MySQL中索引和优化的用法总结
1、什么是数据库中的索引?索引有什么作用?
引入索引的目的是为了加快查询速度。如果数据量很大,大的查询要从硬盘加载数据到内存当中。
2、InnoDB中的索引原理是怎么样的?
InnoDB是Mysql的默认存储引擎,InnoDB有两种索引:B+树索引和哈希索引,其中哈希索引是自适应性的,存储引擎会根据表的使用情况,自动创建哈希索引,不能人为的干涉。
B树、B-树、B+树、B*树四种数据结构在索引中的运用,这四种数据结构的顺序必须是这样的。分别阐述如下:
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点; B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中; B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中; B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
首先,B树也叫作二叉搜索树,字如其义。B树有如下三个特点:所有非叶子节点至多拥有两个儿子;所有节点存储一个关键字;非叶子节点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树。
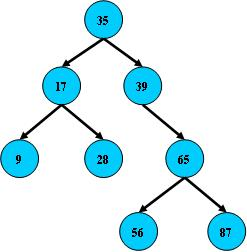

B树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中,否则,如果查询关键字比结点关键字小,就进入左儿子;如果比结点关键字大,就进入右儿子;如果左儿子或右儿子的指针为空,则报告找不到相应的关键字。如果B树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变B树结构(插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销。最右边也是一个B树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的树结构索引;所以,使用B树还要考虑尽可能让B树保持左图的结构,和避免右图的结构,也就是所谓的“平衡”问题;实际使用的B树都是在原B树的基础上加上平衡算法,即“平衡二叉树”;如何保持B树结点分布均匀的平衡算法是平衡二叉树的关键;平衡算法是一种在B树中插入和删除结点的策略;
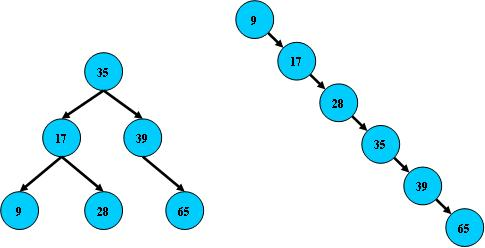
其次,B-树。数据量越大,B树的高度会越高,之所以会越高,主要是因为二叉引起的。所以在此基础上我们定义了B-树的规范如下:B-树不是二叉的,所以又叫作多路搜索树。

B-树是一种多路搜索树(并不是二叉的): 1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];除根结点以外的非叶子结点的儿子数为[M/2, M];
3.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
4.非叶子结点的关键字个数=指向儿子的指针个数-1;
5.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
6.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
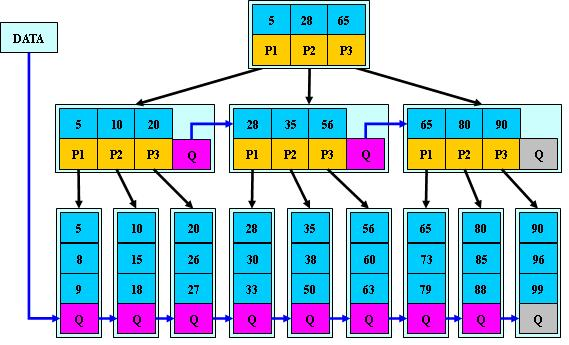
7.所有叶子结点位于同一层;如图所示中(M=3)
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点重复,直到所对应的儿子指针为空,或已经是叶子结点。
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率,其最底搜索性能如图,
其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
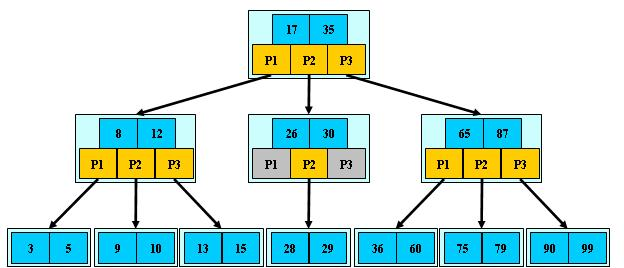
其次,B+树。B树、B-树、B+树、B*树。B树是二叉搜索树,B-树、B+树、B*树都是多路搜索树。B-树定义了基本的规范,它有个特点,关键字出现在非叶子节点或者叶子节点,子树的指针比关键字个数大一个。B+树在这两方面分别做了升级,定义如下:
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树
(B-树是开区间);
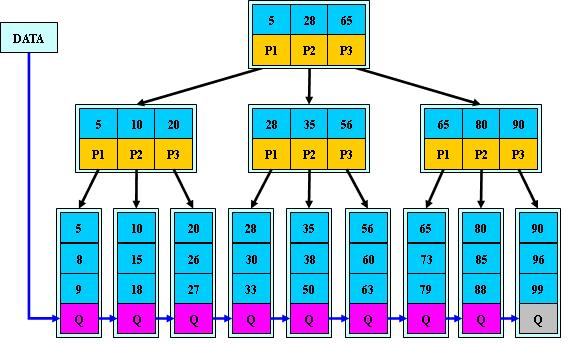
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
最后B*树,它是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针。
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2); B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针; B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);
如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针; 所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
3、如何在Navicat中对表添加索引?
