Yarn简单介绍及内存配置
本文出自:http://blog.chinaunix.net/uid/28311809/abstract/1.html
在这篇博客中,主要介绍了Yarn对MRv1的改进,以及Yarn简单的内存配置和Yarn的资源抽象container。
我么知道MRv1存在的主要问题是:在运行时,JobTracker既负责资源管理又负责任务调度,这导致了它的扩展性、资源利用率低等问题。之所以存在这样的问题,是与其最初的设计有关,如下图:

从上图可以看到,MRv1是围绕着MapReduce进行,并没有过多地考虑以后出现的其它数据处理方式 。按着上图的设计思路,我们每开发一种数据处理方式(例如spark),都要重复实现相应的集群资源管理和数据处理。因此,Yarn就很自然的被开发出来了。
Yarn对MRv1的最大改进就是将资源管理与任务调度分离,使得各种数据处理方式能够共享资源管理,如下图所示:
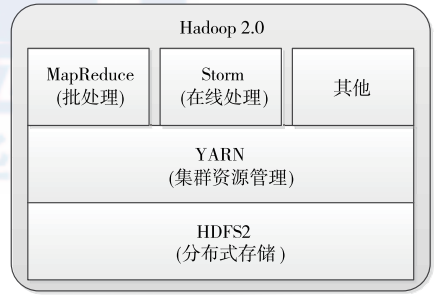
从上图我们可以看到,Yarn是一种统一资源管理方式,是从MRv1中的JobTracker分离出来的。这样的好处显而易见:资源共享,扩展性好等。
MRv1与Yarn的主要区别:在MRv1中,由JobTracker负责资源管理和作业控制,而Yarn中,JobTracker被分为两部分:ResourceManager(RM)和ApplicationMaster(AM)。如下图所示:
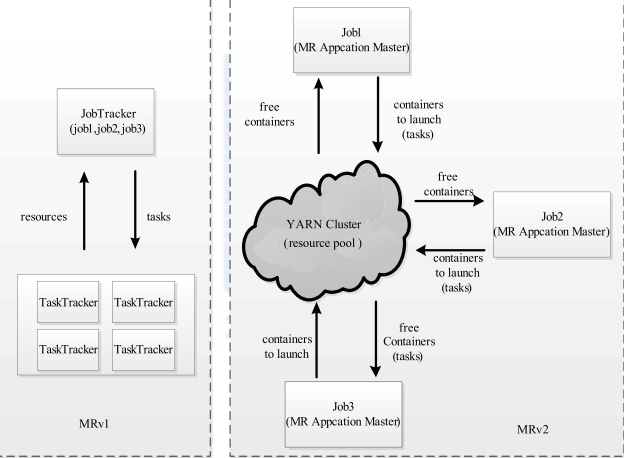
从上图中,我们可以清晰的看到 ,对于MRv1无论是资源管理里还是任务调度都是有JobTracker来完成得。这导致了,JobTracker负荷太大不便于管理和扩展而对于Yarn,我们看可以清晰地看到资源管理和任务调度被分为了两个部分:RM和AM。
Yarn与MRv1的差异对编程的影响:我们知道,MRv1主要由三部分组成:编程模型(API)、数据处理引擎(MapTask和ReduceTask)和运行环境(JobTracker和TaskTracker);Yarn继承了MRv1的编程模型和数据处理,改变的只是运行环境,所以对编程没有什么影响。
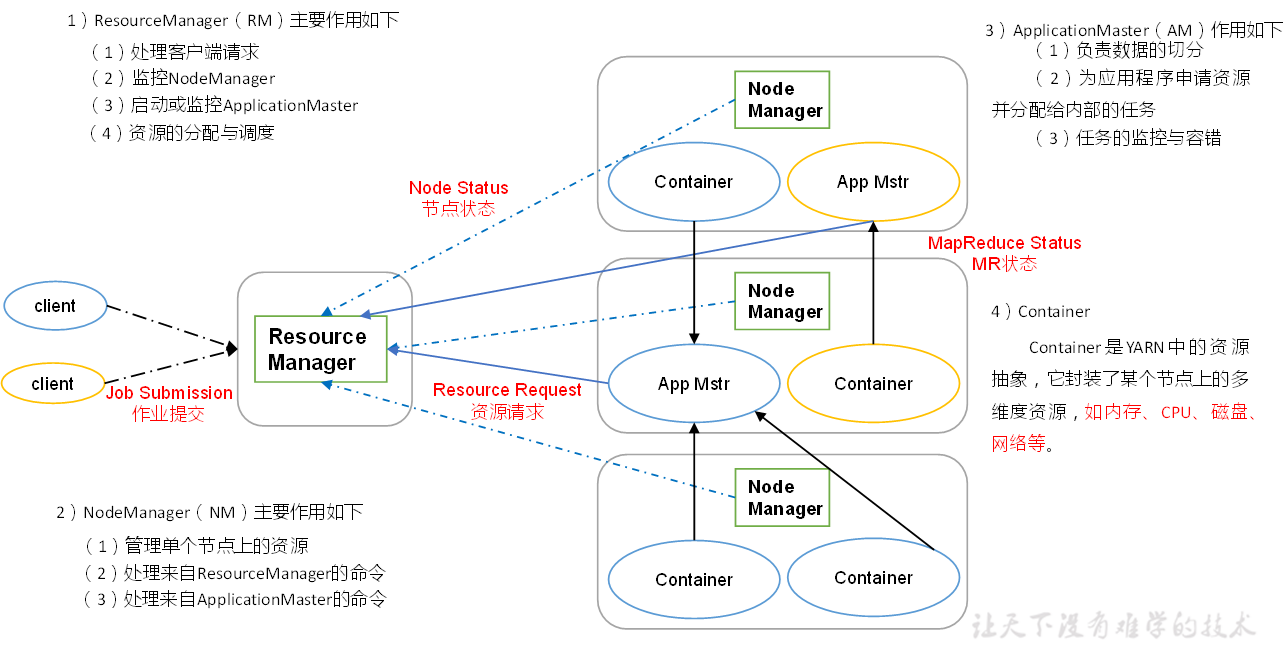
为了更好 的说明Yarn的资源管理,首先来看下Yarn的框架,如下图所示:

从上图可以看到 ,当客户向RM提交 作业时,由AM负责向RM提出资源申请,和向NameManager(NM)提出task执行 。也就是说 在这个过程中,RM负责资源调度,AM 负责任务调度。几点重要说明:RM负责整个集群的资源管理与调度;Nodemanager(NM)负责单个节点的资源管理与调度;NM定时的通过心跳的形式与RM进行通信,报告节点的健康状态与内存使用情况;AM通过与RM交互获取资源,然后然后通过与NM交互,启动计算任务。
下面对上面的内容通过内存资源配置进行详细说明:下面对上面的内容通过内存资源配置进行详细说明:
RM的内存资源配置,主要是通过下面的两个参数进行的(这两个值是Yarn平台特性,应在yarn-sit.xml中配置好):
yarn.scheduler.minimum-allocation-mb
yarn.scheduler.maximum-allocation-mb
说明:单个容器可申请的最小与最大内存,应用在运行申请内存时不能超过最大值,小于最小值则分配最小值,从这个角度看,最小值有点想操作系统中的页。最小值还有另外一种用途,计算一个节点的最大container数目注:这两个值一经设定不能动态改变(此处所说的动态改变是指应用运行时)。
NM的内存资源配置,主要是通过下面两个参数进行的(这两个值是Yarn平台特性,应在yarn-sit.xml中配置) :
