innodb存储引擎之内存
1、innoDB存储引擎体系架构
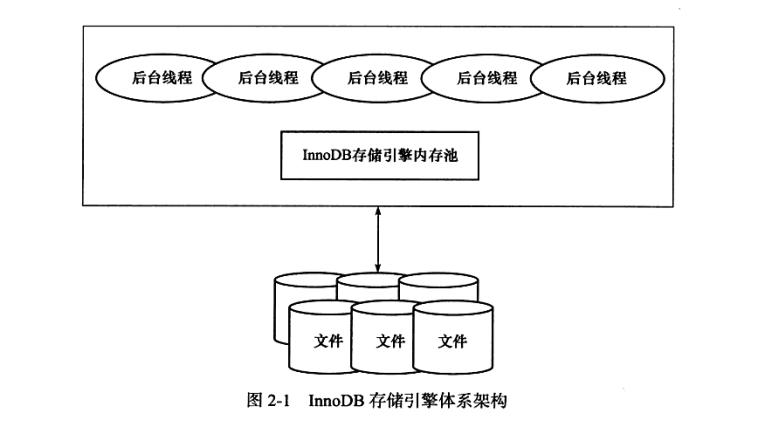
如上图所示,innoDB存储是基于磁盘存储的,并且其中的记录以页的方式进行管理,但为什么要引入一个内存池呢?
其目的就是为了协调CUP速度与磁盘速度的鸿沟,基于磁盘的数据库系统通常使用缓冲池技术来提高数据库的整体性能(简单来说就是通过内存的速度来弥补磁盘速度较慢对数据库性能的影响)
2、内存池的管理
既然内存池能提高数据库的整体性能,那么innoDB是怎么对这块内存区域进行管理的呢?这里就要介绍一种算法和一种机制
2.1、LUR列表
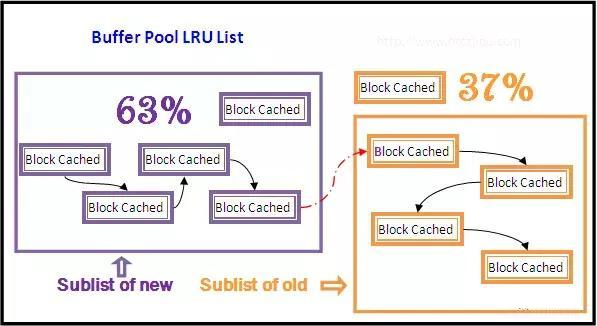
上图就是一个LUR列表,上图的LUR链表氛围new(热点)区和old(淘汰)区,new和old之间的位置称为midpoint,其余的还有free(空闲)列表等
先来说查询情况,在数据库中进行读取页的操作,首先将从磁盘读到的页存放在缓冲池中,下一次在读相同页的时候,首先判断该页是否在缓冲池,若在缓冲池中,则直接读取该页,否则读取磁盘上的页
对于数据库中页的修改操作,首先修改在缓冲池中的页,然后再以一定的频率刷新到磁盘上,页不是在每次发生更新时触发的,而是根据一种checkpoint的机制刷新会磁盘
2.2、LUR(最近最少使用)算法
2.2.1、LUR列表是通过什么方式管理数据的?
LUR(最近最少使用)算法,当新查询进来时,innoDB会从free列表中拿出可用的页,放到LUR列表中,然后从free列表删除该页,如果LRU列表溢出,那么就会淘汰掉LRU列表(old区)末尾的页,同时把新的页放到old区列首
2.2.2、old区的数据什么时候能加入到new区?
