HDFS Federation(转HDFS Federation(HDFS 联盟)介绍 CSDN)
转载地址:http://blog.csdn.net/strongerbit/article/details/7013221
HDFS Federation(HDFS 联盟)介绍
1. 当前HDFS架构和功能概述
我们先回顾一下HDFS功能。HDFS实际上具有两个功能:命名空间管理(Namespace management)和块/存储管理服务(block/storage management)。
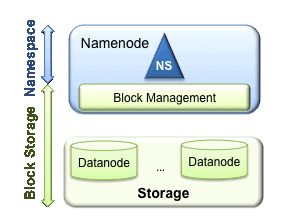
1.1 命名空间管理
HDFS的命名空间包含目录、文件和块。命名空间管理:是指命名空间支持对HDFS中的目录、文件和块做类似文件系统的创建、修改、删除、列表文件和目录等基本操作。
1.2 块/存储管理
在块存储服务中包含两部分工作:块管理和物理存储。这是一个更通用的存储服务。其他的应用可以直接建立在Block Storage上,如HBase,Foreign Namespaces等。
1.2.1 块管理
A) 处理Data Node向Name Node注册的请求,处理datanode的成员关系,处理来自Data Node周期性的心跳。
B) 处理来自块的报告信息,维护块的位置信息。
C) 处理与块相关的操作:块的创建、删除、修改及获取块信息。
D) 管理副本放置(replica placement)和块的复制及多余块的删除。
1.2.2 物理存储
所谓物理存储就是:Data Node把块存储到本地文件系统中,对本地文件系统的读、写。
1.3 当前HDFS的架构
在当前的HDFS架构中(Hadoop v0.23之前),在整个HDFS集群中只有一个命名空间,并且只有单独的一个Name Node,这个Name Node负责对这单独的一个命名空间进行管理。这也正是单点失效(Single Point Failure)的隐患所在。本文所讲的HDFS Federation就是针对当前HDFS架构上的缺陷所做的改进,简单说HDFS Federation就是使得HDFS支持多个命名空间,并且允许在HDFS中同时存在多个Name Node。
简单回顾一下目前HDFS的架构,如下图所示。在整个HDFS集群中只有一个Namenode,还有一个Backup Namenode。Namenode会实时将变化的HDFS的信息同步给Backup Namenode。Backup Namenode顾名思义是用来做Namenode的备份的。Namenode中命名空间以层次结构组织中存储着文件名和BlockID的对应关系、BlockID和具体Block位置的对应关系。这个单独的Namenode管理着数个Datanode,Block分布在各个Datanode中,每个Datanode会周期性的向此Namenode发送心跳消息,报告自己所在Datanode的使用状态。Block是用来存储数据的最小单元,通常一个文件会存储在一个或者多个Block中,默认Block大小为64MB。

2. 单个Namenode的HDFS架构的局限性
2.1 Namespace(命名空间)的限制
2.2 性能的瓶颈
2.3 隔离问题
2.4 集群的可用性
2.5 Namespace和Block Management的紧密耦合
2.6 为什么纵向扩展目前的Namenode不可行?比如将Namenode的Heap空间扩大到512GB。
3. 为什么要引入Federation
引入Federation的最主要原因是简单,其简单性是与真正的分布式Namenode相比而言的。Federation能够快速的解决了大部分单Namenode HDFS的问题。
Federation是简单鲁棒的设计,由于联盟中各个Namenode之间是相互独立的。Federation整个核心设计实现大概用了3.5个月。大部分改变是在Datanode、Config和Tools,而Namenode本身的改动非常少,这样Namenode原先的鲁棒性不会受到影响。比分布式的Namenode简单,虽然这种实现的扩展性比起真正的分布式的Namenode要小些,但是可以迅速满足需求。另外一个原因是Federation良好的向后兼容性,已有的单Namenode的部署配置不需要任何改变就可以继续工作。
4. HDFS Federation

4.1 Federation HDFS与当前HDFS的比较
- 当前HDFS只有一个命名空间(Namespace),它使用全部的块。而Federation HDFS中有多个独立的命名空间(Namespace),并且每一个命名空间使用一个块池(block pool)。
- 当前HDFS中只有一组块。而Federation HDFS中有多组独立的块。块池(block pool)就是属于同一个命名空间的一组块。
- 当前HDFS由一个Namenode和一组datanode组成。而Federation HDFS由多个Namenode和一组datanode,每一个datanode会为多个块池(block pool)存储块。
4.2 Block Pool(块池)
所谓Block pool(块池)就是属于单个命名空间的一组block(块)。每一个datanode为所有的block pool存储块。Datanode是一个物理概念,而block pool是一个重新将block划分的逻辑概念。同一个datanode中可以存着属于多个block pool的多个块。Block pool允许一个命名空间在不通知其他命名空间的情况下为一个新的block创建Block ID。同时,一个Namenode失效不会影响其下的datanode为其他Namenode的服务。
