[科普] CPU, GPU, TPU的区别
Google Cloud 原文链接:https://cloud.google.com/blog/products/ai-machine-learning/what-makes-tpus-fine-tuned-for-deep-learning
机器之心翻译链接:https://baijiahao.baidu.com/s?id=1610560990129941099&wfr=spider&for=pc
张量处理单元(TPU)是一种定制化的 ASIC 芯片,它由谷歌从头设计,并专门用于机器学习工作负载。TPU 为谷歌的主要产品提供了计算支持,包括翻译、照片、搜索助理和 Gmail 等。Cloud TPU 将 TPU 作为可扩展的云计算资源,并为所有在 Google Cloud 上运行尖端 ML 模型的开发者与数据科学家提供计算资源。在 Google Next’18 中,我们宣布 TPU v2 现在已经得到用户的广泛使用,包括那些免费试用用户,而 TPU v3 目前已经发布了内部测试版。
tpudemo.com该网站 PPT 解释了 TPU 的特性与定义。在本文中,我们将关注 TPU 某些特定的属性。
神经网络如何运算
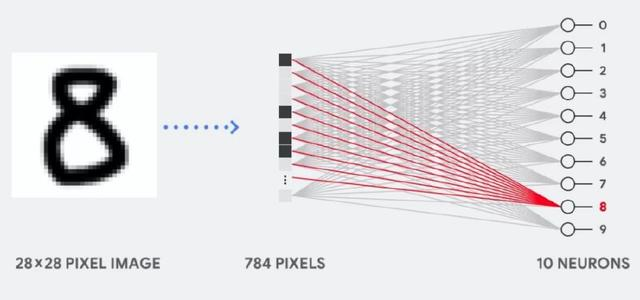
如果图像为 28×28 像素的灰度图,那么它可以转化为包含 784 个元素的向量。神经元会接收所有 784 个值,并将它们与参数值(上图红线)相乘,因此才能识别为「8」。其中参数值的作用类似于用「滤波器」从数据中抽取特征,因而能计算输入图像与「8」之间的相似性:这是对神经网络做数据分类最基础的解释,即将数据与对应的参数相乘,并将它们加在一起。如果我们能得到最高的预测值,那么我们会发现输入数据与对应参数非常匹配,这也就最可能是正确的答案。 简单而言,神经网络在数据和参数之间需要执行大量的乘法和加法。我们通常会将这些乘法与加法组合为矩阵运算,这在我们大学的线性代数中会提到。所以关键点是我们该如何快速执行大型矩阵运算,同时还需要更小的能耗。
CPU 如何运行

CPU 最大的优势是灵活性。通过冯诺依曼架构,我们可以为数百万的不同应用加载任何软件。我们可以使用 CPU 处理文字、控制火箭引擎、执行银行交易或者使用神经网络分类图像。
但是,由于 CPU 非常灵活,硬件无法一直了解下一个计算是什么,直到它读取了软件的下一个指令。CPU 必须在内部将每次计算的结果保存到内存中(也被称为寄存器或 L1 缓存)。内存访问成为 CPU 架构的不足,被称为冯诺依曼瓶颈。虽然神经网络的大规模运算中的每一步都是完全可预测的,每一个 CPU 的算术逻辑单元(ALU,控制乘法器和加法器的组件)都只能一个接一个地执行它们,每一次都需要访问内存,限制了总体吞吐量,并需要大量的能耗。
GPU 如何工作

为了获得比 CPU 更高的吞吐量,GPU 使用一种简单的策略:在单个处理器中使用成千上万个 ALU。现代 GPU 通常在单个处理器中拥有 2500-5000 个 ALU,意味着你可以同时执行数千次乘法和加法运算。
这种 GPU 架构在有大量并行化的应用中工作得很好,例如在神经网络中的矩阵乘法。实际上,相比 CPU,GPU 在深度学习的典型训练工作负载中能实现高几个数量级的吞吐量。这正是为什么 GPU 是深度学习中最受欢迎的处理器架构。
但是,GPU 仍然是一种通用的处理器,必须支持几百万种不同的应用和软件。这又把我们带回到了基础的问题,冯诺依曼瓶颈。在每次几千个 ALU 的计算中,GPU 都需要访问寄存器或共享内存来读取和保存中间计算结果。因为 GPU 在其 ALU 上执行更多的并行计算,它也会成比例地耗费更多的能量来访问内存,同时也因为复杂的线路而增加 GPU 的物理空间占用。
