论文阅读 | Combating Adversarial Misspellings with Robust Word Recognition
对抗防御可以从语义消歧这个角度来做,不同的模型,后备模型什么的,我觉得是有道理的,和解决未登录词的方式是类似的,毕竟文本方面的对抗常常是修改为UNK来发生错误的。怎么使用backgroud model这个要实践以下。但是这个主要还是指word-level的,不知道其他的有没有用。
用强大的单词识别能力对抗对抗性拼写错误
摘要
摘要为了克服对抗性拼写错误,我们建议在下游分类器前放置一个单词识别模型。我们的单词识别模型建立在RNN半字符结构的基础上,引入了一些新的后退策略来处理罕见和未见的单词(backoff srategies -> 未登录词)。经过训练,我们能够识别由随机添加、删除、交换和键盘错误打断的单词,与普通的半字符模型相比,我们的方法实现了32%的相对(和3.3%的绝对)错误减少。尤其是,我们的管道对下游分类器提供了健壮性,比对抗训练和现成的拼写检查器都好。与用于分析的BERT模型相比,一个反向选择的字符攻击的准确率从90.3%降到45.8%。我们的防御将准确率恢复到75%。令人惊讶的是,更好的单词识别并不总是意味着更强的鲁棒性。我们的分析表明,鲁棒性还取决于我们表示为灵敏度的数量。
1 介绍
尽管深度学习技术在不同监督学习任务上取得了快速进展,但这些模型对于数据分布的细微变化仍然很脆弱。即使允许的变化仅限于几乎察觉不到的扰动,训练健壮的模型仍然是一个开放的挑战。在发现难以察觉的攻击可能导致图像识别模型错误地将示例进行分类 (Szegedy et al., 2013)之后,出现了一个名副其实的子领域,作者在其中迭代地提出攻击和对策。
在本文中,我们关注在文本分类上下文中逆向选择的拼写错误,解决以下攻击类型:删除、添加和交换单词中的内部字符。这些干扰的灵感来自心理语言学研究(Rawlinson, 1976: Matt Davis, 2003),该研究表明,如果每个单词的首字母和尾字母保持不变,人类可以理解由混乱的内部字符字符改变的文本。
首先,在处理BiLSTM和经过微调的BERT模型的实验中,包括四种不同的输入格式:word-only、char-only, word+char和word-piece (Wu et al., 2016),我们证明了对手可以将分类器的性能降低到随机猜测的水平。这只需要修改每句话的两个字符。这样的修改可能会将单词翻转到词汇表中的另一个单词,或者更常见的情况是,将词汇表外的单词翻转到token UNK。因此,对抗性编辑可以通过将提供信息的词转换为UNK来对word level model进行性能降低。直观地说,人们可能会怀疑单词片段和字符级模型(word-piece character-level) 不太容易受到拼写攻击,因为它们可以使用剩余单词文本。然而,我们的实验表明,字符和单词块模型(以上两个)实际上更脆弱。我们证明这是由于对抗样本的有能力对这些模型进行更细粒度的操作。而对一个字级模型,对手大多被限制为UNK-ing words,对一个word-piece or character-level 模型,每个字级add, drop或swap生成远程输入,为对手提供更大的选项集。
