spark 机器学习 ALS原理(一)
1.线性回归模型
线性回归是统计学中最常用的算法,当你想表示两个变量间的数学关系时,就可以用线性回归。当你使用它时,你首先假设输出变量(相应变量、因变量、标签)和预测变量(自变量、解释变量、特征)之间存在的线性关系。
(自变量是指:研究者主动操纵,而引起因变量发生变化的因素或条件,因此自变量被看作是因变量的原因。
因变量是指:在函数关系式中,某个量会随一个(或几个)变动的量的变动而变动。)
线性模型可能使用于类似下面的问题:比如你正在研究一个公司的销售额和该公司在广告上的投入之间的关系,或者某人在社交网站上的好友数量和他每天在该社交网站上花费的时间之间的关系。
理解线性回归一个切入点是先确定那条直线,我们知道,通过斜率和截距就可以完全确定一条直线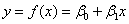
例子1:
假设 (用户数,利润值)
S={(x,y)=(1,25),(10,250),(100,2500)}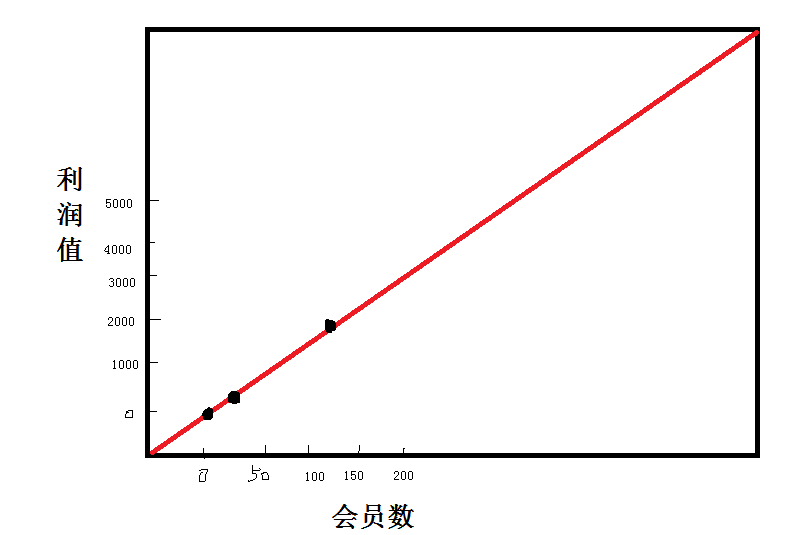
例子2:
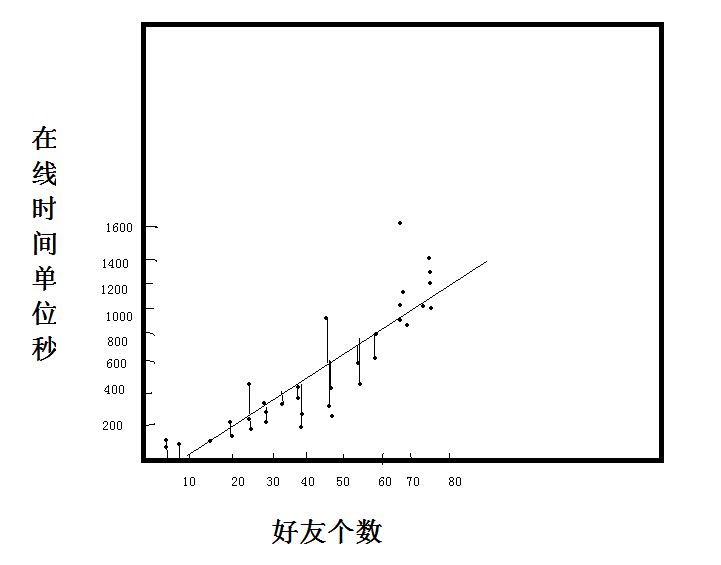
假设(好友数,在线时间)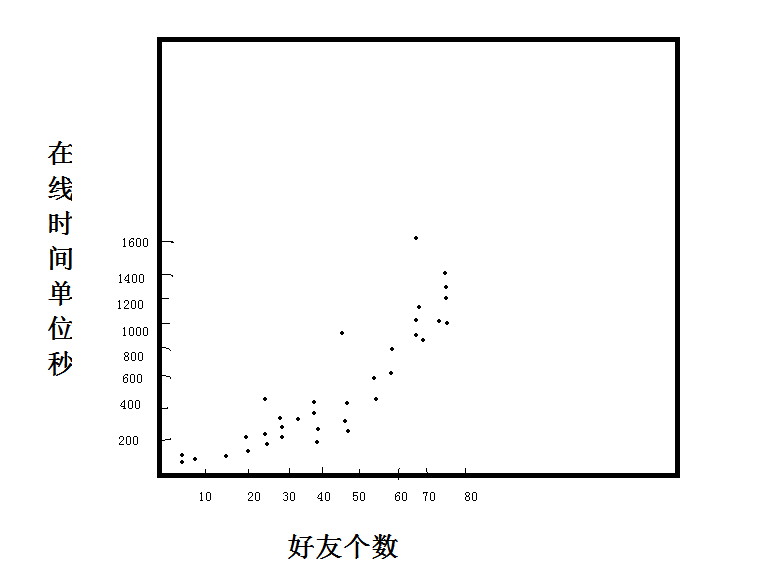
看到当前图片,很难一眼看出两个变量之间的关系了。
我们假设图中是线性关系,可以画出多条线。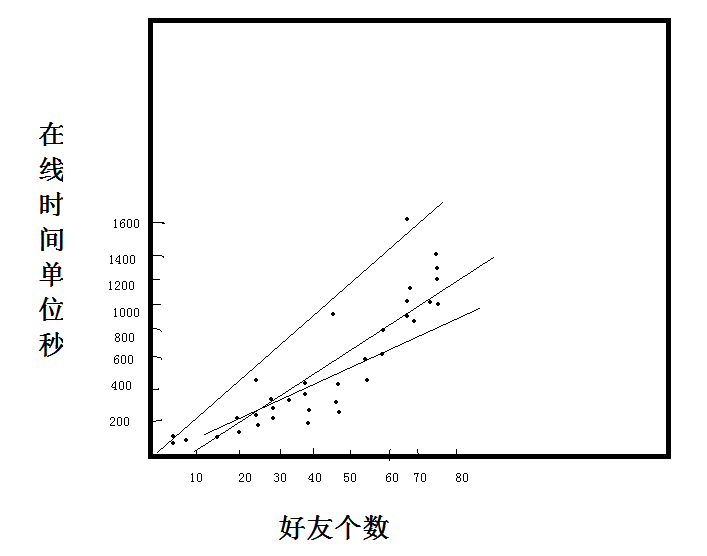
那么哪条线才是我们使用的最优线呢?这是一个拟合过程
2.spark ALS
ALS中文名作交替最小二乘法,就是在最小二乘法基础上的升级,在机器学习中,ALS特指使用最小二乘法求解的一个协同过滤算法,是协同过滤中的一种。ALS算法是2008年以来,用的比较多的协同过滤算法。从协同过滤的分类来说,ALS算法属于User-Item CF,也叫做混合CF,因为它同时考虑了User和Item两个方面,即即可基于用户进行推荐又可基于物品
