五、SSD原理(Single Shot MultiBox Detector)
主流的算法主要分为两个类型:
(1)tow-stage
R-CNN系列算法,其主要思路是先通过启发式方法(selective search)或者CNN网络(RPN)产生一些列稀疏的候选框,然后对这些候选框进行分类和回归。two-stage方法的优势是准确度高。
(2)one-stage
如YOLO和SSD,主要思路是均匀的在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类和回归,整个过程只需要一部,所以其优势是速度快。
均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本与负样本极其不平衡,导致模型准确度稍低,不同算法的性能如图:
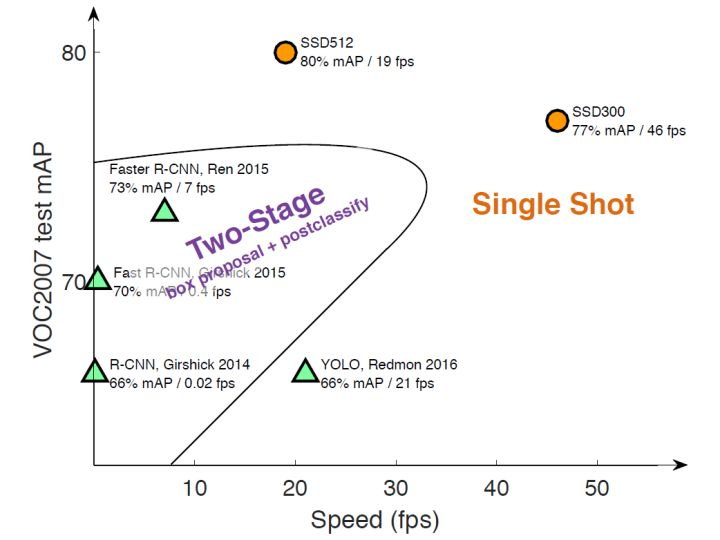
SSD英文名是(Single Shot MultiBox Detector),single shot指的是SSD算法属于one-stage方法,MultiBox说明SSD是多框预测。
上图可以看出SSD在准确度和速度(除了SSD512)上都比YOLO要好很多。
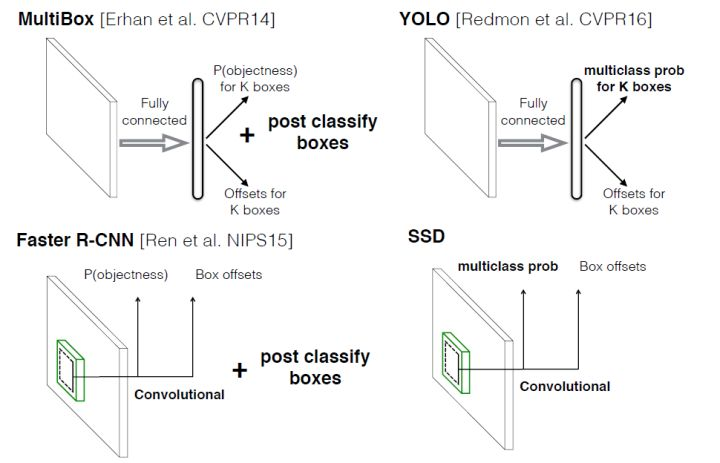
下图是不同算法的基本框架图,对于Faster R-CNN,其先通过CNN得到候选框,然后再进行分类和回归,而Yolo与SSD可以一步到位完成检测。相比于YOLO,SSD采用CNN来直接进行检测,而不是像YOLO那样在全连接层之后再做检测。
其实采用卷积直接做检测只是SSD相比于YOLO的其中一个不同点,另外还有两个重要的改变,一是SSD提取不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)用来检测小物体,小尺度特征图(较靠后的特征图,感受野大)用来检测大物体;二是SSD采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes,在Faster R-CNN中叫做锚,Anchors)。Yolo算法的缺点是难以检测小目标,而且定位不准,但是这几点重要的改进使得SSD在一定程度上克服这些缺点。
设计理念
SSD和YOLO都是采用一个CNN网络来进行检测,但是却采用了多尺度的特征图,其基本架构如下图,下面将SSD核心设计理念总结为以下三点:
(1)采用多尺度特征图用于检测
所谓多尺度采用大小不同的特征图,CNN网络一般前面的特征图比较大,后面会逐渐采用stride=2的卷积或者pool来降低特征图大小,下图所示,一个比较大的特征图和一个比较小的特征图,他们都用来做检测。这样做的好处是比较大的特征图用来检测相对较小的目标,而小的特征图负责检测大目标,8x8的特征图可以划分更多的单元,但是其每个单元的default box尺度比较小。

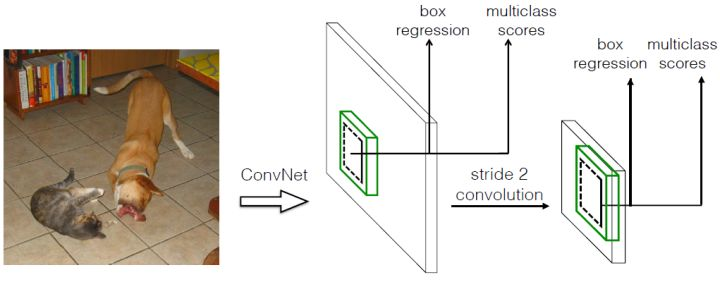
(2)采用卷积进行检测
与Yolo最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果。对于形状为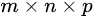 的特征图,只需要采用
的特征图,只需要采用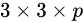 这样比较小的卷积核得到检测值。
这样比较小的卷积核得到检测值。
(3)设置先验框default boxes
