关键词提取算法TF-IDF与TextRank
一、前言
随着互联网的发展,数据的海量增长使得文本信息的分析与处理需求日益突显,而文本处理工作中关键词提取是基础工作之一。
TF-IDF与TextRank是经典的关键词提取算法,需要掌握。
二、TF-IDF
2.1、TF-IDF通用介绍
TF-IDF,全称是 Term Frequency - inverse document frequency,由两部分组成---词频(Term Frequency),逆文档频率(inverse document frequency)。
TF-IDF=词频(TF)*逆文档频率(IDF)
词频(TF-Term Frequency),即某个词语出现的频率。
词频(TF)= 某个词在文章中的出现次数/该文章所有词的数量
一般来说某个词出现的次数多,也就说明这个词的重要性可能很高,但是不一定。例如现代汉语中的许多虚词——“的,地,得”,古汉语中的许多句尾词“之、乎、者、也、兮”,这些词在文中可能出现许多次,但是它们显然不是关键词。(这些词也称为停用词,一般我们会在处理时去掉停用词)。
例如,某个词比较少见,但是它再这篇文章中多次出现,那么它很可能就反映了这篇文章的特性正是我们所需要的关键词。这就是为什么我们在判断关键词的时候,需要第二部分(IDF)配合。
逆文档频率(inverse document frequency-IDF),反映关键词的普遍程度——当一个词越普遍(即有大量文档包含这个词)时,其IDF值越低;反之,则IDF值越高。
逆文档频率(inverse document frequency)首先计算某个词在各文档中出现的频率。假设一共有10篇文档,其中某个词A在其中10篇文章中都出先过,另一个词B只在其中3篇文中出现。请问哪一个词更关键?
词B更重要,逆文档频率,反映的是词的普通程度,这个词出现越少,越稀有,IDF值越高。
逆文档频率(IDF)=log(语料库的文档总数/包含该词的文档数+)
所以要提取一篇文章的关键词,要考虑词频和逆文档频率。
2.2、TF-IDF公式
TF-IDF(Term Frequency/Inverse Document Frequency)是信息检索领域非常重要的搜索词重要性度量;用以衡量一个关键词w对于查询(Query,可看作文档)所能提供的信息。词频(Term Frequency, TF)表示关键词w在文档Di中出现的频率:
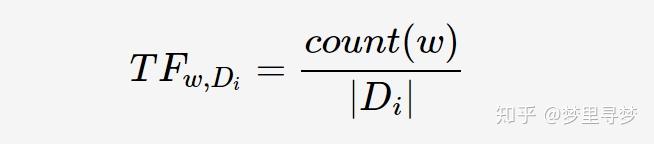
其中,count(w)为关键词w的出现次数,|Di|为文档Di中所有词的数量。逆文档频率(Inverse Document Frequency, IDF)反映关键词的普遍程度——当一个词越普遍(即有大量文档包含这个词)时,其IDF值越低;反之,则IDF值越高。IDF定义如下:
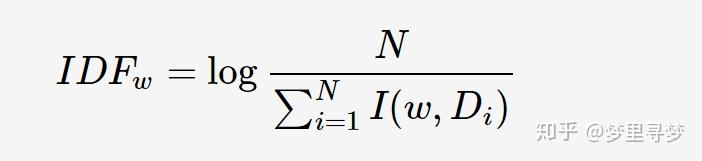
其中,N为所有的文档总数,I(w,Di)表示文档Di是否包含关键词,若包含则为1,若不包含则为0。若词w在所有文档中均未出现,则IDF公式中的分母为0;因此需要对IDF做平滑(smooth):