UNK是Unknown Words的简称,在用seq2seq解决问题上经常出现。
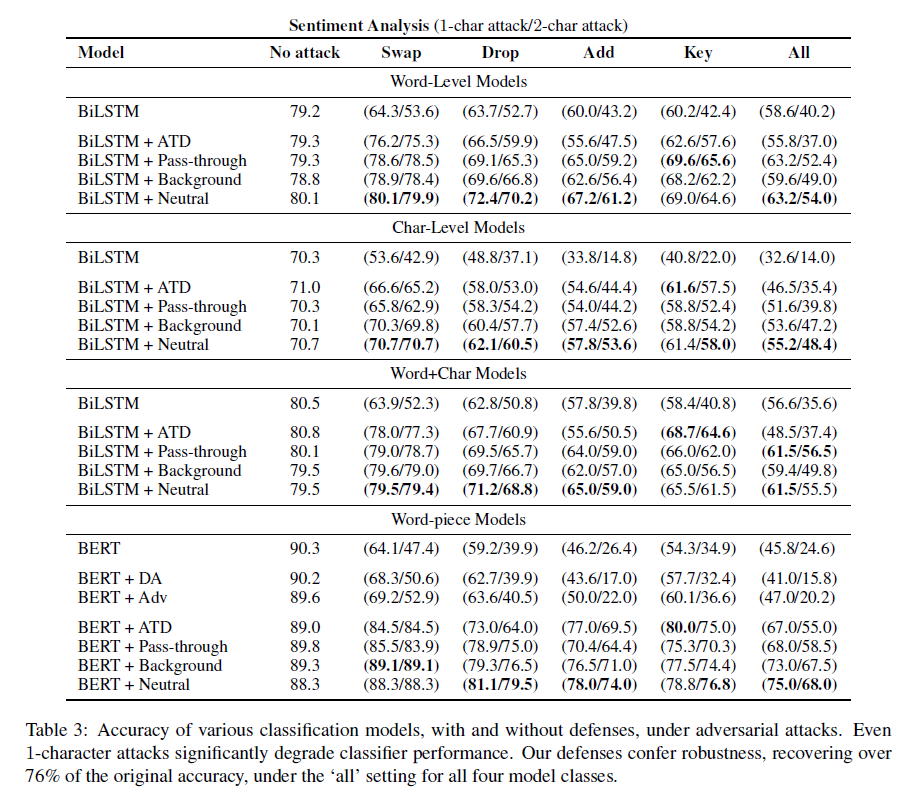
第二,我们评价一线技术包括数据扩充和敌对抗性训练,证明他们只提供微小的效益,例如,伯特模型实现精度90.3情绪分类任务,由adversarially-chosen退化到64.1 1角色互换的句子,只能恢复到69.2的对抗训练。
第三(我们的主要贡献),我们提出了一种与任务无关的防御方法,附加一个单词识别模型,该模型预测给定完整序列(可能拼写错误)输入的句子中的每个单词。单词识别模型的输出形成对下游分类模型的输入。Sakaguchi等人(2017)在基于rnnbased的半字符单词识别模型的基础上建立了我们的单词识别模型。虽然我们的单词识别器是从手头的任务中针对特定领域的文本进行训练的,但由于特定领域的词汇量很小,它们常常在测试时预测UNK。为了处理未观察到的和罕见的单词,我们提出了几种后退策略,包括退回到训练在更大语料库上的通用单词识别器。结合我们的防御,伯特模型受到1个字符的攻击恢复到88.3。81.1、78.0准确率分别为交换、删除、添加攻击。
第四,我们提供了一个详细的定性分析,表明一个低错误率是不够一个单词识别器提高下游任务的鲁棒性。此外,我们发现识别模型为攻击者提供很少的自由度是很重要的。我们提供了一个度量标准(sensiticity)来量化识别模型,并研究其对稳健性的经验。灵敏度低、错误率低的模型鲁棒性最强。
2 相关工作
NLP对抗攻击:文本变化可察觉;结尾添加干扰句;用同近义词代替单词;但常常是语法错误的。
字符级别的gradient-based方法攻击分类器和翻译系统。
我们的重点是改善最坏情况下的性能。
合成和自然噪声如何影响字符级机器翻译。他们认为结构不变表示和对抗性训练是对这种噪声的防御。在此,我们证明了一个辅助的字识别模型,它可以训练对未标记的数据,提供了一个强大的防御。
拼写纠正(Kukich, 1992)常被视为语法错误纠正的子任务。经典方法依赖于源语言模型和噪声信道模型来寻找给定单词的最可能相关项。最近,神经技术被应用到任务中(Sakaguchi et al., 2017 Li et al., 2018),该任务同时对输入的上下文和或图形进行建模。我们的工作扩展了Sakaguchi等人(2017)的ScRNN模型。
3 鲁棒词识别
处理字符级对手的攻击,我们介绍一个简单的两级解决方案,在下游分类器(C)前应用一个词识别模型(W)。在这个计划下,所有输入通过组合模型C · W 进行分类.这个模块化方法,W和C单独训练,提供了许多好处:(i)我们可以部署多个下游分类任务的同一个词识别模型/模型;(二)利用较大的未标注语料库训练单词识别模型。针对对抗性错误,两个重要因素决定了该组合模型的鲁棒性:识别拼写错误的准确性和对同一输入上对抗性干扰的敏感性。我们将在下面详细讨论这些方面。
下面,当ScRNN预测到UNK(罕见和不可见单词的常见结果)时,我们探索了不同的后退方法:
传递:单词识别器按原样传递(可能拼错了)单词。
退到中性词:alternative。注意,通过未更改的传递unk预测的单词会将下游模型暴露给可能损坏的文本,因此我们考虑使用像“a”这样的中性单词。在类之间也有类似的分布。
后退到背景模型:我们还考虑,当前地面单词识别模型预测UNK时,使用更大的、较少专门化的语料库训练更通用的单词识别模型。图1以图的方式描述了这个场景。
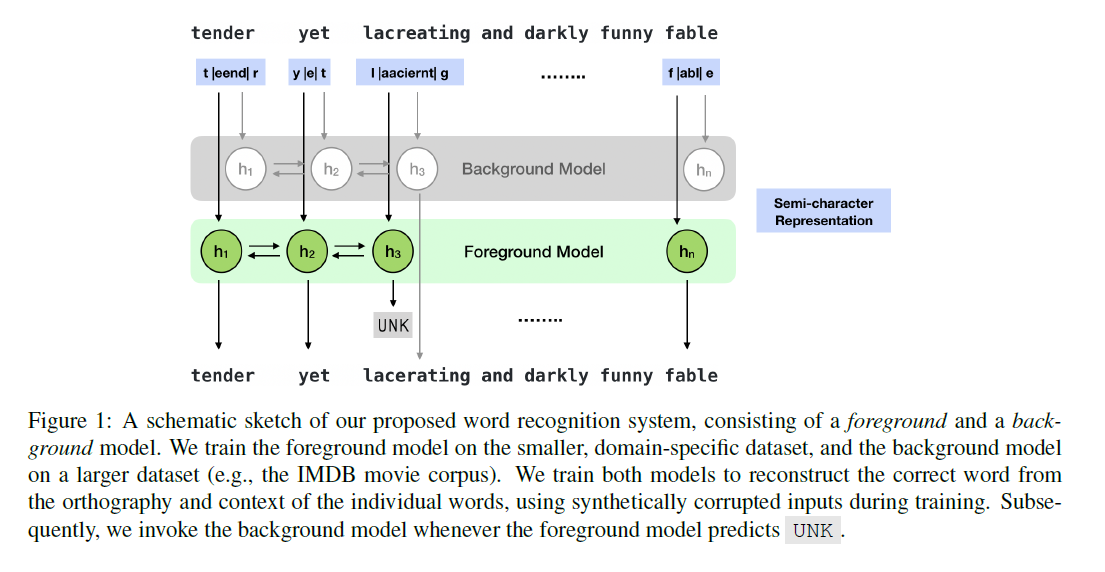
根据经验,我们发现背景模型(本身)不太准确,因为它被训练来预测大量的单词。因此。最好是在一个域内语料库上训练一个精确的前景模型,并将重点放在频繁出现的单词上,然后对罕见和未观察到的单词使用一个通用的背景模型。接下来,我们描述了构建鲁棒的单词识别器的第二个考虑因素。
模型敏感度
如果模型可以降低一些对样本的小变化的敏感度,可以在一定程度上抵御对抗攻击。
我们可以将单词识别系统W的这个概念定义为它分配给一组对抗性扰动的唯一输出的期望数量。给定集合中的一个句子s,令a (s) = s1', s2',…, Sn’表示攻击类型A下的n个扰动集合,设V为将字符串映射到下游分类器的输入表示形式的函数。对于单词级模型,V将句子转换为单词ID序列,将OOV单词映射到相同的UNK ID。而对于char(或word+char, word-piece)模型,V将输入映射到字符ID序列。在形式上,敏感性被定义为
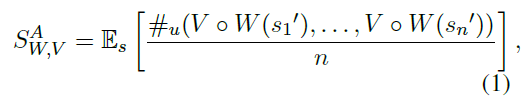
其中Vo W(s)为单词识别器,W使用si和#u生成的输出字符串返回(下游分类器的)输入表示,计算惟一参数的数量。直观上,我们认为SWv值越高,下游classifier的鲁棒性越低,因为对手攻击分类器的自由度越大。因此,在使用文字识别作为一种防御手段时,明智的做法是设计一个低灵敏度、低错误率的系统。然而,正如我们将要演示的,在敏感性和错误率之间常常存在权衡。
综合对抗性
攻击:S→假设我们有一个分类器C该分类器的一个对手是一个函数a,该函数将一个参数s映射到它的扰动版本{s, s2,…s}使得每个s‘,在句子之间距离的概念下,都接近s。我们将分类器C对对手A的鲁棒性定义为:
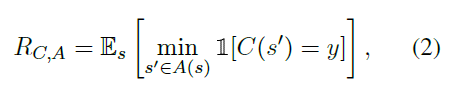
y是真实标签。RCA表示C的最坏情况下的对抗表现。
4种类型的扰动: swap drop key-board(用QWERTY键盘的相邻字符替换内部字符) add 只修改内部字符。
攻击策略:
对于i -字符攻击,我们尝试了上面列出的所有可能的干扰,直到找到一个对手翻转模型预测。对于2个字符的攻击,我们贪婪地修复了在1个字符的攻击中可信度最低的编辑,然后尝试对剩余的单词进行所有允许的干扰。可以用类似的方式执行高阶攻击。贪婪策略减少了获得高阶攻击所需的计算量,但也意味着鲁棒性得分是分类器真实鲁棒性的上限。
4 实验与结果
在本节中,我们首先讨论我们在单词识别系统上的实验。
4.1单词纠错数据
SST IMDB