在YOLO中,每个单元预测多个边界框,但是其都是相对这个单元本身(正方块),但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。而SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的default boxes,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。
一般情况下,每个单元会设置多个default boxes,其尺度和长宽比存在差异,如下图所示,可以看到每个单元使用了4个不同的default boxes,图片中猫和狗分别采用最适合它们形状的先验框来进行训练,后面会详细讲解训练过程中的先验框匹配原则。
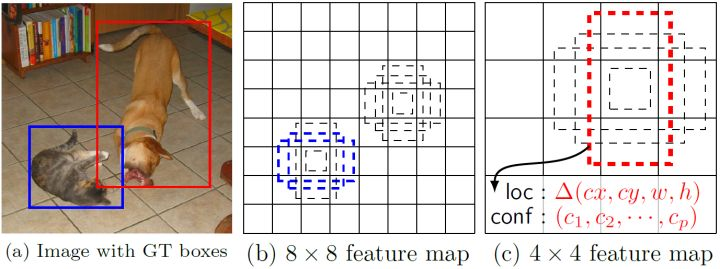
SSD的检测值也与YOLO不太一样,对于每个单元cell的每个先验框default box,其都输出一套独立的检测值,对于一个bouding box,主要分为两个部分:
- 第一个部分是各个类别的置信度或者评分
- 值得注意的是SSD将背景也当做了一个特殊的类别,如果检测目标共有c个类别,SSD其实需要预测c+1个置信度值,其中第一个置信度是不含目标或者属于背景的评分。后面当我们说c个类别置信度时,请记住里面包含背景那个特殊的类别,即真实的检测类别只有c-1个。
- 在预测过程中,置信度最高的那个类别就是边界框所属的类别。特别的,当第一个置信度最高时,表示边界框中并不包含目标。
- 第二个部分就是边界框的location,包含4个值
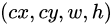 ,分别表示边界框的中心坐标以及宽高。但是真实预测其实只是预测边界框相对于先验框的转换值(offset)。
,分别表示边界框的中心坐标以及宽高。但是真实预测其实只是预测边界框相对于先验框的转换值(offset)。
- 先验框(anchor)位置用
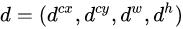 表示,其对应预测的边界框用
表示,其对应预测的边界框用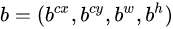 表示,那么边界框的预测值l其实是b相对于d的转换值:
表示,那么边界框的预测值l其实是b相对于d的转换值: 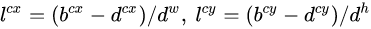
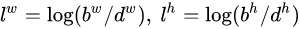
- 先验框(anchor)位置用
习惯上,我们称上面这个过程为边界框的编码(encode),预测时,你需要反向这个过程,即进行解码(decode),从预测值l中得到边界框的真实值b:
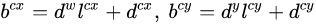
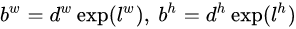
然而,在SSD的caffe源码实现中还有trick,那就是设置variance超参数来调整检测值,通过bool参数variance_encoded_in_target来控制两种模式。当其为true时,表示variance(方差)被包含在预测值中,就是上面那种情况,如果是false(大部分采用这种方式,训练更容易),就需要手动设置超参数variance,用来对l的4个值进行放缩,此时边界框需要这样解码:
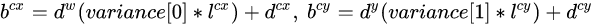
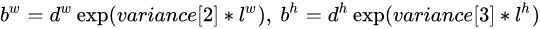
