开源分布式中间件 DBLE 快速入门指南
GitHub:https://github.com/actiontech/dble
官方中文文档:https://actiontech.github.io/dble-docs-cn/
一、环境准备
DBLE项目资料
安装JDK环境
二、安装DBLE
三、配置DBLE
应用场景一:数据拆分
应用场景二:读写分离
四、总结
环境准备
DBLE 项目资料
DBLE 是企业级开源分布式中间件,江湖人送外号 “MyCat Plus”;以其简单稳定,持续维护,良好的社区环境和广大的群众基础得到了社区的大力支持;
DBLE官方网站:
https://opensource.actionsky.com
可以详细了解DBLE的背景和应用场景,本文不涉及到的细节都可在官方文档获得更细节都信息;对于刚了解到同学,可以以本文为快速入门基础
DBLE 官方项目:
https://github.com/actiontech/dble
如对源码有兴趣或者需要定制的功能的可以通过源码编译安装
DBLE 下载地址:
https://github.com/actiontech/dble/releases
DBLE 官方社区交流群:669663113
安装 JDK 环境
DBLE 是使用 java 开发的,所以启动 DBLE 需要先在机器上安装 java 版本 1.8 或以上,并且确保 JAVA_HOME 参数被正确的设置;
这里通过 yum 源的方式安装 openjdk ,同学们可以自行 google jdk 的几百种安装方式,这里不再赘述;

确认 java 环境已配置完成;

安装 DBLE
DBLE 的安装其实只要解压下载的目录就可以了,非常简单。
- 通过此连接下载最新安装包:https://github.com/actiontech/dble/releases
- 解压并安装 DBLE 到指定文件夹中

安装完成后,目录如下:
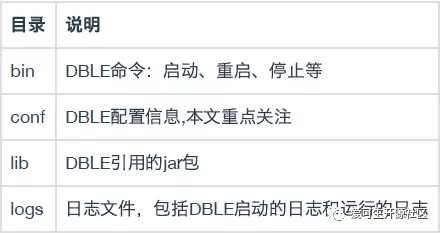
配置 DBLE
DBLE 的配置文件都在 conf 目录里面,这里介绍几个常用的文件:

应用场景一:数据拆分
▽ 后端 MySQL 节点
DBLE 的架构其实很好理解,DBLE 是代理中间件,DBLE 后面就是物理数据库。对于使用者来说,访问的都是 DBLE,不会接触到后端的数据库。
我们先演示简单的数据拆分的功能。物理部署结构如下表:
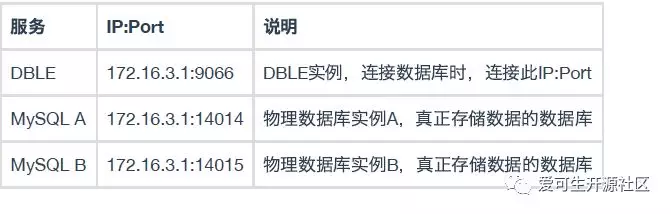
备注:为了演示简单,这里将实例都部署在了一台机器上并用不同端口做区分,同学们也可以用三台机器来做环境搭建。
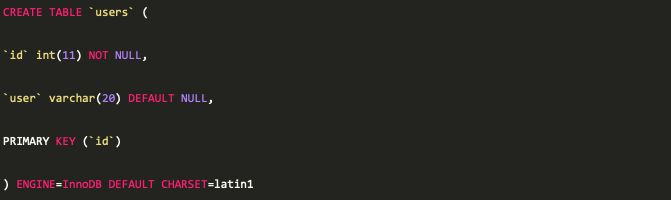
在MySQL A和MySQL B中创建库表testdb.users来方便后续的验证,表结构如下:
▽ server.xml
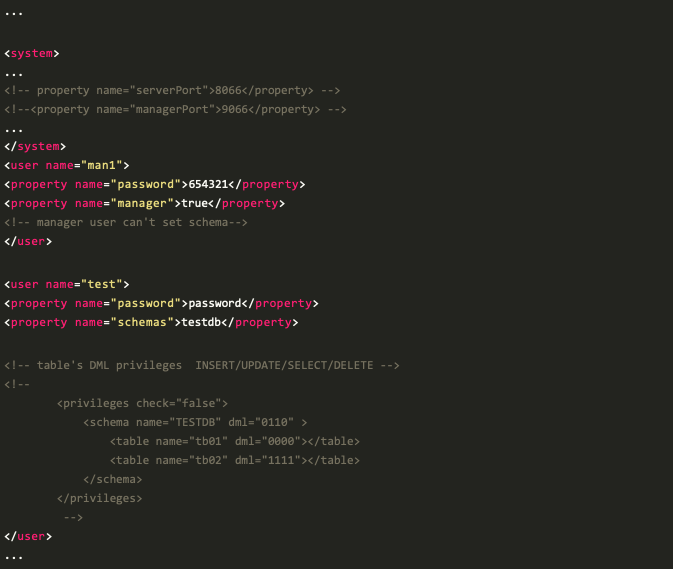
server.xml 里可以配置跟 DBLE 自身相关的许多参数,这里重点只关注下面这段访问用户相关的配置,其他默认即可;
第一段 “< system >” 为 DBLE 的服务端口(默认8066)和管理端口(默认9066)的配置
- 管理端口只能接受 DBLE 的管理命令,这里不做展开
- 服务端口即 DBLE 的业务访问端口,可以接受SQL语句
第二段“< user >”配置管理理用户,默认为 man1,密码为 654321
- 即可以通过 mysql -P9066 -h 127.0.0.1 -u man1 -p654321 来下发管理命令
第三段“< user >”配置业务用户,配置了一个账号 test 密码 password,针对数据库 testdb,读写权限都有,没有针对表做任何特殊的权限,故把表配置做了注释
- 即可以通过 mysql -P8066 -h 127.0.0.1 -utest -ppassword 下发 SQL 语句
▽ schema.xml
schema.xml 是最主要的配置项,我们将 users 用户表按照取模的方式平均拆分到了 MySQL A 和 MySQL B 两个数据数据库实例上, 详细请看配置文件:

- 参数说明
· schema 逻辑数据库信息,此数据库为逻辑数据库,name 与 server.xml 中 schema对应;
· dataNode 分片信息,此为分片节点的定义;分片名字和schema的dataNode对应;分片与下面的dataHost 物理实例进行关联;
· dataHost 物理实例组信息,dataHost下可以挂载同组的读写物理实例节点,实现高可用或者读写分离;
每个节点的重点属性逐一说明:
- schema:
属性说明 :
· name 逻辑数据库名,与 server.xml 中的 schema 对应;
· table:
子属性说明 :
- name 表名,物理数据库中表名
- dataNode 表存储到哪些节点,多个节点用逗号分隔
- primaryKey 主键,用于主键缓存和自增识别,不作主键约束
- autoIncrement 是否自增
- rule 分片规则名,具体规则下文 rule 详细介绍
- dataNode
属性说明:
· name 节点名,与 table 中 dataNode 对应
· datahost 物理实例组名,与 datahost 中 name 对应
· database 物理数据库中数据库名;
- dataHost
属性说明:
· name 物理数据库名,与 dataNode 中 dataHost 对应
· balance 均衡负载的方式
· switchtype 写节点的高可用切换方式;等于1时,心跳不健康发生切换
· heartbeat 心跳检测语句,注意语句结尾的分号要加
· writehost 写物理实例
子属性说明 :
- host 物理实例名
- url 物理库IP+Port
- user 物理库用户
- password 物理库密码
▽ rule.xml
主要关注 rule 属性,rule 属性的内容来源于 rule.xml 这个文件,DBLE 支持多种分表分库的规则,基本能满足你所需要的要求。
table 中的 rule 属性对应的就是 rule.xml 文件中 tableRule 的 name, 具体有哪些拆分算法实现,建议还是看下文档。我这里选择的 sharding-by-mod2,是 hash算法的特例,就是将数据平均拆分。因为我后端是两台物理库,所以 rule.xml中hashmod2 对应的 partitionCountt 为 2 ,配置如下:

▽ 验证配置生效
- 启动 DBLE
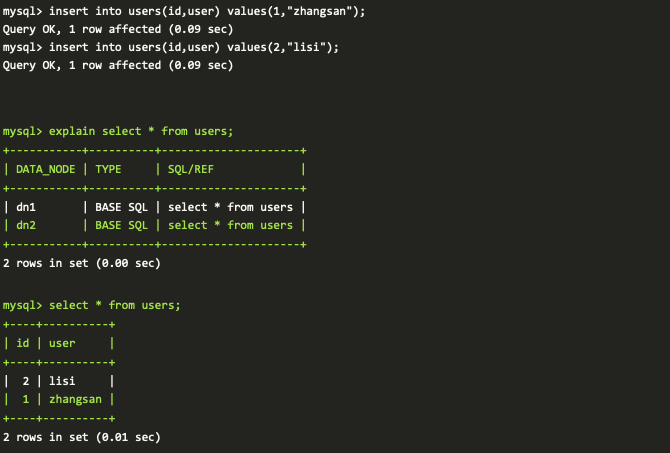
- 通过 DBLE 流量入口 8066 登陆数据库

- 插入两条用户记录,并获取 DBLE 侧的查询记录
- 获取 MySQL A 和 MySQL B 的记录
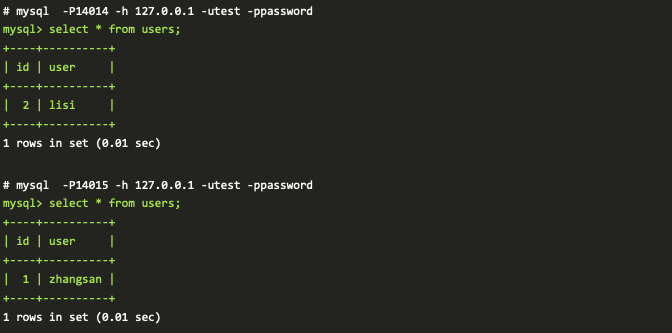
从上面的验证流程,往 DBLE 插入的数据,会按照取模的方式下发到真实的物理库,来实现数据库的自动分片;同时通过 DBLE 下发的查询会被 DBLE 自动下发给实际的物理库,合并返回给客户端,可以通过 explain 执行计划观察到下发的实际下发给物理库的 SQL 语句。
应用场景二:读写分离
DBLE 除了做数据的分片功能外,也支持读写分离功能;开启读写分离功能后,可以将主实例上的读压力负载给原本 stand by 的从实例,从而扩展整个集群的吞吐能力;
▽ 后端 MySQL 节点
我们再通过示例,演示 DBLE 的读写分离的功能。物理部署结构如下表:

备注:为了演示简单,这里将实例都部署在了一台机器上并用不同端口做区分,同学们也可以用三台机器来做环境搭建。
此场景中,我们将 MySQL A 和 MySQL B 搭建成主从复制关系,同时我们只变更schema.xml 的配置来完成读写分离的架构;
▽ schema.xml
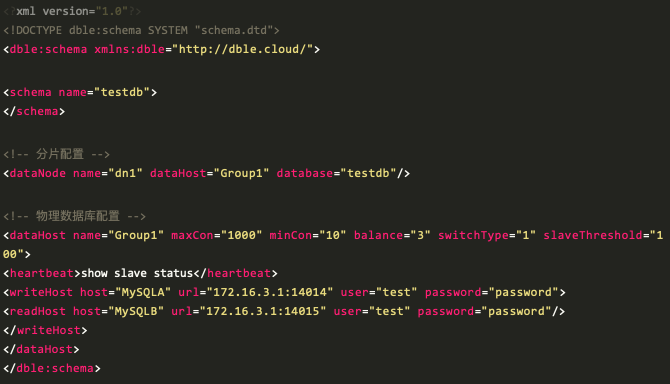
DBLE 通过 balance 参数来控制读写分离的负载策略,写节点是否参与均衡与 datahost 的 balance 属性有关,本案例中我们将值调整为 balance=”3” ,并定义了 writeHost 和 readHost。
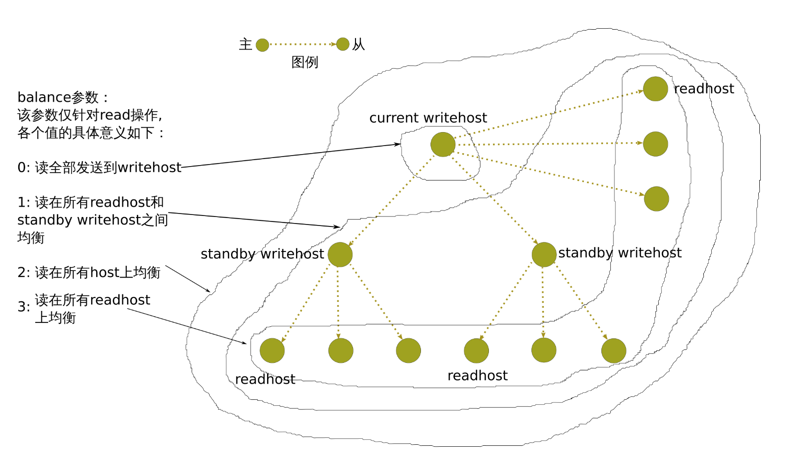
balance 的定义具体见下图:
▽ 验证配置生效
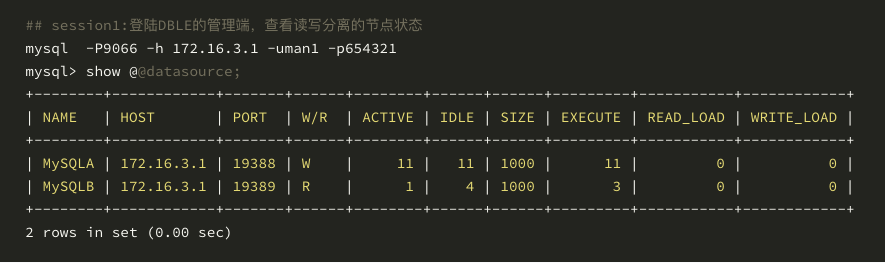
通过 DBLE 管理入口 9066 登陆数据库,注意这里我们通过管理入口的 show @@datasource 来验证读写分离的状态的正确性;
session 1:
session 2:

session 1:

从 show @@datasource; 这个管理命令上我们能够观测到 READ_LOAD 在 slave节点上计数器增加了 5 次,也就是说读流量顺利的下发到了 slave 节点;当然大家也可以通过打开 MySQL 的 general log 来观测读写分离的情况。
总结
本文通过两个场景来讲解 DBLE 的快速入门,希望通过简单的示例来给大家梳理 DBLE 的基本概念,帮助大家快速熟悉和使用 DBLE 这个中间件;更高阶的使用方法和细节建议大家参考官方文档。
转载自:http://www.sohu.com/a/291248428_100251585
开源分布式中间件 DBLE 快速入门指南的更多相关文章
- 分布式消息系统Jafka入门指南之二
分布式消息系统Jafka入门指南之二 作者:chszs,转载需注明.博客主页:http://blog.csdn.net/chszs 三.Jafka的文件夹结构 1.安装tree命令 $ sudo yu ...
- [转] Spark快速入门指南 – Spark安装与基础使用
[From] https://blog.csdn.net/w405722907/article/details/77943331 Spark快速入门指南 – Spark安装与基础使用 2017年09月 ...
- KNIME快速入门指南
一.介绍 KNIME Analytics Platform是用于创建数据科学应用程序和服务的开源软件.KNIME直观,开放,不断整合新的开发,使人们可以理解数据,设计数据科学工作流程和可重用组件. ...
- AngularJS快速入门指南20:快速参考
thead>tr>th, table.reference>tbody>tr>th, table.reference>tfoot>tr>th, table ...
- AngularJS快速入门指南19:示例代码
本文给出的大部分示例都可以直接运行,通过点击运行按钮来查看结果,同时支持在线编辑代码. <div ng-app=""> <p>Name: <input ...
- AngularJS快速入门指南18:Application
是时候创建一个真正的AngularJS单页面应用程序了(SPA). 一个AngularJS应用程序示例 你已经了解了足够多的内容来创建第一个AngularJS应用程序: My Note Save Cl ...
- AngularJS快速入门指南17:Includes
使用AngularJS,你可以在HTML中包含其它的HTML文件. 在HTML中包含其它HTML文件? 当前的HTML文档还不支持该功能.不过W3C建议在后续的HTML版本中增加HTML import ...
- AngularJS快速入门指南16:Bootstrap
thead>tr>th, table.reference>tbody>tr>th, table.reference>tfoot>tr>th, table ...
- AngularJS快速入门指南15:API
thead>tr>th, table.reference>tbody>tr>th, table.reference>tfoot>tr>th, table ...
随机推荐
- 20191011-构建我们公司自己的自动化接口测试框架-TestData的数据准备
创建excel测试数据准备,excel的第一个sheet存储测试集,后面分别为测试用例和断言结果表 测试集构成如下: 按列分别为测试序号,测试用例说明,对应的sheetname,测试用例是否允许,测试 ...
- js 监听键盘的enter键
// js 版本 window.onload=function(){ document.onkeydown=function(ev){ var event=ev ||event if(event.ke ...
- Nature Biotechnology:人类基因研究走近平民 数据是基础解读更重要
Nature Biotechnology:人类基因研究走近平民 数据是基础解读更重要 5万美元可以做什么?最近,美国斯坦福大学教授斯蒂芬·夸克在国际著名学术期刊<自然·生物技术>发表论文宣 ...
- c++-01--迭代器
迭代器的概念 除了在其它语言中司空见惯的下标法访问容器元素之外,C++ 语言提供了一种全新的方法——迭代器(iterator)来访问容器的元素.迭代器其实类似于引用,指向容器中某一元素.迭代器(ite ...
- rabbitMQ 安装,基于Windows环境
参考文章:https://www.cnblogs.com/ericli-ericli/p/5902270.htmlRabbit MQ 是建立在Erlang OTP平台上,安装前需先安装Erlang.h ...
- java封装数据类型——Integer 缓存策略验证
上一篇学习 Integer 类型源码,知道了它使用缓存策略,默认对 [-128, 127] 范围的对象进行类加载时自动创建缓存. Integer 源码学习:https://www.cnblogs.co ...
- [转载]Linux 命令详解:./configure、make、make install 命令
[转载]Linux 命令详解:./configure.make.make install 命令 来源:https://www.cnblogs.com/tinywan/p/7230039.html 这些 ...
- jdk8的环境配置
下载jdk,选择安装路径进行安装.https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.htm ...
- 【数字图像处理】目标检测的图像特征提取之HOG特征
1.HOG特征 方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子.它通过计算和统计图像局部区域的梯 ...
- linux文件系统初学
Linux磁盘分区和目录 Linux发行版之间的差别很小,差别主要表现在系统管理的特色工具以及软件包管理方式的不同. Windows的文件结构是多个并列的树状结构,最顶部是不同的磁盘(分区),如C,D ...