selenium入门学习
在写爬虫的学习过程中,经常会有一些动态加载,有些是可以动过接口直接获取到,但是实在没办法,所以学习下selenium。
首先百度一下:
Selenium [1] 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
首先下载:
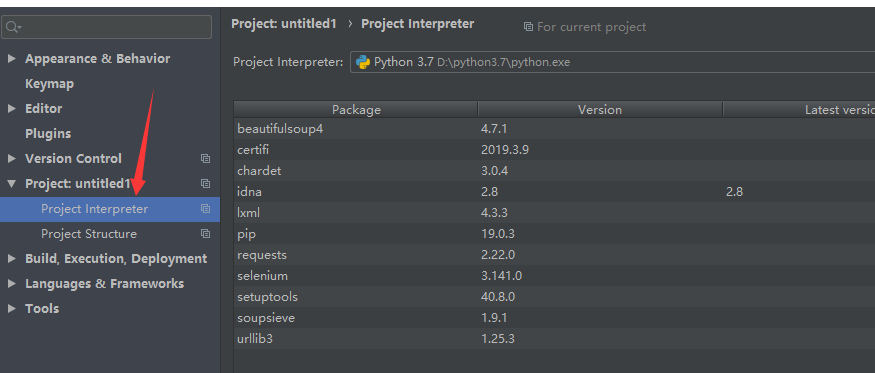
二: 下载chromedriver
找到本地chrome版本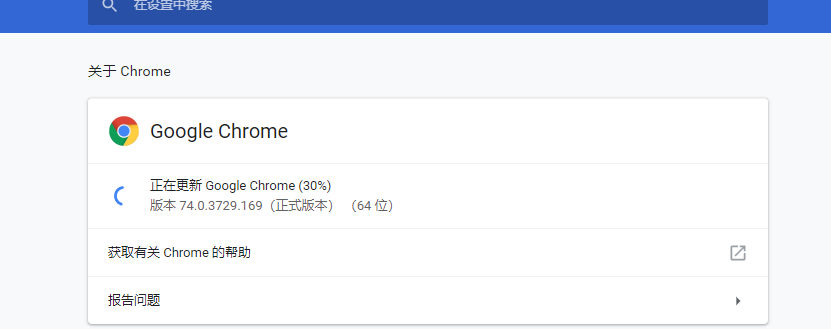
去队员的driver网站 http://npm.taobao.org/mirrors/chromedriver/ 下载(注意这里的win32兼容64位的)