综上所述,对于一个大小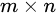 的特征图,共有m x n 个单元,每个单元设置的先验框数目记为k,那么每个单元共需要
的特征图,共有m x n 个单元,每个单元设置的先验框数目记为k,那么每个单元共需要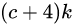 个预测值,所有的单元共需要
个预测值,所有的单元共需要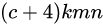 个预测值,由于SSD采用卷积做检测,所以就需要
个预测值,由于SSD采用卷积做检测,所以就需要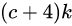 个卷积核来完成这个特征图的检测过程。(卷积核参数共享)。
个卷积核来完成这个特征图的检测过程。(卷积核参数共享)。
网络结构
SSD采用VGG16作为基础模型,然后在VGG16的基础上新增了卷几层来获得更多的特征图以用于检测。SSD网络结构如图所示:

很明显可以看出SSD利用了多尺度的特征图做检测,模型的输入图片大小是 (还可以是
(还可以是 ),其与前者网络结构没有差别,只是最后新增一个卷积层。
),其与前者网络结构没有差别,只是最后新增一个卷积层。
采用VGG16做基础模型,首先VGG16是在ILSVRC CLS-LOC数据集预训练。然后借鉴了DeepLab-LargeFOV,分别将VGG16的全连接层fc6和fc7转换成 卷积层 conv6和
卷积层conv7,同时将池化层pool5由原来的stride=2的
变成stride=1的
(猜想是不想reduce特征图大小),为了配合这种变化,采用了一种Atrous Algorithm,其实就是conv6采用扩展卷积或带孔卷积(Dilation Conv),其在不增加参数与模型复杂度的条件下指数级扩大卷积的视野,其使用扩张率(dilation rate)参数,来表示扩张的大小,如下图6所示,(a)是普通的
卷积,其视野就是
,(b)是扩张率为1,此时视野变成
,(c)扩张率为3时,视野扩大为
,但是视野的特征更稀疏了。Conv6采用
大小但dilation rate=6的扩展卷积。

然后移除dropout层和fc8层,并新增一系列卷积层,在检测数据集上做finetuing。
其中VGG16中的Conv4_3层将作为用于检测的第一个特征图。conv4_3层特征图大小是 ,但是该层比较靠前,其norm(范数)较大,所以在其后面增加了一个L2 Normalization层(参见ParseNet),以保证和后面的检测层差异不是很大,这个和Batch Normalization层不太一样,其仅仅是对每个像素点在channle维度做归一化,而Batch Normalization层是在[batch_size, width, height]三个维度上做归一化。归一化后一般设置一个可训练的放缩变量gamma,使用TF可以这样简单实现:
# l2norm (not bacth norm, spatial normalization)
def l2norm(x, scale, trainable=True, scope="L2Normalization"):
n_channels = x.get_shape().as_list()[-1]
l2_norm = tf.nn.l2_normalize(x, [3], epsilon=1e-12)
with tf.variable_scope(scope):
gamma = tf.get_variable("gamma", shape=[n_channels, ], dtype=tf.float32,