在old列表存留了innodb_old_blocks_time所配置的时间之后下一次查询还能在old区中命中缓存,则加入到new区,如果new区溢出,则溢出的页则放到old区
2.3、Checkpoint机制
Checkpoint机制指得就是将缓冲池的脏页数据刷新到磁盘
如果在缓冲池将页的数据刷新到磁盘时发生了宕机,那么数据就无法恢复了,所以事务数据库系统都会采用一种Write Ahead Log策略,即当事务提交时,先写重做日志,再修改页,因为宕机而导致数据丢失时,可以通过重做日志完成数据的恢复
2.3.1、Checkpoint机制触发点
(1)Sharp Checkpoint
在数据库关闭时,将所有的脏页都刷新到磁盘,如果在数据库运行时使用Sharp Checkpoint,那么数据库的可用性就会收到很大的影响
(2)Fuzzy Checkpoint
每次刷新一部分脏页,因此InnoDB存储引擎内部使用Fuzzy Checkpoint进行页的刷新
2.3.2 Fuzzy Checkpoint
Fuzzy Checkpoint 有一下4种方式
(1)Master Thread Checkpoint
在Master Thread中发生的Checkpoint,以每秒或每十秒的速度从缓冲池的脏页列表中刷新一定比例的页回磁盘,过程是异步的,所以InnoDB存储引擎可以机芯其他操作,用户查询线程不会阻塞
(2)FLUSH_LRU_LIST Checkpoint
InnoDB存储引擎需要保证LRU列表中需要有100个空闲页可以使用(为了保证有足够的可用空间给用户查询线程中,不会阻塞线程的查询操作)
如果没有100个空闲页,LRU算法会清除掉LRU列表(old区)尾端的页,此时如果有脏页,则需要进行CheckPoint
(3)Async/Sync Flush Checkpoint
指重做日志不可用时(这部分日志已经不再需要了,可以进行清除),刷新脏页到磁盘(如果这时的重做日志还有脏页,则必须要刷新到磁盘)
(4)Dirty Page too much Checkpoint
脏页数据太多,导致InnoDB存储引擎强制进行Checkpoint,目的总的来说还是为了保证缓冲池有足够可用的页
2.3.2、Checkpoint机制解决的问题
(1)缩短数据库的恢复时间
当数据库发生宕机时,数据库不需要重做所有的日志,因为checkpoint之前的页都已经刷新回磁盘了,所以只需要对checkPoint后的重做日志进行恢复(增量恢复)
(2)缓冲池不够用时,将脏页刷新到磁盘
因为LRU算法会清楚掉最近最少使用的页,如果清除的包含脏页,那么需要强制执行checkPoint,将脏页刷新到磁盘
(3)重做日志不可用时,刷新脏页
重做日志不可用指得是:这部分日志已经不再需要了,可以进行清除(节省空间,新的重做日志可以复用这部分的空间),但是如果这部分的日志还有脏页数据(需要使用),那么必须强制产生Checkpoint,将缓冲池中的页至少刷新到磁盘到当前重做日志的位置
参考资料:
MySQL技术内幕InnoDB存储引擎第二版
https://blog.51cto.com/14227759/2384690?source=dra
https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html
innodb存储引擎之内存的更多相关文章
- InnoDB存储引擎介绍-(1)InnoDB存储引擎结构
首先以一张图简单展示 InnoDB 的存储引擎的体系架构. 从图中可见, InnoDB 存储引擎有多个内存块,这些内存块组成了一个大的内存池,主要负责如下工作: 维护所有进程/线程需要访问的多个内部数 ...
- 《Mysql技术内幕,Innodb存储引擎》——Innodb体系结构
Innodb体系结构 Innodb存储引擎主要包括内存池以及后台线程. 内存池:多个内存块组成一个内存池,主要维护进程/线程的内部数据.缓存磁盘数据,修改文件前先修改内存.redo log 后台线程: ...
- 【MySQL】(二)InnoDB存储引擎
InnoDB是事务安全的MySQL存储引擎,设计上采用了类似于Oracel数据库的架构.通常来说,InnoDB存储引擎是OLTP应用中核心表的首选存储引擎.同时,也正是因为InnoDB的存在,才使My ...
- INNODB存储引擎之缓冲池
以下的资料总结自:官方文档和<MySQL技术内幕-INNODB存储引擎>一书. 对INNODB存储引擎缓冲池的那一段描述来自博文:http://www.ywnds.com/?p=9886说 ...
- MySQL技术内幕InnoDB存储引擎(二)——InnoDB存储引擎
1.概述 是一个高性能.高可用.高扩展的存储引擎. 2.InnoDB体系架构 InnoDB存储引擎主要由内存池和后台线程构成. 其中,内存池由许多个内存块组成,作用如下: 维护所有进程和线程需要访问的 ...
- Galera集群server.cnf参数调整--Innodb存储引擎内存相关参数(一)
在innodb引擎中,内存的组成主要有三部分:缓冲池(buffer pool),重做日志缓存(redo log buffer),额外的内存池(additional memory pool).
- InnoDB存储引擎内存缓冲池管理技术——LRU List、Free List、Flush List
InnoDB是事务安全的MySQL存储引擎,野山谷OLTP应用中核心表的首选存储引擎.他是基于表的存储引擎,而不是基于数据库的.其特点是行锁设计.支持MVCC.支持外键.提供一致性非锁定读,同时被设计 ...
- InnoDB 存储引擎的线程与内存池
InnoDB 存储引擎的线程与内存池 InnoDB体系结构如下: 后台线程: 1.后台线程的主要作用是负责刷新内存池中的数据,保证缓冲池中的内存缓存的是最近的数据: 2.另外,将以修改的数据文件刷 ...
- MySQL数据库和InnoDB存储引擎文件
参数文件 当MySQL示例启动时,数据库会先去读一个配置参数文件,用来寻找数据库的各种文件所在位置以及指定某些初始化参数,这些参数通常定义了某种内存结构有多大等.在默认情况下,MySQL实例会按照一定 ...
随机推荐
- 小D课堂-SpringBoot 2.x微信支付在线教育网站项目实战_5-2.微信扫一扫功能开发前期准备
笔记 2.微信扫一扫功能开发前期准备 简介:讲解微信扫一扫功能相关开发流程和资料准备 1.微信开放平台介绍(申请里面的网站应用需要企业资料) ...
- [Spark News] Spark + GPU are the next generation technology
一.资源:Spark进行机器学习,支持GPU From:https://my.oschina.net/u/2306127/blog/1602291 为了使用Spark进行机器学习,支持GPU是必须的, ...
- CentOS7或CentOS8 安装VirtualBox Guest Addon缺少kernel-headers的解决办法
CentOS7或CentOS8 在Oracle VM VirtualBox中安装Guest Addon时,如果缺少kernel-headers和相应的编译库,会提示出错. "kernel h ...
- Java泛型(7):无界通配符<?>
无界通配符<?>很容易和原生类型混淆. 以List为例: List表示持有任何Object类型的原生List,其实就等价于List<Object> List<?>表 ...
- Git(1):思想及概念
Git与其他版本控制软件的差异及思想 直接记录快照,而非差异比较 Git不保存这些前后变化的差异数据.实际上,Git 更像是把变化的文件作快照后,记录在一个微型的文件系统中.每次提交更新时,它会纵览一 ...
- Qt 字符映射表 显示图标
一.利用字符映射表segmdl2.ttf,窗体显示字符图片. 在win10里面搜“字符映射表”,选择字体segmdl2.ttf,查看图标对应得16进制值.把此字体拷贝到程序的目录下. 二.使用 #if ...
- Unreal Engine* 4.19 的 CPU 功能检测
随着现代 CPU 内核数量的增加,可以拥有更多的游戏功能.但是,相比配备高端系统的玩家,内核数量较少的玩家可能会处于劣势.为了缩小这种差距,可以使用 C++ 和蓝图划分特性.这样可以实现最大的 CPU ...
- 用myeclipse连接MySQL8.0时没有配置jar包
先上测试代码 package testJdbc; import java.sql.Connection; import java.sql.DriverManager; import java.sql. ...
- Mac 操作小技巧
系统版本 MacOs Mojava # 快捷键篇: 1. 打开终端:command+空格,输入terminal:在终端页面,新建终端command + T 2. 打开文件夹:command + T 3 ...
- 第二次Java实验报告
Java实验报告 班级 计科二班 学号 20188437 姓名 何磊 完成时间 2019/9/12 评分等级 实验二 Java简单类与对象 实验目的 掌握类的定义,熟悉属性.构造函数.方法的作用,掌握 ...