FileChannel类支持从连接到文件的通道读取字节或向其写入字节,以及查询和修改当前的文件位置及将文件调整为指定大小等常见操作。它定义了在整个文件或具体文件区域上获取锁定的方法;这些方法返回FileLock类的实例。最后,它定义了对要写入到存储设备的文件进行强行更新的方法、在文件和其他通道之间高效传输字节的方法,以及将文件区域直接映射到内存中的方法。你可以配置通道进行阻塞或非阻塞操作。在阻塞方式下调用读、写或其他操作时,直到操作完成才能返回。例如,在缓慢的套接字上进行大型写操作可能要用很长时间。在非阻塞模式下,在缓慢的套接字上写入大型缓冲器只是排列数据(可能在一个操作系统缓冲器,或在网卡上的缓冲器中)并立即返回。线程可能转向其他任务,而由操作系统的输入/输出管理器完成工作。从文件通道中移出,可将我们带到读出及写入套接字的连接通道。你还能够以阻塞或非阻塞方式应用这些通道。在阻塞方式下,它们视客户或服务器而替代连接或接受调用。在非阻塞方式下,就没有对应项。
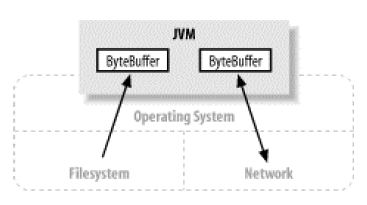
通道和操作系统的底层I/O Service直接连通,而通过Channel可以连接到操作系统里面的实体,比如下图中的文件系统和网络设备:
通道是java.nio的核心组件,这里先整体透视一下它的所有Channel相关接口的结构:
[I]java.nio.channels.Channel(1.4)
|—[I]java.nio.channels.InterruptibleChannel(1.4)
|—[I]java.nio.channels.ReadableByteChannel(1.4)
|—[I]java.nio.channels.ByteChannel(1.4)
|—[I]java.nio.channels.ScatteringByteChannel(1.4)
|—[I]java.nio.channels.WritableByteChannel(1.4)
|—[I]java.nio.channels.GatheringByteChannel(1.4)
|—[I]java.nio.channels.ByteChannel(1.4)
【*:ByteChannel是多继承通道接口,它同时继承了两个接口】
Channel接口:
该通道为所有通道接口的父接口,用于IO操作的连接用,通道表示到实体、如硬件设备、文件、网络套接字或可以执行一个或多个不同IO操作的程序组件开放的连接。通道可处于打开或关闭状态,创建通道时它处于打开状态,一旦将其关闭,则保持关闭状态。一旦关闭了某个通道,视图调用IO操作的时候就会导致ClosedChannelException抛出;
InterruptibleChannel接口:
可被异步关闭和中断的通道,实现此接口的通道是可异步关闭的;如果某个线程阻塞于可中断通道上的IO操作,则另一个线程可调用该通道的close()方法,这将导致已阻塞线程接收到AsynchronousCloseException;实现此接口的通道也是可中断的:如果某个线程阻塞于可中断通道上的IO操作中,则另一个线程可调用该阻塞线程的interrupt方法,这将导致该通道被关闭,已阻塞线程接收到ClosedByInterruptException,并且设置已阻塞线程的中断状态。如果已设置某个线程的中断状态并且它在通道上调用某个阻塞的IO操作,则该通道将关闭并且该线程立即接收到ClosedByInterruptException,并仍然设置其中断状态;当且仅当某个通道实现此接口时,该通道才支持异步关闭和中断。如有必要,可在运行时通过instanceof操作符进行测试。
ReadableByteChannel接口:
在任意给定时刻,一个可读取通道上只能进行一个读取操作。如果某个线程在通道上发起读取操作,那么在第一个操作完成之前,将阻塞其他所有试图发起另一个读取操作的线程。其他种类的 I/O 操作是否继续与读取操作并发执行取决于该通道的类型。
WritableByteChannel接口:
在任意给定时刻,一个可写入通道上只能进行一个写入操作。如果某个线程在通道上发起写入操作,那么在第一个操作完成之前,将阻塞其他所有试图发起另一个写入操作的线程。其他种类的 I/O 操作是否继续与写入操作并发执行则取决于该通道的类型。
ScatteringByteChannel接口:
分散读取操作可在单个调用中将一个字节序列读入一个或多个给定的缓冲区序列。分散读取通常在实现网络协议或文件格式时很有用,例如将数据分组放入段中(这些段由一个或多个长度固定的头,后跟长度可变的正文组成)。在 GatheringByteChannel 接口中定义了类似的集中写入操作。
GatheringByteChannel接口:
集中写入操作可在单个调用中写入来自一个或多个给定缓冲区序列的字节序列。集中写入通常在实现网络协议或文件格式时很有用,例如将数据分组放入段中(这些段由一个或多个长度固定的头,后跟长度可变的正文组成)。在 ScatteringByteChannel 接口中定义了类似的分散读取操作。
ByteChannel接口:
可读取和写入字节的信道。此接口只是统一了 ReadableByteChannel 和 WritableByteChannel;它没有指定任何新操作。
[1]Scatter/Gather分散/集中通道
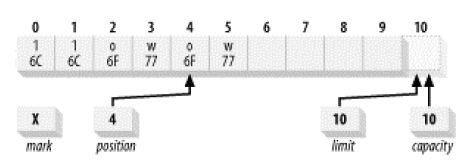
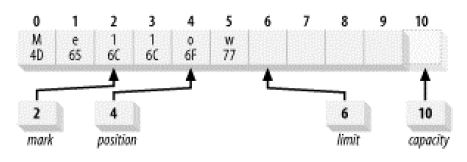
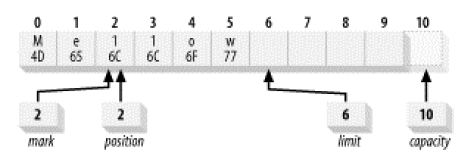
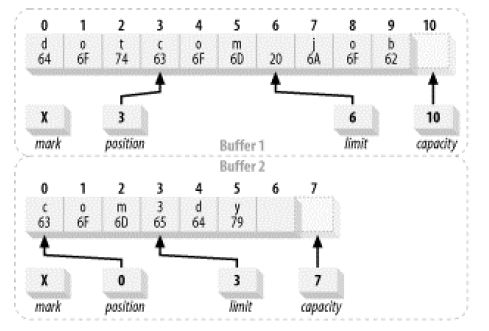
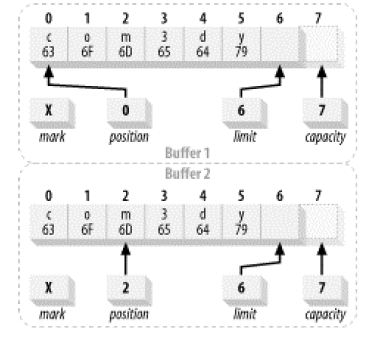
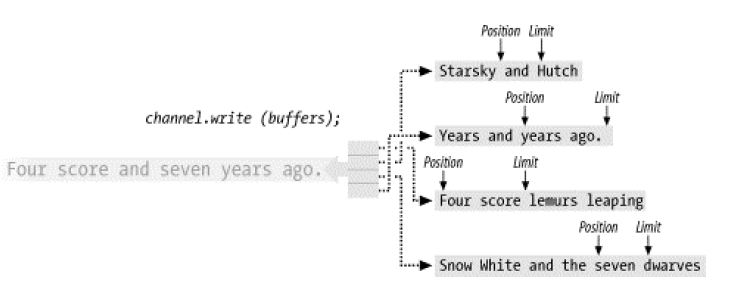
Java NIO读写通道系统里面提供了一个比较高效的文件读写模型,这种模型称为:集中/分散通道模型,也就是该章节讲到的Scatter和Gather模型。这个概念很强大,但是理解起来应该不难,它提供了多个缓冲区(Buffer)来执行读写操作,当应用程序在进行写操作或者读操作的时候,数据会从许多个缓冲区集中起来发送到该通道里面,这些缓冲区可以有不同的容量,这种读写方式也可以称为数据的分流读写,让后最终按照一定的顺序把这些数据组合到一起进行集中读写。【*:可以思考这样问题,这种模型下可能最需要考虑的是数据读写的完整性,因为所有的数据都是按照字节进行读写,一旦拆分然后再组合有可能会出现错误,但是该模型虽然提供了很多缓冲区,但是这些缓冲区都是有序的,这种模型在Java NIO里面使用ScatteringByteChannel和GatheringByteChannel的设计来完成。】其实很多操作系统都使用了该模型进行读写的操作,而且仔细思考这两个通道必定是直接操作ByteBuffer也就是字节缓冲区,使用这个类可以完成更加高效的读写,并借助操作系统的优势去提高读写效率。
下图描述了组合写数据:Gather方式,数据写入到每一个缓冲区里面,这些缓冲区被保存该数据的数组引用,并且是每一个缓冲区都可以被引用到,然后按照流的方式进行分散写入。
接下来演示分散读取这些写入数据,数据到达了通道过后就被该通道读取分散在不同的Buffer缓冲区里面的数据:
【*:针对这两个类谈谈个人的思考心得,分散聚合读写操作使得所有的数据可以分流进行读写,并且不同的缓冲区里面在读写过程中可以同时进行,类似并发读写的操作,当然这里的并发是指代Buffer相互之间互不影响的过程,Java NIO里面的这种通道结构使得数据的读写可以更加高效。至于如何分发数据到每一个缓冲区以及如何从缓冲区里面将数据组合过后使得数据的完整性得到保障不属于我们在开发过程去关心的内容,由Java的两个通道类来完成。】
——[$]提供一个集中写入例子——
package org.susan.java.io;
import java.io.FileOutputStream;
