【Coursera-ML-Notes】线性回归(下)
模型表示
多变量的线性回归也叫做“多元线性回归”。首先还是先明确几个符号的含义。
- \(x{^{(i)}_j}\):第i个训练样本的第j个特征,比如面积,楼层,客厅数
- \(x^{(i)}\):第i个训练样本的输入
- \(m\):训练样本的数量
- \(n\):特征的数量
多元线性模型的假设函数的形式如下:
\[
h_θ(x)=θ_0+θ_1x_1+θ_2x_2+θ_3x_3+...+θ_nx_n
\]
对应的\(x_1\)是房子的面积,\(x_2\)是房子的层数,...
用矩阵的形式来表示假设函数可以表示为:

这里让每个样本的第一个特征\(x{^{(i)}_0}\)都等于1。
梯度下降
和一元模型一样,我们只需要将参数收敛的程序做\(n\)次就可以了。
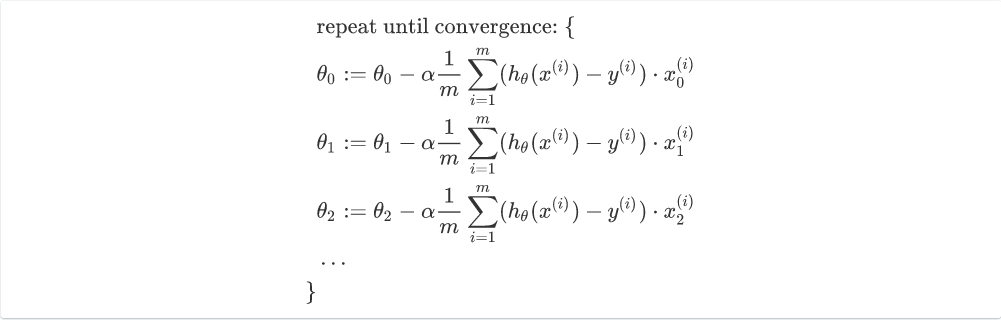
\[
θ=θ-α\frac{1}{m}(X^T(X\cdotθ-y))
\]
加速梯度下降
有两种方法可以帮助我们加速梯度下降,分别是特征缩放和均值归一化。
特征缩放
当特征保持在差不多相同的范围时,梯度下降的速度会快一些。
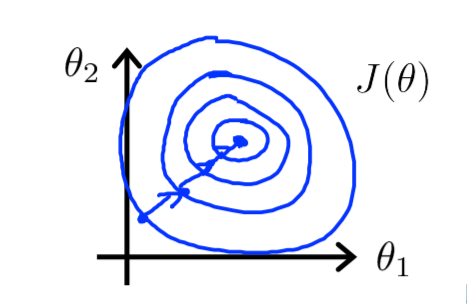
然而实际问题中可能就不这么完美,例如\(x_1\)的范围是0-2000,\(x_2\)的范围是0-5,得到的轮廓图是细长的同心椭圆,收敛所需要的迭代次数因此更多。
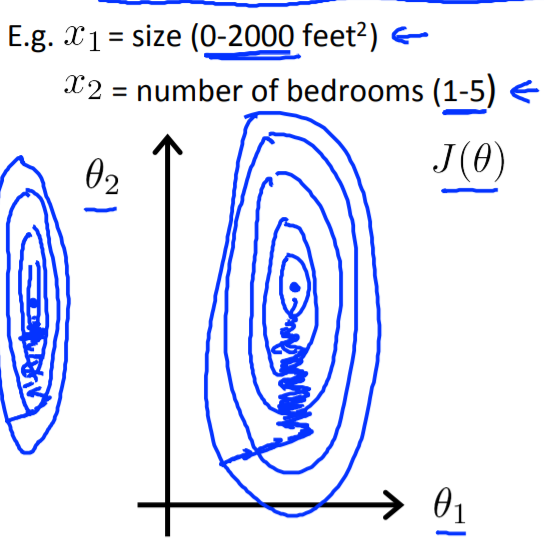
现在通过特征缩放的方法让每一个特征在相同的尺度范围内,让特征除以特征的范围(max-min)。
\[
x_1=\frac{size}{2000},x_2=\frac{number-of-bedrooms}{5}
\]
这样\(x_1,x_2\)的范围都在0-1之间。
均值归一化
均值归一化先减去该特征的平均值\(u_i\),在除以标准差\(s_i\)或是range(max-min)。
\[
x_i:=\frac{x_i-u_i}{s_i}
\]
例如,\(x_i\)代表房价在100到2000之间,平均值为1000,那么
\[
x_i:=\frac{x_i-1000}{1900}
\]
多项式回归
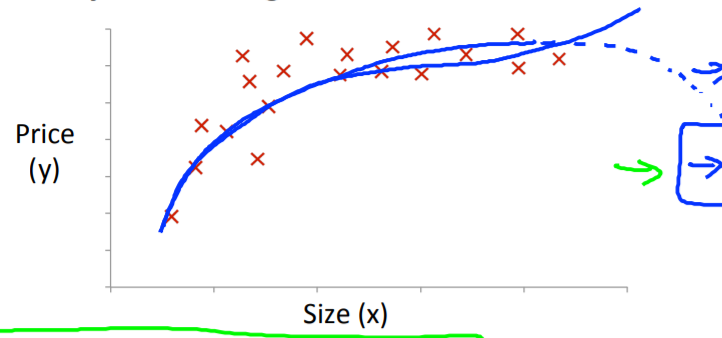
当输入数据的分布是这个样子的,直线的拟合程度是不高的。
可以考虑以一元二次函数来拟合,
\[
h_θ(x)=θ_0+θ_1x_1+θ_2x_2^{2}
\]
但是二次函数随着面积增大后面会下降,这与显示不符,进一步考虑三次函数来拟合
\[
h_θ(x)=θ_0+θ_1x_1+θ_2x_2^{2}+θ_3x_3^3
\]
三次函数会带来巨大的特征范围,这是特征缩放将变得十分重要。因此可以进一步考虑将三次替换为平方根
\[
h_θ(x)=θ_0+θ_1x_1+θ_2x_2^{2}+θ_3\sqrt x_3
\]
这就是多项式回归。
正规方程
在梯度下降中,我们通过调节学习率\(\alpha\),迭代的算法来求解使得\(J(θ)\)最优的参数解。正规方程的方法不涉及到调参,而是一步直接求出参数\(θ\)。
\[
θ=(X^TX)^{-1}X^Ty
\]
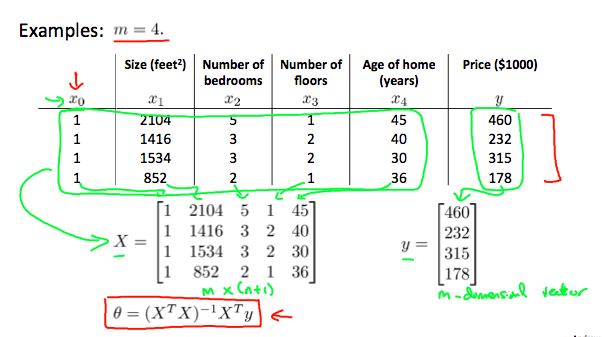
与梯度下降的对比
| 梯度下降 | 正规方程 |
|---|---|
| 需要调节\(\alpha\) | 不需要调节\(\alpha\) |
| 需要多次迭代 | 一次求出\(θ\) |
| 在特征\(n\)很大时也能很好工作 | \(n\)很大时,在求解\((X^TX)\)时时间复杂度很大 |
【Coursera-ML-Notes】线性回归(下)的更多相关文章
- Coursera ML笔记 - 神经网络(Representation)
前言 机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,涵盖线性回归.逻辑回归.Softmax回归.神经网络和SVM等等,主要学习资料来自Standford Andrew N ...
- (转载)[机器学习] Coursera ML笔记 - 监督学习(Supervised Learning) - Representation
