循环节,例如 abababab 最小循环节当是 ab ,而类似 abab 也可以成为它的循环节,但并非最短. 分析 : 对于上述问题有两个 ...
- redis简单消息队列
<?php $redis = new Redis(); $redis->connect('127.0.0.1',6379); $redis->flushall(); $redis-& ...
- php rsa 非对称加解密类
<?php header("Content-Type: text/html;charset=utf-8"); /* 生成公钥.私钥对,私钥加密的内容能通过公钥解密(反过来亦可 ...