#删除表
DROP TABLE test.idc_work_order_main # 创建表结构idc_work_order_main
CREATE TABLE `idc_work_order_main` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`creator` varchar(128) NOT NULL DEFAULT '0' COMMENT '创建人',
`gmt_create` timestamp NULL DEFAULT NULL COMMENT '创建时间',
`modifier` varchar(128) DEFAULT '0' COMMENT '修改人',
`gmt_modified` timestamp NULL DEFAULT NULL COMMENT '修改时间',
`title` varchar(64) DEFAULT NULL COMMENT '工单标题',
`category` varchar(32) DEFAULT NULL COMMENT '工单类别',
`subject` varchar(32) DEFAULT NULL COMMENT '工单类型',
`demander` varchar(30) DEFAULT NULL COMMENT '需求方',
`is_atomic` char(1) DEFAULT 'y' COMMENT '是否原子工单',
`atomic_id` int(11) DEFAULT NULL COMMENT '当前原子工单在列表中ID',
`site` varchar(50) DEFAULT NULL COMMENT '工单所在机房',
`operationer` varchar(32) DEFAULT NULL COMMENT '当前处理人',
`operation_role` varchar(50) DEFAULT NULL COMMENT '当前处理角色',
`state` varchar(50) DEFAULT NULL COMMENT '工单状态',
`sub_state` varchar(50) DEFAULT NULL COMMENT '工单子状态',
`expect_time` timestamp NULL DEFAULT NULL COMMENT '预期结单时间',
`sla` bigint(20) DEFAULT NULL COMMENT 'sla',
`evaluation` varchar(200) DEFAULT NULL COMMENT '评价',
`create_source` varchar(32) DEFAULT 'TBOSS' COMMENT '创建源',
`source_key` varchar(32) DEFAULT NULL COMMENT '创建源唯一标示',
`is_deleted` char(1) DEFAULT 'n' COMMENT '是否已删除y,n',
`remark` varchar(500) DEFAULT NULL COMMENT '备注',
`parent_id` int(11) DEFAULT '0' COMMENT '父工单ID',
`asset_total` int(11) DEFAULT '0' COMMENT '设备总数',
`sla_standard` double DEFAULT NULL COMMENT '标准时间',
`sla_unit` char(1) DEFAULT NULL COMMENT 'sla 单位',
`effective_date` timestamp NULL DEFAULT NULL COMMENT '提单时间(生效时间)',
`is_timeout` char(1) DEFAULT 'n' COMMENT '是否超时,‘y’超时,‘n’未超时',
`statement_date` timestamp NULL DEFAULT NULL COMMENT '结单的时间',
`source_creator` varchar(32) DEFAULT NULL COMMENT '第三方创建人信息(域账号)',
`atomic_order_id` int(11) DEFAULT NULL COMMENT '当前原子工单编号',
`order_device_type` varchar(50) DEFAULT 'SERVER' COMMENT '工单设备类型(server=服务器,network_serve等)',
`finish_asset_total` int(11) DEFAULT '0' COMMENT '完成设备数',
PRIMARY KEY (`id`),
KEY `idx_statement_date` (`statement_date`),
KEY `idx_parent_id` (`parent_id`),
KEY `idx_gmt_modified` (`gmt_modified`),
KEY `idx_gmt_create` (`gmt_create`)