import java.nio.ByteBuffer;
import java.nio.channels.GatheringByteChannel;
import java.util.LinkedList;
import java.util.List;
import java.util.Random;
public class ScatterGatherMain {
private static final String DEMOGRAPHIC = "D:/work/blahblah.txt";
public static void main(String args[]) throws Exception{
int reps = 10;
if( args.length > 0){
reps = Integer.parseInt(args[0]);
}
FileOutputStream fos = new FileOutputStream(DEMOGRAPHIC);
GatheringByteChannel gatherChannel = fos.getChannel();
ByteBuffer[] bs = utterBS(reps);
while(gatherChannel.write(bs) > 0){}
System.out.println("Mindshare paradigms synergized to " + DEMOGRAPHIC);
fos.close();
}
private static String[] col1 = {
"Aggregate", "Enable","Leverage",
"Facilitate","Synergize","Repurpose",
"Strategize","Reinvent","Harness"
};
private static String[] col2 = {
"Cross-platform","best-of-bread","frictionless",
"ubiquitous","extensible","compelling",
"mission-critical","collaborative","integrated"
};
private static String[] col3 ={
"methodologies","infomediaries","platforms",
"schemas","mindshare","paradigms",
"functionalities","web services","infrastructures"
};
private static final String newLine = System.getProperty("line.separator");
private static ByteBuffer[] utterBS(int howMany) throws Exception{
List<ByteBuffer> list = new LinkedList<ByteBuffer>();
for( int i = 0; i < howMany; i++ ){
list.add(pickRandom(col1, " "));
list.add(pickRandom(col2, " "));
list.add(pickRandom(col3, newLine));
}
ByteBuffer[] buffers = new ByteBuffer[list.size()];
list.toArray(buffers);
return (buffers);
}
private static Random rand = new Random();
private static ByteBuffer pickRandom(String[] strings,String suffix) throws Exception{
String string = strings[rand.nextInt(strings.length)];
int total = string.length() + suffix.length();
ByteBuffer buffer = ByteBuffer.allocate(total);
buffer.put(string.getBytes("US-ASCII"));
buffer.put(suffix.getBytes("US-ASCII"));
buffer.flip();
return (buffer);
}
}
该程序执行过后可以看到控制台输出为:
Mindshare paradigms synergized to D:/work/blahblah.txt
而txt文本里面有了下边的内容:
Aggregate Cross-platform mindshare
Synergize best-of-bread schemas
Repurpose mission-critical infrastructures
Harness best-of-bread infomediaries
Enable ubiquitous infomediaries
Leverage integrated functionalities
Harness extensible infomediaries
Enable integrated mindshare
Facilitate mission-critical mindshare
Leverage extensible schemas
集中分散读写的方式为DMA设计中常用的,这里简单介绍一下DMA:
DMA的英文拼写是“Direct Memory Access”,汉语的意思就是直接内存访问,是一种不经过CPU而直接从内存存取数据的数据交换模式。PIO模式下硬盘和内存之间的数据传输是由CPU来控制的;而在DMA模式下,CPU只须向DMA控制器下达指令,让DMA控制器来处理数据的传送,数据传送完毕再把信息反馈给CPU,这样就很大程度上减轻了CPU资源占有率。DMA模式与PIO模式的区别就在于,DMA模式不过分依赖CPU,可以大大节省系统资源,二者在传输速度上的差异并不十分明显。DMA模式又可以分为Single-Word DMA(单字节DMA)和Multi-Word DMA(多字节DMA)两种,其中所能达到的最大传输速率也只有16.6MB/s。DMA 传送方式的优先级高于程序中断,两者的区别主要表现在对CPU的干扰程度不同。中断请求不但使CPU停下来,而且要CPU执行中断服务程序为中断请求服务,这个请求包括了对断点和现场的处理以及CPU与外设的传送,所以CPU付出了很多的代价;DMA请求仅仅使CPU暂停一下,不需要对断点和现场的处理,并且是由DMA控制外设与主存之间的数据传送,无需CPU的干预,DMA只是借用了一点CPU的时间而已。还有一个区别就是,CPU对这两个请求的响应时间不同,对中断请求一般都在执行完一条指令的时钟周期末尾响应,而对DMA的请求,由于考虑它得高效性,CPU在每条指令执行的各个阶段之中都可以让给DMA使用,是立即响应。DMA主要由硬件来实现,此时高速外设和内存之间进行数据交换不通过CPU的控制,而是利用系统总线。DMA方式是I/O系统与主机交换数据的主要方式之一,另外还有程序查询方式和中断方式。
[2]文件通道(FileChannel)