当datanode与Namenode建立联系并开始会话后自动建立Block pool。每个block都有一个唯一的标识,这个标识我们称之为扩展的块ID(Extended Block ID)= BlockID+BlockID。这个扩展的块ID在HDFS集群之间都是唯一的,这为以后集群归并创造了条件。
Datanode中的数据结构都通过块池ID(BlockPoolID)索引,即datanode中的BlockMap,storage等都通过BPID索引。
在HDFS中,所有的更新、回滚都是以Namenode和BlockPool为单元发生的。即同一HDFS Federation中不同的Namenode/BlockPool之间没有什么关系。
Hadoop V0.23版本中Block Pool的管理功能依然放在了Namenode中,将来的版本中会将Block Pool的管理功能移动的新的功能节点中。
4.3 Datanode的改进
在datanode中,对应于每个Namnode都有一条相应的线程。每个datanode会去每一个Namenode注册,并且周期性的给所有的Namenode发送心跳及datanode的使用报告。Datanode还会给Namenode发送其所在的block pool的block report(块报告)。由于有多个Namenode同时存在,因此任何一个Namenode都可以随时动态加入、删除和更新。
4.4 Federation中的其他方面的改进
- 提供了工具,对于Namenode的初始化和退役的监控和管理。
- 允许在datanode级别或者block pool级别的负载均衡。
- Datanode的后台守护进程,为Federation所做的磁盘和目录扫描。
- 提供了显示Namenode的Block pool的使用状态的Web UI。
- 还提供了对全部集群存储使用状态的UI展示。
- 在Web UI中列出了所有的Namenode及其细节,如Namenode-BlockPoolID和存储的使用状态,失去联系的、活的和死的块信息。还有前往各个Namenode Web UI的链接。
- Datanode退役状态的展示。
4.5 多命名空间的管理问题

如上图所示,每个深色三角形代表一个独立的命名空间,上方浅色的三角形代表从客户角度去访问下方的子命名空间。各个深色的命名空间Mount到浅色的表中,客户可以访问不同的挂载点来访问不同的命名空间,这就如同在Linux系统中访问不同挂载点一样。这就是HDFS Federation中命名空间管理的基本原理:将各个命名空间挂载到全局mount-table中,就可以做将数据到全局共享;同样的命名空间挂载到个人的mount-table中,这就成为应用程序可见的命名空间视图。
4.6 Namespace Volume(命名空间卷)
4.7 ClusterID
在HDFS Federation中添加了Cluster ID用来区分集群中的每个节点。当格式化一个Namenode时,这个ClusterID会自动生成或者手动提供。在格式化同一集群中其他Namenode时会用到这个ClusterID。
4.8 HDFS Federation对老版本的HDFS是兼容的
这种兼容性可以使得已有的Namenode配置不需要任何改变继续工作。
具体的如何配置和管理Federation HDFS,请参考 http://hadoop.apache.org/common/docs/r0.23.0/hadoop-yarn/hadoop-yarn-site/Federation.html#Federation_Configuration 。
参考资料:
Hadoop is here: http://hortonworks.com/apache-hadoop-is-here
HDFS Federation: http://www.slideshare.net/ydn/hug-march-hdfs-federation
HDFS Federation: http://hadoop.apache.org/common/docs/r0.23.0/hadoop-yarn/hadoop-yarn-site/Federation.html
HDFS Federation hadoop submit 2011: http://www.slideshare.net/huguk/hdfs-federation-hadoop-summit2011
An Introduction to HDFS Federation: http://hortonworks.com/an-introduction-to-hdfs-federation/
HDFS Federation(转HDFS Federation(HDFS 联盟)介绍 CSDN)的更多相关文章
- Mysql增量写入Hdfs(二) --Storm+hdfs的流式处理
一. 概述 上一篇我们介绍了如何将数据从mysql抛到kafka,这次我们就专注于利用storm将数据写入到hdfs的过程,由于storm写入hdfs的可定制东西有些多,我们先不从kafka读取,而先 ...
- HDFS概述(4)————HDFS权限
概述 Hadoop分布式文件系统(HDFS)的权限模型与POSIX模型的文件和目录权限模型一致.每个文件和目录与所有者和组相关联.该文件或目录将权限划分为所有者的权限,作为该组成员的其他用户的权限.以 ...
- HDFS概述(1)————HDFS架构
概述 Hadoop分布式文件系统(HDFS)是一种分布式文件系统,用于在普通商用硬件上运行.它与现有的分布式文件系统有许多相似之处.然而,与其他分布式文件系统的区别很大.HDFS具有高度的容错能力,旨 ...
- Flume启动时报错Caused by: java.lang.InterruptedException: Timed out before HDFS call was made. Your hdfs.callTimeout might be set too low or HDFS calls are taking too long.解决办法(图文详解)
前期博客 Flume自定义拦截器(Interceptors)或自带拦截器时的一些经验技巧总结(图文详解) 问题详情 -- ::, (agent-shutdown-hook) [INFO - org.a ...
- hdfs深入:03、hdfs的架构以及副本机制和block块存储
HDFS分布式文件系统设计目标 1. 硬件错误 由于集群很多时候由数量众多的廉价机组成,使得硬件错误成为常态 2. 数据流访问 所有应用以流的方式访问数 ...
- 初识HDFS(10分钟了解HDFS、NameNode和DataNode)
概览 首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通 ...
- HDFS概述(3)————HDFS Federation
本指南概述了HDFS Federation功能以及如何配置和管理联合集群. 当前HDFS背景 HDFS主要有两层: 1.Namespace (1)包含目录,文件和块. (2)它支持所有命名空间相关的文 ...
- Hadoop HDFS (3) JAVA訪问HDFS之二 文件分布式读写策略
先把上节未完毕的部分补全,再剖析一下HDFS读写文件的内部原理 列举文件 FileSystem(org.apache.hadoop.fs.FileSystem)的listStatus()方法能够列出一 ...
- HDFS概述(5)————HDFS HA
HA With QJM 目标 本指南概述了HDFS高可用性(HA)功能以及如何使用Quorum Journal Manager(QJM)功能配置和管理HA HDFS集群. 本文档假设读者对HDFS集群 ...
随机推荐
- webpack build后生成的app、vendor、manifest三者有何职能不同?
贴一下之前vue脚手架的webpack3配置: app.js是入口js,vendor则是通过提取公共模块插件来提取的代码块(webpack本身带的模块化代码部分),而manifest则是在vendor ...
- Node.js开发——MongoDB与Mongoose
为了保存网站的用户数据和业务数据,通常需要一个数据库.MongoDB和Node.js特别般配,因为MongoDB是基于文档的非关系型数据库,文档是按BSON(JSON的轻量化二进制格式)存储的,增删改 ...
- ES6之class 中 constructor 方法 和 super 的作用
首先,ES6 的 class 属于一种“语法糖”,所以只是写法更加优雅,更加像面对对象的编程,其思想和 ES5 是一致的. function Point(x, y) { this.x = x; thi ...
- 小任务之使用SVG画柱状图~
function drawBar(data) { var barGraph = document.querySelector("#bar-graph"); var graphWid ...
- base64的编码解码的一些坑
1. //编码 value = base64encode(utf16to8(src)) //解码 value = utf8to16(base64decode(src)) 这里:base64编码之前先转 ...
- 第四次作业-第一次scrum冲刺
团队成员 周斌 舒 溢 许嘉荣 唐 浩 黄欣欣 1.第一次冲刺任务安排 对Github上的HUSTOJ开源项目进行Fork,搭建基本环境 2.用户需求 ①基本功能显示在首页 ②能够提交题目并判题,并对 ...
- Elk and nginx and redis 干货
ELKStack ELKStack即Elasticsearch + Logstash + Kibana.日志监控和分析在保障业务稳定运行时,起到了很重要的作用.比如对nginx日志的监控分析,ngin ...
- Java初学者 编译能通过,但显示有错误,并且不会自动弹出方法的解决方法。
因为使用了 @Data注解,关于注解的作用尚未深入理解,此处先做一个记录. 解决方法是,添加lombok插件
- Windows ->> FIX: “The security database on the server does not have a computer account for this workstation trust relationship”
前几天在做AlwaysOn实验时遇到搭建活动目录域时某台已经加入AD的机器无法以域管理员账户登录的情况. 报错信息是:The security database on the server does ...
- abstract(抽象)修饰符
abstract(抽象)修饰符,可以修饰类和方法 1,abstract修饰类,会使这个类成为一个抽象类,这个类将不能生成对象实例,但可以做为对象变量声明的类型,也就是编译时类型,抽象类就像当于一类的半 ...