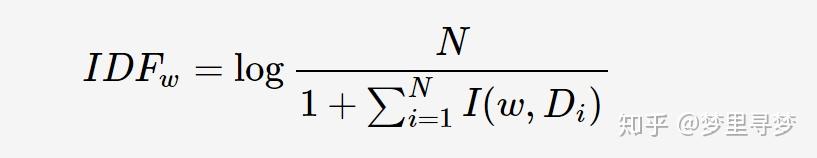
关键词w在文档Di的TF-IDF值:
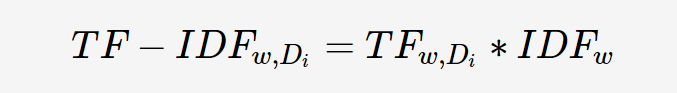
从上述定义可以看出:
- 当一个词在文档频率越高并且新鲜度高(即普遍度低),其TF-IDF值越高。
- TF-IDF兼顾词频与新鲜度,过滤一些常见词,保留能提供更多信息的重要词。
三、TextRank
3.1、TextRank通用介绍
TextRank首先会提取词汇,形成节点;然后依据词汇的关联,建立链接。
依照连接节点的多少,给每个节点赋予一个初始的权重数值。
然后就开始迭代。
根据某个词所连接所有词汇的权重,重新计算该词汇的权重,然后把重新计算的权重传递下去。直到这种变化达到均衡态,权重数值不再发生改变。这与Google的网页排名算法PageRank,在思想上是一致的。
根据最后的权重值,取其中排列靠前的词汇,作为关键词提取结果。
如果你对原始文献感兴趣,请参考以下链接:

3.2、TextRank详解
TextRank由Mihalcea与Tarau于EMNLP'04 [1]提出来,其思想非常简单:通过词之间的相邻关系构建网络,然后用PageRank迭代计算每个节点的rank值,排序rank值即可得到关键词。PageRank本来是用来解决网页排名的问题,网页之间的链接关系即为图的边,迭代计算公式如下:
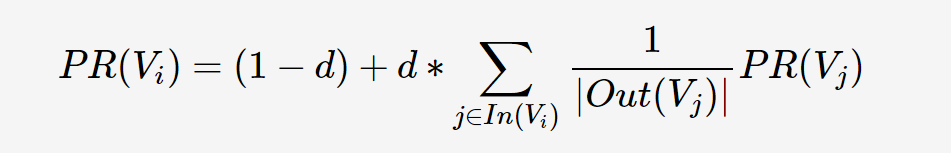
其中,PR(Vi)表示结点Vi的rank值,In(Vi)表示结点Vi的前驱结点集合,Out(Vj)表示结点Vj的后继结点集合,d为damping factor用于做平滑。
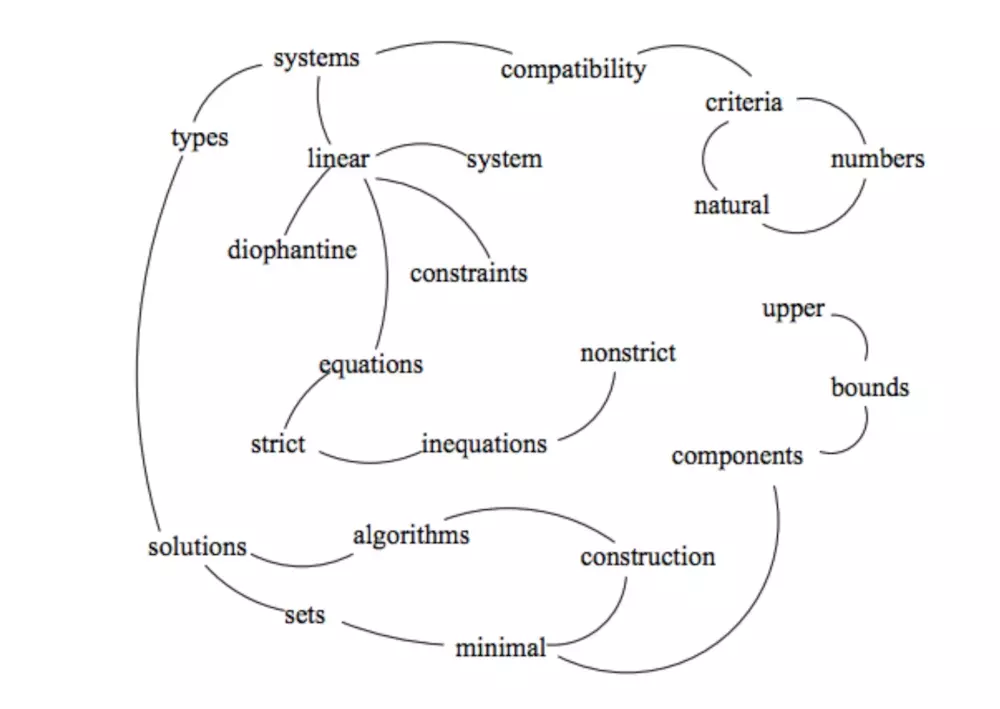
网页之间的链接关系可以用图表示,那么怎么把一个句子(可以看作词的序列)构建成图呢?TextRank将某一个词与其前面的N个词、以及后面的N个词均具有图相邻关系(类似于N-gram语法模型)。具体实现:设置一个长度为N的滑动窗口,所有在这个窗口之内的词都视作词结点的相邻结点;则TextRank构建的词图为无向图。下图给出了由一个文档构建的词图(去掉了停用词并按词性做了筛选):
考虑到不同词对可能有不同的共现(co-occurrence),TextRank将共现作为无向图边的权值。那么,TextRank的迭代计算公式如下:
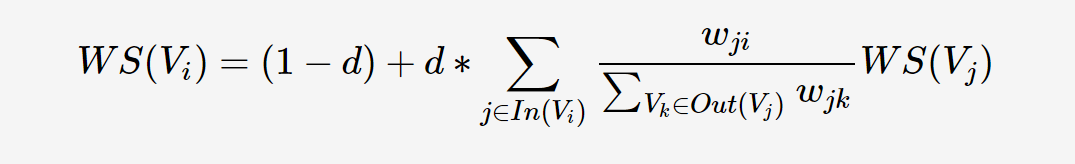
可以看出,该公式仅仅比PageRank多了一个权重项Wji,用来表示两个节点之间的边连接有不同的重要程度。
在这里算是简单说明了TextRank的内在原理,以下对其关键词提取应用做进一步说明。
TextRank用于关键词提取的算法如下:
1)把给定的文本T按照完整句子进行分割,即
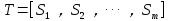