上边讨论了Java NIO提供了一种新型读写模型,本小节主要讨论常用的文件读写,如何使用Java NIO来进行文件读写,和Gather/Scatter两种管道一样,虽然FileChannel针对的是普通的文件读写,但是它的效率和集中/分散模式的的读写效率差不多高效,换句话说,它依然使用了一种比较规范的方式以字节为单位来进行文件读写。文件通道(FileChannel)在读写数据的时候主要使用了阻塞模式,它不能支持非阻塞模式的读写,而且FileChannel的对象是不能够直接实例化的,他的实例只能通过getChannel()从一个打开的文件对象上边读取(RandomAccessFile、FileInputStream、FileOutputStream),并且通过调用getChannel()方法返回一个Channel对象去连接同一个文件,也就是针对同一个文件进行读写操作。一般情况下,FileChannel尽可能使用本地IO服务,而FileChannel本身是抽象的,使用getChannel()返回的是实现了该类里面方法的子类,而这些实现大部分使用的已经不是Java代码,而是本地C代码。FileChannel的读写是线程安全的,当多个文件通道在操作同一个文件的时候很难引起一些读写问题,并且FileChannel可以支持多线程操作;和其他读写相关的类一样,FileChannel本身是针对JVM里面的一种抽象描述,所以该通道操作的文件仅仅只能在一个Java进程里面访问,而不能提供给其他的非Java进程来操作。
文件访问控制:
FileChannel通道类针对操作系统的一些文件读写本地代码是一对一的,该抽象类里面的每一个方法,在操作系统底层都有对应的指令集,有可能名称不一样,但是功能基本是一致的。FileChannel和Buffer有一个概念类似就是position,它记录了这个文件即将写入或者读取数据的游标位置,因为这样的关系,FileChannel可以使用内存映射类通过ByteBuffer的API来访问某些文件。
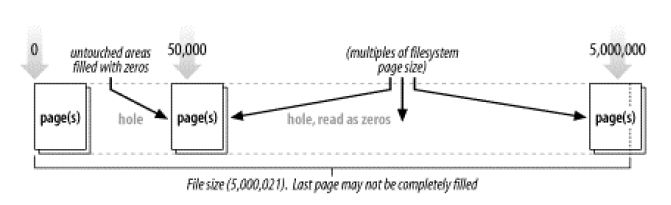
文件泄漏:
文件泄漏是指操作系统本身分配给文件的磁盘空间小于文件本身大小而造成的一种溢出,类似内存泄漏的概念。
——[$]提供一个文件泄漏的例子——
package org.susan.java.io;
import java.io.File;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class FileHole {
public static void main(String args[]) throws IOException{
File temp = File.createTempFile("holy", null);
RandomAccessFile file = new RandomAccessFile(temp,"rw");
FileChannel channel = file.getChannel();
ByteBuffer buffer = ByteBuffer.allocateDirect(100);
putData(0, buffer, channel);
putData(5000000, buffer, channel);
putData(50000, buffer, channel);
System.out.println("Wrote temp file '" + temp.getPath() + "',size = " + channel.size());
channel.close();
file.close();
}
private static void putData(int position,ByteBuffer buffer,FileChannel fileChannel) throws IOException{
String string = "*<-- location " + position;
buffer.clear();
buffer.put(string.getBytes("US-ASCII"));
buffer.flip();
fileChannel.position(position);
fileChannel.write(buffer);
}
}
该文件运行的过程可以知道:
如果文件是顺序读取,那么泄漏有可能直接发生,就使用0来填充但是并不会占磁盘空间,但是当一个进程读取该文件的时候,读到500021个字节的时候有可能数据全部是0,而且当你的数据越大的时候这种文件泄漏的情况可能更加严重。
关于文件锁:
文件锁的出现解决了很多Java应用程序和非Java程序之间共享文件数据的问题,在以前的JDK版本中,没有文件锁机制使得Java应用程序和其他非Java进程程序之间不能够针对同一个文件共享数据,有可能造成很多问题,JDK1.4里面有了FileChannel,它的锁机制使得文件能够针对很多非Java应用程序以及其他Java应用程序可见【可见的概念可以参考《Java内存模型》章节】。但是Java里面的文件锁机制主要是基于共享锁模型,在不支持共享锁模型的操作系统上,文件锁本身也起不了作用,JDK1.4使用文件通道读写方式可以向一些文件发送锁请求,但是和前边介绍的内存的锁一样的道理,等待响应过程也是编程过程中造成程序性能的主要原因之一。不同的操作系统、不同的文件系统本身支持不同的锁模型,使用Java的文件锁可以使得应用程序更好针对异构平台管理、操作这些锁模型来完成文件的读写操作,FileChannel的锁模型主要针对的是每一个文件,并不是每一个线程和每一个读写通道,也就是以文件为中心进行共享以及独占,也就是文件锁本身并不适合于同一个JVM的不同线程之间。
【*:文件锁主要和文件联系,并不是通道和线程,也就是使用文件锁的最终目的是和外联进程进行配合执行,而不是在同一个JVM的线程之间。】
这里看看FileChannel里面关于文件锁的几个方法(这里未列举抛出的异常列表):
public abstract FileLock lock(long position,long size,boolean shared)
获取此通道的文件给定区域上的锁定。在可以锁定该区域、已关闭此通道或者已中断调用线程(以先到者为准)之前,将阻塞此方法的调用。如果在此方法调用期间另一个线程关闭了此通道,则抛出 AsynchronousCloseException。如果在等待获取锁定的同时中断了调用线程,则将状态设置为中断并抛出 FileLockInterruptionException。如果调用此方法时已设置调用方的中断状态,则立即抛出该异常;不更改该线程的中断状态。由 position 和 size 参数所指定的区域无需包含在实际的底层文件中,甚至无需与文件重叠。锁定区域的大小是固定的;如果某个已锁定区域最初包含整个文件,并且文件因扩大而超出了该区域,则该锁定不覆盖此文件的新部分。如果期望文件大小扩大并且要求锁定整个文件,则应该锁定从零开始,到不小于期望最大文件大小的区域。零参数的 lock() 方法只是锁定大小为 Long.MAX_VALUE 的区域。某些操作系统不支持共享锁定,在这种情况下,自动将对共享锁定的请求转换为对独占锁定的请求。可通过调用所得锁定对象的 isShared 方法来测试新获取的锁定是共享的还是独占的。文件锁定是以整个 Java 虚拟机来保持的。但它们不适用于控制同一虚拟机内多个线程对文件的访问。
public abstract FileLock lock()
获取对此通道的文件的独占锁定,下边两句代码是等效的:
file.lock();
file.lock(0L,Long.MAX_VALUE,false);
public abstract FileLock tryLock(long position,long size,boolean shared)
图获取对此通道的文件给定区域的锁定。此方法不会阻塞。无论是否已成功地获得请求区域上的锁定,调用总是立即返回。如果由于另一个程序保持着一个重叠锁定而无法获取锁定,则此方法返回 null。如果由于任何其他原因而无法获取锁定,则抛出相应的异常。由 position 和 size 参数所指定的区域无需包含在实际的底层文件中,甚至无需与文件重叠。锁定区域的大小是固定的;如果某个已锁定区域最初包含整个文件,但文件因扩大而超出了该区域,则该锁定不覆盖此文件的新部分。如果期望文件大小扩大并且要求锁定整个文件,则应该锁定从零开始,到不小于期望最大文件大小为止的区域。零参数的 tryLock() 方法只是锁定大小为 Long.MAX_VALUE 的区域。某些操作系统不支持共享锁定,在这种情况下,自动将对共享锁定的请求转换为对独占锁定的请求。可通过调用所得锁定对象的 isShared 方法来测试新获取的锁定是共享的还是独占的。文件锁定以整个 Java 虚拟机来保持。但它们不适用于控制同一虚拟机内多个线程对文件的访问。
