【零基础】神经网络优化之Adam
一、序言
Adam是神经网络优化的另一种方法,有点类似上一篇中的“动量梯度下降”,实际上是先提出了RMSprop(类似动量梯度下降的优化算法),而后结合RMSprop和动量梯度下降整出了Adam,所以这里我们先由动量梯度下降引申出RMSprop,最后再介绍Adam。不过,由于RMSprop、Adam什么的,真的太难理解了,我就只说实现不说原理了。
二、RMSprop
先回顾一下动量梯度下降中的“指数加权平均”公式:
vDW1 = beta*vDW0 + (1-beta)*dw1
vDb1 = beta*vDb0 + (1-beta)*db1
动量梯度下降:
W = W - learning_rate*vDW
b = b - learning_rate*vDb
简而言之就是在更新W和b时不使用dw和db,而是使用其“指数加权平均”的值。
RMSprop只是做了一点微小的改变,为了便于区分将v改成s:
sDW1= beta*sDW0 + (1-beta)*dw1^2
sDb1 = beta*sDb0 + (1-beta)*db1^2
RMSprop梯度下降,其中sqrt是开平方根的意思:
W = W - learning_rate*(dw/sqrt(sDW))
b = b - learning_rate*(db/sqrt(sDb))
需要注意的是,无论是dw^2还是sqrt(sDW)都是矩阵内部元素的平方或开根。
三、Adam
Adam是结合动量梯度下降和RMSprop的混合体,先按动量梯度下降算出vDW、vDb
vDW1 = betaV*vDW0 + (1-beta)*dw1
vDb1 = betaV*vDb0 + (1-beta)*db1
然后按RMSprop算出sDW、sDb:
sDW1= betaS*sDW0 + (1-beta)*dw1^2
sDb1 = betaS*sDb0 + (1-beta)*db1^2
最后Adam的梯度下降是结合了v和s:
W = W - learning_rate*( vDW/sqrt(sDW) )
b = b - learning_rate*( vDb/sqrt(sDb) )
我们来看下最终实现后的效果:
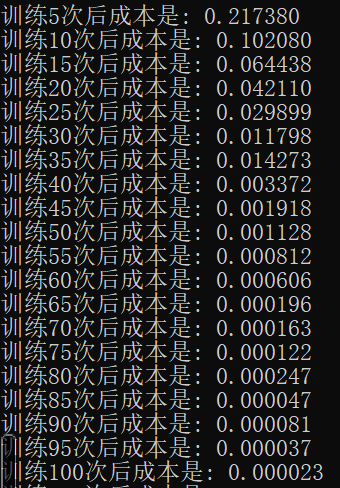
是的,你没有看错。。。只需要100次训练,就比以前2000次训练的效果还要好!看到这个结果其实我也很震惊,反复查了几遍。
不过使用Adam优化后的神经网络一定要注意learning_rate的设置,我这里改成了0.01(之前一直是0.1,多次试错后才发现是这个问题)否则会发生梯度消失(表现为dw等于0)。
四、回顾
本篇是在mini_batch的基础上,结合动量梯度下降、RMSprop做的Adam梯度下降,其目的与mini_batch、动量梯度下降一样,都是使神经网络可以更快找到最优解,不得不说Adam实在太给力了。完整的实现代码请关注公众号“零基础爱学习”回复“AI13”获取。

【零基础】神经网络优化之Adam的更多相关文章
- 【零基础】神经网络优化之mini-batch
一.前言 回顾一下前面讲过的两种解决过拟合的方法: 1)L0.L1.L2:在向前传播.反向传播后面加个小尾巴 2)dropout:训练时随机“删除”一部分神经元 本篇要介绍的优化方法叫mini-bat ...
- 【零基础】神经网络优化之dropout和梯度校验
一.序言 dropout和L1.L2一样是一种解决过拟合的方法,梯度检验则是一种检验“反向传播”计算是否准确的方法,这里合并简单讲述,并在文末提供完整示例代码,代码中还包含了之前L2的示例,全都是在“ ...
- 【零基础】神经网络优化之L1、L2
一.序言 前面的文章中,我们逐步从单神经元.浅层网络到深层网络,并且大概搞懂了“向前传播”和“反向传播”的原理,比较而言深层网络做“手写数字”识别已经游刃有余了,但神经网络还存在很多问题,比如最常见的 ...
- 神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
最近回顾神经网络的知识,简单做一些整理,归档一下神经网络优化算法的知识.关于神经网络的优化,吴恩达的深度学习课程讲解得非常通俗易懂,有需要的可以去学习一下,本人只是对课程知识点做一个总结.吴恩达的深度 ...