我们从斯坦福情感树银行(SST)的电影评论中评估拼写纠正器,从3美元起(Socher等人)。2013)。SST数据集包含8544篇电影评论,词汇量超过16K。我们使用IMDB电影评论作为背景cor pus (Maas et al., 2011),其中包含54K篇电影评论,词汇量超过78K。这两个数据集不共享任何公共评论。拼写纠正模型是根据其纠正拼写错误的能力来评估的。测试设置由评审组成,其中每个单词(长度为24,不包括stopwords)都受到类型(来自swap、add、drop和keyboard )的攻击。在all攻击设置中,我们通过为每个单词随机选择一个来混合所有攻击 就是随机选一个攻击类型。这与真实世界的攻击设置非常相似实验设置除了我们的文字识别模型外,我们还比较了ATD (After The Deadline),一个开源的拼法纠正器。我们发现ATD是最好的免费可用的校正器。我们请读者参考Sak aguchi等人(2017)将ScRNN与其他匿名商业拼写检查器进行比较。对于ScRNN模型,我们使用了一个隐藏尺寸为50的单层Bi LSTM。输入表示由198个维度组成,是词汇表中唯一字符数(66)的三倍。我们把词汇量限制在10000个单词以内。而当我们回到背景模型时,我们使用了整个78470字的词汇库。为了训练这些网络,我们破坏了电影评论,根据将四种攻击类型中的一种应用于每个单词,并尝试通过交叉熵损失来重建原始单词。
结果
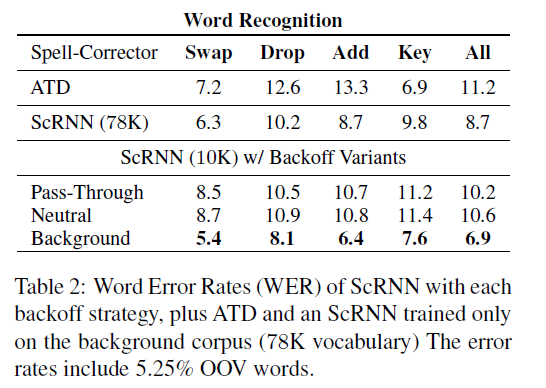
计算了不同tacks模型的单词错误率(WER),结果如表2所示。注意,ATD错误地预测了每100个单词就有11.2个单词(在“all”设置中),而ScRNN的所有回退变体都能更好地重构。最精确的变异包括后退到背景模型,导致较低的错误率6.9%。在单词识别方面表现最佳。这是32%的相对误差,与传统的ScRNN模型相比,采用了传递回退策略。测试语料库中有5.25%的单词在训练语料库中是不可见的,因此只有后退到更大的语料库中才能恢复这些单词,我们可以将性能的提高归功于这一事实。由于背景语料库中的词频分布与前景语料库中的词频分布不同,因此,仅仅在较大的背景语料库上的训练效果更差,为8.7%。
4.2 对抗攻击的鲁棒性
在情绪分类方面,我们系统地研究了字符级对抗攻击对两种体系结构和四种不同输入格式的影响。第一种体系结构将输入语句编码为一系列嵌入,然后由BiLSTM按顺序处理这些嵌入。然后,softmax层使用BiLSTM的第一和最后两个状态来预测输入的情绪。
我们考虑了该体系结构的三种输入格式:(1)仅使用单词:其中输入单词使用查找表进行编码;(2) charonly:输入的单词在其字符上使用单独的单层BiLSTM进行编码;和(3)Word+Char:其中输入单词使用(1)和(2)的连接进行编码。
第二种体系结构使用经过微调的BERT模型(Devlin et al., 2018),带有单词块标记化的输入格式。这个模型最近在几个NLP基准上设置了一个新的最先进的技术,包括我们在这里考虑的情绪分析任务。所有的模型都是在句子级的Stanford Sentiment Treebank (Socher et al., 2013)数据集的二进制版本上训练和评估的,只有正面和负面的评价。我们还考虑了意译检测的任务。在这里,我们也使用了微调伯特(Devlin et al., 2018),这是在微软研究释义语料库(MRPC)上训练和评估(多兰和布罗基特,2005)。