) ENGINE=InnoDB AUTO_INCREMENT=182431 DEFAULT CHARSET=utf8 COMMENT='工单主表'; #显示建表信息
SHOW CREATE TABLE idc_work_order_main #添加索引
ALTER TABLE idc_work_order_main ADD INDEX atomic_order_id (atomic_order_id)
SHOW INDEX FROM idc_work_order_main
EXPLAIN SELECT * FROM idc_work_order_main WHERE atomic_order_id = '9956' #添加主键 (唯一)
ALTER TABLE idc_work_order_main ADD PRIMARY KEY source_creator (source_creator) #添加唯一索引
ALTER TABLE idc_work_order_main ADD UNIQUE source_creator (source_creator)
SHOW INDEX FROM idc_work_order_main #添加联合索引
ALTER TABLE idc_work_order_main ADD INDEX id_source_parent_create_atomic (id,source_creator,parent_id,gmt_create,atomic_order_id)
SHOW INDEX FROM idc_work_order_main
关于索引:
1.一本书光目录就占半本书,目录(索引)还有意义吗?索引过多一定情况下会导致索引文件过大(指数增长),系统在寻址时查询时间增长。
2.性别字段就男女两个,加索引纯浪费。一个索引会在 update 或 insert 时增加一次 I/O,对于操作系统底层来说是非常损耗性能的。
3.首先mysql是B+树索引,这种作为索引的好处是可以对有序的记录作logN级的查找,不过对于没有大小之分的数据来说,还是建立哈希索引更好,因为哈希索引的时间复杂度基本是log1的。(注意此处有序和无序的概念)。
4.索引的命名规则:表名_字段名,需要加索引的字段,要在where条件中,数据量少的字段不需要加索引,如果where条件中是OR关系,加索引不起作用,符合最左原则。
4、索引中的index和key的使用
key 是数据库的物理结构,处于模型层面的,它包含两层意义和作用,一是约束(偏重于约束和规范数据库的结构完整性),二是索引(辅助查询用的)。包括primary key, unique key, foreign key 等。
primary key 有两个作用,一是约束作用(constraint),用来规范一个存储主键和唯一性,但同时也在此key上建立了一个index;
unique key 也有两个作用,一是约束作用(constraint),规范数据的唯一性,但同时也在这个key上建立了一个index;
foreign key也有两个作用,一是约束作用(constraint),规范数据的引用完整性,但同时也在这个key上建立了一个index;
可见,mysql的key是同时具有constraint和index的意义,这点和其他数据库表现的可能有区别。index是数据库的物理结构,处于实现层面的,它只是辅助查询的,它创建时会在另外的表空间(mysql中的innodb表空间)以一个类似目录的结构存储。索引只是索引,它不会去约束索引的字段的行为(那是key要做的事情)。Mysql常见索引有:主键索引、唯一索引、普通索引、全文索引、组合索引。
参考:
1.http://www.data.5helpyou.com/article392.html
2.关于where条件中or对索引影响:http://blog.csdn.net/hguisu/article/details/7106159
MySQL中索引和优化的用法总结的更多相关文章
- mysql 中合并查询结果union用法 or、in与union all 的查询效率
mysql 中合并查询结果union用法 or.in与union all 的查询效率 (2016-05-09 11:18:23) 转载▼ 标签: mysql union or in 分类: mysql ...
- MySQL函数索引及优化
很多开发人员在使用MySQL时经常会在部分列上进行函数计算等,导致无法走索引,在数据量大的时候,查询效率低下.针对此种情况本文从MySQL5.7 及MySQL8.0中分别进行不同方式的优化. 1. M ...
- 一天五道Java面试题----第九天(简述MySQL中索引类型对数据库的性能的影响--------->缓存雪崩、缓存穿透、缓存击穿)
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 1.简述MySQL中索引类型对数据库的性能的影响 2.RDB和AOF机制 3.Redis的过期键的删除策略 4.Redis ...
