Mysql主从分离介绍及实现
参考:
http://www.cnblogs.com/panxuejun/p/5887118.html
https://www.cnblogs.com/alvin_xp/p/4162249.html
https://blog.51cto.com/13555423/2068071
一.什么是Mysql主从分离
将读操作和写操作分离到不同的数据库上,避免主服务器出现性能瓶颈;主服务器进行写操作时,不影响查询应用服务器的查询性能,降低阻塞,提高并发; 数据拥有多个容灾副本,提高数据安全性,同时当主服务器故障时,可立即切换到其他服务器,提高系统可用性;
二.为什么要实现Mysql主从分离
大型网站为了软解大量的并发访问,除了在网站实现分布式负载均衡,远远不够。到了数据业务层、数据访问层,如果还是传统的数据结构,或者只是单单靠一台服务器扛,如此多的数据库连接操作,数据库必然会崩溃,数据丢失的话,后果更是 不堪设想。这时候,我们会考虑如何减少数据库的联接,一方面采用优秀的代码框架,进行代码的优化,采用优秀的数据缓存技术如:memcached,如果资金丰厚的话,必然会想到假设服务器群,来分担主数据库的压力。
三.主从分离原理
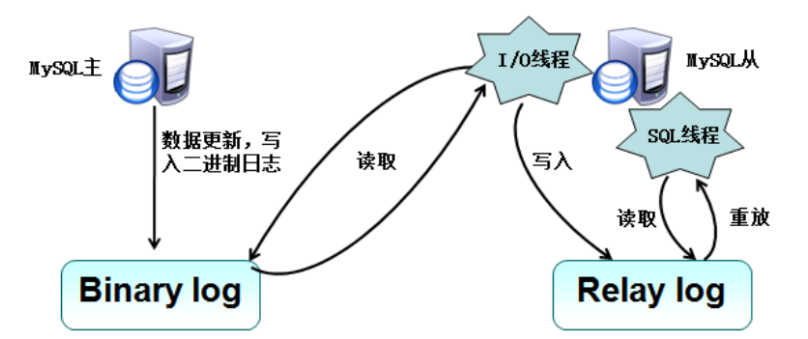
1.第一步:Master(主服务器)将操作记录到binary log(二进制日志文件当中)【即每个事务更新数据完成之前先把操作记录在日志文件中,Mysql将事务串行的写入二进制日志文件中】,写入日志文件完成之后,Master通知存储引擎提交事务(注:对数据的操作成为一次二进制的日志事件【binary log event】);
2.第二步:slave(从服务器)把binary log拷贝到relay log(中介日志)【相当于缓存作用,存储在从服务器的缓存中】,首先slave会开始一个工作线程(I/O线程),I/O线程会在Master上打开一个普通的连接,然后读取binary log事件,如果已经跟上master,就会睡眠,并等待Master产生新的事件,I/O线程将读取的这些事件写入到relay log;
3.第三步:slave从做中介日志事件(relay log),sql线程读取relay log事件并执行更新从服务器上的数据,使其与Master上的数据一致。
总结:主服务器把操作记录到binary log——>从服务器将binary log中的数据同步到relay log(中介日志中)——>从服务器读取中介日志执行同步数据
四.数据库主从配置
注:可以是一主一从,一主多从,主从从等。
我这里配置一主一从,自己有一台服务器,又借了室友一台服务器准备试试。
1.两个服务器:
1.1配置主服务器(Master):
打开binary log,配置mysql配置文件:
(1)vim /etc/my.cnf(编辑服务器上的mysql配置文件,一般都存储在这儿,如果没有可以根据自己的配置文件):

(2)配置打开binary log:
[mysqld]
#红色的为新配置的打开binary log的配置
#配置binary log
#配置server-id
server-id=1
#打开二进制日志文件
log-bin=master-bin
#打开二进制日志文件索引
log-bin-index=master-bin.index
character_set_server=utf8
init_connect='SET NAMES utf8'
