kubernetes 的数据的存储 存储卷
根据应用本身是否 需要持久存储数据,以及某一此请求和此前的请求是否有关联性,可以分为四类应用:
1.有状态要存储 2.有状态无持久存储 3.无状态无持久存储4.无状态有持久存储
在k8s上的数据持久性:1.emptyDir:只在节点本地使用,一旦pod删除存储卷也删除。只是用来做临时目录,可是做缓存用 没有任何持久性
2.hostPath:主机路径,直接在宿主机上找一个目录与容器建立关联关系,也不具有真正意义上的持久性
3.网络连接性存储 1)传统意义上的存储设备,本地的san(iscsi),nas(nfs,cifs)
2) 分布式存储 文件系统级别的(glusterfs,cephfs) 块存储级别的(ceph)
3)云存储 EBS、Azure Disk、
可以通过命令 kubectl explain pod.spec.volumes
一、emptyDir:同一个pod内的多个容器可以共享同一个存储卷,pod删除存储卷也删除。不能实现数据存储化
- apiVersion: v1
- kind: Pod
- metadata:
- name: pod-volume
- namespace: default
- labels:
- app: myapp
- tier: frontend
- annotations:
- create_by: yiruiduan
- spec:
- containers:
- - name: nginx
- image: ikubernetes/myapp:v1
- imagePullPolicy: IfNotPresent
- ports:
- - name: http
- containerPort:
- volumeMounts:
- - name: html
- mountPath: /usr/share/nginx/html/
- - name: busybox
- image: busybox:latest
- imagePullPolicy: IfNotPresent
- volumeMounts:
- - name: html
- mountPath: /data
- command: ['/bin/sh','-c',"while true;do echo $(date) >>/data/index.html;sleep 2;done"]
- volumes:
- - name: html
- emptyDir: {}
访问nginx就可以看到动态生成的index.html
二、hostPathsu宿主机路径,把pod所在的宿主机之上的文件 系统的某一目录,与pod建立关系,在pod被删除的时候,这个存储卷是不会被删除的。所以只要同一个pod能够调度到同一个节点上,对应的数据依然是存在的。这只是节点及的持久,节点down了数据也就没有了。存在数据丢失
- apiVersion: v1
- kind: Pod
- metadata:
- name: pod-vol-hostpath
- namespace: default
- spec:
- containers:
- - name: myapp
- image: ikubernetes/myapp:v1
- volumeMounts:
- - name: html
- mountPath: /usr/share/nginx/html
- volumes:
- - name: html
- hostPath:
- path: /data/pod/volume1
- type: DirectoryOrCreate #如果目录不存在就创建
三、nfs共享存储,节点挂在共享存储。无论调度在那个节点上所有数据能共享访问。
- apiVersion: v1
- kind: Pod
- metadata:
- name: pod-vol-nfs
- namespace: default
- spec:
- containers:
- - name: myapp
- image: ikubernetes/myapp:v1
- volumeMounts:
- - name: html
- mountPath: /usr/share/nginx/html
- volumes:
- - name: html
- nfs:
- path: /k8s #nfs所共享的目录
- server: 192.168.1.120 #nfs服务器地址
四、pvc(persistentVolumeClaim)
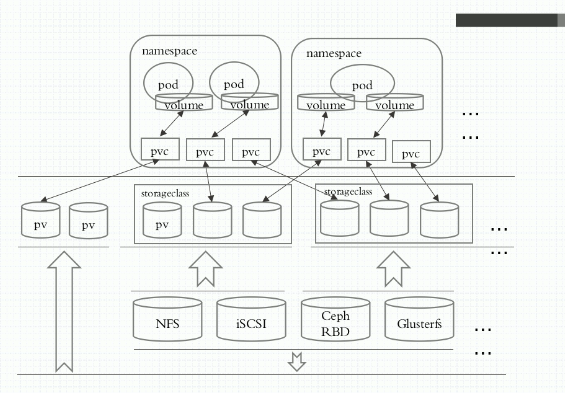
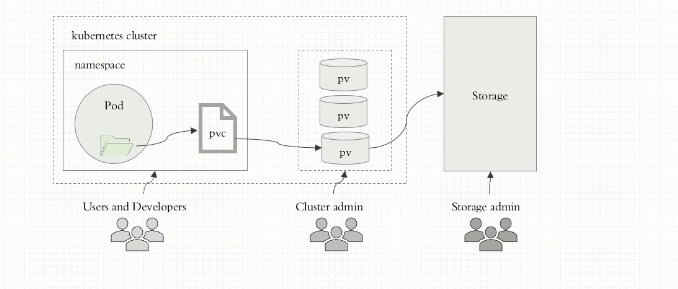
首先要制作pv,它是不包含名称空间中的。通过nfs共享目录的形式
- apiVersion: v1
- kind: PersistentVolume
- metadata:
- name: pv001
- labels:
- name: pv001
- spec:
- nfs:
- path: /k8s/v1
- server: 192.168.1.120
- accessModes: ["ReadWriteMany","ReadWriteOnce"] #访问模式
- capacity: #设置pv的大小
- storage: 2Gi
制作pvc
- apiVersion: v1
- kind: PersistentVolumeClaim
- metadata:
- name: mypvc
- namespace: default
- spec:
- accessModes: ["ReadWriteMany"] #是pv的访问模式的子集
- resources: #所需pv的大小
- requests:
- storage: 6Gi
pod 使用pvc
- apiVersion: v1
- kind: Pod
- metadata:
- name: pod-vol-pvc
- namespace: default
- spec:
- containers:
- - name: myapp
- image: ikubernetes/myapp:v1
- volumeMounts:
- - name: html
- mountPath: /usr/share/nginx/html
- volumes:
- - name: html
- persistentVolumeClaim:
- claimName: mypvc
pv的动态供给
kubernetes 的数据的存储 存储卷的更多相关文章
- Kubernetes (1.6) 中的存储类及其动态供给
原文地址:http://blog.fleeto.us/translation/dynamic-provisioning-and-storage-classes-kubernetes-0?utm_sou ...