TPU 如何工作
当谷歌设计 TPU 的时候,我们构建了一种领域特定的架构。这意味着,我们没有设计一种通用的处理器,而是专用于神经网络工作负载的矩阵处理器。TPU 不能运行文本处理软件、控制火箭引擎或执行银行业务,但它们可以为神经网络处理大量的乘法和加法运算,同时 TPU 的速度非常快、能耗非常小且物理空间占用也更小。
其主要助因是对冯诺依曼瓶颈的大幅度简化。因为该处理器的主要任务是矩阵处理,TPU 的硬件设计者知道该运算过程的每个步骤。因此他们放置了成千上万的乘法器和加法器并将它们直接连接起来,以构建那些运算符的物理矩阵。这被称作脉动阵列(Systolic Array)架构。在 Cloud TPU v2 的例子中,有两个 128X128 的脉动阵列,在单个处理器中集成了 32768 个 ALU 的 16 位浮点值。
一个脉动阵列如何执行神经网络计算。
首先,TPU 从内存加载参数到乘法器和加法器的矩阵中。

然后,TPU 从内存加载数据。当每个乘法被执行后,其结果将被传递到下一个乘法器,同时执行加法。因此结果将是所有数据和参数乘积的和。在大量计算和数据传递的整个过程中,不需要执行任何的内存访问。

这就是为什么 TPU 可以在神经网络运算上达到高计算吞吐量,同时能耗和物理空间都很小。
好处:成本降低至 1/5
因此使用 TPU 架构的好处就是:降低成本。以下是截至 2018 年 8 月(写这篇文章的时候)Cloud TPU v2 的使用价格。
Cloud TPU v2 的价格,截至 2018 年 8 月。
斯坦福大学发布了深度学习和推理的基准套装 DAWNBench。你可以在上面找到不同的任务、模型、计算平台以及各自的基准结果的组合。
DAWNBench:https://dawn.cs.stanford.edu/benchmark/
在 DAWNBench 比赛于 2018 年 4 月结束的时候,非 TPU 处理器的最低训练成本是 72.40 美元(使用现场实例训练 ResNet-50 达到 93% 准确率)。而使用 Cloud TPU v2 抢占式计价,你可以在 12.87 美元的价格完成相同的训练结果。这仅相当于非 TPU 的不到 1/5 的成本。这正是神经网络领域特定架构的威力之所在。
[科普] CPU, GPU, TPU的区别的更多相关文章
- CPU/GPU/TPU/NPU...XPU都是什么意思?
CPU/GPU/TPU/NPU...XPU都是什么意思? 现在这年代,技术日新月异,物联网.人工智能.深度学习等概念遍地开花,各类芯片名词GPU, TPU, NPU,DPU层出不穷......都是什么 ...
- 处理器 趣事 CPU/GPU/TPU/DPU/BPU
有消息称,阿里巴巴达摩院正在研发一款神经网络芯片——Ali-NPU,主要运用于图像视频分析.机器学习等AI推理计算.按照设计,这款芯片性能将是目前市面上主流CPU.GPU架构AI芯片的10倍,而制造成 ...
- 浅谈CPU,GPU,TPU,DPU,NPU,BPU
https://www.sohu.com/a/191538165_777155 A12宣传的每秒5万亿次运算,用计算机语言描述就是5Tops. 麒麟970 NPU,根据资料是 1.92Tops. 麒麟 ...
- 1.2CPU和GPU的设计区别
CPU和GPU之所以大不相同,是由于其设计目标的不同,它们分别针对了两种不同的应用场景.CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理.这些都使得C ...