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
# Settings user and group are ignored when systemd is used.
# If you need to run mysqld under a different user or group,
# customize your systemd unit file for mariadb according to the
# instructions in http://fedoraproject.org/wiki/Systemd [mysqld_safe]
log-error=/var/log/mariadb/mariadb.log
pid-file=/var/run/mariadb/mariadb.pid

(3)重启mysql加载配置文件:service mysqld restart或者(etc/init.d/mysql stop 然后etc/init.d/mysql start)
注:如果用的是MariaDB,会发生如下错误(Failed to start mysql.server.service: Unit not found.)则需要用systemctl restart mariadb.service启动(参照:https://www.cnblogs.com/yuanchaoyong/p/9749060.html)
再注:systemctl和service是Linux服务管理的两种方式,service命令其实是去/etc/init.d目录下,去执行相关程序,systemd是Linux系统最新的初始化系统(init),作用是提高系统的启动速度,尽可能启动较少的进程,尽可能更多进程并发启动。systemd对应的进程管理命令是systemctl
systemctl命令兼容了service(即systemctl也会去/etc/init.d目录下,查看,执行相关程序),并且systemctl命令管理systemd的资源Unit(systemd的Unit放在目录/usr/lib/systemd/system(Centos)或/etc/systemd/system(Ubuntu))
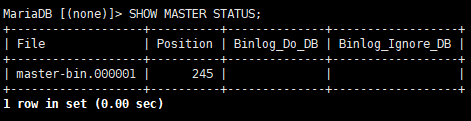
(4)SHOW MASTERT STATUS;
会查看到第一个二进制日志文件:
1.2从服务器配置:
(1)同理进入mysql配置文件:vim /etc/my.cnf:
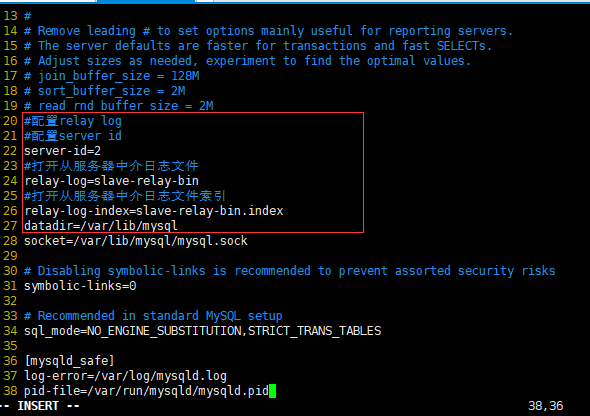
(2)配置relay log:
[mysqld]
#配置relay log
#配置server id
server-id=2
#打开从服务器中介日志文件
relay-log=slave-relay-bin
#打开从服务器中介日志文件索引
relay-log-index=slave-relay-bin.index
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock # Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0 # Recommended in standard MySQL setup
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES [mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
(3)同理,保存配置重启mysql加载配置文件生效

1.3相关连接配置:
(1)在主服务器上(Master)创建一个用于用于从服务器连接并赋予其所有数据库所有表的权限:
创建用户:create user 用户名;
赋予连接权限:GRANT REPLICATION SLAVE ON *.* TO 'repl'@'从服务器IP' IDENTIFIED BY '密码'
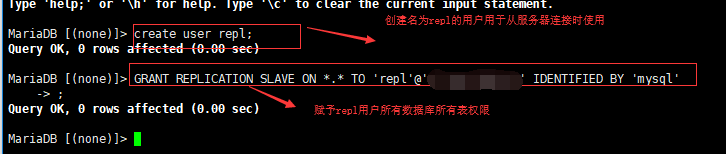
刷新:flush privileges;

(2)从服务器建立连接(使用主服务器创建的repl用户及密码):
建立连接:change master to master_host='主服务器IP',master_port=主服务器MYSQL端口,master_user='用户名',master_password='密码',master_log_file='master-bin.000001',master_log_pos=0;
读取master-bin.000001文件,即主服务器的第一个日志文件,master_log_pos的作用是如果从服务器挂掉后,只要记得这个master_log_pos的大小,然后赋值就能恢复同步在某个时刻。
开启主从跟踪:start slave;
相应得关闭主从跟踪:stop slave;

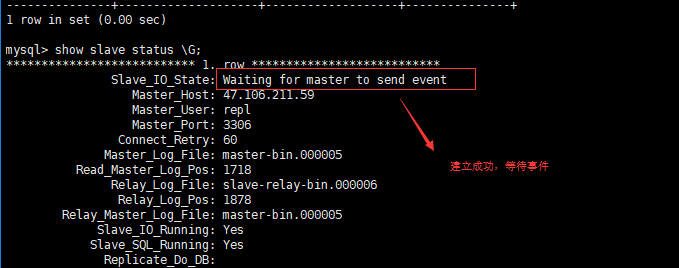
查看从服务器show slave status \G:
这里注意状态是否正确,有可能连接不正确(如主服务器配置文件种有blind-address只能指定ip访问数据库,权限未赋予正确,防火墙等等),我最后遇到的原因是阿里云服务器端口没有打开3306端口,打开即可。
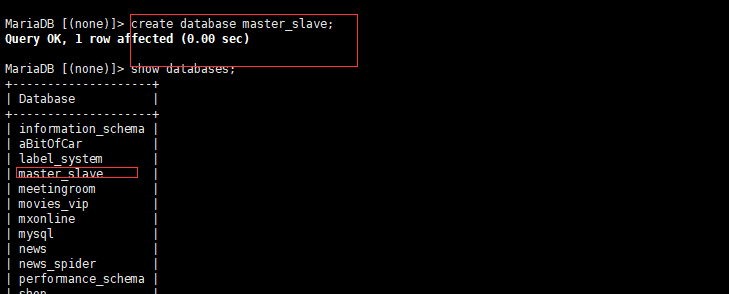
2.测试:
主服务器创建一个数据库:
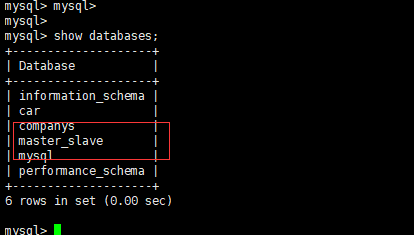
从服务器也创建成功:
五.Spring代码读写分离
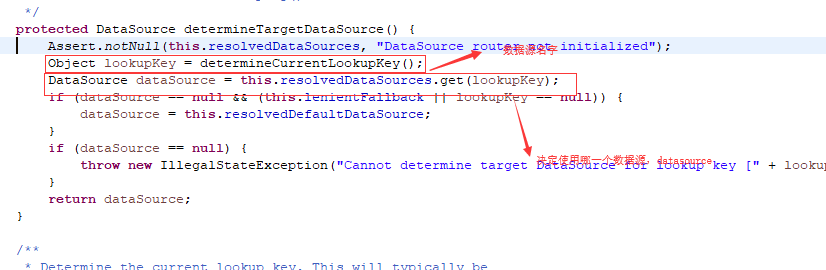
1.Spring中的AbstractRoutingDataSource(Eclipce中Ctrl+Shift+T搜索jar包)

EclipceCtrl+O查看类中所有方法及属性:查看AbstractRoutingDataSource中的determineTargetDataSource()方法:
2.相关实现:
DynamicDataSourceHolder:
package com.swpu.o2o.dao.split; import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
/**
* 继承AbstractRoutingDataSource实现抽象方法
* @author ASUS
*
*/
public class DynamicDataSource extends AbstractRoutingDataSource{ @Override
protected Object determineCurrentLookupKey() {
return DynamicDataSourceHolder.getDbType();
} }
DynamicDataSource:
package com.swpu.o2o.dao.split; import org.slf4j.Logger;
import org.slf4j.LoggerFactory; public class DynamicDataSourceHolder {
//这是日志模块
private static Logger logger = LoggerFactory.getLogger(DynamicDataSourceHolder.class);
//线程安全的ThreadLocal模式
private static ThreadLocal<String> contextHolder=new ThreadLocal<String>();
//两个key,主服务器,从服务器
private static final String DB_MASTER="master";
public static final String DB_SLAVE="slave";
/**
* 获取线程的DbType
* @return db
*/
public static String getDbType(){ String db=contextHolder.get();
//如果为空,默认为master,即支持写,也支持读
if(db==null){
db=DB_MASTER;
}
return db;
}
/**
* 设置线程的dbType
* @param str
*/
public static void setDbType(String str){
logger.debug("所使用的数据源是:"+str);
contextHolder.set(str); }
/**
* 清理连接类型
*/
public static void DbType(){
contextHolder.remove();
}
}
mybatis拦截器:拦截mybatis传递进来的sql信息,根据sql信息选择数据源,如写的数据源【master】(update,insert等),读的数据源【slave】(select)
package com.swpu.o2o.dao.split; import java.util.Locale;
import java.util.Properties; import org.apache.ibatis.executor.Executor;
import org.apache.ibatis.executor.keygen.SelectKeyGenerator;
import org.apache.ibatis.mapping.BoundSql;
import org.apache.ibatis.mapping.MappedStatement;
import org.apache.ibatis.mapping.SqlCommandType;
import org.apache.ibatis.plugin.Interceptor;
import org.apache.ibatis.plugin.Intercepts;
import org.apache.ibatis.plugin.Invocation;
import org.apache.ibatis.plugin.Plugin;
import org.apache.ibatis.plugin.Signature;
import org.apache.ibatis.session.ResultHandler;
import org.apache.ibatis.session.RowBounds;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.transaction.support.TransactionSynchronizationManager; /**
* 拦截器,实现mybatis中的Interceptor接口
*
* @author ASUS
*
*/
//指定拦截类型,mybatis会把增删改封装到update中
@Intercepts({@Signature(type=Executor.class,method="update",args={MappedStatement.class,Object.class}),
@Signature(type=Executor.class,method="query",args={MappedStatement.class,Object.class,RowBounds.class,ResultHandler.class})})
public class DynamicDataSourceInterceptor implements Interceptor {
//日志
private static Logger logger = LoggerFactory.getLogger(DynamicDataSourceInterceptor.class); // 匹配的正则表达(增删改\u0020表示空格)
private static final String REGEX = ".*insert\\u0020.*|.*delete \\u0020.*|.*update\\u0020.*"; // 主要拦截方法
@Override
public Object intercept(Invocation invocation) throws Throwable {
// 判断当前是不是事务的
boolean synchronizationActive = TransactionSynchronizationManager.isActualTransactionActive();
Object[] objects = invocation.getArgs();
MappedStatement ms = (MappedStatement) objects[0];
String lookupKey = DynamicDataSourceHolder.DB_MASTER;
if (synchronizationActive != true) {
// 是否为读方法
if (ms.getSqlCommandType().equals(SqlCommandType.SELECT)) {
// selectKey为自增id查询主键(SELECT_KEY_SUFFIX())方法,使用主库(更新)
if (ms.getId().contains(SelectKeyGenerator.SELECT_KEY_SUFFIX)) {
lookupKey = DynamicDataSourceHolder.DB_MASTER;
} else {
// 格式化sql语句
BoundSql boundsql = ms.getSqlSource().getBoundSql(objects[1]);
String sql = boundsql.getSql().toLowerCase(Locale.CHINA).replaceAll("[\\t\\n\\r]", " ");
// 使用正则匹配是否是增删改
if (sql.matches(REGEX)) {
lookupKey = DynamicDataSourceHolder.DB_MASTER; } else {
lookupKey = DynamicDataSourceHolder.DB_SLAVE;
}
}
} } else {
lookupKey = DynamicDataSourceHolder.DB_SLAVE;
}
logger.debug("设置方法[{}]use [{}] Strategy,SqlCommanType[{}]",ms.getId(),lookupKey,ms.getSqlCommandType());
return invocation.proceed();
} // 返回封装好的对象或代理对象
@Override
public Object plugin(Object target) {
// 如果是mybatis中的Executor对象(增删改查),就通过intercept()封装返回,否则直接防回
if (target instanceof Executor) {
return Plugin.wrap(target, this);
} else {
return target;
}
} // 设置相关代理,不是必备的
@Override
public void setProperties(Properties arg0) {
// TODO Auto-generated method stub } }
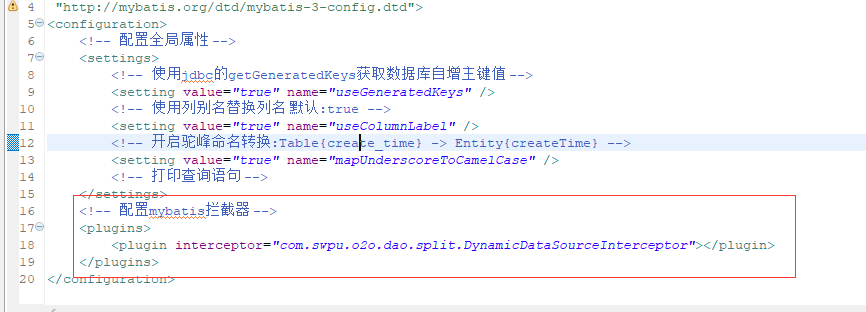
mybatis配置文件中配置拦截器:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 配置全局属性 -->
<settings>
<!-- 使用jdbc的getGeneratedKeys获取数据库自增主键值 -->
<setting value="true" name="useGeneratedKeys" />
<!-- 使用列别名替换列名 默认:true -->
<setting value="true" name="useColumnLabel" />
<!-- 开启驼峰命名转换:Table{create_time} -> Entity{createTime} -->
<setting value="true" name="mapUnderscoreToCamelCase" />
<!-- 打印查询语句 -->
</settings>
<!-- 配置mybatis拦截器 -->
17 <plugins>
18 <plugin interceptor="com.swpu.o2o.dao.split.DynamicDataSourceInterceptor"></plugin>
19 </plugins>
</configuration>
配置datasource:
mysql的相关信息(主从数据库):

datasource及动态数据源相关配置(选择不同数据源):
<bean class="com.mchange.v2.c3p0.ComboPooledDataSource" abstract="true"
destroy-method="close" id="abstractDataSource">
<!-- 配置连接池属性 -->
<property name="driverClass" value="${jdbc.driver}" />
<property name="jdbcUrl" value="${jdbc.url}" />
<property name="user" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<!-- c3p0连接池的私有属性 -->
<property name="maxPoolSize" value="30" />
<property name="minPoolSize" value="10" />
<!-- 关闭连接后不自动commit -->
<property name="autoCommitOnClose" value="false" />
<!-- 获取连接超时时间 -->
<property name="checkoutTimeout" value="10000" />
<!-- 当获取连接失败重试次数 -->
<property name="acquireRetryAttempts" value="2" />
</bean>
<!-- 主服务器数据源,继承abstractDataSource,这里主库从库密码一致 -->
<bean id="master" parent="abstractDataSource">
<property name="driverClass" value="${jdbc.driver}" />
<property name="jdbcUrl" value="${jdbc.masterurl}" />
<property name="user" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
</bean>
<!-- 从库先关信息 -->
<bean id="slave" parent="abstractDataSource">
<property name="driverClass" value="${jdbc.driver}" />
<property name="jdbcUrl" value="${jdbc.slaveurl}" />
<property name="user" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
</bean>
<!-- 配置动态数据源,targetDataSouece就是lu'you数据源锁对应的名称 -->
<bean id="dynamicDataSource" class="com.swpu.o2o.dao.split.DynamicDataSource">
<property name="targetDataSource">
<map>
<!-- value-ref和datasource名字保持一致,key和DynamicDataSourceHolder中的kookupKey保持一致 -->
<entry value-ref="master" key="master"></entry>
<entry value-ref="slave" key="slave"></entry> </map>
</property>
</bean>
<!-- 放入连接池,做懒加载 -->
<bean id="dataSource" class="org.springframework.jdbc.datasource.LazyConnectionDataSourceProxy">
<property name="targetDataSource">
<ref bean="dynamicDataSource"/></property>
</bean>
3.测试成功
六.Django实现主从分离
配置很简单:https://blog.csdn.net/linzi1994/article/details/82934612
Mysql主从分离介绍及实现的更多相关文章
- 基于MySql主从分离的代码层实现
前言 该文是基于上篇<MySQL主从分离的实现>的代码层实现,所以本文配置的主数据库和从数据库的数据源都是在上篇博文中已经介绍了的. 动态选择数据源的配置 由于我们在写数据的时候需 ...
- Atlas实现mysql主从分离
可以接受失败,无法接受放弃!加油! 一.介绍Atlas及架构图 Atlas源代码用C语言编写,它对于Web Server相当于是DB,相对于DB相当于是Client,如果把Atlas的逻辑放到Web ...
- MySQL主从分离实现
前言 大型网站为了减轻服务器处理海量的并发访问,所产生的性能问题,采用了很多解决方案,其中最主流的解决方案就是读写分离,即将读操作和写操作分别导流到不同的服务器集群执行,到了数据业务层,数据访问层 ...
- Mysql主从分离与双机热备超详细配置
一.概述 本例是在Windows环境,基于一台已经安装好的Mysql57,在本机安装第二台Mysql57服务. 读完本篇内容,你可以了解到Mysql的主从分离与双机热备的知识,以及配置期间问题的解决方 ...
- MySQL主从分离读写复制
参考教程:http://www.yii-china.com/post/detail/283.html MySQL是开源的关系型数据库系统.复制(Replication)是从一台MySQL数据库服务器( ...
- mysql主从分离
1.工具: 两台机器 master:192.168.0.1 slave:192.168.0.2 2.master的配置 找到mysql的配置文件,一般centos的是/etc/my.cnf,ubunt ...
- CentOS系统 Amoeba+MySql主从读写分离配置 适合新手傻瓜式教程!-----仅供参考!
废话不说,直接开始: 一.安装mysql的三种方式,这里采用第2种(安装方式不再详解,请参照) http://www.cnblogs.com/babywaa/articles/4837946.html ...
- Mysql主从方案的实现
Mysql主从方案介绍 mysql主从方案主要作用: 读写分离,使数据库能支撑更大的并发.在报表中尤其重要.由于部分报表sql语句非常的慢,导致锁表,影响前台服务.如果前台使用master,报表使用s ...
- Amoeba搞定mysql主从读写分离
前言:一直想找一个工具,能很好的实现mysql主从的读写分离架构,曾经试用过mysql-proxy发现lua用起来很不爽,尤其是不懂lua脚本,突然发现了Amoeba这个项目,试用了下,感觉还不错,写 ...
随机推荐
- 基于Redis的分布式锁安全性分析-转
基于Redis的分布式锁到底安全吗(上)? 2017-02-11 网上有关Redis分布式锁的文章可谓多如牛毛了,不信的话你可以拿关键词“Redis 分布式锁”随便到哪个搜索引擎上去搜索一下就知道了 ...
- VirtualBox更改虚拟硬盘 VDI文件空间大小的方法
cmd执行 C:\Oracle\VirtualBox\VBoxManage.exe modifyhd
- C++入门经典-例8.6-多重继承的构造顺序
1:单一继承是先调用基类的构造函数,然后调用派生类的构造函数,但多重继承将如何调用构造函数呢?多重继承中的基类构造函数被调用的顺序以派生表中声明的顺序为准.派生表就是多重继承定义中继承方式后面的内容, ...
- VS Code 调试 Golang 出现 Failed to continue: Check the debug console for details
VS Code断点调试Golang时候,弹出提示:Failed to continue: Check the debug console for details 点击Open launch.json, ...
- cygwin执行.py提示找不到模块,但已经安装模块的解决办法
. 在解决了cygwin中make命令不能使用的问题之后(https://www.cnblogs.com/zhenggege/p/10724122.html),make maskrcnn路径下的set ...
- yarn application命令介绍
yarn application 1.-list 列出所有 application 信息 示例:yarn application -list 2.-appStates <Stat ...
- Nginx服务应用
虚拟主机 基于域名的虚拟主机 所谓基于域名的虚拟主机,意思就是通过不同的域名区分不同的虚拟主机,基于域名的虚拟主机是企业应用最广的虚拟主机类型,几乎所有对外提供服务的网站都是使用基于域名的虚拟主机 基 ...
- openLdap安装教程
环境 操作系统:centOS 7.0 OpenLDAP:2.4.X 安装 从yum源安装 yum install openldap openldap-servers openldap-clients ...
- 卷积的三种模式:full、same、valid + 卷积输出size的计算
转自https://blog.csdn.net/u012370185/article/details/95238828 通常用外部api进行卷积的时候,会面临mode选择. 这三种mode的不同点:对 ...
- app测试自动化操作方法之三
首先导包: from appium.webdriver.common.touch_action import TouchAction #(导包指针定位滑动手势密码那个) #设置手势密码(前提是在设备上 ...