- 狗屁不通的“视频专辑:零基础学习C语言(小甲鱼版)”(2)
前文链接:狗屁不通的“视频专辑:零基础学习C语言(小甲鱼版)”(1) 小甲鱼在很多情况下是跟着谭浩强鹦鹉学舌,所以谭浩强书中的很多错误他又重复了一次.这样,加上他自己的错误,错谬之处难以胜数. 由于拙 ...
- IM开发者的零基础通信技术入门(二):通信交换技术的百年发展史(下)
1.系列文章引言 1.1 适合谁来阅读? 本系列文章尽量使用最浅显易懂的文字.图片来组织内容,力求通信技术零基础的人群也能看懂.但个人建议,至少稍微了解过网络通信方面的知识后再看,会更有收获.如果您大 ...
- IM开发者的零基础通信技术入门(一):通信交换技术的百年发展史(上)
[来源申明]本文原文来自:微信公众号“鲜枣课堂”,官方网站:xzclass.com,原题为:<通信交换的百年沧桑(上)>,本文引用时已征得原作者同意.为了更好的内容呈现,即时通讯网在收录时 ...
- IM开发者的零基础通信技术入门(三):国人通信方式的百年变迁
[来源申明]本文原文来自:微信公众号“鲜枣课堂”,官方网站:xzclass.com,原题为:<中国通信的百年沉浮>,本文引用时已征得原作者同意.为了更好的内容呈现,即时通讯网在收录时内容有 ...
- 【零基础】使用Tensorflow实现神经网络
一.序言 前面已经逐步从单神经元慢慢“爬”到了神经网络并把常见的优化都逐个解析了,再往前走就是一些实际应用问题,所以在开始实际应用之前还得把“框架”翻出来,因为后面要做的工作需要我们将精力集中在业务而 ...
随机推荐
- 安装HANA Rules Framework(HRF)
1. 收集文档 1.1 SAP HANA Rules Framework by the SAP HANA Academy link 1.2 HANA Rules Framework (HRF) b ...
- java保证多线程的执行顺序
1. java多线程环境中,如何保证多个线程按指定的顺序执行呢? 1.1 通过thread的join方法保证多线程的顺序执行, wait是让主线程等待 比如一个main方法里面先后运行thread1, ...
- SAP Marketing Cloud功能简述(三) 营销活动内容设计和产品推荐
Grace的前两篇文章: SAP Marketing Cloud功能简述(一) : Contacts和Profiles SAP Marketing Cloud功能简述(二) : Target Grou ...
- js中的深复制与浅复制
前言 所谓深复制与浅复制(深拷贝与浅拷贝),乍一听感觉听高大上,像是一个非常难理解的概念,其实我们平常项目开发都是在用的,只是你可能不知道该怎么叫它的名字而已,就像你听熟了一首歌,就是不知道这首歌叫什 ...
- 删除MRP单据
select *into newtable from a_mplist 把a_mplist的表中的数据复制到newtable表中结构也是一样的 insert into newtable select ...
- DMA和通道的区别
转:https://wenku.baidu.com/view/7987ae5283c4bb4cf7ecd18e.html
- 说说客户端访问一个链接URL的全过程
讲讲登录权限是如何控制的 我们可以把这个过程类比成一个电话对话的过程.当我们要打电话给某个人,首先要知道对方的电话号码,然后进行拨号.打通电话后我们会进行对话,当然要对话肯定需要共同的语言,如果一 ...
- 【清北学堂】广州OI学习游记
\(Day~0\) 早上\(9\)点多才爬起来,然后水了道题. 下午从[数据删除]出发,颠簸了将近\(5\)个小时终于抵达广州. 一出地铁站--卧槽这天,卧槽这风,要下雨的节奏? 没过两分钟倾盆大雨. ...
- 【转】Senior Data Structure · 浅谈线段树(Segment Tree)
本文章转自洛谷 原作者: _皎月半洒花 一.简介线段树 ps: _此处以询问区间和为例.实际上线段树可以处理很多符合结合律的操作.(比如说加法,a[1]+a[2]+a[3]+a[4]=(a[1]+a[ ...
- JS中map、some、every、filter方法
简介 every()方法用于检测数组中所有元素是否都符合指定条件,若符合返回true,否则返回false:不会对空数组进行检测,不会改变原来的数组. some()方法用于检测数组中的元素是否有满足指定 ...