initializer=tf.constant_initializer(scale),
trainable=trainable)
return l2_norm * gamma
从后面新增的卷积层中提取Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2作为检测所用的特征图,加上Conv4_3层,共提取了6个特征图,其大小分别是 ,但是不同特征图单元cell设置的先验框数目不同(同一个特征图上每个单元设置的先验框是相同的,这里的数目指的是一个单元的先验框数目)。先验框的设置,包括尺度(或者说大小)和长宽比两个方面。对于先验框的尺度,其遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加
每一个feature map中的每一个小格子(cell)都包含多个default box,同时每个box对应loc(位置坐标)和conf(每个种类的得分)。
default box长宽比例默认有四个和六个:
四个default box是长宽比(aspect ratios)为(1:1)、(2:1)、(1:2)、(1:1);六个则是添加了(1:3)、(3:1)
为什么会有两个(1:1)呢。这时候就要讲下论文中Choosing scales and aspect ratios for default boxes这段内容了。作者认为不同的feature map应该有不同的比例(一个大框一个小框,长宽比相同,大框是指不同feature map 相对于原图的尺寸比例不同),这是什么意思呢,代表的是default box中这个1在原图中的尺寸是多大的,计算公式如下所示:

Sk即代表在300*300输入中的比例,表示先验框大小相对于图片的比例
m为当前的feature map是第几层; m=5,因为一共有6个feature map,但是第一层(Conv4_3层)是单独设置的
k代表的是一共有多少层的feature map
Smin和Smax代表的是第一层和最后一层所占的比例,比例的最小值和最大值,在ssd300中为0.2-0.9。
计算:
第一个feature map 是 conv4_3:默认设置比例为0.2/2=0.1, 此时k=1
第二个feature map 是 conv7: k=2,s = 0.2 +(0.7/4) x (2-1) =0.375 ,最后300x0.375 = 112.5,这个就是在这个feature map中比例为1的这个default box 的尺寸相对于原图300x300 的大小。
为什么default box的size有两个1吗?
作者在这有引入了一个
,也就是每个特征图都设置了两个长宽比为1大小不同的正方形default box。有的小伙伴可能会有疑问,这有了Sk+1则需要多出来一部分的Sk啊,是的没错,最后一个特征图需要参考
来计算
,因此每个特征图(的每个cell)都有6个default box
(aspect ratios),但是在实现时, Conv4_3,Conv10_2,Conv11_2仅仅使用4个先验框(default box),不使用长宽比为3,1/3的先验框(default box)。作者的代码中就添加了两层,第一层取0.1,最后一层取1。
注:对于第一个特征图,先验框(default box)的尺度比例一般
,则尺度为300x0.1=30。
对于后面的特征图,先验框尺度比例按照上面公式线性增加,先将尺度比例放大100倍,然后再计算得到Sk,然后再将Sk除以100,再乘以图片大小,就可以得到各个特征图的先验框的size