- Longhorn,Kubernetes 云原生分布式块存储
Longhorn 是用于 Kubernetes 的轻量级.可靠且功能强大的分布式块存储系统. Longhorn 使用容器(containers)和微服务(microservices)实现分布式块存储. ...
- MySQL内核:InnoDB存储引擎 卷1
MySQL内核:InnoDB存储引擎卷1(MySQL领域Oracle ACE专家力作,众多MySQL Oracle ACE力捧,深入MySQL数据库内核源码分析,InnoDB内核开发与优化必备宝典) ...
- Docker 存储之卷(Volume)
理解Docker(8):Docker 存储之卷(Volume) (1)Docker 安装及基本用法 (2)Docker 镜像 (3)Docker 容器的隔离性 - 使用 Linux namespa ...
- Centos7——docker持久化存储和卷间状态共享(笔记)
docker持久化存储和卷间状态共享(笔记) 本章介绍 存储卷的介绍 存储卷的两种类型 宿主机好额容器之间如何共享数据 容器之间如何共享数据 存储卷的声明周期 存储卷之间的数据管理和控制模式 就像在 ...
- ios开发之数据的持久化存储机制
IOS中数据的持久化保存这块内容,类似于Android中文件的几种常见的存储方式. 对于数据的持久化存储,ios中一般提供了4种不同的机制. 1.属性列表 2.对象归档 3.数据库存储(SQLite3 ...
- 云方案,依托H3C彩虹云存储架构,结合UIA统一认证系统,实现了用户数据的集中存储和管理
客户的声音 资料云项目在迷你云基础上二次开发,通过使用云存储技术及文件秒传技术,对文件进行统一存储与管理,以达到节约文件管理成本.存储成本目的:通过有效的文件版本控制机制,以达到风险管控的目的:通过多 ...
- mysql 数据表操作 存储引擎介绍
一 什么是存储引擎? 存储引擎就是表的类型. mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制 ...
- kafka传数据到Flink存储到mysql之Flink使用SQL语句聚合数据流(设置时间窗口,EventTime)
网上没什么资料,就分享下:) 简单模式:kafka传数据到Flink存储到mysql 可以参考网站: 利用Flink stream从kafka中写数据到mysql maven依赖情况: <pro ...
- linux下,MySQL默认的数据文档存储目录为/var/lib/mysql。
0.说明 Linux下更改yum默认安装的mysql路径datadir. linux下,MySQL默认的数据文档存储目录为/var/lib/mysql. 假如要把MySQL目录移到/home/data ...
随机推荐
- spark调优篇-spark on yarn web UI
spark on yarn 的执行过程在 yarn RM 上无法直接查看,即 http://192.168.10.10:8088,这对于调试程序很不方便,所以需要手动配置 配置方法 1. 配置 spa ...
- MongoDB数据库、集合、文档的操作
MongoDB系列第一课:MongDB简介 MongoDB系列第二课:MongDB环境搭建 MongoDB系列第三课:MongDB用户管理 MongoDB系列第四课:MongoDB数据库.集合.文档的 ...
- docker启动mysql 自定义配置文件
命令行如下: docker run --name mysql56 -p : -v /home/mysql56/data:/var/lib/mysql -v /home/mysql56/conf:/et ...
- Django2.0 应用 Xadmin 报错二
以上错误是运行点击添加数据等报异常,全是度年解决,并记录解决方法 1.报异常 ‘某个字段类型 ‘ object has no attribute ‘rel‘,点击报异常的地方,把.rel 修改为.re ...
- Windows 下 nvm, node, npm 的下载、安装与配置
主要解决的问题 下载安装完 nvm 和 node 后,缺失 npm 文件 执行 jasmine 等命令时提示「不是内部或外部命令...」及全局变量的设置 下载与安装 一.nvm github 下载地址 ...
- JavaScript中的setTimeout、setInterval和随机函数制作简易抽奖小程序
几乎所有计算机语言有都内置随机函数.当然这种随机,人们习惯称为伪随机数发生器,产生的是一个[0,1)之间的一个小数.再通过简单算术运算生成一个符合需求的整数.JS中通用公式通常为parseInt(Ma ...
- struts 漏洞
安装shop++ 安装成功 访问 http://127.0.0.1:8080 即网站首页 访问 http://127.0.0.1:8080/admin 即网站后台
- ASR测试方法---字错率(WER)、句错率(SER)统计
一.基础概念 1.1.语音识别(ASR) 语音识别(speech recognition)技术,也被称为自动语音识别(英语:Automatic Speech Recognition, ASR), 狭隘 ...
- 5.1 Request 获取请求数据的几种方法
//获取请求头和请求数据 //请求数据(1.通过超链接 2.通过表单) //获取请求数据的时候一般来说 都要先检查 再使用 public class RequestDemo2 extends Http ...
- 基于docker搭建elasticsearch集群
es集群的搭建 - 基于单机搭建elasticsearch集群见官网 https://www.elastic.co/guide/en/elasticsearch/reference/current/d ...