基线防御策略
处理对抗实例的两种常用方法包括:(1)数据增强(DA) (Krizhevsky et al., 2012);(2)对抗性训练(Adv) (Goodfellow等。2014)。在训练集的基础上,通过1个字符的编辑,增加相同数量的随机攻击实例,对训练模型进行微调。在预先训练的模型是微调与额外的adver sarial例子(随机选择),产生不正确的预测从当前状态分类器。这个过程是迭代地重复的,从更新的分类器模型生成并添加新的对抗性示例。直到开发集的对抗性精度停止提高。
The robustness of different models can be
ordered as word-only > word+char > char-only
word-piece, and the efficacy of different attacks as
add > key > drop > swap.
随着字符和单词块输入在现代NLP管道中成为com monplace,值得注意的是它们所增加的漏洞。我们建议将单词识别作为一种安全防范措施,并构建在基于rnnbased的半字符单词识别器的基础上。我们发现,当作为一种防御机制使用时,大多数交流辅助文字识别模型并不总是对对抗攻击最健壮的。此外,我们强调需要控制这些模型的灵敏度,以实现高鲁棒性。
结论
我们建议将单词识别作为一种安全防范措施,并构建在基于rnnbased的半字符单词识别器的基础上。我们发现,当作为一种防御机制使用时,大多数交流辅助文字识别模型并不总是对对抗攻击最健壮的。此外,我们强调需要控制这些模型的灵敏度,以实现高鲁棒性。
看了这个文章也没太多收获 感觉也没讲啥啊???
论文阅读 | Combating Adversarial Misspellings with Robust Word Recognition的更多相关文章
- [论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks
[论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问 ...
- [论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding
[论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding 本文结构 解决问题 主要贡献 算法原理 实验结果 参考文献 ...
- 论文阅读:Multi-task Learning for Multi-modal Emotion Recognition and Sentiment Analysis
论文标题:Multi-task Learning for Multi-modal Emotion Recognition and Sentiment Analysis 论文链接:http://arxi ...