接下来执行一小段代码

报错:
TypeError: 'module' object is not callable
解决办法
chrome-->Chrome 再次执行还是报错

解决办法,吧二进制包放到python家目录下面

或者
driver=webdriver.Chrome ('D:\python3.7\chromedriver') 写绝对路径
环境安装好了之后,一下是个基本应用:
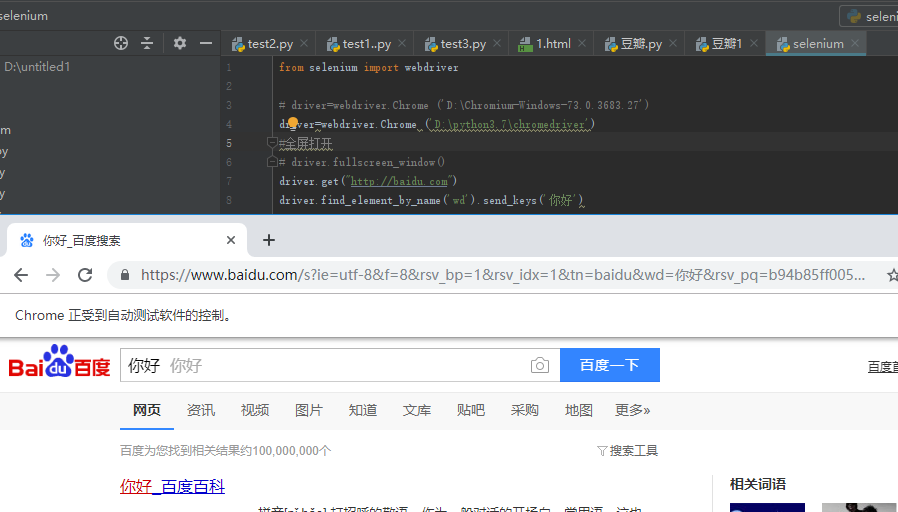
driver.quit()退出浏览器
elements=driver.find_elements_by_link_text("a")
for elment in elements:
if "新闻" in elment.test:
elment.clink()
elements=driver.find_elements_by_link_text("贴吧").click()
driver.back()
driver.find_element_by_partial_link_text("贴").click()driver.find_element_by_name('wd').send_keys('你好 \n')
driver.quit()
from selenium import webdriver # driver=webdriver.Chrome ('D:\Chromium-Windows-73.0.3683.27')
driver=webdriver.Chrome ('D:\python3.7\chromedriver')
#全屏打开
# driver.fullscreen_window()
driver.get("http://baidu.com")
#获取页面头部
baiduTitle = driver.title
print(baiduTitle)
#获取 带钱的url
currentUrl = driver.current_url
print(currentUrl)
# 页面刷新
driver.refresh()
#打开另一个url
driver.get("https://google.com")
#后退
driver.back()
#获取页面源代码
pageSource=driver.page_source
selenium入门学习的更多相关文章
- python3+selenium入门01-环境搭建
作为一个测试,在最近两年应该有明显的感觉.那就是工作变的难找,要求变的高了,自动化测试,性能测试等.没有自动化测试能力,只会点点点工作难找不说,工资也不高.所以还是要学习一些技术.首先要学习一门编程语 ...
- 自动化测试Java一:Selenium入门
From: https://blog.csdn.net/u013258415/article/details/77750214 Selenium入门 欢迎阅读Selenium入门讲义,本讲义将会重点介 ...
- Selenium自动化测试Python一:Selenium入门
Selenium入门 欢迎阅读Selenium入门讲义,本讲义将会重点介绍Selenium的入门知识以及Selenium的前置知识. 自动化测试的基础 在Selenium的课程以前,我们先回顾一下软件 ...
- vue入门学习(基础篇)
vue入门学习总结: vue的一个组件包括三部分:template.style.script. vue的数据在data中定义使用. 数据渲染指令:v-text.v-html.{{}}. 隐藏未编译的标 ...
- Hadoop入门学习笔记---part4
紧接着<Hadoop入门学习笔记---part3>中的继续了解如何用java在程序中操作HDFS. 众所周知,对文件的操作无非是创建,查看,下载,删除.下面我们就开始应用java程序进行操 ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- PyQt4入门学习笔记(三)
# PyQt4入门学习笔记(三) PyQt4内的布局 布局方式是我们控制我们的GUI页面内各个控件的排放位置的.我们可以通过两种基本方式来控制: 1.绝对位置 2.layout类 绝对位置 这种方式要 ...
- PyQt4入门学习笔记(一)
PyQt4入门学习笔记(一) 一直没有找到什么好的pyqt4的教程,偶然在google上搜到一篇不错的入门文档,翻译过来,留以后再复习. 原始链接如下: http://zetcode.com/gui/ ...
- Hadoop入门学习笔记---part2
在<Hadoop入门学习笔记---part1>中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱.不够系统化,不够简洁.经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建ha ...
随机推荐
- mysql之索引 应用于事物 内连接、左(外)连接、右(外)连接
什么是索引 索引就像是一本书的目录一样,能够快速找到所需要的内容 索引的作用 加快查询速率,降低IO成本加快表与表之间的连接,减少分组和排序时间 索引类型 普通索引:没有唯一性的基本索引 唯一索引:有 ...
- Python:目录
ylbtech-Python:目录 1.返回顶部 2.返回顶部 3.返回顶部 4.返回顶部 5.返回顶部 6.返回顶部 作者:ylbtech出处:http://ylbtec ...
- [Python]python-jenkins 启动需要参数的job
需求: 我要用python通过api,启动这个job,并且启动这个job需要1个参数 安装依赖: pipenv install python-jenkins 熟悉API的使用方法: 了解一个API的最 ...
- tensorflow二进制文件读取与tfrecords文件读取
1.知识点 """ TFRecords介绍: TFRecords是Tensorflow设计的一种内置文件格式,是一种二进制文件,它能更好的利用内存, 更方便复制和移动,为 ...
- netcore kafka操作
安装使用: 1:下载nuget包 Confluent.Kafka librdkafka.redist System.Runtime.CompilerServices.Unsafe 基于.net实现ka ...
- 六十七:flask上下文之Local线程隔离对象
Local对象在flask中,类似于request对象,其实是绑定到了werkzeug.local.Local对象上,这样即使是同一个对象,在多线程中都是隔离的,类似的对象还有session以及g对象 ...
- Jmeter测试结果分析(下)
Jmeter测试结果分析(下) 前文再续,续接上一回.上一篇讲了如何利用Assertion将测试结果进行初步的筛选.那么,当我们拿到了测试结果之后,我们应该如何去看待它们呢?它们又是怎么来的呢? 一. ...
- 如何删除link-local(169.255.0.0) 路由表项
route -n 时你总能看到这样一条路由Destination Gateway Genmask Flags Metric Ref Use Iface169.254.0.0 0.0.0.0 255.2 ...
- MYSQL查询今天、昨天、7天前、30天、本月数据
今天: SELECT * FROM 表名 WHERE TO_DAYS( 时间字段名) = TO_DAYS(NOW()); 昨天: SELECT * FROM 表名 WHERE TO_DAYS( NOW ...
- etcd 使用: golang 例子
一:连接到 etcd package main import ( "fmt" "go.etcd.io/etcd/clientv3" "time&quo ...