PostgreSQL 进程结构
本文主要讲述了PG的几个主要进程,以及PG的核心架构。进程和体系结构详见下图:
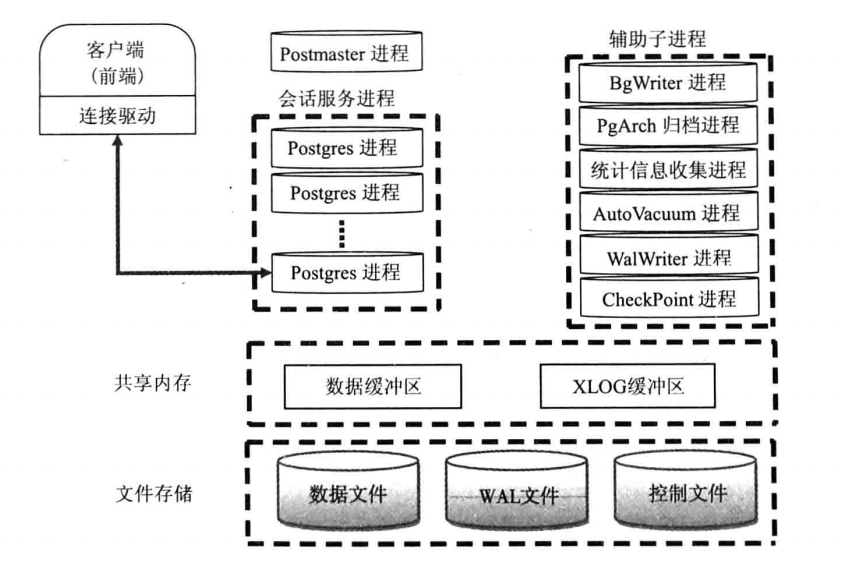
从上面的体系结构图可以看出来,PG使用经典的C/S架构,进程架构。在服务器端有主进程、服务进程、子进程、共享内存以及文件存储几大部分,下面着重讲述服务器端的进程部分:
1. Postmaster主进程和服务进程
当PG数据库启动时,首先会启动Postmaster主进程。这个进程是PG数据库的总控制进程,负责启动和关闭数据库实例。实际上Postmaster进程是一个指向postgres命令的链接,如下:
[postgres@drz ~]$ ll /opt/postgresql/bin/postmaster
lrwxrwxrwx. 1 postgres dba 8 Aug 7 23:33 /opt/postgresql/bin/postmaster -> postgres
当用户和PG数据库建立连接时,要先与Postmaster进程建立连接,此时客户端进程会发送身份验证消息给Postmaster主进程,Postmaster主进程根据消息进行身份验证,验证通过后,Postmaster主进程会fork出一个会话服务进程为这个用户连接服务。可以通过pg_stat_activity表来查看服务进程的pid,如下:
test=# select pid,usename,client_addr,client_port from pg_stat_activity;
pid | usename | client_addr | client_port
-------+----------+-------------+-------------
26402 | postgres | | -1
(1 row)
2. BgWriter(后台写)进程
BgWriter进程是把共享内存中的脏页写到磁盘上的进程。它的作用有两个:一是定期把脏数据从内存缓冲区刷出到磁盘中,减少查询时的阻塞;二是PG在定期作检查点时需要把所有脏页写出到磁盘,通过BgWriter预先写出一些脏页,可以减少设置检查点(CheckPoint,数据库恢复技术的一种)时要进行的IO操作,使系统的IO负载趋向平稳。BgWriter是PostgreSQL 8.0以后新加的特性,它的机制可以通过postgresql.conf文件中以"bgwriter_"开头配置参数来控制:

# - Background Writer - #bgwriter_delay = 200ms # 10-10000ms between rounds
#bgwriter_lru_maxpages = 100 # 0-1000 max buffers written/round
#bgwriter_lru_multiplier = 2.0 # 0-10.0 multiplier on buffers scanned/round
#bgwriter_flush_after = 512kB # measured in pages, 0 disables
bgwriter_delay:
backgroud writer进程连续两次flush数据之间的时间的间隔。默认值是200,单位是毫秒。
bgwriter_lru_maxpages:
backgroud writer进程每次写的最多数据量,默认值是100,单位buffers。如果脏数据量小于该数值时,写操作全部由backgroud writer进程完成;反之,大于该值时,大于的部分将有server process进程完成。设置该值为0时表示禁用backgroud writer写进程,完全有server process来完成;配置为-1时表示所有脏数据都由backgroud writer来完成。(这里不包括checkpoint操作)
bgwriter_lru_multiplier:
这个参数表示每次往磁盘写数据块的数量,当然该值必须小于bgwriter_lru_maxpages。设置太小时需要写入的脏数据量大于每次写入的数据量,这样剩余需要写入磁盘的工作需要server process进程来完成,将会降低性能;值配置太大说明写入的脏数据量多于当时所需buffer的数量,方便了后面再次申请buffer工作,同时可能出现IO的浪费。该参数的默认值是2.0。
bgwriter的最大数据量计算方式:
1000/bgwriter_delay*bgwriter_lru_maxpages*8K=最大数据量
bgwriter_flush_after:
数据页大小达到bgwriter_flush_after时触发BgWriter,默认是512KB。
3. PgArch(归档)进程
类似于Oracle数据库的ARCH归档进程,不同的是ARCH是吧redo log进行归档,PgArch是把WAL日志进行归档。再深入点,WAL日志会被循环使用,也就是说,过去的WAL日志会被新产生的日志覆盖,PgArch进程就是为了在覆盖前把WAL日志备份出来。归档日志的作用是为了数据库能够使用全量备份和备份后产生的归档日志,从而让数据库回到过去的任一时间点。PG从8.X版本开始提供的PITR(Point-In-Time-Recovery)技术,就是运用的归档日志。