- 论文阅读 | Tackling Adversarial Examples in QA via Answer Sentence Selection
核心思想 基于阅读理解中QA系统的样本中可能混有对抗样本的情况,在寻找答案时,首先筛选出可能包含答案的句子,再做进一步推断. 方法 Part 1 given: 段落C query Q 段落切分成句 ...
- 【论文阅读】Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks 参考 1. 人脸关键点: 2. ...
- 论文阅读 | Universal Adversarial Triggers for Attacking and Analyzing NLP
[code] [blog] 主要思想和贡献 以前,NLP中的对抗攻击一般都是针对特定输入的,那么他们对任意的输入是否有效呢? 本文搜索通用的对抗性触发器:与输入无关的令牌序列,当连接到来自数据集的任何 ...
- 论文阅读 | Real-Time Adversarial Attacks
摘要 以前的对抗攻击关注于静态输入,这些方法对流输入的目标模型并不适用.攻击者只能通过观察过去样本点在剩余样本点中添加扰动. 这篇文章提出了针对于具有流输入的机器学习模型的实时对抗攻击. 1 介绍 在 ...
- 【CV论文阅读】Dynamic image networks for action recognition
论文的重点在于后面approximation部分. 在<Rank Pooling>的论文中提到,可以通过训练RankSVM获得参数向量d,来作为视频帧序列的representation.而 ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
随机推荐
- freemarker 生成word
一.生成模板,动态获取的部分用${变量名},然后将word另存为xml文件,再将后缀名改成ftl格式.然后将模板放在对应的目录下. 二.引入freemarker包,mawen引用 <depend ...
- 处理springboot OTS parsing error: Failed to convert WOFF 2.0 font to SFNT
springboot项目中添加了字体等文件后,页面无法识别,浏览器调试窗口报错如下: Failed to decode downloaded font: http://localhost:8080/f ...
- 从Ubuntu 18.04 LTS升级到Ubuntu 18.10版本的方法
从Ubuntu 18.04 LTS升级到Ubuntu 18.10版本的方法 2018-10-18 21:08:39作者:ywnz稿源:云网牛站 本文提供从Ubuntu 18.04 LTS(Bionic ...
- ETL工具-KETTLE教程专栏1----术语和定义
1-资源库 资源库是用来保存转换任务的,用户通过图形界面创建的的转换任务可以保存在资源库中. 资源库可以使多用户共享转换任务,转换任务在资源库中是以文件夹形式分组管理的,用户可以自定义文 ...
- pymysql pymysql.err.OperationalError 1045 Access denied最简单解决办法
我使用的是python3.6+pymysql+mysql8.0 在cmd命令行直接输入mysql回车出现:ERROR 1045 (28000): Access denied for user 'ODB ...
- 20.Python类型转换,Python数据类型转换函数大全
虽然 Python 是弱类型编程语言,不需要像 Java 或 C 语言那样还要在使用变量前声明变量的类型,但在一些特定场景中,仍然需要用到类型转换. 比如说,我们想通过使用 print() 函数输出信 ...
- Java 读取模板并生成HTML静态文件实例
原理都很简单,主要是对模板的解析.so,我们先准备一个html模板mb.html,做个文件其中的###title###之类的标签用于程序进行查询替换. HTML code复制代码 <html&g ...
- Java写入的常用技巧
一.批量写入 Java写入大量数据到磁盘/数据库等其它第三方介质时,由于IO是比较耗费资源的操作,通常采用攒一批然后批量写入的模式 //通常构造一个缓存池,一个限制指标,可以是内存大小也可以是时间 B ...
- 安装指定版本的Ionic或Cordova
安装ionic 及 cordova npm install -g cordova ionic更新命令 npm update -g cordova ionic安装特定版本 npm install -g ...
- 注意机制CBAM
这是一种用于前馈卷积神经网络的简单而有效的注意模块. 给定一个中间特征图,我们的模块会沿着两个独立的维度(通道和空间)依次推断注意力图,然后将注意力图乘以输入特征图以进行自适应特征修饰. 由于CBAM ...