ElasticSearch 集群环境搭建,安装ElasticSearch-head插件,安装错误解决
ElasticSearch-5.3.1集群环境搭建,安装ElasticSearch-head插件,安装错误解决
说起来甚是惭愧,博主在写这篇文章的时候,还没有系统性的学习一下ES,只知道可以拿来做全文检索,功能很牛逼,但是接到了任务不想做也不行,
leader让我搭建一下分布式的ES集群环境,用来支持企业信用数据的检索,刚开始宝宝一脸蒙逼,只是之前自己本地搭建过一个测试玩过,开发任务也是忙的不行,
一直也没时间好好的研究一下,惭愧。《Elasticsearch服务器开发》已经备好,只能边学边开发了,希望本篇拙文可以帮到有需要的coder们。----jstarseven
话不多说,开始搭建环境,准备好集群搭建需要的软硬件:
1.服务器(系统版本 centos7)三台(没有的话,可以在一台pc上尝试不同端口):
1. 172.16.31.220
2. 172.16.31.221
3. 172.16.31.224
2.JDK (下载最新版本JDK,至少JDK1.8,最新版本ES需要1.8的jdk环境):
博主的为:

配置JDK1.8环境变量(自行解决。。。)
3.elasticsearch-5.3.1.tar.gz(下载地址:https://www.elastic.co/downloads/elasticsearch)
在220服务器/usr/local/下解压 tar -zxvf elasticsearch-5.3.1.tar.gz,修改配置文件,vim elasticsearch-5.3.1/config/elasticsearch.yml
220服务器,原有配置文件:
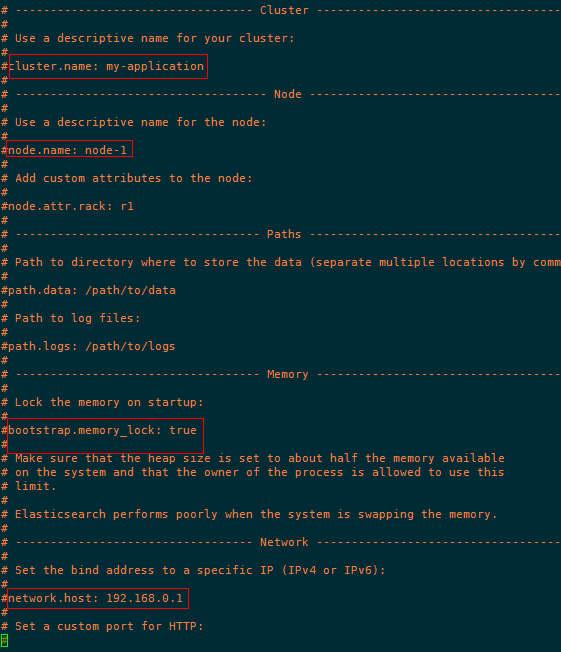
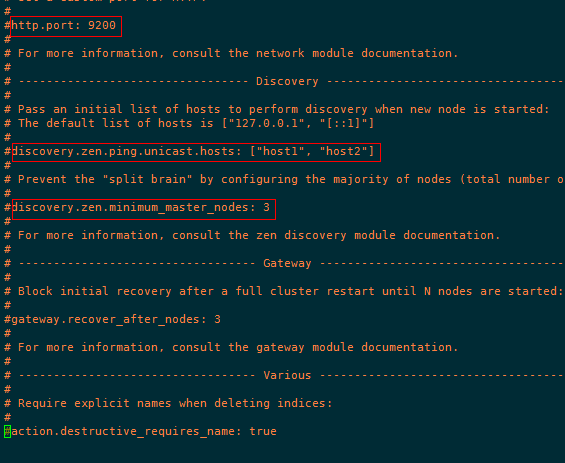
修改之后的配置文件:
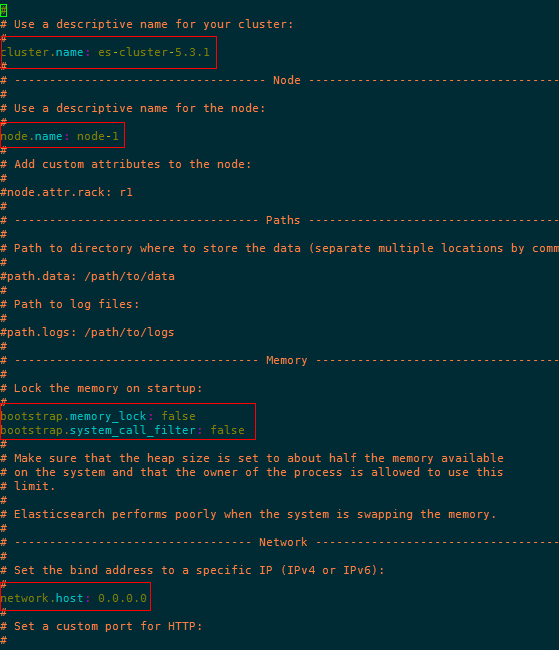

解释:
cluster.name: es-cluster-5.3.1 配置集群名称 三台服务器保持一致
node.name: node-1 配置单一节点名称,每个节点唯一标识
network.host: 0.0.0.0 设置绑定的ip地址
http.port: 9200 端口
discovery.zen.ping.unicast.hosts: ["172.16.31.220", "172.16.31.221","172.16.31.224"] 集群节点ip或者主机
discovery.zen.minimum_master_nodes: 3 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
下面两行配置为haad插件配置,三台服务器一致。
http.cors.enabled: true
http.cors.allow-origin: "*"
ok,220服务器修改完毕。
[转载请注明原文出处]:http://www.cnblogs.com/jstarseven/p/6803054.html
221服务器ES配置文件修改 vim elasticsearch-5.3.1/config/elasticsearch.yml
cluster.name: es-cluster-5.3.1
node.name: node-2
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["172.16.31.220", "172.16.31.221","172.16.31.224"]
discovery.zen.minimum_master_nodes: 3
http.cors.enabled: true
http.cors.allow-origin: "*"