yarn.nodemanager.resource.memory-mb
yarn.nodemanager.vmem-pmem-ratio
说明:每个节点可用的最大内存,RM中的两个值不应该超过此值。此数值可以用于计算container最大数目,即:用此值除以RM中的最小容器内存。虚拟内存率,是占task所用内存的百分比,默认值为2.1倍;注意:第一个参数是不可修改的,一旦设置,整个运行过程中不可动态修改,且该值的默认大小是8G,即使计算机内存不足8G也会按着8G内存来使用。
AM内存配置相关参数,此处以MapReduce为例进行说明(这两个值是AM特性,应在mapred-site.xml中配置),如下:
mapreduce.map.memory.mb
mapreduce.reduce.memory.mb
说明:这两个参数指定用于MapReduce的两个任务(Map and Reduce task)的内存大小,其值应该在RM中的最大最小container之间。如果没有配置则通过如下简单公式获得:
max(MIN_CONTAINER_SIZE, (Total Available RAM) / containers))
一般的reduce应该是map的2倍。注:这两个值可以在应用启动时通过参数改变;
AM中其它与内存相关的参数,还有JVM相关的参数,这些参数可以通过,如下选项配置:
mapreduce.map.java.opts
mapreduce.reduce.java.opts
说明:这两个参主要是为需要运行JVM程序(java、scala等)准备的,通过这两个设置可以向JVM中传递参数的,与内存有关的是,-Xmx,-Xms等选项。此数值大小,应该在AM中的map.mb和reduce.mb之间。
我们对上面的内容进行下总结,当配置Yarn内存的时候主要是配置如下三个方面:每个Map和Reduce可用物理内存限制;对于每个任务的JVM对大小的限制;虚拟内存的限制;
下面通过一个具体错误实例,进行内存相关说明,错误如下:
Container[pid=41884,containerID=container_1405950053048_0016_01_000284] is running beyond virtual memory limits. Current usage: 314.6 MB of 2.9 GB physical memory used; 8.7 GB of 6.2 GB virtual memory used. Killing container.
配置如下:
- <property>
- <name>yarn.nodemanager.resource.memory-mb</name>
- <value>100000</value>
- </property>
- <property>
- <name>yarn.scheduler.maximum-allocation-mb</name>
- <value>10000</value>
- </property>
- <property>
- <name>yarn.scheduler.minimum-allocation-mb</name>
- <value>3000</value>
- </property>
- <property>
- <name>mapreduce.reduce.memory.mb</name>
- <value>2000</value>
- </property>
通过配置我们看到,容器的最小内存和最大内存分别为:3000m和10000m,而reduce设置的默认值小于2000m,map没有设置,所以两个值均为3000m,也就是log中的“2.9 GB physical