那么S怎么用呢?按如下方式计算先验框的宽高(这里的Sk是上面求得的各个特征图的先验框的实际size,不再是尺度比例):
ar代表的是之前提到的default box(aspect ratios)比例,即
对于default box中心点的值取值为:
其中i,j代表在feature map中的水平和垂直的第几格
fk代表的是feature map的size
每个单元的先验框中心点分布在各单元的中心
得到特征图后,需要对特征图进行卷积得到检测结果,下图给出了一个5x5大小的特征图检测过程:
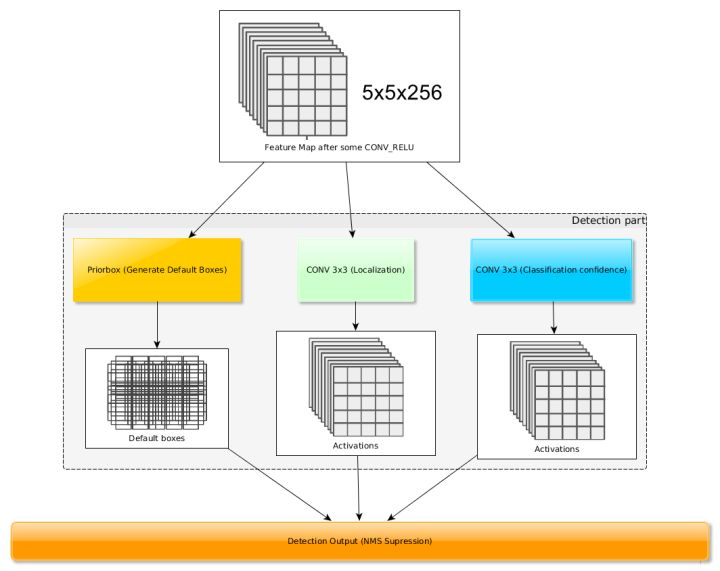
Priorbox是得到先验框,生成规则前面已经讲了。
检测值包含两个部分:类别置信度和边界框位置,各采用一次3x3卷积来进行完成。
是该特征图所采用的先验框数目,那么类别置信度需要的卷积核数量为
,而边界框位置需要的卷积核数量为
。由于每个先验框都会预测一个边界框,所以SSD300一共可以预测
Conv4_3 得到的feature map大小为38*38:38*38*4 = 5776
Conv7 得到的feature map大小为19*19:19*19*6 = 2166
Conv8_2 得到的feature map大小为10*10:10*10*6 = 600
Conv9_2 得到的feature map大小为5 * 5 :5 * 5 * 6 = 150
Conv10_2得到的feature map大小为3 * 3 :3 * 3 * 4 = 36
Conv11_2得到的feature map大小为1 * 1 :1 * 1 * 4 = 4
最后结果为:8732
个边界框,这是一个相当庞大的数字,所以说SSD本质上是密集采样。
训练过程
(1)先验框匹配
在训练过程中,首先要确定训练图片中的ground truth(真实目标)与哪个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。
Yolo中,ground truth的中心落在哪个单元格,该单元格中与其IOU最大的边界框负责预测它。
SSD中,先验框与ground truth的匹配原则又两点:
1、每个ground truth找到与其IOU最大的先验框,互相匹配。该先验框称为正样本(先验框对应的预测box)
若有个先验框没有与ground truth匹配,就只能与背景匹配,就是负样本。(一个图片中ground truth少,但先验框多,这样匹配,很多先验框会是负样本,正负样本不均衡)。
2、对剩余未匹配先验框,若某个ground truth的IOU大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配。
这样ground truth可能与多个先验框匹配
FP:负样本 TP:正样本
尽管一个ground truth可以与多个先验框匹配,但是ground truth相对于先验框还是太少了,所以负样本会很多。为保证正负样本尽量均衡,SSD采用了hard negative mining,先将每一个物体位置上对应 predictions(default boxes)是 negative 的 boxes 进行排序,按照 default boxes 的 confidence 的大小。 选择最高的几个,保证最后 negatives、positives 的比例接近3:1
(2)损失函数
损失函数定义为位置误差(locatization loss, loc)与置信度误差(confidence loss, conf)的加权和:
其中
是先验框的正样本数量。
