deep_learning_Function_Sklearn_Mode
API参考:https://scikit-learn.org/stable/modules/classes.html#
作为Python中经典的机器学习模块,sklearn围绕着机器学习提供了很多可直接调用的机器学习算法以及很多经典的数据集,本文就对sklearn中专门用来得到已有或自定义数据集的datasets模块进行详细介绍;
datasets中的数据集分为很多种,本文介绍几类常用的数据集生成方法,本文总结的所有内容你都可以在sklearn的官网:
http://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
中找到对应的更加详细的英文版解释;
1 自带的经典小数据集
1.1 波士顿房价数据(适用于回归任务)
这个数据集包含了506处波士顿不同地理位置的房产的房价数据(因变量),和与之对应的包含房屋以及房屋周围的详细信息(自变量),其中包含城镇犯罪率、一氧化氮浓度、住宅平均房间数、到中心区域的加权距离以及自住房平均房价等13个维度的数据,因此,波士顿房价数据集能够应用到回归问题上,这里使用load_boston(return_X_y=False)方法来导出数据,其中参数return_X_y控制输出数据的结构,若选为True,则将因变量和自变量独立导出;

from sklearn import datasets '''清空sklearn环境下所有数据'''
datasets.clear_data_home() '''载入波士顿房价数据''' X,y = datasets.load_boston(return_X_y=True) '''获取自变量数据的形状''' print(X.shape) '''获取因变量数据的形状''' print(y.shape)

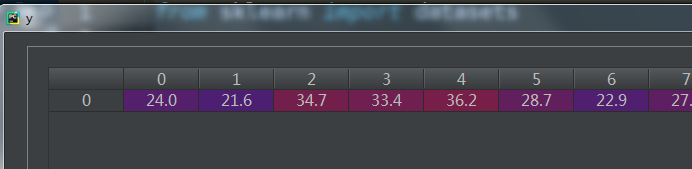
自变量X:

因变量y:
1.2 威斯康辛州乳腺癌数据(适用于分类问题)
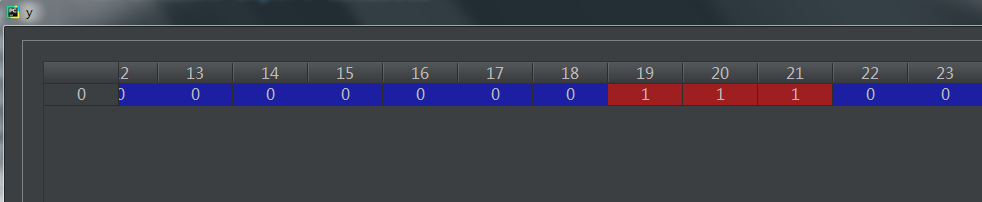
这个数据集包含了威斯康辛州记录的569个病人的乳腺癌恶性/良性(1/0)类别型数据(训练目标),以及与之对应的30个维度的生理指标数据;因此这是个非常标准的二类判别数据集,在这里使用load_breast_cancer(return_X_y)来导出数据:
from sklearn import datasets '''载入威斯康辛州乳腺癌数据''' X,y = datasets.load_breast_cancer(return_X_y=True) '''获取自变量数据的形状''' print(X.shape) '''获取因变量数据的形状''' print(y.shape)

自变量X:

因变量y:
1.3 糖尿病数据(适用于回归任务)
这是一个糖尿病的数据集,主要包括442行数据,10个属性值,分别是:Age(年龄)、性别(Sex)、Body mass index(体质指数)、Average Blood Pressure(平均血压)、S1~S6一年后疾病级数指标。Target为一年后患疾病的定量指标,因此适合与回归任务;这里使用load_diabetes(return_X_y)来导出数据:
from sklearn import datasets '''载入糖尿病数据''' X,y = datasets.load_diabetes(return_X_y=True) '''获取自变量数据的形状''' print(X.shape) '''获取因变量数据的形状''' print(y.shape)
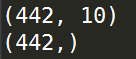
自变量X:
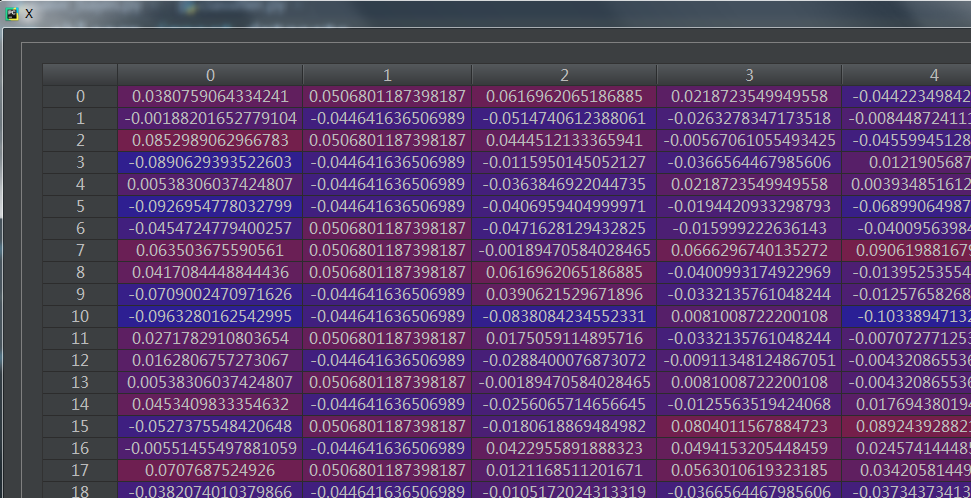
因变量y:

1.4 手写数字数据集(适用于分类任务)
这个数据集是结构化数据的经典数据,共有1797个样本,每个样本有64的元素,对应到一个8x8像素点组成的矩阵,每一个值是其灰度值,我们都知道图片在计算机的底层实际是矩阵,每个位置对应一个像素点,有二值图,灰度图,1600万色图等类型,在这个样本中对应的是灰度图,控制每一个像素的黑白浓淡,所以每个样本还原到矩阵后代表一个手写体数字,这与我们之前接触的数据有很大区别;在这里我们使用load_digits(return_X_y)来导出数据:
from sklearn import datasets '''载入手写数字数据''' data,target = datasets.load_digits(return_X_y=True) print(data.shape) print(target.shape)

这里我们利用matshow()来绘制这种矩阵形式的数据示意图:
import matplotlib.pyplot as plt
import numpy as np '''绘制数字0'''
num = np.array(data[0]).reshape((8,8))
plt.matshow(num)
print(target[0]) '''绘制数字5'''
num = np.array(data[15]).reshape((8,8))
plt.matshow(num)
print(target[15]) '''绘制数字9'''
num = np.array(data[9]).reshape((8,8))
plt.matshow(num)
print(target[9])

1.5 Fisher的鸢尾花数据(适用于分类问题)
著名的统计学家Fisher在研究判别分析问题时收集了关于鸢尾花的一些数据,这是个非常经典的数据集,datasets中自然也带有这个数据集;这个数据集包含了150个鸢尾花样本,对应3种鸢尾花,各50个样本(target),以及它们各自对应的4种关于花外形的数据(自变量);这里我们使用load_iris(return_X_y)来导出数据:
from sklearn import datasets '''载入Fisher的鸢尾花数据''' data,target = datasets.load_iris(return_X_y=True) '''显示自变量的形状'''
print(data.shape) '''显示训练目标的形状'''
print(target.shape)
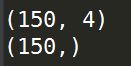
自变量:
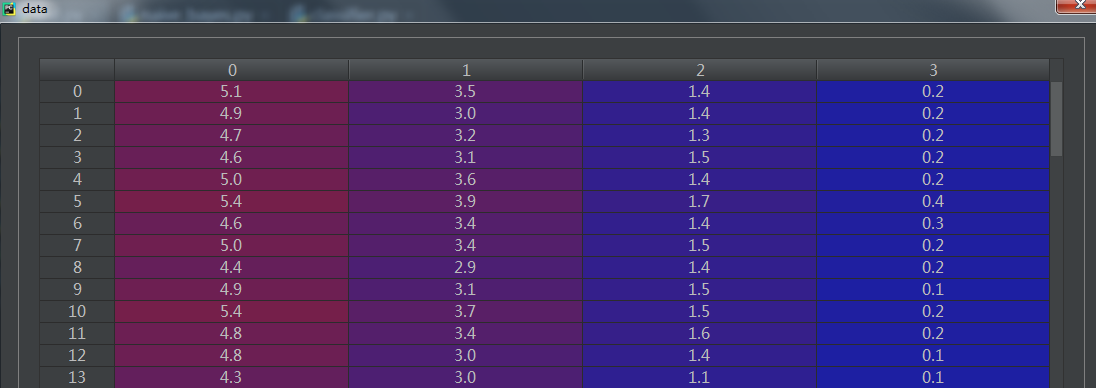
训练目标:

1.6 红酒数据(适用于分类问题)
这是一个共178个样本,代表了红酒的三个档次(分别有59,71,48个样本),以及与之对应的13维的属性数据,非常适合用来练习各种分类算法;在这里我们使用load_wine(return_X_y)来导出数据:
from sklearn import datasets '''载入wine数据''' data,target = datasets.load_wine(return_X_y=True) '''显示自变量的形状'''
print(data.shape) '''显示训练目标的形状'''
print(target.shape)

2 自定义数据集
前面我们介绍了几种datasets自带的经典数据集,但有些时候我们需要自定义生成服从某些分布或者某些形状的数据集,而datasets中就提供了这样的一些方法:
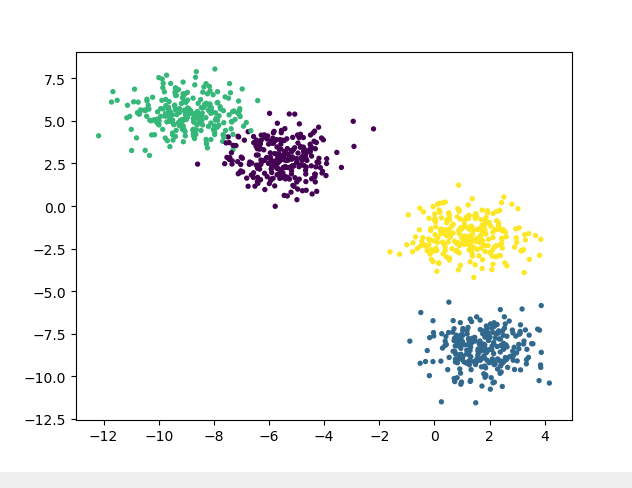
2.1 产生服从正态分布的聚类用数据
datasets.make_blobs(n_samples=100, n_features=2, centers=3, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None),其中:
n_samples:控制随机样本点的个数
n_features:控制产生样本点的维度(对应n维正态分布)
centers:控制产生的聚类簇的个数
from sklearn import datasets
import matplotlib.pyplot as plt X,y = datasets.make_blobs(n_samples=1000, n_features=2, centers=4, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=None) plt.scatter(X[:,0],X[:,1],c=y,s=8)
2.2 产生同心圆样本点
datasets.make_circles(n_samples=100, shuffle=True, noise=0.04, random_state=None, factor=0.8)
n_samples:控制样本点总数
noise:控制属于同一个圈的样本点附加的漂移程度
factor:控制内外圈的接近程度,越大越接近,上限为1
from sklearn import datasets
import matplotlib.pyplot as plt X,y = datasets.make_circles(n_samples=10000, shuffle=True, noise=0.04, random_state=None, factor=0.8) plt.scatter(X[:,0],X[:,1],c=y,s=8)

2.3 生成模拟分类数据集
datasets.make_classification(n_samples=100, n_features=20, n_informative=2, n_redundant=2, n_repeated=0, n_classes=2, n_clusters_per_class=2, weights=None, flip_y=0.01, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None)
n_samples:控制生成的样本点的个数
n_features:控制与类别有关的自变量的维数
n_classes:控制生成的分类数据类别的数量
from sklearn import datasets X,y = datasets.make_classification(n_samples=100, n_features=20, n_informative=2, n_redundant=2, n_repeated=0, n_classes=2, n_clusters_per_class=2, weights=None, flip_y=0.01, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None) print(X.shape)
print(y.shape)
set(y)

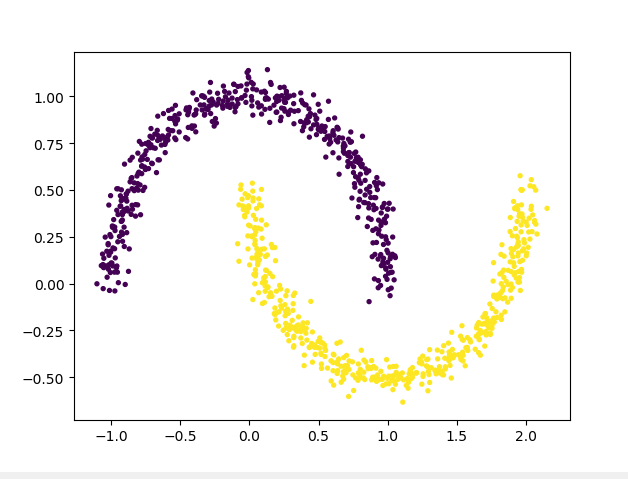
2.4 生成太极型非凸集样本点
datasets.make_moons(n_samples,shuffle,noise,random_state)
from sklearn import datasets
import matplotlib.pyplot as plt X,y = datasets.make_moons(n_samples=1000, shuffle=True, noise=0.05, random_state=None) plt.scatter(X[:,0],X[:,1],c=y,s=8)
以上就是sklearn.datasets中基本的数据集方法,如有笔误之处望指出
转自:https://www.cnblogs.com/feffery/p/8686128.html
deep_learning_Function_Sklearn_Mode的更多相关文章
随机推荐
- Java泛型(9):动态类型安全
因为可以向Java SE5之前的代码传递泛型容器,所以旧式代码仍有可能破坏你的容器.Java SE5中有一组便利工具,可以解决这种情况下类型检查的问题. 它们是静态方法checkedCollectio ...
- 后缀数组--summer-work之我连模板题都做不起
这章要比上章的AC自动机要难理解. 这里首先要理解基数排序:基数排序与桶排序,计数排序[详解] 下面通过这个积累信心:五分钟搞懂后缀数组!后缀数组解析以及应用(附详解代码) 下面认真研读下这篇: [转 ...
- 在SSH里面远程启动ubuntu上的GUI程序
由于嵌入式开发板上是ubuntu系统,开发板接有显示器,现有一GUI程序需要在开发板显示器上实时显示,开发板与本地通过网络SSH连接,正常情况执行如:firefox,那么firefox会显示到本地,只 ...
- Spark在Windows上调试
1. 背景 (1) spark的一般开发与运行流程是在本地Idea或Eclipse中写好对应的spark代码,然后打包部署至驱动节点,然后运行spark-submit.然而,当运行时异常,如空指针或数 ...
- Tensorflow 用训练好的模型预测
本节涉及点: 从命令行参数读取需要预测的数据 从文件中读取数据进行预测 从任意字符串中读取数据进行预测 一.从命令行参数读取需要预测的数据 训练神经网络是让神经网络具备可用性,真正使用神经网络时,需要 ...
- Python学习笔记——递归函数
1.设置递归层数 #设置recursion函数的层数,默认是100层 import sys sys.setrecursionlimit(10000) 2. 阶乘 #定义一个阶乘函数 def facto ...
- 【计算机视觉】【并行计算与CUDA开发】GPU硬解码---DXVA
前面介绍利用NVIDIA公司提供的CUVID库进行视频硬解码,下面将介绍利用DXVA进行硬解码. 一.DXVA介绍 DXVA是微软公司专门定制的视频加速规范,是一种接口规范.DXVA规范制定硬件加速解 ...
- Servlet 使Session设置失效
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletExcep ...
- vue $refs获取dom元素
1.今天做vue项目有个获取dom节点,主要目的是获取节点让滚动到顶部 首先在滑动容器去添加ref <div class="contentScroll" ref=" ...
- 19.通过MAPREDUCE 把收集数据进行清洗
在eclipse软件里创建一个maven项目 jdk要换成本地安装的1.8版本的 加载pom.xml文件 <project xmlns="http://maven.apache.org ...