public abstract FileLock tryLock():(等价于:tryLock(0L, Long.MAX_VALUE, false))
——[$]提供一个文件锁例子——
package org.susan.java.io;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.IntBuffer;
import java.nio.channels.FileChannel;
import java.nio.channels.FileLock;
import java.util.Random;
public class LockTest {
private static final int SIZEOF_INT = 4;
private static final int INDEX_START = 0;
private static final int INDEX_COUNT = 10;
private static final int INDEX_SIZE = INDEX_COUNT * SIZEOF_INT;
private ByteBuffer buffer = ByteBuffer.allocate(INDEX_SIZE);
private IntBuffer indexBuffer = buffer.asIntBuffer();
private Random rand = new Random();
public static void main(String args[]) throws Exception {
boolean writer = false;
String filename;
if (args.length != 2) {
System.out.println("Usage: [ -r | -w ] filename");
return;
}
writer = args[0].equals("-w");
filename = args[1];
RandomAccessFile raf = new RandomAccessFile(filename, (writer) ? "rw": "r");
FileChannel fc = raf.getChannel();
LockTest lockTest = new LockTest();
if (writer) {
lockTest.doUpdates(fc);
} else {
lockTest.doQueries(fc);
}
}
void doQueries(FileChannel fc) throws Exception {
while (true) {
println("trying for shared lock...");
FileLock lock = fc.lock(INDEX_START, INDEX_SIZE, true);
int reps = rand.nextInt(60) + 20;
for (int i = 0; i < reps; i++) {
int n = rand.nextInt(INDEX_COUNT);
int position = INDEX_START + (n * SIZEOF_INT);
buffer.clear();
fc.read(buffer, position);
int value = indexBuffer.get(n);
println("Index entry " + n + "=" + value);
Thread.sleep(100);
}
lock.release();
println("<sleeping>");
Thread.sleep(rand.nextInt(3000) + 500);
}
}
void doUpdates(FileChannel fc) throws Exception {
while (true) {
println("trying for exclusive lock...");
FileLock lock = fc.lock(INDEX_START, INDEX_SIZE, false);
updateIndex(fc);
lock.release();
println("<sleeping>");
Thread.sleep(rand.nextInt(2000) + 500);
}
}
private int idxval = 1;
private void updateIndex(FileChannel fc) throws Exception {
indexBuffer.clear();
for (int i = 0; i < INDEX_COUNT; i++) {
idxval++;
println("Updating index " + i + "=" + idxval);
indexBuffer.put(idxval);
Thread.sleep(500);
}
buffer.clear();
fc.write(buffer, INDEX_START);
}
private int lastLineLen = 0;
private void println(String msg) {
System.out.println("/r");
System.out.println(msg);
for (int i = msg.length(); i < lastLineLen; i++) {
System.out.println(" ");
}
System.out.println("/r");
System.out.println();
lastLineLen = msg.length();
}
}
上边这段程序读者可以自己去琢磨,这里就不介绍文件通道FileChannel里面的内容了。
[3]内存映射文件(Memory-Mapped Files)
FileChannel通道提供了一个方法map(),它在打开的文件和ByteBuffer字节缓冲区之间直接开启了一个虚拟内存映射,当通道调用map()的时候可以直接通过虚拟内存空间和物理内存空间使用MappedByteBuffer类以映射方式进行数据读写。MappedByteBuffer对象可以从map()方法返回,类似基于内存的缓冲区,但实际上它的数据元素却是直接存储在磁盘文件上的。通过调用get()方法可以直接从文件中读取数据,即使这个文件被其他进程修改了,这些数据也可以映射出该文件的实际内容。通过内存映射机制来操作文件的时候比起普通的文件读写方式更加高效,但是这种方式需要显示调用,学过操作系统的人都明白操作系统的虚拟内存可以自动缓存内存页面,这些页面会由系统内存进行缓存而不去消耗JVM的内存堆空间。
内存映射文件提供了三种模式:
FileChannel.MapMode.READ_ONLY
FileChannel.MapMode.READ_WRITE
FileChannel.MapMode.PRIVATE
内存映射文件能让你创建和修改那些大到无法读入内存的文件。有了内存映射文件,你就可以认为文件已经全部读进了内存,然后把它当成一个非常大的数组来访问了。这种解决思路能大大简化修改文件的代码。注意,你必须指明,它是从文件的哪个位置开始映射的,映射的范围又有多大;也就是说,它还可以映射一个大文件的某个小片断。文件的访问好像只是一瞬间的事,这是因为,真正调入内存的只是其中的一小部分,其余部分则被放在交换文件上。这样你就可以很方便地修改超大型的文件了(最大可以到2 GB)。
——[$]三种映射模式的使用——
package org.susan.java.io;
import java.io.File;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