224服务器ES配置文件修改 vim elasticsearch-5.3.1/config/elasticsearch.yml
cluster.name: es-cluster-5.3.1
node.name: node-3
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["172.16.31.220", "172.16.31.221","172.16.31.224"]
discovery.zen.minimum_master_nodes: 3
http.cors.enabled: true
http.cors.allow-origin: "*"
到这里集群就算配置完毕了,但是ES5.3.1不允许使用root用户运行,不然启动会报错,Exception in thread "main" java.lang.RuntimeException: don't run elasticsearch as root.
所以新建用户(三台服务器,都要新建)
groupadd elsearch 新增elsearch用户组
useradd elsearch -g elsearch -p elasticsearch 创建elsearch用户
chown -R elsearch:elsearch ./elasticsearch-5.3.1 用户目录权限
运行操作,开启三台服务
切换到elsearch用户下,su elsearch,cd /usr/local/elasticsearch-5.3.1 执行命令./bin/elasticsearch
观察运行日志:
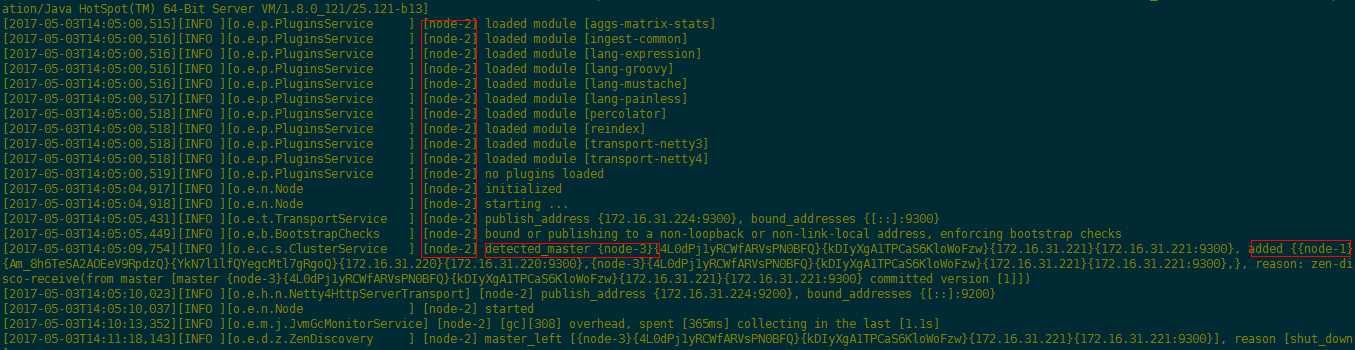
可以看到集群已经成功运行,选举了node-3节点为master节点
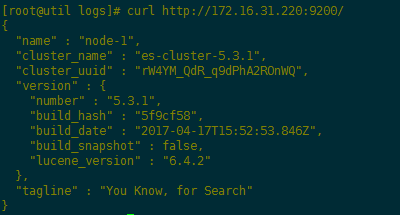
测试,节点启动情况: curl http://172.16.31.220:9200/,集群情况安装好了head插件,即可显示
当然配置完成之后,启动的时候出现了很多的错误,错误汇总<部分问题来源于网络,感谢大家的之后,博主在此汇总一下>:
问题一:
bin/elasticsearch-plugin install x-pack
问题九:
启动异常:ERROR: bootstrap checks failed
system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
问题原因:因为Centos6不支持SecComp,而ES5.2.1默认bootstrap.system_call_filter为true进行检测,所以导致检测失败,失败后直接导致ES不能启动。详见 :https://github.com/elastic/elasticsearch/issues/22899
解决方法:在elasticsearch.yml中配置bootstrap.system_call_filter为false,注意要在Memory下面:
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
问题十:
Failed to send join request to master [{node-1}{WbcP0pC_T32jWpYvu5is1A}{2_LCVHx1QEaBZYZ7XQEkMg}{10.10.11.200}{10.10.11.200:9300}], reason [RemoteTransportException[[node-1][10.10.11.200:9300][internal:discovery/zen/join]]; nested: IllegalArgumentException[can't add node {node-2}{WbcP0pC_T32jWpYvu5is1A}{p-HCgFLvSFaTynjKSeqXyA}{10.10.11.200}{10.10.11.200:9301}, found existing node {node-1}{WbcP0pC_T32jWpYvu5is1A}{2_LCVHx1QEaBZYZ7XQEkMg}{10.10.11.200}{10.10.11.200:9300} with the same id but is a different node instance]; ]
问题原因:要是部署的时候从一个节点复制elasticsearch文件夹,其他节点可能包含被复制节点的data文件数据,需要把data文件下的文件清空
到这里基本上集群搭建起来就没什么问题了,如果还不能正常启动,麻烦各位解决了,通知我一声,我也好记录一下,哈哈哈。
下面说ElasticSearch-head插件在ElasticSearch-5.3.1中的安装使用:
1.安装nodejs环境
- 1) wget https://npm.taobao.org/mirrors/node/latest-v4.x/node-v4.4.7-linux-x64.tar.gz
- 2) tar -zxvf node-v4.4.7-linux-x64.tar.gz
- 3) vim /etc/profile
- 4)source /etc/profile
- 5) 追加 export PATH=$PATH:/opt/node-v4.4.7-linux-x64/bin 至文件最后
- 测试 node --version
v4.4.7
2.安装npm
下载nmp安装包,一般nodejs包中已经包含了,设置过环境变量就可以直接使用nmp命令了,如果没有安装,先下载:
官网地址:www.npmjs.com
淘宝地址:https://npm.taobao.org/mirrors/npm/
安装使用如下命令:
- node cli.js install npm -gf
3.安装grunt
1)安装grunt命令行工具grunt-cli npm install -g grunt-cli
2)安装grunt及其插件 npm install grunt --save-dev
可以使用grunt -version查看安装版本情况
然后,在220服务器上,
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm install grunt --save
修改elasticsearch-head下Gruntfile.js文件,默认监听在127.0.0.1下9200端口,
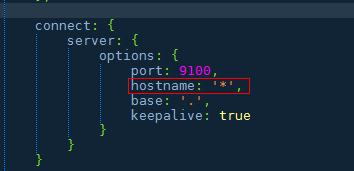
然后cd /usr/local/elasticsearch-head 执行grunt server
浏览器访问 http://172.16.31.220:9100/
出现一下界面:
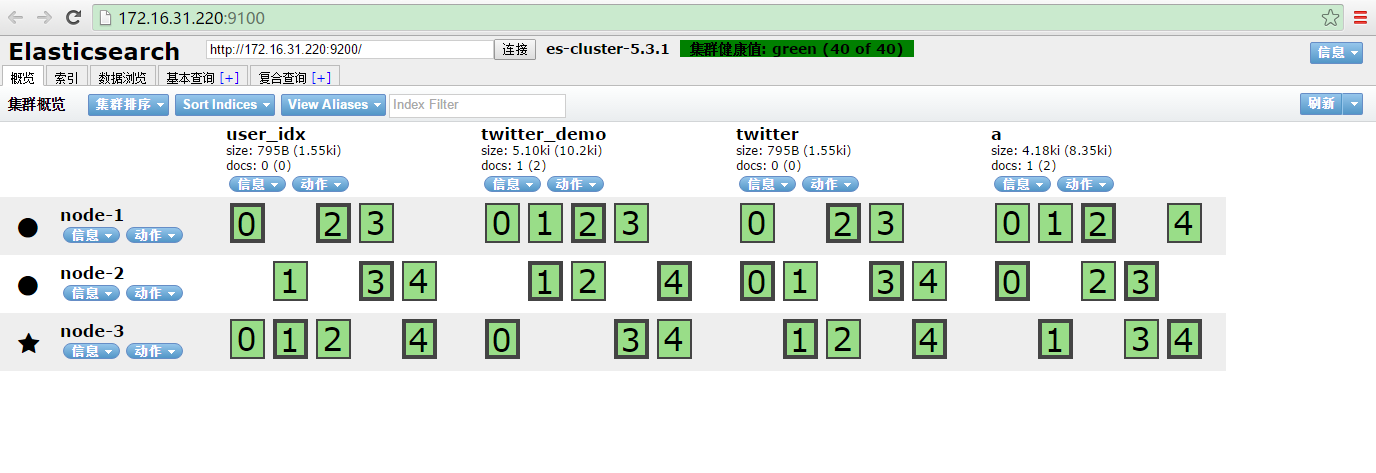
ok 到此,ElasticSearch-5.3.1集群,以及head插件的安装就结束了。
转载自:
http://www.cnblogs.com/jstarseven/p/6803054.html,这么多字,博主码的也挺累的,谢谢合作。
ElasticSearch 集群环境搭建,安装ElasticSearch-head插件,安装错误解决的更多相关文章
- ElasticSearch集群环境搭建
一 .单机部署 1.下载安装包.解压 2.在window下运行bin/elasticsearch.bat 3.访问localhost:9200 页面显示结果 { "name" : ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