这里
为一个指示参数,当
时表示第
个先验框与第
个ground truth匹配,并且ground truth的类别为
。
为类别置信度预测值。
为先验框的所对应边界框的位置预测值
是ground truth的位置参数
对于位置误差,其采用Smooth L1 loss,定义如下:
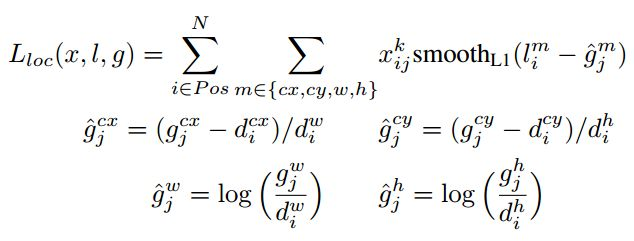
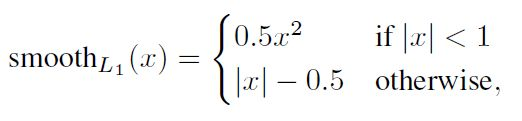
由于
的存在,所以位置误差仅针对正样本进行计算。值得注意的是,要先对ground truth的
,因为预测值
对于置信度误差,其采用softmax loss:
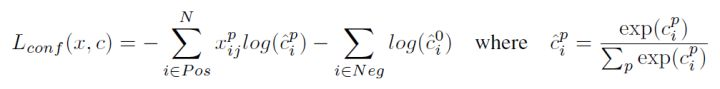
权重系数 通过交叉验证设置为1。
(3)数据扩增
采用数据扩增(Data Augmentation)可以提升SSD的性能,主要采用的技术有水平翻转(horizontal flip),随机裁剪加颜色扭曲(random crop & color distortion),随机采集块域(Randomly sample a patch)(获取小目标训练样本),如下图所示:

预测过程
确定预测框类别(置信度最大者)与置信度值,并且过滤掉属于背景的预测框,过滤掉置信度阈值较低的预测框;
对留下的预测框进行编码,得到真实的位置参数(解码后还需要clip,防止预测框位置超出图片);
解码之后,根据置信度进行降序排列,保留top-k个预测框;
进行NMS算法,过滤掉那些重叠度比较大的预测框,最后剩余的预测框就是检测结果了。
性能评估
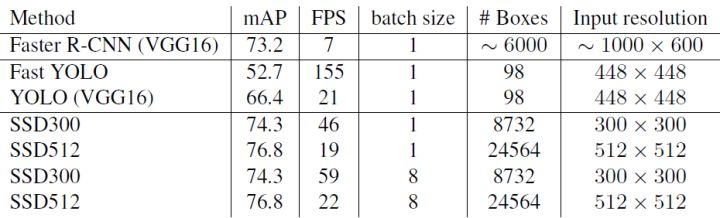
首先整体看一下SSD在VOC2007,VOC2012及COCO数据集上的性能,如表1所示。相比之下,SSD512的性能会更好一些。加*的表示使用了image expansion data augmentation(通过zoom out来创造小的训练样本)技巧来提升SSD在小目标上的检测效果,所以性能会有所提升。
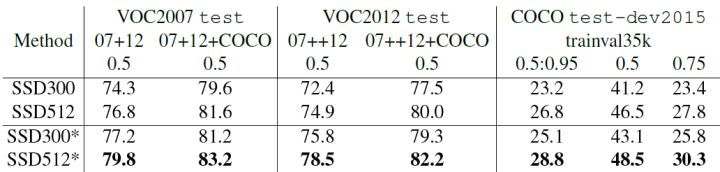
SSD与其它检测算法的对比结果(在VOC2007数据集)如表2所示,基本可以看到,SSD与Faster R-CNN有同样的准确度,并且与Yolo具有同样较快地检测速度。
文章还对SSD的各个trick做了更为细致的分析,表3为不同的trick组合对SSD的性能影响,从表中可以得出如下结论:
- 数据扩增技术很重要,对于mAP的提升很大;
- 使用不同长宽比的先验框可以得到更好的结果;

同样的,采用多尺度的特征图用于检测也是至关重要的,这可以从表4中看出:

补充
1、L2 normalization
2、hard nevigating mining
五、SSD原理(Single Shot MultiBox Detector)的更多相关文章
- SSD(single shot multibox detector)
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法,截至目前是主要的检测框架之一,相比Faster RCNN有明显的速 ...
- SSD(single shot multibox detector)算法及Caffe代码详解[转]
转自:AI之路 这篇博客主要介绍SSD算法,该算法是最近一年比较优秀的object detection算法,主要特点在于采用了特征融合. 论文:SSD single shot multibox det ...