- mysql中isnull,ifnull,nullif的用法
今天用到了MySql里的isnull才发现他和MSSQL里的还是有点区别,现在简单总结一下: mysql中isnull,ifnull,nullif的用法如下: 1. isnull(expr) 的用法: ...
- MySQL中索引的基础知识
本文是关于MySQL中索引的基础知识.主要讲了索引的意义与原理.创建与删除的操作.并未涉及到索引的数据结构.高性能策略等. 一.概述 1.索引的意义:用于提高数据库检索数据的效率,提高数据库性能. 数 ...
- MySQL 中索引的限制
MySQL 中索引的限制在使用索引的同时,我们还应该了解在MySQL 中索引存在的限制,以便在索引应用中尽可能的避开限制所带来的问题.下面列出了目前MySQL 中索引使用相关的限制.1. MyISAM ...
- MySQL 中now()时间戳用法
MySQL 中now()时间戳用法 UPDATE news set addtime = unix_timestamp(now()); #结果:1452001082
- MySQL索引,MySQL中索引的限制?
MySQL中索引的限制: 1.MyISAM存储引擎引键的长度综合不能超过1000字节: 2.BLOB和TEXT类型的列只能创建前缀索引: 3.MySQL目前不支持函数索引: 4.使用!= 或者< ...
- (转) MySQL中索引的限制
转:http://book.51cto.com/art/200906/132459.htm 8.4.8 MySQL中索引的限制 在使用索引的同时,还应该了解MySQL 中索引存在的限制,以便在索引应 ...
随机推荐
- Go语言实战 - 创业进行时之创业伊始
在工作了10年之后,我于32岁的年纪在两个月前辞职创业了. 简单介绍一下之前的整个职业生涯,挺典型的,工程师 –> 资深工程师 –> 架构师 –> 项目经理 –> 部门经理,可 ...
- [ASP.NET MVC 小牛之路]03 - Razor语法
本人博客已转移至:http://www.exblr.com/liam Razor是MVC3中才有的新的视图引擎.我们知道,在ASP.NET中,ASPX的视图引擎依靠<%和%>来调用C#指 ...
- iOS 代码规范
1 目的 统一规范XCode编辑环境下Objective-C.swift的编码风格和标准 2 适用范围 适用于所有用Objective-C,swift语言开发的项目. 3 编码规范 3.1 文件 项目 ...
- Thrift架构~目录
回到占占推荐博客索引 概念相关 thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发.它结合了功能强大的软件堆栈和代码生成引擎,以构建在 C++, Java, Python, PHP, Ru ...
- jQuery Colorbox弹窗插件使用教程小结、属性设置详解
jQuery Colorbox是一款弹出层,内容播放插件,效果极佳,当然我主要是用来弹出图片啦. jQuery Colorbox不仅有弹性动画效果,淡入淡出效果,幻灯片播放,宽度自定义,还能够ajax ...
- KnockoutJS 3.X API 第六章 组件(2) 组件注册
要使Knockout能够加载和实例化组件,必须使用ko.components.register注册它们,从而提供如此处所述的配置. 注意:作为替代,可以实现一个自定义组件加载器(自定义加载器下一节介绍 ...
- CSS3总结 (帅哥)
第1章CSS3简介 如同人类的的进化一样,CSS3是CSS2的"进化"版本,在CSS2基础上,增强或新增了许多特性, 弥补了CSS2的众多不足之处,使得Web开发变得更为高效和便捷 ...
- MongoDB 分片管理
在MongoDB(版本 3.2.9)中,分片集群(sharded cluster)是一种水平扩展数据库系统性能的方法,能够将数据集分布式存储在不同的分片(shard)上,每个分片只保存数据集的一部分, ...
- jQuery 2.0.3 源码分析Sizzle引擎 - 超级匹配
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢! 通过Expr.find[ type ]我们找出选择器最右边的最终seed种子合集 通过Sizzle.compile函数编译器 ...
- 动态给div中新增html
小颖最近接触的项目中用到了 innerHTML 所以小颖今天就自己做了个demo,当当当当代码请看下方: 页面效果: