遍历二叉树 - 基于递归的DFS(前序,中序,后序)
上节中已经学会了如何构建一个二叉搜索数,这次来学习下树的打印-基于递归的DFS,那什么是DFS呢?

有个概念就行,而它又分为前序、中序、后序三种遍历方式,这个也是在面试中经常会被问到的,下面来具体学习下,用三种遍历方法来遍历上节中的二叉数:
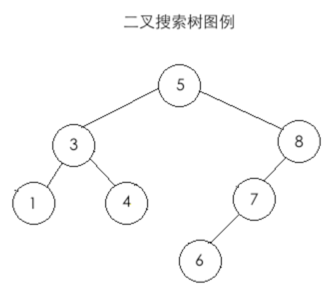
前序遍历:

那对于上面的二叉数用前序遍历,遍历过程如下:
1、先遍历根节点【5】
2、再遍历左子树:

需要注意的是:遍历左右子树时仍然采用前序遍历方法。所以如下:
a、先遍历根节点【3】
b、再遍历左子树,由于只有一个结点则直接打印【1】
c、再遍历右子树,由于只有一个结点则直接打印【4】
3、再遍历右子树:
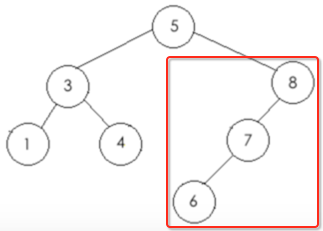
a、先遍历根节点【8】
b、再遍历左子树:
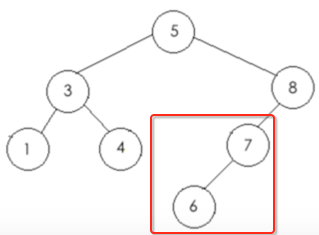
ba、先遍历根节点【7】
bb、再遍历左子树,由于只有一个结点则直接打印【6】
bc、再遍历右子树,由于木有右子树,递归返回。
c、再遍历右子树,由于木有右子树,递归返回。
至此整个前序遍历结束,结果如:【5】、【3】、【1】、【4】、【8】、【7】、【6】
下面看下代码具体实现,基于上节二叉搜索树的实现,增加一个遍历的方法,其它木变,直接上代码:
public class BinarySearchTree {
TreeNode root = null;
class TreeNode{
int value;
int position;
TreeNode left = null, right = null;
TreeNode(int value, int position){
this.value = value;
this.position = position;
}
}
public void add(int value, int position){
if(root == null){//生成一个根结点
root = new TreeNode(value, position);
} else {
//生成叶子结点
add(value, position, root);
}
}
private void add(int value, int position, TreeNode node){
if(node == null)
throw new RuntimeException("treenode cannot be null");
if(node.value == value)
return; //ignore the duplicated value
if(value < node.value){
if(node.left == null){
node.left = new TreeNode(value, position);
}else{
add(value, position, node.left);
}
}else{
if(node.right == null){
node.right = new TreeNode(value, position);
}else{
add(value, position, node.right);
}
}
}
//打印构建的二叉搜索树
static void printTreeNode(TreeNode node) {
if(node == null)
return;
System.out.println("node:" + node.value);
if(node.left != null) {
printTreeNode(node.left);
}
if(node.right != null) {
printTreeNode(node.right);
}
}
//搜索结点
public int search(int value){
return search(value, root);
}
private int search(int value, TreeNode node){
if(node == null)
return -1; //not found
else if(value < node.value){
System.out.println("Searching left");
return search(value, node.left);
}
else if(value > node.value){
System.out.println("Searching right");
return search(value, node.right);
}
else
return node.position;
}
//二叉树遍历
public void travel(){
travel(root);
}
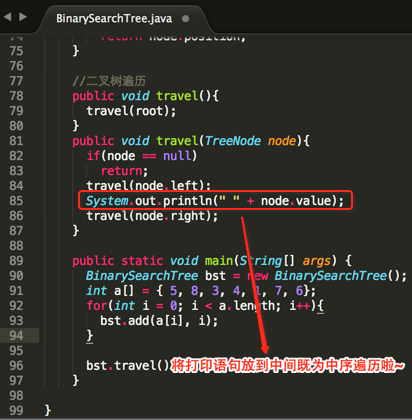
public void travel(TreeNode node){
if(node == null)
return;
System.out.println(" " + node.value);
travel(node.left);
travel(node.right);
}
public static void main(String[] args) {
BinarySearchTree bst = new BinarySearchTree();
int a[] = { 5, 8, 3, 4, 1, 7, 6};
for(int i = 0; i < a.length; i++){
bst.add(a[i], i);
}
bst.travel();
}
}
编译运行:
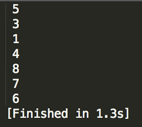
由于比较好理解,所以这里就不一一debug遍历方法去了,总之是首先先打印当前结点,之后再递归左右子树,刚好跟前序遍历的定义一样。
中序遍历:

同样对于上面的二叉数用前序遍历,遍历过程如下:
1、先遍历左节点
继续按着左中右的遍历顺序继续对左子树进行遍历,如下:
a、先遍历左节点,由于只有一个结点直接打印【1】
b、再遍历根节点【3】
c、最后再遍历右节点【4】
2、再遍历根节点【5】
3、最后再遍历右节点:
继续按着左中右的遍历顺序继续对右子树进行遍历,如下:
a、先遍历左节点
aa、先遍历左节点【6】
ab、再遍历根节点【7】
ac、最后再遍历右节点,由于木有右节点直接结束递归。
b、再遍历根节点【8】
c、最后再遍历右节点,由于木有右节点直接结束递归。
至此整个中序遍历结束,结果如:【1】、【3】、【4】、【5】、【6】、【7】、【8】
【提示】:有木有发现居然结果成了一组有序的数列,也就是说这又是一种排序的算法:将一组数用组成二叉搜索树之后然后再用中序遍历打印出来,当然这种排序算法不是特别好,只是从这个结果点可以联想到排序算法。
下面看下代码具体实现,比较简单,只需要简单修改travel的打印顺序既可,如下:
编译运行:
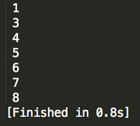 ,跟预期一致。
,跟预期一致。
后序遍历:

同理,对于上面的二叉数用后序遍历,遍历过程如下:
1、先遍历左节点
继续按着左右中的遍历顺序继续对左子树进行遍历,如下:
a、先遍历左节点,由于只有一个结点直接打印【1】
b、再遍历右节点【4】
c、最后再遍历根节点【3】
2、再遍历右节点
继续按着左右中的遍历顺序继续对右子树进行遍历,如下:
a、先遍历左节点
aa、先遍历左节点【6】
ab、最后再遍历右节点,由于木有右节点直接忽略。
ac、再遍历根节点【7】
b、最后再遍历右节点,由于木有右节点直接结束递归。
c、再遍历根节点【8】
3、最后遍历根节点【5】
至此整个后序遍历结束,结果如:【1】、【4】、【3】、【6】、【7】、【8】、【5】
下面看下代码具体实现,同理只需要简单修改travel的打印顺序既可,如下:

编译运行:
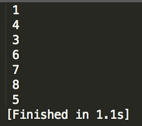 ,跟预期一致~
,跟预期一致~
那以上的遍历方法的时间复杂度是多少呢?一个结点只访问一次,自然复杂度是O(n),其中n为结点个数。
遍历二叉树 - 基于递归的DFS(前序,中序,后序)的更多相关文章
- 遍历二叉树 - 基于栈的DFS
之前已经学过二叉树的DFS的遍历算法[http://www.cnblogs.com/webor2006/p/7244499.html],当时是基于递归来实现的,这次利用栈不用递归也来实现DFS的遍历, ...
- 算法进阶面试题03——构造数组的MaxTree、最大子矩阵的大小、2017京东环形烽火台问题、介绍Morris遍历并实现前序/中序/后序
接着第二课的内容和带点第三课的内容. (回顾)准备一个栈,从大到小排列,具体参考上一课.... 构造数组的MaxTree [题目] 定义二叉树如下: public class Node{ public ...
- 二叉树 遍历 先序 中序 后序 深度 广度 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- 前序+中序->后序 中序+后序->前序
前序+中序->后序 #include <bits/stdc++.h> using namespace std; struct node { char elem; node* l; n ...
- SDUT OJ 数据结构实验之二叉树八:(中序后序)求二叉树的深度
数据结构实验之二叉树八:(中序后序)求二叉树的深度 Time Limit: 1000 ms Memory Limit: 65536 KiB Submit Statistic Discuss Probl ...
- SDUT-2804_数据结构实验之二叉树八:(中序后序)求二叉树的深度
数据结构实验之二叉树八:(中序后序)求二叉树的深度 Time Limit: 1000 ms Memory Limit: 65536 KiB Problem Description 已知一颗二叉树的中序 ...
- 给出 中序&后序 序列 建树;给出 先序&中序 序列 建树
已知 中序&后序 建立二叉树: SDUT 1489 Description 已知一棵二叉树的中序遍历和后序遍历,求二叉树的先序遍历 Input 输入数据有多组,第一行是一个整数t (t& ...
- 【C&数据结构】---关于链表结构的前序插入和后序插入
刷LeetCode题目,需要用到链表的知识,忽然发现自己对于链表的插入已经忘得差不多了,以前总觉得理解了记住了,但是发现真的好记性不如烂笔头,每一次得学习没有总结输出,基本等于没有学习.连复盘得机会都 ...
- 【11】-java递归和非递归二叉树前序中序后序遍历
二叉树的遍历 对于二叉树来讲最主要.最基本的运算是遍历. 遍历二叉树 是指以一定的次序访问二叉树中的每个结点.所谓 访问结点 是指对结点进行各种操作的简称.例如,查询结点数据域的内容,或输出它的值,或 ...
随机推荐
- manjar 搭建aria2c下载器
从添加或删除软件管理程序里安装 aria2. 在一个地方创建一个文本文件,名为 「aria2.conf」 : rpc-user=我是用户名 rpc-passwd=我是密码 enable-rpc=tru ...
- jquery防止快速点击
jquery防止快速点击(推荐第三种方式) //全站ajax加载提示 (function ($) { var str = '<div class="ajax-status" ...
- STM32 M0之SPI
从M3到M0,可能SPI的接口函数大致类似,但是细节略有不同 仔细观察寄存器描述,虽然个别存在差异,但是真心不知道竟然有太多的“玄机” 这次的问题主要出在了数据宽度上: 1. M3/M4的数据宽度支持 ...
- navicat破解版的下载与激活
原文链接:http://www.cnblogs.com/djwhome/p/9289295.html 以前一直使用的老版的破解版的navicat,但是最近老是报错 而且连接还特别慢,今天终于不忙了额, ...
- Minimizing Difference 【思维】
题目链接: https://vjudge.net/contest/336389#problem/B 题目大意: 给出一个长度为n的数列以及操作次数k.k的范围为1e14.每次操作都可以选择给任意一个数 ...
- axios设置请求头内容
axios设置请求头中的Authorization 和 cookie 信息: GET请求 axios.get(urlString, { headers: { 'Authorization': 'Bea ...
- Oracle的查询-自连接概念和联系
查询出员工姓名,员工领导姓名 select e1.ename,e2.ename from emp e1,emp e2 where e1.mgr = e2.empno; 结果 自连接:站在不同角度把一张 ...
- Linux系列(14)之工作管理
1.工作管理 说明:工作管理(job control)是用在bash环境下的,也就是说:“当我们登录系统取得bash shell之后,在单一终端机接口下同时进行多个工作的行为管理”.举例说明,我们在登 ...
- 在win7中解决Visual C++ 6.0打开文件时出现停止工作问题
在使用Visual C++ 6.0打开文件时可能会出现下面的情况 这可能是Vc6.0和win7兼容性问题. 方法: 下载filetool即可 链接:https://pan.baidu.com/s/1X ...
- 【第一季】CH07_FPGA_RunLED创建VIVADO工程实验
[第一季]CH07_FPGA_RunLED创建VIVADO工程实验 7.1 硬件图片 先来熟悉一下开发板的硬件:LED部分及按钮部分 7.2 硬件原理图 PIN脚定义(讲解以MIZ702讲解,MIZ7 ...