机器学习第一章——NFL的个人理解
第一篇博客,想给自己的学习加深记忆。看到书中第一个公式时,本来想直接看证明结果就好,然鹅。。。作者在备注上写:这里只用到一些非常基础的数学知识,只准备读第一章且有“数学恐惧”的读者可跳过。。。嘤嘤嘤,不服气,想弄明白一些。
就看到了知乎的这篇文章,算是我的启蒙文章了,感激。https://zhuanlan.zhihu.com/p/48493722
下面针对这篇文章加入自己的理解。
没有免费午餐定理是说无论两种算法 多聪明、
多笨拙,它们的期望性能竟然相同。
(1)期望性能
期望也叫均值:可以表述为有一种内在的动力趋于某种东西。简单解释:
在概率论和统计学中,一个离散性随机变量的期望值(或数学期望、或均值,亦简称期望,物理学中称为期待值)是试验中每次可能的结果乘以其结果概率的总和。换句话说,期望值像是随机试验在同样的机会下重复多次,所有那些可能状态平均的结果,便基本上等同“期望值”所期望的数。需要注意的是,期望值并不一定等同于常识中的“期望”——“期望值”也许与每一个结果都不相等。(换句话说,期望值是该变量输出值的平均数。期望值并不一定包含于变量的输出值集合里。)
例如,掷一枚公平的六面骰子,其每次“点数”的期望值是3.5,计算如下:
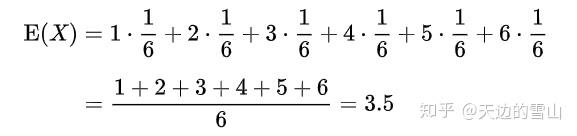
不过如上所说明的,3.5虽是“点数”的期望值,但却不属于可能结果中的任一个,没有可能掷出此点数。
(2)算法假设
NFL定理的前提是:所有问题出现的机会相同、或者说所有的问题同等重要。
没有免费的午餐定理(No Free Lunch Theorem),这个定理说明,若学习算法 ,在某些问题上比学习算法
要好, 那么必然存在另一些问题, 在这些问题中
比
表现更好。
(以下类比:La和Lb就像是两家父母,La的父母教育出来的孩子学习很好,但是Lb的父母教育出来的孩子自理能力很强)
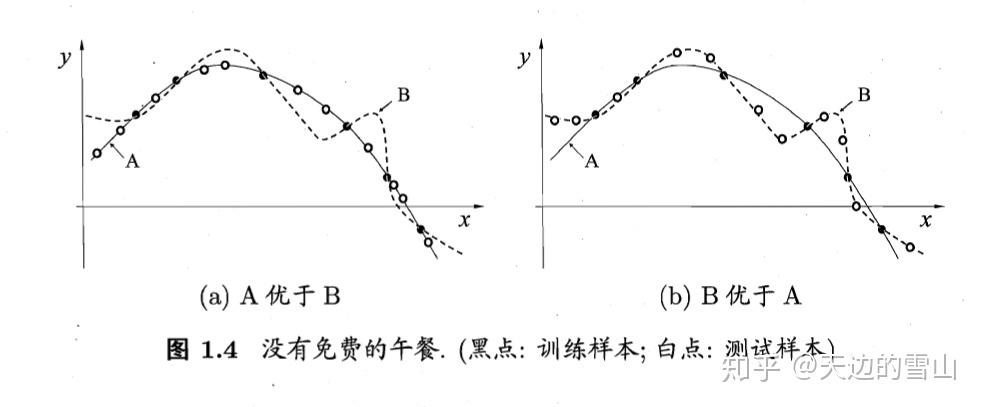
泛化能力就是:现在让两家父母用自己原来教育孩子的方法去培养其他的孩子
这里说的表现好就是前面所说的泛化能力更强。然后出现了下面这个公式
令人生畏的长公式,不过我们来依次解读它。
X : 样本空间,什么是样本空间呢?就是你的样本的属性张成的空间,书的前文有介绍
还是以他书中的西瓜来举例吧:
西瓜的属性和每个属性的取值是
色泽= 青绿||乌黑||浅白 x= 0 || 1 || 2
根蒂= 蜷缩||稍蜷||硬挺 y= 0 || 1 || 2
敲声= 浊响||沉闷||清脆 z= 0 || 1 || 2
你把色泽、根蒂、敲声想想成x,y,z轴。取值的范围都是0,1,2。怎么样,是不是像一个正方体的三维空间,当然属性可能有多种,那就上升到多维空间去了,不好想像了。
H:假设空间,什么是假设空间呢?