使用VMW安装四台CentOS-7-x86_64-DVD-1804.iso虚拟机: 计划配置三台centos虚拟机: master:192.168.0.120 slave1:192.168.0.121 ...
- 学习elasticsearch(一)linux环境搭建(3)——head插件安装
对于5.x的es,head插件不支持 ./elasticearch-plugin install [plugin_name]方式安装. 进入正文 1.首先确保你的机器安装了python,如果没有,请看 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三)安装spark2.2.1
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
随机推荐
- 15-16 ICPC europe J Saint John Festival (graham扫描法+旋转卡壳)
题意:给n个大点,m个小点$(n<=1e5,m<=5e5),问有多少个小点,存在3个大点,使小点在三个大点组成的三角形内. 解题思路: 首先,易证,若该小点在某三大点行成的三角形内,则该小 ...
- python 之 数据库(数据库安装方法、基本sql语句、存储引擎)
第十章 数据库 10.1 数据库介绍 1.数据库相关概念 数据库服务器:本质就是一个台计算机,该计算机之上安装有数据库管理软件的服务端 数据库管理系统RDBMS:本质就是一个C/S架构的套接字软件 库 ...
- OpenCV学习笔记3
OpenCV学习笔记3 图像平滑(低通滤波) 使用低通滤波器可以达到图像模糊的目的.这对与去除噪音很有帮助.其实就是去除图像中的高频成分(比如:噪音,边界).所以边界也会被模糊一点.(当然,也有一些模 ...
- Bootsrap表格表单及其使用方法
bootstrap的使用 bootstrap中的js插件依赖于jQuery 因此jQuery要在bootstrap之前引入 参考官网标准引入方法和引入样式 排版 标题 Bootstrap和普通的HTM ...
- vue防止闪屏小技巧:[v-cloak]
css 内添加此属性[v-cloak] { display: none; } html中引入即可 <div v-cloak> {{ message }} </div> 如果觉得 ...
- JNI创建共享内存导致JVM terminated的问题解决(segfault,shared memory,内存越界,内存泄漏,共享内存)
此问题研究了将近一个月,最终发现由于JNI不支持C中创建共享内存而导致虚拟机无法识别这块共享内存,造成内存冲突,最终虚拟机崩溃. 注意:JNI的C部分所使用的内存也是由JVM创建并管理的,所以C创建了 ...
- Mybatis的实现原理
在spring启动的时候,spring会根据我们配置的有关mapper.xml的路径加载此路径下的xml文件,得到一个List<Resource>的集合,然后将这个集合转化成Resourc ...
- 关于utf8mb4的使用
针对mysql数据库存储一些特殊字符或者emoji的字符,所需要的编码类型.实际上基于efcore框架的情况下,codefirst自动迁移生成的数据库的默认编码格式,就是utf8mb4,以前的时候记得 ...
- webstrom设置语句中的分号
webstrom可以设置语句默认是否添加分号 setting >editor > Code Style > Javascript
- iOS-CGContextRef
图形上下文(Graphics Context)---绘制目标 需要在iOS应用程序的屏幕上进行绘制时,需要先定义一个UIView类,并实现它的drawRect:方法,当启动程序时,会先调用loadVi ...