- 翻译SSD论文(Single Shot MultiBox Detector)
转自http://lib.csdn.net/article/deeplearning/53059 作者:Ai_Smith 本文翻译而来,如有侵权,请联系博主删除.未经博主允许,请勿转载.每晚泡脚,闲来 ...
- 目标检测--SSD: Single Shot MultiBox Detector(2015)
SSD: Single Shot MultiBox Detector 作者: Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, ...
- 论文笔记 SSD: Single Shot MultiBox Detector
转载自:https://zhuanlan.zhihu.com/p/33544892 前言 目标检测近年来已经取得了很重要的进展,主流的算法主要分为两个类型(参考RefineDet):(1)two-st ...
- SSD(Single Shot MultiBox Detector)的安装配置和运行
下文图文介绍转自watersink的博文SSD(Single Shot MultiBox Detector)不得不说的那些事. 该方法出自2016年的一篇ECCV的oral paper,SSD: Si ...
- SSD: Single Shot MultiBox Detector
By Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexande ...
- 机器视觉:SSD Single Shot MultiBox Detector
今天介绍目标检测中非常著名的一个框架 SSD,与之前的 R-CNN 系列的不同,而且速度比 YOLO 更快. SSD 的核心思想是将不同尺度的 feature map 分成很多固定大小的 box,然后 ...
- SSD: Single Shot MultiBox Detector 编译方法总结
SSD是一个基于单网络的目标检测框架,它是基于caffe实现的,所以下面的教程是基于已经编译好的caffe进行编译的. caffe的编译可以参考官网 caffe Installation Instal ...
随机推荐
- hdu 6182
A Math Problem Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...
- RMQ((Range Minimum/Maximum Query))ST算法
给定一个数组,求出给定区间[l,r]中元素的最大值或最小值或者最值的索引. 一看到这个题目,简单,看我暴力出奇迹.暴力当然是可行的.但是时间复杂度很高(O(n^2)).线段树,树状数组也可以解决这个问 ...
- java如何在不访问数据库就可以对list分页?
废话不多说,直接上代码 import java.util.ArrayList; import java.util.List; public class demo { public static voi ...
- js通俗易懂的&&与||或运算
使用&&将返回第一个条件为假的值. 如果每个操作数的计算值都为true, 则返回最后一个计算过的表达式. let one = 1, two = 2, three = 3;console ...
- iOS 超级签名详解
一.原理 把安装设备当做开发设备进行分发.说的明白一些,开发者可以在开发者后台添加手机的UDID,然后重新打包一个IPA文件,分发平台,然后被添加的UDID就可以下载. 二.优缺点 优势: 直接分发, ...
- mongodb备份每一天的数据
需求:把mongodb里面存储6个月的数据备份到本地,一天天的来备份,方便对备份管理.然后mongo保留一周的数据(优化查询速度,可以用mongo的ttl来实现,但是我的业务场景不太适合用ttl索引) ...
- 扩展的KMP算法图解
扩展的KMP算法,可以在Ο(n + m)的时间复杂度内计算出模板串与文本串的每一个后缀的最长公共前缀,即LCP(T[i:n],P). KMP算法所解决的单模板字符串匹配问题,求得的匹配点是LCP = ...
- 用python计算最高投标限价
题目是文绉绉的说法,背景来于群里提问,是一份文件里面关于最高投标限价的确定. 最高投标限价下浮率在开标前在开标现场采取逐标段摇珠方式确定,摇珠操作办法如下:在下浮率摇珠范围内,以0.1%为以一档次增序 ...
- 《流畅的Python》Data Structures--第7章 colsure and decorator
Function Decorators and Closures 装饰器是用于增强函数的行为,理解它,就必须先理解闭包. Python3引入关键字nonlocal,如果要理解闭包,就必须了解它的所有方 ...
- 分享一波目前写的最强的autohotkey 插件
支持各种软件快速切换,补全括号,代码等!!!!!!!! ;这种全局定义要写在所有代码的前面才能让所有代码起作用. SetCapsLockState , AlwaysOff SetNumlockStat ...