memory used”。而由于使用了默认虚拟内存率(也就是2.1倍),所以对于Map Task和Reduce Task总的虚拟内存为都为3000*2.1=6.2G。而应用的虚拟内存超过了这个数值,故报错 。解决办
法:在启动Yarn是调节虚拟内存率或者应用运行时调节内存大小。
在上Yarn的框架管理中,无论是AM从RM申请资源,还是NM管理自己所在节点的资源,都是通过container进行的。Container是Yarn的资源抽象,此处的资源包括内存和cup等。下面对
container,进行比较详细的介绍。为了是大家对container有个比较形象的认识,首先看下图:

从上图中我们可以看到,首先AM通过请求包ResourceRequest从RM申请资源,当获取到资源后,AM对其进行封装,封装成ContainerLaunchContext对象,通过这个对象,AM与NM进行通讯,
以便启动该任务。下面通过ResourceRequest、container和ContainerLaunchContext的protocol buffs定义,对其进行具体分析。
ResourceRequest结构如下:
- message ResourceRequestProto {
- optional PriorityProto priority = 1; // 资源优先级
- optional string resource_name = 2; // 期望资源所在的host
- optional ResourceProto capability = 3; // 资源量(mem、cpu)
- optional int32 num_containers = 4; // 满足条件container个数
- optional bool relax_locality = 5 ; //default = true;
- }
对上面结构进行简要按序号说明:
2:在提交申请时,期望从哪台主机上获得,但最终还是AM与RM协商决定;
3:只包含两种资源,即:内存和cpu,申请方式:<memory_num,cup_num>
注:1、由于2与4并没有限制资源申请量,则AP在资源申请上是无限的。2、Yarn采用覆盖式资源申请方式,即:AM每次发出的资源请求会覆盖掉之前在同一节点且优先级相同的资源请求,
也就是说同一节点中相同优先级的资源请求只能有一个。
container结构:
- message ContainerProto {
- optional ContainerIdProto id = 1; //container id
- optional NodeIdProto nodeId = 2; //container(资源)所在节点
- optional string node_http_address = 3;
- optional ResourceProto resource = 4; //分配的container数量
- optional PriorityProto priority = 5; //container的优先级
- optional hadoop.common.TokenProto container_token = 6; //container token,用于安全认证
- }
注:每个container一般可以运行一个任务,当AM收到多个container时,将进一步分给某个人物。如:MapReduce
点击(此处)折叠或打开
- message ContainerLaunchContextProto {
- repeated StringLocalResourceMapProto localResources = 1; //该Container运行的程序所需的在资源,例如:jar包