PgArch进程通过postgresql.conf文件中的如下参数进行配置:
# - Archiving - #archive_mode = off # enables archiving; off, on, or always
# (change requires restart)
#archive_command = '' # command to use to archive a logfile segment
# placeholders: %p = path of file to archive
# %f = file name only
# e.g. 'test ! -f /mnt/server/archivedir/%f && cp %p /mnt/server/archivedir/%f'
#archive_timeout = 0 # force a logfile segment switch after this
# number of seconds; 0 disables
archive_mode:
表示是否进行归档操作,可选择为off(关闭)、on(启动)和always(总是开启),默认值为off(关闭)。
archive_command:
由管理员设置的用于归档WAL日志的命令。在用于归档的命令中,预定义变量“%p”用来指代需要归档的WAL全路径文件名,“%f”表示不带路径的文件名(这里的路径都是相对于当前工作目录的路径)。每个WAL段文件归档时将调用archive_command所指定的命令。当归档命令返回0时,PostgreSQL就会认为文件被成功归档,然后就会删除或循环使用该WAL段文件。否则,如果返回一个非零值,PostgreSQL会认为文件没有被成功归档,便会周期性地重试直到成功。
archive_timeout:
表示归档周期,在超过该参数设定的时间时强制切换WAL段,默认值为0(表示禁用该功能)。
4. PgStat(统计数据收集)进程
PgStat进程是PostgreSQL数据库的统计信息收集器,用来收集数据库运行期间的统计信息,如表的增删改次数,数据块的个数,索引的变化等等。收集统计信息主要是为了让优化器做出正确的判断,选择最佳的执行计划。postgresql.conf文件中与PgStat进程相关的参数,如下:
#------------------------------------------------------------------------------
# RUNTIME STATISTICS
#------------------------------------------------------------------------------ # - Query/Index Statistics Collector - #track_activities = on
#track_counts = on
#track_io_timing = off
#track_functions = none # none, pl, all
#track_activity_query_size = 1024 # (change requires restart)
#stats_temp_directory = 'pg_stat_tmp'
track_activities:表示是否对会话中当前执行的命令开启统计信息收集功能,该参数只对超级用户和会话所有者可见,默认值为on(开启)。
track_counts:表示是否对数据库活动开启统计信息收集功能,由于在AutoVacuum自动清理进程中选择清理的数据库时,需要数据库的统计信息,因此该参数默认值为on。
track_io_timing:定时调用数据块I/O,默认是off,因为设置为开启状态会反复的调用数据库时间,这给数据库增加了很多开销。只有超级用户可以设置
track_functions:表示是否开启函数的调用次数和调用耗时统计。
track_activity_query_size:设置用于跟踪每一个活动会话的当前执行命令的字节数,默认值为1024,只能在数据库启动后设置。
stats_temp_directory:统计信息的临时存储路径。路径可以是相对路径或者绝对路径,参数默认为pg_stat_tmp,设置此参数可以减少数据库的物理I/O,提高性能。此参数只能在postgresql.conf文件或者服务器命令行中修改。
5. AutoVacuum(自动清理)进程
在PG数据库中,对数据进行UPDATE或者DELETE操作后,数据库不会立即删除旧版本的数据,而是标记为删除状态。这是因为PG数据库具有多版本的机制,如果这些旧版本的数据正在被另外的事务打开,那么暂时保留他们是很有必要的。当事务提交后,旧版本的数据已经没有价值了,数据库需要清理垃圾数据腾出空间,而清理工作就是AutoVacuum进程进行的。postgresql.conf文件中与AutoVacuum进程相关的参数有:
#------------------------------------------------------------------------------
# AUTOVACUUM PARAMETERS
#------------------------------------------------------------------------------ #autovacuum = on # Enable autovacuum subprocess? 'on'
# requires track_counts to also be on.
#log_autovacuum_min_duration = -1 # -1 disables, 0 logs all actions and
# their durations, > 0 logs only
# actions running at least this number
# of milliseconds.
#autovacuum_max_workers = 3 # max number of autovacuum subprocesses
# (change requires restart)
#autovacuum_naptime = 1min # time between autovacuum runs
#autovacuum_vacuum_threshold = 50 # min number of row updates before
# vacuum
#autovacuum_analyze_threshold = 50 # min number of row updates before
# analyze
#autovacuum_vacuum_scale_factor = 0.2 # fraction of table size before vacuum
#autovacuum_analyze_scale_factor = 0.1 # fraction of table size before analyze
#autovacuum_freeze_max_age = 200000000 # maximum XID age before forced vacuum
# (change requires restart)
#autovacuum_multixact_freeze_max_age = 400000000 # maximum multixact age
# before forced vacuum
# (change requires restart)
#autovacuum_vacuum_cost_delay = 20ms # default vacuum cost delay for
# autovacuum, in milliseconds;
# -1 means use vacuum_cost_delay
#autovacuum_vacuum_cost_limit = -1 # default vacuum cost limit for
# autovacuum, -1 means use
# vacuum_cost_limit
autovacuum:是否启动系统自动清理功能,默认值为on。
log_autovacuum_min_duration:这个参数用来记录 autovacuum 的执行时间,当 autovaccum 的执行时间超过 log_autovacuum_min_duration参数设置时,则autovacuum信息记录到日志里,默认为 "-1", 表示不记录。
autovacuum_max_workers:设置系统自动清理工作进程的最大数量。
autovacuum_naptime:设置两次系统自动清理操作之间的间隔时间。
autovacuum_vacuum_threshold和autovacuum_analyze_threshold:设置当表上被更新的元组数的阈值超过这些阈值时分别需要执行vacuum和analyze。
autovacuum_vacuum_scale_factor和autovacuum_analyze_scale_factor:设置表大小的缩放系数。
autovacuum_freeze_max_age:设置需要强制对数据库进行清理的XID上限值。
autovacuum_vacuum_cost_delay:当autovacuum进程即将执行时,对 vacuum 执行 cost 进行评估,如果超过 autovacuum_vacuum_cost_limit设置值时,则延迟,这个延迟的时间即为 autovacuum_vacuum_cost_delay。如果值为 -1, 表示使用 vacuum_cost_delay 值,默认值为 20 ms。