什么是假设呢,前面说也叫学得模型,这里我们不搞那些概念。请看这篇博主的文章http://blog.csdn.net/VictoriaW/article/details/77686168,看完应该就能理解假设空间和版本空间)
假设空间就是指La父母,可能把孩子培养成警察、程序员、宇航员、服务员、白富美、傻白甜。。。这些组成假设空间
但是呢根据传统的定义,只有宇航员和程序员才可以成为祖国的栋梁,这里版本空间就是祖国的栋梁定义下的组成
:学习算法,学习算法有其偏好性,对于相同的训练数据,不同的学习算法可以产生不同的假设,学得不同的模型,因此才会有那个学习算法对于具体问题更好的问题,这里这个没有免费的午餐定理要证明的就是:若对于某些问题算法
学得的模型更好,那么必然存在另一些问题,这里算法
学得的模型更好。这里的好坏在下文中使用算法对于所有样本的总误差表示(就是相同的孩子给不同的父母培养,可能产生不同的结果)
P(h|X, ): 算法La基于训练数据X产生假设h的概率(就是La父母训练完自己的孩子成为警察之后,开始训练别的孩子(X)了,P就是别的孩子在La父母的训练下成为警察的概率)
这里我说一下自己的理解,既然是 基于X产生假设h的概率,那么就说明假设不止一个(你说这不是废话吗?上面都说有假设空间了,假设当然不止一个),这里要注意的是这里的假设是一个映射,是y=h(x),(这个孩子变成警察算不算祖国的栋梁)是基于数据X产生的对于学习目标(判断好瓜)的预测。因数据X不一样,所以可能产生不一样的假设h,既然假设假设有可能不一样,那么对每一种假设都有其对应的概率即P(h|X,
)。而且所有假设h加起来的概率为1,这个不难理解,概率总和为1(不成为警察最后成为各种职业的人,加起来概率为1,因为每个孩子总要当一个啥)
f: 代表希望学得的真实目标函数,要注意这个函数也不是唯一的,而是存在一个函数空间,在这个空间中按某个概率分布,下文证明中采用的是均匀分布。(f就是指最后成为了是祖国的栋梁)
(训练集外误差:La父母开始上路变成职业培训父母了,Eote是他们没有成功把社会上的孩子变成警察的这一事件的期望)
首先看这个E,这个E是期望,expectation的意思,这个下标ote,是off-training error,即训练集外误差Eote( |X,f )算法
学得的假设在训练集外的所有样本上的误差的期望
P(x): 对于这个,我的理解是样本空间中的每个样本的取得概率不同,什么意思呢?拿西瓜来说,(色泽=浅白,根蒂=硬挺,敲声=清脆)的西瓜可能比(色泽=浅白,根蒂=稍蜷,敲声=沉闷)的西瓜更多,取到的概率更大。所以有P(x)这个概率。
I(h(x)≠f(x))看前面的符号表把这个叫做指示函数,这个很好理解,就像if语句括号里的表达式一样,为真就=1,为假就=0。(假就是指成功变为警察,不需要考虑了,只考虑没成功的)(与孩子本身P(x)和La的训练能力P(h|X,La)有关)
P(h|X, ): 前面说过了,再复习一下,算法
基于训练集X产生假设h的概率。
好了,公式的每一部分都说清楚了,来整体理解一下,这个公式就是说:
第一个求和符号:
: 这里的这个对假设的求和其实我也不是很理解,我的理解主要是算法对于同一个训练集会产生不同的假设,每个假设有不同的概率。(除了警察也可以是其他的职业,各种)
第二个求和符号:
:对于样本空间中每一个训练集外的数据都进行右边的运算。(训练集外的孩子)
好了,公式的每一部分都说清楚了,来整体理解一下,这个公式就是说:
对于算法 产生的每一个不同的假设h,进行训练外样本的测试,然后测试不成功(因为求的是误差)指示函数就为1,并且两个概率相乘,最后所有的结果加起来,就是该算法在训练集外产生的误差。
然后下面考虑二分类问题,先要说明,对于我们想要求得的真实目标函数 可能不止一个,这个好理解,因为满足版本空间中的假设的函数都可以是真实目标函数,然后这些不同的
有着相同的概率(均匀分布),函数空间为{0,1}{0,1},那么有多少个这种函数呢?我们来看对于同一个样本的这个预测值,对于样本空间χ中的某个样本x,如果f1(x)=0,f2(x)=1, 那么这就是两个不同的真实目标函数,所以对于某个样本可以区分出两个真实目标函数,一共有|χ|个样本,所以一共有
个真实目标函数,这些真实目标函数是等可能分布的(均匀分布),所以对于某个假设h(x)如果h(x)=0那么就有
的可能与真实目标函数相等。
所以下面来看这个公式推导

(有2|x|个1/2)概率求和为1,就是这么简单
经过这么一通推导后,发现得出期望的表达式中关于没有具体算法的,所以是算法无关的!
写给自己看的,不喜勿喷。
机器学习第一章——NFL的个人理解的更多相关文章
- Python机器学习第一章
1. 机器学习 (Machine Learning, ML) 1.1 概念:多领域交叉学科,涉及概率论.统计学.逼近论.凸分析.算法复杂度理论等多门学科.专门研究计算机怎样模拟或 ...