- optional bytes tokens = 2;//Security模式下的SecurityTokens
- repeated StringBytesMapProto service_data = 3;
- repeated StringStringMapProto environment = 4; //Container启动所需的环境变量
- repeated string command = 5; //该Container所运行程序的命令,比如运行的为java程序,即$JAVA_HOME/bin/java org.ourclassrepeated ApplicationACLMapProto application_ACLs = 6;//该Container所属的Application的访问
- 控制列表
- }
下面结合一段代码,仅以ContainerLaunchContext为例进行描述(本应该写个简单的有限状态机的,便于大家理解,但时间不怎么充分):
- 申请一个新的ContainerLaunchContext:
- ContainerLaunchContext ctx = Records.newRecord(ContainerLaunchContext.class);
- 填写必要的信息:
- ctx.setEnvironment(...);
- childRsrc.setResource(...);
- ctx.setLocalResources(...);
- ctx.setCommands(...);
- 启动任务:
- startReq.setContainerLaunchContext(ctx);
最后对container进行如下总结:container是Yarn的资源抽象,封装了节点上的一些资源,主要是CPU与内存;container是AM向NM申请的,其运行是由AM向资源所在NM发起的,并最终运行
的。有两类container:一类是AM运行需要的container;另一类是AP为执行任务向RM申请的。
Yarn简单介绍及内存配置的更多相关文章
- Frame Relay - 简单介绍及基本配置
Frame Relay如今越来越不流行了,只是在过去的设计中被广泛应用. 所以工作上还是能常常见到的, 这篇博文从二层简单总结下FR的一些概念 在介绍Frame Relay之前,先了解下广播介质和非广 ...
- Android Studio使用心得 - 简单介绍与环境配置
FBI Warning:欢迎转载,但请标明出处:http://blog.csdn.net/codezjx/article/details/38544823,未经本人允许请勿用于商业用途.感谢支持! 关 ...
- 内存数据网格IMDG简单介绍
1 简单介绍 将内存作为首要存储介质不是什么新奇事儿,我们身边有非常多主存数据库(IMDB或MMDB)的样例.在对主存的使用上.内存数据网格(In Memory Data Grid,IMDG)与IMD ...
- 【C/C++学院】0724-堆栈简单介绍/静态区/内存完毕篇/多线程
[送给在路上的程序猿] 对于一个开发人员而言,可以胜任系统中随意一个模块的开发是其核心价值的体现. 对于一个架构师而言,掌握各种语言的优势并能够运用到系统中.由此简化系统的开发.是其架构生涯的第一步. ...
- 分配IP地址的好东西 DHCP以及NAT简单介绍
主机配置协议DHCP 1.DHCP应用场景 2.DHCP基础原理 3.NAT简单介绍 4.配置命令 1.手工配置IP地址,工作量比较大而且不好管理,如果用户自己修改参数,可能会导致ip地址冲突,这个时 ...