2)对于每个句子Si属于T,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即
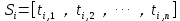
,其中 ti,j 是保留后的候选关键词。
3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
4)根据上面公式,迭代传播各节点的权重,直至收敛。
5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
6)由5得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。
3.2.1 TextRank算法提取关键词短语
提取关键词短语的方法基于关键词提取,可以简单认为:如果提取出的若干关键词在文本中相邻,那么构成一个被提取的关键短语。
3.2.2 TextRank生成摘要
将文本中的每个句子分别看做一个节点,如果两个句子有相似性,那么认为这两个句子对应的节点之间存在一条无向有权边。考察句子相似度的方法是下面这个公式:
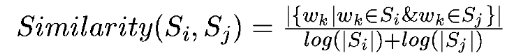
公式中,Si,Sj分别表示两个句子词的个数总数,Wk表示句子中的词,那么分子部分的意思是同时出现在两个句子中的同一个词的个数,分母是对句子中词的个数求对数之和。分母这样设计可以遏制较长的句子在相似度计算上的优势。
我们可以根据以上相似度公式循环计算任意两个节点之间的相似度,根据阈值去掉两个节点之间相似度较低的边连接,构建出节点连接图,然后计算TextRank值,最后对所有TextRank值排序,选出TextRank值最高的几个节点对应的句子作为摘要。
四、对比总结
- TextRank与TFIDF均严重依赖于分词结果——如果某词在分词时被切分成了两个词,那么在做关键词提取时无法将两个词黏合在一起(TextRank有部分黏合效果,但需要这两个词均为关键词)。因此是否添加标注关键词进自定义词典,将会造成准确率、召回率大相径庭。
- TextRank的效果并不优于TFIDF。
- TextRank虽然考虑到了词之间的关系,但是仍然倾向于将频繁词作为关键词。
此外,由于TextRank涉及到构建词图及迭代计算,所以提取速度较慢。
发现以上两种方法本质上还是基于词频,这也导致了我们在进行自然语言处理的时候造成的弊端,因为我们阅读一篇文章的时候,并不是意味着主题词会一直出现,特别对于中文来说,蕴含的中心思想也往往不是一两个词能够说明的,这也是未来自然语言方面要解决的基于语义的分析,路还很长。
更多阅读:
refer:
https://zhuanlan.zhihu.com/p/41091116
关键词提取算法TF-IDF与TextRank的更多相关文章
- TextRank:关键词提取算法中的PageRank
很久以前,我用过TFIDF做过行业关键词提取.TFIDF仅仅从词的统计信息出发,而没有充分考虑词之间的语义信息.现在本文将介绍一种考虑了相邻词的语义关系.基于图排序的关键词提取算法TextRank [ ...