- Cpu Gpu 内存 显存 数据流
[精]从CPU架构和技术的演变看GPU未来发展 http://www.pcpop.com/doc/0/521/521832_all.shtml 显存与纹理内存详解 http://blog.csdn.n ...
- Raspberry Pi B+ 定时向物联网yeelink上传CPU GPU温度
Raspberry Pi B+ 定时向物联网yeelink上传CPU GPU温度 硬件平台: Raspberry Pi B+ 软件平台: Raspberry 系统与前期安装请参见:树莓派(Ros ...
- 读书笔记:7个示例科普CPU Cache
本文转自陈皓老师的个人博客酷壳:http://coolshell.cn/articles/10249.html 7个示例科普CPU Cache (感谢网友 @我的上铺叫路遥 翻译投稿) CPU cac ...
- 舌尖上的硬件:CPU/GPU芯片制造解析(高清)(组图)
一沙一世界,一树一菩提,我们这个世界的深邃全部蕴藏于一个个普通的平凡当中.小小的厨房所容纳的不仅仅是人们对味道的情感,更有推动整个世界前进的动力.要想理解我们的世界,有的时候只需要细细品味一下我们所喜 ...
- [转帖]双剑合璧:CPU+GPU异构计算完全解析
引用自:http://tech.sina.com.cn/mobile/n/2011-06-20/18371792199.shtml 这篇文章写的深入浅出,把异构计算的思想和行业趋势描述的非常清楚,难得 ...
随机推荐
- 史上最全的MySQL高性能优化实战总结!
1.1 前言 MySQL对于很多Linux从业者而言,是一个非常棘手的问题,多数情况都是因为对数据库出现问题的情况和处理思路不清晰.在进行MySQL的优化之前必须要了解的就是MySQL的查询过程,很多 ...
- gRPC 和 C#
前些天gRPC 发布1.0 版本,代表着gRPC 已经正式进入稳定阶段. 今天我们就来学习gRPC C# .而且目前也已经支持.NET Core 可以实现完美跨平台. 传统的.NET 可以通过Mono ...
- golang(10):web开发 & 连接数据库
http编程 ) Go原生支持 http : import ("net/http") ) Go 的 http 服务性能和 nginx 比较接近 ) 几行代码就可以实现一个 web ...
- httpclient 多附件上传
多附件上传实例: /** * 多附件上传 * @param host * @param uri * @param attachment 附件 * @param param body参数 * @retu ...
- MongoDB学习笔记,基础+增删改查+索引+聚合...
一 基础了解 对应关系 -> https://docs.mongodb.com/manual/reference/sql-comparison/ database -> database ...
- Java注解【五、注解实战】
需求: 1.表:用户ID,用户名,年龄,邮箱. 2.实现方法,传入实体,打印sql. 实现: 1.表: package Annotation; @Table("user") pub ...
- Win7系统打开防火墙出现0x6D9错误的解决方法
防火墙是Windows系统内的一道屏障,开启防火墙可以对系统起到一定的保护作用,可以说非常重要.但是有些Win7系统用户在开启防火墙时会被系统提示出现0x6D9的错误代码,从而不能打开防火墙. 当我们 ...
- kubernetes资源清单之Deployment
Deployment为Pod和ReplicaSets提供声明性更新 示例 --- apiVersion: apps/v1 kind: Deployment metadata: name: de ...
- 【C/C++】内存对齐规则和实战
内存对齐规则和实战 这篇文章是我的平时的一个笔记修改后来的.这里主要介绍一下内存对齐的规则,以及提供一些实战一下.几篇我觉得比较好的详细的介绍内存对齐的作用什么的博文会在文末附上. 规则 在开始实战前 ...
- 2.2.EJB_Bean
1.EJB中的三种Bean 1.会话bean(sessionbean) 负责与客户端交互.是编写业务逻辑的地方.在会话Bean中可以通过jdbc直接操作数据厍.但大多数情况下都是通过实体bean来完 ...