public class MapFiles {
public static void main(String[] argv) throws Exception {
// 创建一个临时文件链接和管道
File tempFile = File.createTempFile("mmaptest", null);
RandomAccessFile file = new RandomAccessFile(tempFile, "rw");
FileChannel channel = file.getChannel();
ByteBuffer temp = ByteBuffer.allocate(100);
// 从位置0存放一些内容到文件
temp.put("This is the file content".getBytes());
temp.flip();
channel.write(temp, 0);
temp.clear();
temp.put("This is more file content".getBytes());
temp.flip();
channel.write(temp, 8192);
//针对同一个文件创建三种映射文件模式
MappedByteBuffer ro = channel.map(FileChannel.MapMode.READ_ONLY, 0,channel.size());
MappedByteBuffer rw = channel.map(FileChannel.MapMode.READ_WRITE, 0,channel.size());
MappedByteBuffer cow = channel.map(FileChannel.MapMode.PRIVATE, 0,channel.size());
System.out.println("Begin");
showBuffers(ro, rw, cow);
// 修改READ模式拷贝位置
cow.position(8);
cow.put("COW".getBytes());
System.out.println("Change to COW buffer");
showBuffers(ro, rw, cow);
// 修改READ/WRITE模式拷贝位置
rw.position(9);
rw.put(" R/W ".getBytes());
rw.position(8194);
rw.put(" R/W ".getBytes());
rw.force();
System.out.println("Change to R/W buffer");
showBuffers(ro, rw, cow);
temp.clear();
temp.put("Channel write ".getBytes());
temp.flip();
channel.write(temp, 0);
temp.rewind();
channel.write(temp, 8202);
System.out.println("Write on channel");
showBuffers(ro, rw, cow);
// 再次修改
cow.position(8207);
cow.put(" COW2 ".getBytes());
System.out.println("Second change to COW buffer");
showBuffers(ro, rw, cow);
rw.position(0);
rw.put(" R/W2 ".getBytes());
rw.position(8210);
rw.put(" R/W2 ".getBytes());
rw.force();
System.out.println("Second change to R/W buffer");
showBuffers(ro, rw, cow);
channel.close();
file.close();
tempFile.delete();
}
//显示目前的缓冲区内容
public static void showBuffers(ByteBuffer ro, ByteBuffer rw, ByteBuffer cow)
throws Exception {
dumpBuffer("R/O", ro);
dumpBuffer("R/W", rw);
dumpBuffer("COW", cow);
System.out.println("");
}
public static void dumpBuffer(String prefix, ByteBuffer buffer)
throws Exception {
System.out.print(prefix + ": '");
int nulls = 0;
int limit = buffer.limit();
for (int i = 0; i < limit; i++) {
char c = (char) buffer.get(i);
if (c == '/u0000') {
nulls++;
continue;
}
if (nulls != 0) {
System.out.print("|[" + nulls + " nulls]|");
nulls = 0;
}
System.out.print(c);
}
System.out.println("'");
}
}
上边是三种方式的使用方法代码演示,这里不列举输出了。
[4]套接字通道(Socket Channel):
新的Socket Channel可以在非阻塞模式下运行而且是可选择的,这两个功能使得大型应用程序的可伸缩性和松耦合程度有所增加,比如Web服务器和中间件,这种做法就没有必要使得一个线程仅仅服务于某一个连接。使用NIO类,一个或者多个线程可以同时支持多个激活的网络连接并且不会影响系统运行的性能。Java NIO处理这一部分内容主要有三个类:
DatagramChannel、SocketChannel、ServerSocketChannel,它们都位于java.nio.channels.spi包下边,也就是说这些通道类有可能在读取过程使用Selector类进行网络通道的预选择,而且这三个类中比较特殊的是ServerSocketChannel类,因为这个类不像其他两个类一样具有read和write方法,它仅仅是为了监听连接以及创建一个新的SocketChannel对象,它自己本身并不传输任何数据,也可以说它属于管道监听器,而不是一个标准的管道。【先区分一个概念:套接字端口和套接字通道,一个通道是一个IO服务,提供了一系列的方法用来完成数据的读写以及传输,而区别于套接字端口的是,套接字端口是实现了协议的一些API用来返回给Channel对象对应的响应。】非阻塞I/O(NIO)有效解决了多线程服务器存在的线程开销问题,但在使用上略显得复杂一些。在NIO中使用多线程,主要目的已不是为了应对每个客户端请求而分配独立的服务线程,而是通过多线程充分使用用多个CPU的处理能力和处理中的等待时间,达到提高服务能力的目的。
这里介绍一下三个主要的类:
public abstract class SocketChannel extends AbstractSelectableChannel implements ByteChannel,ScatteringByteChannel,GatheringByteChannel