- 关键词提取算法TextRank
很久以前,我用过TFIDF做过行业关键词提取.TFIDF仅仅从词的统计信息出发,而没有充分考虑词之间的语义信息.现在本文将介绍一种考虑了相邻词的语义关系.基于图排序的关键词提取算法TextRank. ...
- 关键词提取算法-TextRank
今天要介绍的TextRank是一种用来做关键词提取的算法,也可以用于提取短语和自动摘要.因为TextRank是基于PageRank的,所以首先简要介绍下PageRank算法. 1.PageRank算法 ...
- 自然语言处理工具hanlp关键词提取图解TextRank算法
看一个博主(亚当-adam)的关于hanlp关键词提取算法TextRank的文章,还是非常好的一篇实操经验分享,分享一下给各位需要的朋友一起学习一下! TextRank是在Google的PageRan ...
- 关键字提取算法TF-IDF和TextRank(python3)————实现TF-IDF并jieba中的TF-IDF对比,使用jieba中的实现TextRank
关键词: TF-IDF实现.TextRank.jieba.关键词提取数据来源: 语料数据来自搜狐新闻2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据 数据处 ...
- NLP之关键词提取(TF-IDF、Text-Rank)
1.文本关键词抽取的种类: 关键词提取方法分为有监督.半监督和无监督三种,有监督和半监督的关键词抽取方法需要浪费人力资源,所以现在使用的大多是无监督的关键词提取方法. 无监督的关键词提取方法又可以分为 ...
- 关键词提取TF-IDF算法/关键字提取之TF-IDF算法
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与信息探勘的常用加权技术.TF的意思是词频(Term - frequency), ...
- TF-IDF算法之关键词提取
(注:本文转载自阮一峰老师的博文,原文地址:http://www.ruanyifeng.com/blog/2013/03/tf-idf.html) 这个标题看上去好像很复杂,其实我要谈的是一个很简单的 ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
随机推荐
- selenium操作cookie
1,登录网页,使用webdriver的get_cookies获取cookie,并保存json文件 2,读取json文件,遍历添加网站使用的每一个cookies的name,value. 使用add_co ...
- 使用AOP思想封装JDBC
看代码 package learning.aop2; import org.springframework.stereotype.Component; import java.sql.SQLExcep ...
- Python的一个bug,记录一下
安装报错:E:\webpy-master>python setup.py installTraceback (most recent call last): File "setup.p ...
- switch语句 initialization of 'XXX' is skipped by 'case' label 原因及解决办法--块语句的作用
出错代码段: switch (t) { case 0: int a = 0; break; default: break; }编译时提示:“error C2361: initialization ...
- ceph常用命令(3)
1.查看集群配置信息 ceph daemon /var/run/ceph/ceph-mon.$(hostname -s).asok config show 2.在部署节点修改了ceph.conf文件, ...
- zabbix通过SDK和API获取阿里云RDS的监控数据
阿里云的RDS自带的监控系统获取数据不怎么直观,想要通过API获取数据通过zabbix显示,因为网上资料缺乏和其他一些原因,获取API签名很困难,但使用阿里云的SDK可以完美避开获取签名的步骤. 阿里 ...
- dede不同栏目调用不同banner图的方法
用顶级栏目ID 方法: <img src="{dede:global.cfg_templets_skin/}/images/{dede:field.typeid function=&q ...
- 深入解读TCP/IP
虽然大家现在对互联网很熟悉,但是计算机网络的出现比互联网要早很多. 计算机为了联网,就必须规定通信协议,早期的计算机网络,都是由各厂商自己规定一套协议,IBM.Apple和Microsoft都有各自的 ...
- 一些常用的java书籍的适看范围
一些常用的java书籍的适看范围 Java三本经典的书: 1.Java核心技术书籍:适合查阅,遇到某个问题不清楚了,可以来此求证. 2.Effective Java:对java底层的一些涉及内容,书 ...
- DES算法概述
DES全称为Data Encryption Standard,即数据加密标准.1997年数据加密标准DES正式公布,其分组长度为64比特,密钥长度为64比特,其中8比特为奇偶校验位,所以实际长度为56 ...