- Andrew Ng机器学习第一章——单变量线性回归
监督学习算法工作流程 h代表假设函数,h是一个引导x得到y的函数 如何表示h函数是监督学习的关键问题 线性回归:h函数是一个线性函数 代价函数 在线性回归问题中,常常需要解决最小化问题.代价函数常用平 ...
- Andrew Ng机器学习第一章——初识机器学习
机器学习的定义 计算机程序从经验E中学习,解决某一任务T.进行某一性能度量P,通过P测定在T上的表现因E而提高. 简而言之:程序通过多次执行之后获得学习经验,利用这些经验可以使得程序的输出结果更为理想 ...
- 顶级c程序员之路 基础篇 - 第一章 关键字的深度理解 number-1
c语言有32个关键字,每个关键字你都理解吗? 今天出场的是: auto , register, static, extern 为什么他们会一起呢,说到这里不得不谈到c语言对变量的描述. c给每 ...
- 第一章:走近java-深入理解java虚拟机-读书总结
java技术体系: 1.java程序设计语言 2.硬件平台上的java虚拟机 3.class文件格式 4.java的API类库 5.第三方的类库 JDK: java语言,虚拟机,java API类库 ...
- PRML读书会第一章 Introduction(机器学习基本概念、学习理论、模型选择、维灾等)
主讲人 常象宇 大家好,我是likrain,本来我和网神说的是我可以作为机动,大家不想讲哪里我可以试试,结果大家不想讲第一章.估计都是大神觉得第一章比较简单,所以就由我来吧.我的背景是统计与数学,稍懂 ...
- Day1 《机器学习》第一章学习笔记
<机器学习>这本书算是很好的一本了解机器学习知识的一本入门书籍吧,是南京大学周志华老师所著的鸿篇大作,很早就听闻周老师大名了,算是国内机器学习领域少数的大牛了吧,刚好研究生做这个方向相关的 ...
- 《深入理解Spark-核心思想与源码分析》(一)总体规划和第一章环境准备
<深入理解Spark 核心思想与源码分析> 耿嘉安著 本书共计486页,计划每天读书20页,计划25天完成. 2018-12-20 1-20页 凡事豫则立,不豫则废:言前定,则不跲:事 ...
- 深入理解Magento - 第一章 - Magento强大的配置系统
深入理解Magento 作者:Alan Storm翻译:zhlmmc 前言第一章 - Magento强大的配置系统第二章 - Magento请求分发与控制器第三章 - 布局,块和模板第四章 - 模型和 ...
随机推荐
- docker学习(四)
一.Docker数据管理 在容器中管理数据主要有两种方式:1.数据卷(Data volumes)2.数据卷容器(Data volume containers) 1.数据卷数据卷是一个可供一个或多个容器 ...
- KMP模板,注释
#include<bits/stdc++.h> using namespace std; queue<int> KMP(string a,string b){//a是主串,b是 ...
- xml介绍+xml创建+xml读取
1.xml介绍:(URL:https://blog.csdn.net/weixin_37861326/article/details/81082144) xml是用来传输内容的,是w3c推荐的 2.使 ...
- 数据库学习之七--视图(View)
一.定义 视图:指计算机数据库中的一个临时虚拟表,其内容由查询定义:同真实的表一样,视图包含一系列带有名称的列和行数据.但是,视图并不在数据库中以存储的数据值集形式存在. 二.优点 1. 优点: a. ...
- 搭建自己的博客(八):使用fontawesome框架来添加图标以及美化详情页
在网页中有时候会使用到图标,自己弄图标有些麻烦所以就使用了fontawesome框架. 官网: 下载地址 我使用的fontawesome版本是5.5.0版本 1.先上变化的部分
- NetworkX系列教程(10)-算法之四:拓扑排序与最大流问题
小书匠Graph图论 重头戏部分来了,写到这里我感觉得仔细认真点了,可能在NetworkX中,实现某些算法就一句话的事,但是这个算法是做什么的,用在什么地方,原理是怎么样的,不清除,所以,我决定先把图 ...
- Best free and public DNS servers of 2019
1. OpenDNSPrimary, secondary DNS servers: 208.67.222.222 and 208.67.220.220 2. CloudflarePrimary, se ...
- 使用AwesomeWM作为Mate(Gnome相同) Desktop的窗口管理器
本文通过MetaWeblog自动发布,原文及更新链接:https://extendswind.top/posts/technical/using_awesomewm_as_wm_of_mate_des ...
- SqlServer 获取 当前地址下 所有数据库字段信息 / 快速 批量插入数据库(TVPs)
SQL执行 --拼装 当前地址下 所有数据库字段信息 BEGIN DECLARE @dataBaseName NVARCHAR(MAX)--数据库名称 DECLARE @tableName NVARC ...
- Tkinter 之OptionMenu下拉选择菜单
一.代码示例 import tkinter as tk window = tk.Tk() # 设置窗口大小 winWidth = 600 winHeight = 400 # 获取屏幕分辨率 scree ...