如下图所示,u表示用户,v表示商品,用户给商品打分,但是并不是每一个用户都会给每一种商品打分。比如用户u6就没有给商品v3打分,需要我们推断出来,这就是机器学习的任务。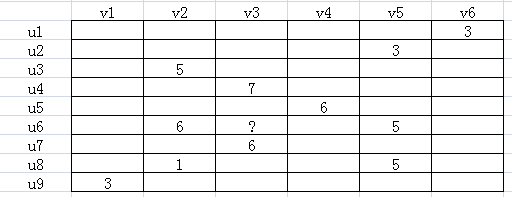
由于并不是每个用户给每种商品都打了分,可以假设ALS矩阵是低秩的,即一个m*n的矩阵,是由m*k和k*n两个矩阵相乘得到的,其中k<<m,n。
Am×n=Um×k×Vk×n
这种假设是合理的,因为用户和商品都包含了一些低维度的隐藏特征,比如我们只要知道某个人喜欢碳酸饮料,就可以推断出他喜欢百世可乐、可口可乐、芬达,而不需要明确指出他喜欢这三种饮料。这里的碳酸饮料就相当于一个隐藏特征。上面的公式中,Um×k表示用户对隐藏特征的偏好,Vk×n表示产品包含隐藏特征的程度。机器学习的任务就是求出Um×k和Vk×n。可知uiTvj是用户i对商品j的偏好,使用Frobenius范数来量化重构U和V产生的误差。由于矩阵中很多地方都是空白的,即用户没有对商品打分,对于这种情况我们就不用计算未知元了,只计算观察到的(用户,商品)集合R。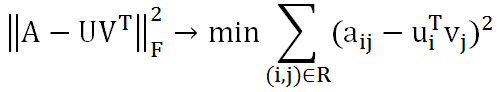
这样就将协同推荐问题转换成了一个优化问题。目标函数中U和V相互耦合,这就需要使用交替二乘算法。即先假设U的初始值U(0),这样就将问题转化成了一个最小二乘问题,可以根据U(0)可以计算出V(0),再根据V(0)计算出U(1),这样迭代下去,直到迭代了一定的次数,或者收敛为止。虽然不能保证收敛的全局最优解,但是影响不大。
spark 机器学习 ALS原理(一)的更多相关文章
- spark 机器学习 决策树 原理(一)
1.什么是决策树 决策树(decision tree)是一个树结构(可以是二叉树或者非二叉树).决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树. 其中每个非叶节点表示 ...
- spark 机器学习 knn原理(一)
1.knnK最近邻(k-Nearest Neighbor,KNN)分类算法,在给定一个已经做好分类的数据集之后,k近邻可以学习其中的分类信息,并可以自动地给未来没有分类的数据分好类.我们可以把用户分 ...
- 【转载】协同过滤 & Spark机器学习实战
因为协同过滤内容比较多,就新开一篇文章啦~~ 聚类和线性回归的实战,可以看:http://www.cnblogs.com/charlesblc/p/6159187.html 协同过滤实战,仍然参考:h ...
- Spark机器学习之协同过滤算法
Spark机器学习之协同过滤算法 一).协同过滤 1.1 概念 协同过滤是一种借助"集体计算"的途径.它利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度.其内在思想是相 ...
- Spark生态以及原理
spark 生态及运行原理 Spark 特点 运行速度快 => Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算.官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapR ...
- Spark 以及 spark streaming 核心原理及实践
收录待用,修改转载已取得腾讯云授权 作者 | 蒋专 蒋专,现CDG事业群社交与效果广告部微信广告中心业务逻辑组员工,负责广告系统后台开发,2012年上海同济大学软件学院本科毕业,曾在百度凤巢工作三年, ...
- Spark机器学习6·聚类模型(spark-shell)
K-均值(K-mean)聚类 目的:最小化所有类簇中的方差之和 类簇内方差和(WCSS,within cluster sum of squared errors) fuzzy K-means 层次聚类 ...
- Spark机器学习3·推荐引擎(spark-shell)
Spark机器学习 准备环境 jblashttps://gcc.gnu.org/wiki/GFortranBinaries#MacOS org.jblas:jblas:1.2.4-SNAPSHOT g ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
随机推荐
- iOS点击按钮第二次不能旋转View
原因: 用CGAffineTransformMakeRotation,每次旋转都要在之前最后的角度基础之上再转才有效果. - (void)clickAction: (UIButton *)button ...
- 【GStreamer开发】GStreamer播放教程04——既看式流
目的 在<GStreamer基础教程--流>里面我们展示了如何在较差的网络条件下使用缓冲这个机制来提升用户体验.本教程在<GStreamer基础教程--流>的基础上在扩展了一下 ...
- MangoDB
<MongoDB权威指南> 一.简介 MongoDB是一款强大.灵活.且易于扩展的通用型数据库 1.易用性 MongoDB是一个面向文档(document-oriented)的数据库,而不 ...
- 利用单臂路由实现vlan间路由
本实验模拟公司场景 通过路由器实现不同vlan部门间通讯,拓扑图如下
- python字符串/列表/元组/字典之间的相互转换(5)
一.字符串str与列表list 1.字符串转列表 字符串转为列表list,可以使用str.split()方法,split方法是在字符串中对指定字符进行切片,并返回一个列表,示例代码如下: # !usr ...
- pycharm设置开发模板/字体大小/背景颜色(3)
一.pycharm设置字体大小/风格 选择 File –> setting –> Editor –> Font ,可以看到如上界面,可以根据自己的喜好随意调整字体大小,字体风格,文字 ...
- 012 Android 动画效果(补间动画) +去掉App默认自带的标题+更改应用的图标
1.介绍 补间动画开发者只需指定动画开始,以及动画结束"关键帧", 而动画变化的"中间帧"则由系统计算并补齐! 2.去掉App的标题 (1)将AndroidMa ...
- java当中JDBC当中请给出一个DataSource的单态模式(SingleTon)HelloWorld例子
[学习笔记] 2.DataSource的单态模式(SingleTon)程序 咱们还接着上面的例子来说.1万个人要看书.千万确保要只建立一个图书馆.要是一不留神,建了两个或三个图书馆,那可就亏大发了.对 ...
- Python类和实例调用
self指向的是实例对象,作为第一个参数,使用时不需要传入此参数. class Student(object): #定义一个Student类, def __init__(self, name, sco ...
- 函数的第一类对象,f格式化,迭代器以及递归
函数名的第一类对象及使用,f格式化以及迭代器 1.函数的第一类对象 第一类对象 --特殊点 1.可以当作值被赋值给变量 def func(): print(1) a = func a() 2.可以当作 ...