autovacuum_vacuum_cost_limit:这个值为 autovacuum 进程的评估阀值, 默认为 -1, 表示使用 "vacuum_cost_limit " 值,如果在执行 autovacuum 进程期间评估的cost 超过 autovacuum_vacuum_cost_limit, 则 autovacuum 进程则会休眠。
6. WalWriter(预写式日志写)进程
预写式日志WAL(Write Ahead Log,也称为Xlog)的中心思想是对数据文件的修改必须是只能发生在这些修改已经记录到日志之后,也就是先写日志后写数据(日志先行)。使用这种机制可以避免数据频繁的写入磁盘,可以减少磁盘I/O。数据库在宕机重启后可以运用这些WAL日志来恢复数据库。postgresql.conf文件中与WalWriter进程相关的参数如下:
#------------------------------------------------------------------------------
# WRITE AHEAD LOG
#------------------------------------------------------------------------------ # - Settings - #wal_level = minimal # minimal, replica, or logical
# (change requires restart)
#fsync = on # flush data to disk for crash safety
# (turning this off can cause
# unrecoverable data corruption)
#synchronous_commit = on # synchronization level;
# off, local, remote_write, remote_apply, or on
#wal_sync_method = fsync # the default is the first option
# supported by the operating system:
# open_datasync
# fdatasync (default on Linux)
# fsync
# fsync_writethrough
# open_sync
#full_page_writes = on # recover from partial page writes
#wal_compression = off # enable compression of full-page writes
#wal_log_hints = off # also do full page writes of non-critical updates
# (change requires restart)
#wal_buffers = -1 # min 32kB, -1 sets based on shared_buffers
# (change requires restart)
#wal_writer_delay = 200ms # 1-10000 milliseconds
#wal_writer_flush_after = 1MB # measured in pages, 0 disables #commit_delay = 0 # range 0-100000, in microseconds
#commit_siblings = 5 # range 1-1000
wal_level:控制wal存储的级别。wal_level决定有多少信息被写入到WAL中。 默认值是最小的(minimal),其中只写入从崩溃或立即关机中恢复的所需信息。replica 增加 wal 归档信息 同时包括 只读服务器需要的信息。(9.6 中新增,将之前版本的 archive 和 hot_standby 合并)
logical 主要用于logical decoding 场景
fsync:该参数直接控制日志是否先写入磁盘。默认值是ON(先写入),表示更新数据写入磁盘时系统必须等待WAL的写入完成。可以配置该参数为OFF,表示更新数据写入磁盘完全不用等待WAL的写入完成。
synchronous_commit:参数配置是否等待WAL完成后才返回给用户事务的状态信息。默认值是ON,表明必须等待WAL完成后才返回事务状态信息;配置成OFF能够更快地反馈回事务状态。
wal_sync_method:WAL写入磁盘的控制方式,默认值是fsync,可选用值包括open_datasync、fdatasync、fsync_writethrough、fsync、open_sync。open_datasync和open_sync分别表示在打开WAL文件时使用O_DSYNC和O_SYNC标志;fdatasync和fsync分别表示在每次提交时调用fdatasync和fsync函数进行数据写入,两个函数都是把操作系统的磁盘缓存写回磁盘,但前者只写入文件的数据部分,而后者还会同步更新文件的属性;fsync_writethrough表示在每次提交并写回磁盘会保证操作系统磁盘缓存和内存中的内容一致。
full_page_writes:表明是否将整个page写入WAL。
wal_buffers:用于存放WAL数据的内存空间大小,系统默认值是64K,该参数还受wal_writer_delay、commit_delay两个参数的影响。
wal_writer_delay:WalWriter进程的写间隔时间,默认值是200毫秒,如果时间过长可能造成WAL缓冲区的内存不足;时间过短将会引起WAL的不断写入,增加磁盘I/O负担。
wal_writer_flush_after:
commit_delay:表示一个已经提交的数据在WAL缓冲区中存放的时间,默认值是0毫秒,表示不用延迟;设置为非0值时事务执行commit后不会立即写入WAL中,而仍存放在WAL缓冲区中,等待WalWriter进程周期性地写入磁盘。
commit_siblings:表示当一个事务发出提交请求时,如果数据库中正在执行的事务数量大于commit_siblings值,则该事务将等待一段时间(commit_delay的值);否则该事务则直接写入WAL。系统默认值是5,该参数还决定了commit_delay的有效性。
wal_writer_flush_after:当脏数据超过阈值时,会被刷出到磁盘。
7. CheckPoint(检查点)进程
检查点是系统设置的事务序列点,设置检查点保证检查点前的日志信息刷到磁盘中。postgresql.conf文件中与之相关的参数有:
# - Checkpoints - #checkpoint_timeout = 5min # range 30s-1d
#max_wal_size = 1GB
#min_wal_size = 80MB
#checkpoint_completion_target = 0.5 # checkpoint target duration, 0.0 - 1.0
#checkpoint_flush_after = 256kB # measured in pages, 0 disables
#checkpoint_warning = 30s # 0 disables
8. SysLogger进程
日志信息是数据库管理员获取数据库系统运行状态的有效手段。在数据库出现故障时,日志信息是非常有用的。把数据库日志信息集中输出到一个位置将极大方便管理员维护数据库系统。然而,日志输出将产生大量数据(特别是在比较高的调试级别上),单文件保存时不利于日志文件的操作。因此,在SysLogger的配置选项中可以设置日志文件的大小,SysLogger会在日志文件达到指定的大小时关闭当前日志文件,产生新的日志文件。在postgresql.conf里可以配置日志操作的相关参数:
log_destination:配置日志输出目标,根据不同的运行平台会设置不同的值,Linux下默认为stderr。
logging_collector:是否开启日志收集器,当设置为on时启动日志功能;否则,系统将不产生系统日志辅助进程。
log_directory:配置日志输出文件夹。
log_filename:配置日志文件名称命名规则。
log_rotation_size:配置日志文件大小,当前日志文件达到这个大小时会被关闭,然后创建一个新的文件来作为当前日志文件。
此外,postgresql.conf中还提供了其他配置参数,可以根据需要进行设置。
9. 共享内存

PostgreSQL启动后,会生成一块共享内存,共享内存主要做数据块的缓冲区,以便提高读写新能,WAL日志缓冲区和CLOG缓冲区也存在于共享内存中,除此之外,一些全局信息也保存在共享内存中,如进程信息,锁信息,全局统计信息,等.
10. 本地内存
后台服务进程除了访问共享内存外,还会申请分配一些本地内存,以便暂存一些不需要全局存储的数据,这些内存缓冲区主要有以下几类:
- 临时缓冲区:用于访问临时表的本地缓冲区
- work_mem:内存排序操作和Hash表在使用临时磁盘文件之前使用的内存缓冲区.
- maintenance_work_mem:在维护性操作(如vacuum,create index,和alter table add foreign key等)中使用的内存缓冲区.
整理自:
https://www.cnblogs.com/ilifeilong/p/6995260.html?utm_source=itdadao&utm_medium=referral
https://www.cnblogs.com/NextAction/p/7456396.html
PostgreSQL 进程结构的更多相关文章
- Postgresql 进程和内存结构
在本章中,总结了PostgreSQL中的流程体系结构和内存体系结构,以帮助阅读后续章节.如果您已经熟悉它们,可以跳过本章 1.进程结构 Postgresql 是一个C/S架构的关系型数据库,由多个后台 ...
- PG进程结构和内存结构
本文主要介绍PostgreSQL数据库(后文简称PG)进程结构和内存结构,物理结构将在后续继续整理分享. 上图描述了PG进程结构.内存结构和部分物理结构的内容.图中的内容包含了两个部分: PG ...
- Linux程序存储结构与进程结构堆和栈的区别【转】
转自:http://www.hongkevip.com/caozuoxitong/Unix_Linux/24581.html 红客VIP(http://www.hongkevip.com):Linux ...
- DBA_Oracle基本体系内存和进程结构(概念)
2014-08-05 Created By BaoXinjian
- nginx系列6:nginx的进程结构
nginx的进程结构 如下图: 通过ps –ef | grep nginx可以看到共有三个进程,一个master进程,两个worker进程. nginx是多进程结构,多进程结构设计是为了保证nginx ...
- Oracle数据库体系结构之进程结构(4)
Oracle进程结构包括用户进程,服务进程,后台进程. 1. 用户进程 用户进程在数据库用户要求连接到Oracle服务器时开始启动. 用户进程是要求Oracle服务器交互的一种进程 它必须首先建立一个 ...
- 第5章 进程环境(1)_进程结构(task_struct)
1. 进程的概念和进程结构 1.1 进程 (1)程序(program):是一些保存在磁盘上有序指令的集合,是存放在磁盘文件中的可执行文件.但没有任何执行的概念,它是静态的. (2)进程(process ...
- 第二十一篇:Linux 操作系统中的进程结构
前言 在 Linux 中,一个正在执行的程序往往由各种各样的进程组成,这些进程除了父子关系,还有其他的关系.依赖于这些关系,所有进程构成一个整体,给用户提供完整的服务( 考虑到了终端,即与用户的交互 ...
- Linux进程调度与源码分析(二)——进程生命周期与task_struct进程结构体
1.进程生命周期 Linux操作系统属于多任务操作系统,系统中的每个进程能够分时复用CPU时间片,通过有效的进程调度策略实现多任务并行执行.而进程在被CPU调度运行,等待CPU资源分配以及等待外部事件 ...
随机推荐
- c++实现的顺序栈
栈是一种运算受限的线性表,是一种先进后出的数据结构,限定只能在一端进行插入和删除操作,允许操作的一端称为栈顶,不允许操作的称为栈底 因此需要的成员变量如下 int *_stack; //指向申请的空间 ...
- PowerBuilder学习笔记之导入Excel数据
原文地址:http://blog.chinaunix.net/uid-20586802-id-3235549.html /*****************简单的导入功能,涉及到数据类型判断***** ...
- 手写PE结构解析工具
PE格式是 Windows下最常用的可执行文件格式,理解PE文件格式不仅可以了解操作系统的加载流程,还可以更好的理解操作系统对进程和内存相关的管理知识,而有些技术必须建立在了解PE文件格式的基础上,如 ...
- 测试库异常down分析(abnormal instance termination)
客户测试库,down问题分析,根据alert 的问题指向,实例异常终止,但是无其它有价值的信息 Terminating the Instance Due to Error Out-Of-Memory( ...
- 路由基础(Routing)
查看本机路由表: [root@controller02 ~]# cat /etc/iproute2/rt_tables # # reserved values # 255 local 254 ...
- ActiveX控件的注册和反注册
原文转自 https://blog.csdn.net/piaopiaopiaopiaopiao/article/details/41649495 ActiveX控件,需要注册之后才能使用. 注意:注册 ...
- 笔记 - C#从头开始构建编译器 - 1
视频与PR:https://github.com/terrajobst/minsk/blob/master/docs/episode-01.md 作者是 Immo Landwerth(https:// ...
- OpenSSL 1.1.1 国密算法支持
OpenSSL 1.1.1 国密算法支持 https://www.openssl.org/ https://github.com/openssl/openssl OpenSSL 1.1.1 新特性: ...
- webstrom设置语句中的分号
webstrom可以设置语句默认是否添加分号 setting >editor > Code Style > Javascript
- 【转】使用Scanner输入字符串时next()和nextLine()区别
在实现字符窗口的输入时,很多人更喜欢选择使用扫描器Scanner,它操作起来比较简单.在编程的过程中,我发现用Scanner实现字符串的输入有两种方法,一种是next(),一种nextLine(),但 ...