针对面向流的连接套接字的可选择通道。套接字通道不是连接网络套接字的完整抽象。必须通过调用 socket 方法所获得的关联 Socket 对象来完成对套接字选项的绑定、关闭和操作。不可能为任意的已有套接字创建通道,也不可能指定与套接字通道关联的套接字所使用的 SocketImpl 对象。通过调用此类的某个 open 方法创建套接字通道。新创建的套接字通道已打开,但尚未连接。试图在未连接的通道上调用 I/O 操作将导致抛出 NotYetConnectedException。可通过调用套接字通道的 connect 方法连接该通道;一旦连接后,关闭套接字通道之前它会一直保持已连接状态。可通过调用套接字通道的 isConnected 方法来确定套接字通道是否已连接。套接字通道支持非阻塞连接:可创建一个套接字通道,并且通过 connect 方法可以发起到远程套接字的连接,之后通过 finishConnect 方法完成该连接。可通过调用 isConnectionPending 方法来确定是否正在进行连接操作。可单独地关闭 套接字通道的输入端和输出端,而无需实际关闭该通道。调用关联套接字对象的 shutdownInput 方法来关闭某个通道的输入端将导致该通道上的后续读取操作返回 -1(指示流的末尾)。调用关联套接字对象的 shutdownOutput 方法来关闭通道的输出端将导致该通道上的后续写入操作抛出 ClosedChannelException。套接字通道支持异步关闭,这与 Channel 类中所指定的异步 close 操作类似。如果一个线程关闭了某个套接字的输入端,而同时另一个线程被阻塞在该套接字通道上的读取操作中,那么处于阻塞线程中的读取操作将完成,而不读取任何字节且返回 -1。如果一个线程关闭了某个套接字的输出端,而同时另一个线程被阻塞在该套接字通道上的写入操作中,那么阻塞线程将收到 AsynchronousCloseException。多个并发线程可安全地使用套接字通道。尽管在任意给定时刻最多只能有一个线程进行读取和写入操作,但数据报通道支持并发的读写。connect 和 finishConnect 方法是相互同步的,如果正在调用其中某个方法的同时试图发起读取或写入操作,则在该调用完成之前该操作被阻塞。
public abstract class ServerSocketChannel extends AbstractSelectableChannel
针对面向流的侦听套接字的可选择通道。 服务器套接字通道不是侦听网络套接字的完整抽象。必须通过调用 socket 方法所获得的关联 ServerSocket 对象来完成对套接字选项的绑定和操作。不可能为任意的已有服务器套接字创建通道,也不可能指定与服务器套接字通道关联的服务器套接字所使用的 SocketImpl 对象。 通过调用此类的 open 方法创建服务器套接字通道。新创建的服务器套接字通道已打开,但尚未绑定。试图调用未绑定的服务器套接字通道的 accept 方法会导致抛出 NotYetBoundException。可通过调用相关服务器套接字的某个 bind 方法来绑定服务器套接字通道。 多个并发线程可安全地使用服务器套接字通道。
public abstract class DatagramChannel extends AbstractSelectableChannel implements ByteChannel, ScatteringByteChannel, GatheringByteChannel
针对面向数据报套接字的可选择通道。 数据报通道不是网络数据报套接字的完整抽象。必须通过调用 socket 所获得的关联 DatagramSocket 对象来完成套接字选项的绑定和操作。不可能为任意的已有数据报套接字创建通道,也不可能指定与数据报通道关联的数据报套接字所使用的 DatagramSocketImpl 对象。通过调用此类的 open 方法创建数据报通道。新创建的数据报通道已打开,但尚未连接。为了使用 send 和 receive 方法,无需连接数据报通道。但是如果为了避免作为每次发送和接收操作的一部分而执行的安全检查开销,也可以通过调用数据报通道的 connect 方法来建立数据报通道连接。为了使用 read 和 write 方法,必须建立数据报通道连接,因为这些方法不接受或返回套接字地址。 一旦建立了连接,在断开数据报通道的连接或将其关闭之前,该数据报通道保持连接状态。可通过调用数据报通道的 isConnected 方法来确定它是否已连接。多个并发线程可安全地使用数据报通道。尽管在任意给定时刻最多只能有一个线程进行读取和写入操作,但数据报通道支持并发的读写。
ServerSocketChannel类:
该类是基于通道监听器,它和java.net.ServerSocket做了同样的事情,但是添加了通道的语义,包括在非阻塞模式下的一些操作。ServerSocketChannel类的对象的创建使用的是静态工厂方法open(),有可能直接和一个未绑定的ServerSocket对象直接联系,使用ServerSocket对象的socket()方法可以返回一个ServerSocketChannel对象。ServerSocketChannel对象并不提供bind()方法,但是提供了accept()方法,这个方法将会直接返回SocketChannel类的对象,它适用于非阻塞模式;如果在非阻塞模式下调用accept()方法,如果没有任何连接那么accept()方法会立即返回null。
——[$]提供一个非阻塞模式的accept()方法例子——
package org.susan.java.io;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
public class ChannelAccept {
public static final String GREETING = "Hello I must be going./n";
public static void main(String[] argv) throws Exception {
int port = 1234;
if (argv.length > 0) {
port = Integer.parseInt(argv[0]);
}
ByteBuffer buffer = ByteBuffer.wrap(GREETING.getBytes());
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.socket().bind(new InetSocketAddress(port));
ssc.configureBlocking(false);
while (true) {
System.out.println("Waiting for connections");
SocketChannel sc = ssc.accept();
if (sc == null) {
Thread.sleep(2000);
} else {
System.out.println("Incoming connection from: " + sc.socket().getRemoteSocketAddress());
buffer.rewind();
sc.write(buffer);
sc.close();
}
}
}
}
这段代码的输出为:
Waiting for connections
Incoming connection from: /127.0.0.1:59377
Waiting for connections
注意中间一行,中间一行代码是用浏览器直接输入:http://localhost:1234的时候控制台打印出来的,而网页显示内容就是GREETING字符串的内容。
SocketChannel类:
该类扮演了Socket通道中的客户端,可以初始化一个连接到请求监听服务器。而每一个SocketChannel对象都是使用java.net.Socket对象创建的,静态方法open()创建了一个新的SocketChannel对象,而SocketChannel对象调用socket()方法可以返回一个Socket对象,反之调用Socket的getChannel()方法可以返回原来的SocketChannel对象,当Socket对象直接创建并且和SocketChannel对象没有任何联系的时候,它的getChannel()方法会直接返回null。当该连接通道建立好了过后,可以使用connect()方法完成真正的连接过程,一旦某个套接字通道连接创建成功过后,它就会一直保持连接状态直到关闭为止。