- 并发编程概述 委托(delegate) 事件(event) .net core 2.0 event bus 一个简单的基于内存事件总线实现 .net core 基于NPOI 的excel导出类,支持自定义导出哪些字段 基于Ace Admin 的菜单栏实现 第五节:SignalR大杂烩(与MVC融合、全局的几个配置、跨域的应用、C/S程序充当Client和Server)
并发编程概述 前言 说实话,在我软件开发的头两年几乎不考虑并发编程,请求与响应把业务逻辑尽快完成一个星期的任务能两天完成绝不拖三天(剩下时间各种浪),根本不会考虑性能问题(能接受范围内).但随着工 ...
- 一个性能较好的jvm參数配置以及jvm的简单介绍
一个性能较好的webserverjvm參数配置: -server //服务器模式 -Xmx2g //JVM最大同意分配的堆内存,按需分配 -Xms2g //JVM初始分配的堆内存.一般和Xmx配置成一 ...
- Mahout学习之Mahout简单介绍、安装、配置、入门程序測试
一.Mahout简单介绍 查了Mahout的中文意思--驭象的人,再看看Mahout的logo,好吧,想和小黄象happy地玩耍,得顺便陪陪这位驭象人耍耍了... 附logo: (就是他,骑在象头上的 ...
- SiteMesh配置下载使用(简单介绍)
简单介绍 SiteMesh 是一个网页布局和修饰的框架,利用它可以将网页的内容和页面结构分离,以达到页面结构共享的目的. Sitemesh是由一个基于Web页面布局.装饰以及与现存Web应用整合的框架 ...
随机推荐
- evpp http response_http_code_
response_http_code_ 909 例子代码 evpp 代码内例子 注释 可以读一下
- HTTP 状态码(常见及分析)
首先得明白状态码的几个大类: 状态码 响应类别 出现原因 1XX 信息性状态码(Informational) 服务器正在处理请求 2XX 成功状态码(Success) 请求已正常处理完毕 3XX 重定 ...
- Vue界面中关于APP端回调方法问题
在混合开发中,HTML界面经常性的需要调用APP端提供的原生方法,而且在很多时候,APP端需要各种回调,如果将所有的回调方法写在内部,不是很方便,而且有些时候,APP端需要定义一些主动触发HTML界面 ...
- MySQL 新建用户并赋予权限
创建一个用户: create user 'oukele'@'%' identified by 'oukele'; 提示下面所列出的信息的话,得刷新一下权限表 The MySQL server is r ...
- 理解*arg 、**kwargs
这两个是python中的可变参数.*args表示任何多个无名参数,它是一个tuple(元祖):**kwargs表示关键字参数,它是一个dict(字典).并且同时使用*args和**kwargs时,必须 ...
- OFDM为什么把高频子载波作为保护频带
实际中发射机接收机的低通滤波器并不是理想低通滤波器,在[-W/2,W/2]之外的一个小范围(对应使用旁边的频带的用户的高频)之内也会有一些不可忽略的能量:并且,实际低通滤波器在高频子载波上的幅度也会比 ...
- HEML与Css的基本理解
什么是 HTML? HTML 就像造房子一样,一栋房子有多个组成部分,html类似于房子的户型,它设计了房子的整体架构.分区.布局,而且还定义了每个区块的功能作用.html技术为后续入住的数据事先搭建 ...
- 002_Python3 基础语法
1.注释 实例1: #!/usr/bin/python3 # 第一个注释 print("Hello, Python!") # 第二个注释 ****************** ...
- 51nod 3 * problem
1640题意:一张无向图在最小化最大边后求最大边权和 Slove:sort 最小生成树倒叙最大生成树 #include <iostream> #include <cstdio> ...
- CSP初赛复习
初赛复习 初赛一定要过啊,否则付出的那么多都白搭了! while(1) ++csp.rp,++csp.luck,++csp.scores; 历史 2020年开始,除NOIP以外的NOI系列其他赛事(包 ...