使用SocketChannel的关闭连接的时候使用的是finishConnect()方法,在非阻塞模式调用了这个方法过后:
- connect()方法如果没有调用的时候,直接抛出异常:NoConnectionException
- 当连接打开了但是还没有完成的时候,什么都不会发生,finishConnect()方法会直接返回false
- SocketChannel类的对象调用了connect()方法过后可以直接从阻塞模式切换到非阻塞模式,如果有必要的调用线程会产生阻塞直到连接完成,这时finishConnect()方法返回true
- 当连接启用从connect()直到finishConnect(),SocketChannel对象的内部状态已经更新到已连接,这种时候finishConnect()方法也会返回true,而且SocketChannel对象接着继续进行数据传送
- 当连接启用的时候,什么事情都不发生,该方法直接返回true
——[$]使用SocketChannel在非阻塞模式下的异步调用——
package org.susan.java.io;
import java.net.InetSocketAddress;
import java.nio.channels.SocketChannel;
public class ConnectAsync {
public static void main(String[] argv) throws Exception {
String host = "localhost";
int port = 80;
if (argv.length == 2) {
host = argv[0];
port = Integer.parseInt(argv[1]);
}
InetSocketAddress addr = new InetSocketAddress(host, port);
SocketChannel sc = SocketChannel.open();
sc.configureBlocking(false);
System.out.println("initiating connection");
sc.connect(addr);
while (!sc.finishConnect()) {
doSomethingUseful();
}
System.out.println("connection established");
sc.close();
}
private static void doSomethingUseful() {
System.out.println("doing something useless");
}
}
该段代码输出为:
initiating connection
connection established
DatagramChannel类:
和SocketChannel不一样的是:
SocketChannel操作是基于TCP/IP协议,而DatagramChannel是基于UDP/IP协议,所以这里仅仅讲解DatagramChannel区别于SocketChannel的方法,其他方法内容都大同小异,该类这里就不提供例子了。
主要区分的方法:
public abstract int send(ByteBuffer src,SocketAddress target):
通过此通道发送数据报。如果此通道处于非阻塞模式并且底层输出缓冲区中没有足够的空间,或者如果此通道处于阻塞模式并且缓冲区中有足够的空间,则将给定缓冲区中的剩余字节以单个数据报的形式传送到给定的目标地址。从字节缓冲区传输数据报如同通过正规的 write 操作一样。此方法执行的安全检查与 DatagramSocket 类的 send 方法执行的安全检查完全相同。也就是说,如果该套接字未连接到指定的远程地址,并且已安装了安全管理器,则对于每个发送的数据报,此方法都会验证安全管理器的 checkConnect 方法是否允许使用该数据报的目标地址和端口号。避免此项安全检查开销的方法是首先通过 connect 方法连接该套接字。可在任意时间调用此方法。但是如果另一个线程已经在此通道上发起了一个写入操作,则在该操作完成前此方法的调用被阻塞。
使用原因:
- 当应用程序需能够承受数据丢失的时候
- 应用程序想通知某些客户端而且不需要知道对方是否收到数据包的时候
- 吞吐率比稳定性重要的时候
- 需要进行多播或者广播方式发送数据出去
- 基于包比基于流好的时候【抱歉,这点我不是很理解,所以留下英文原文:The packet metaphor fits the task at hand better than the stream metaphor.】
这里提供两个例子,一个是客户端、一个是服务端:
——[$]服务端代码——
package org.susan.java.io;
import java.net.InetSocketAddress;
import java.net.SocketAddress;
import java.net.SocketException;
import java.nio.ByteBuffer;
import java.nio.ByteOrder;
import java.nio.channels.DatagramChannel;
public class TimeServer {
private static final int DEFAULT_TIME_PORT = 37;
private static final long DIFF_1900 = 2208988800L;
protected DatagramChannel channel;
public TimeServer(int port) throws Exception {
this.channel = DatagramChannel.open();
this.channel.socket().bind(new InetSocketAddress(port));
System.out.println("Listening on port " + port + " for time requests");
}
public void listen() throws Exception {
ByteBuffer longBuffer = ByteBuffer.allocate(8);
longBuffer.order(ByteOrder.BIG_ENDIAN);
longBuffer.putLong(0, 0);
longBuffer.position(4);
ByteBuffer buffer = longBuffer.slice();
while (true) {
buffer.clear();
SocketAddress sa = this.channel.receive(buffer);
if (sa == null) {
continue;
}
System.out.println("Time request from " + sa);
buffer.clear();
longBuffer.putLong(0, (System.currentTimeMillis() / 1000) + DIFF_1900);
this.channel.send(buffer, sa);
}
}
public static void main(String[] argv) throws Exception {
int port = DEFAULT_TIME_PORT;
if (argv.length > 0) {
port = Integer.parseInt(argv[0]);
}
try {
TimeServer server = new TimeServer(port);
server.listen();
} catch (SocketException e) {
System.out.println("Can't bind to port " + port + ", try a different one");
}
}
}
——[$]客户端代码——
package org.susan.java.io;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.ByteOrder;
import java.nio.channels.DatagramChannel;
import java.util.Date;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
public class TimeClient {
private static final int DEFAULT_TIME_PORT = 37;
private static final long DIFF_1900 = 2208988800L;
protected int port = DEFAULT_TIME_PORT;
protected List remoteHosts;
protected DatagramChannel channel;
public TimeClient(String[] argv) throws Exception {
if (argv.length == 0) {
throw new Exception("Usage: [ -p port ] host ...");
}
parseArgs(argv);
this.channel = DatagramChannel.open();
}
protected InetSocketAddress receivePacket(DatagramChannel channel,
ByteBuffer buffer) throws Exception {
buffer.clear();
return ((InetSocketAddress) channel.receive(buffer));
}
protected void sendRequests() throws Exception {
ByteBuffer buffer = ByteBuffer.allocate(1);
Iterator it = remoteHosts.iterator();
while (it.hasNext()) {
InetSocketAddress sa = (InetSocketAddress) it.next();
System.out.println("Requesting time from " + sa.getHostName() + ":" + sa.getPort());
buffer.clear().flip();
channel.send(buffer, sa);
}
}
public void getReplies() throws Exception {
ByteBuffer longBuffer = ByteBuffer.allocate(8);
longBuffer.order(ByteOrder.BIG_ENDIAN);
longBuffer.putLong(0, 0);
longBuffer.position(4);
ByteBuffer buffer = longBuffer.slice();
int expect = remoteHosts.size();
int replies = 0;
System.out.println("");
System.out.println("Waiting for replies...");
while (true) {
InetSocketAddress sa;
sa = receivePacket(channel, buffer);
buffer.flip();
replies++;
printTime(longBuffer.getLong(0), sa);
if (replies == expect) {
System.out.println("All packets answered");
break;
}
System.out.println("Received " + replies + " of " + expect + " replies");
}
}
protected void printTime(long remote1900, InetSocketAddress sa) {
long local = System.currentTimeMillis() / 1000;
long remote = remote1900 - DIFF_1900;
Date remoteDate = new Date(remote * 1000);
Date localDate = new Date(local * 1000);
long skew = remote - local;
System.out.println("Reply from " + sa.getHostName() + ":" + sa.getPort());
System.out.println(" there: " + remoteDate);
System.out.println(" here: " + localDate);
System.out.print(" skew: ");
if (skew == 0) {
System.out.println("none");
} else if (skew > 0) {
System.out.println(skew + " seconds ahead");
} else {
System.out.println((-skew) + " seconds behind");
}
}
protected void parseArgs(String[] argv) {
remoteHosts = new LinkedList();
for (int i = 0; i < argv.length; i++) {
String arg = argv[i];
if (arg.equals("-p")) {
i++;
this.port = Integer.parseInt(argv[i]);
continue;
}
InetSocketAddress sa = new InetSocketAddress(arg, port);
if (sa.getAddress() == null) {
System.out.println("Cannot resolve address: " + arg);
continue;
}
remoteHosts.add(sa);
}
}
public static void main(String[] argv) throws Exception {
TimeClient client = new TimeClient(argv);
client.sendRequests();
client.getReplies();
}
}
上边代码就不详细讲解了,运行的时候需要先运行服务端,然后再运行客户端,客户端记得在参数列表中添加-p port来运行。还有一类通道读写这里不做介绍,就是基于Pipe的,因为这方面的类我很少使用,所以怕总结出来的和翻译出来的内容会误导读者,如果有兴趣的读者了解这部分内容可以来Email补充该章节内容。
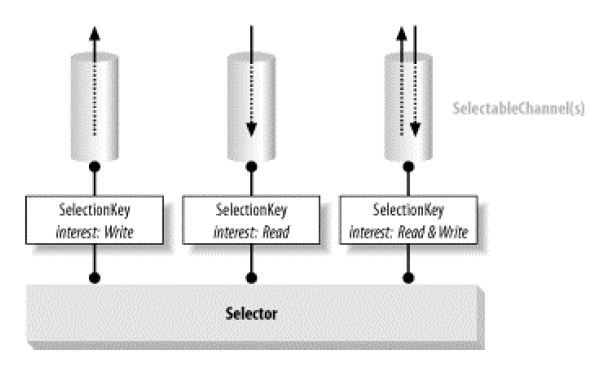
【*:和Socket Channel有关的在Java NIO里面还有一个关键的概念是Selector,这个概念在最后讲解,通过上边部分的讲解,已经基本将Java NIO里面的内容详细解说了一边,可能有些地方有遗漏而且总结得比较粗略,所以本章节所有标题上都加上了草案,希望读者理解。】
到此针对通道做一个简单的小节:
- 通道读取支持分散集中的机制进行高效读写数据
- 文件通道是常用的方式,主要理解文件锁、和操作系统本地代码的相互关系、以及文件的访问控制
- 内存映射文件的理解需深入
- 基于网络套接字的三个Channel类的理解