[机器学习] Coursera ML笔记 - 监督学习(Supervised Learning) - Representation http://blog.csdn.net/walilk/articl ...
- [机器学习] Coursera ML笔记 - 逻辑回归(Logistic Regression)
引言 机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,涵盖线性回归.逻辑回归.Softmax回归.神经网络和SVM等等.主要学习资料来自Standford Andrew N ...
- 如何应用ML的建议-下
正则化与过拟合(highvariance)和欠拟合(highbias)的关系-部分(五) ML的诊断方法-部分(六) 如何采取下一步-部分(七) 部分(五) 从图中可以看出,正则化项可以用来影响模型函 ...
- ml的线性回归应用(python语言)
线性回归的模型是:y=theta0*x+theta1 其中theta0,theta1是我们希望得到的系数和截距. 下面是代码实例: 1. 用自定义数据来看看格式: # -*- coding:utf ...
- Linux Notes:Linux下的远程登录协议及软件
常见的远程登录协议 1.RDP(remote desktopp protocol)协议,windows远程桌面协议 2.telnet CLI 界面下远程管理,几乎所有的操作系统都有,数据明文传输,不安 ...
- ML:多变量线性回归(Linear Regression with Multiple Variables)
引入额外标记 xj(i) 第i个训练样本的第j个特征 x(i) 第i个训练样本对应的列向量(column vector) m 训练样本的数量 n 样本特征的数量 假设函数(hypothesis fun ...
- JavaScript机器学习之线性回归
译者按: AI时代,不会机器学习的JavaScript开发者不是好的前端工程师. 原文: Machine Learning with JavaScript : Part 1 译者: Fundebug ...
- 如何应用ML的建议-上
本博资料来自andrew ng的13年的ML视频中10_X._Advice_for_Applying_Machine_Learning. 遇到问题-部分(一) 错误统计-部分(二) 正确的选取数据集- ...
- 机器学习实验报告:利用3层神经网络对CIFAR-10图像数据库进行分类
PS:这是6月份时的一个结课项目,当时的想法就是把之前在Coursera ML课上实现过的对手写数字识别的方法迁移过来,但是最后的效果不太好… 2014年 6 月 一.实验概述 实验采用的是CIFAR ...
随机推荐
- Knowledge Point 20180303 对比编译器、解释器与Javac编译原理
编译器与Javac编译原理 在前文我们知道了Java是一种编译语言和解释语言,它的源代码经过编译器Javac编译为能够被JVM识别的二进制语言,然后JVM将其解释为能够被平台识别的机器语言.那么什么是 ...
- js中两个日期大小比较,获取当前日期,日期加减一天
一.两个日期大小比较 1.日期参数格式:yyyy-mm-dd // a: 日期a, b: 日期b, flag: 返回的结果 function duibi(a, b,flag) { var arr = ...
- C# Oracle批量插入数据进度条制作
前言 由于项目需求,需要将Excel中的数据进过一定转换导入仅Oracle数据库中.考虑到当Excel数据量较大时,循环Insert语句效率太低,故采用批量插入的方法.在插入操作运行时,会造成系统短暂 ...
- MySQL必知必会 读书笔记一:简介
了解数据库 数据库(database) 数据库(database) 保存有组织的数据的容器(通常是一个文 件或一组文件). 数据库软件应称为DBMS(数据库管理系统).数据库是通过DBMS创建和操纵的 ...
- JavaScript中Array的正确使用方式
在 JavaScript 中正确使用地使用 Array 的方法如下: 用 Array.includes 代替 Array.indexOf “如果你要在数组中查找元素,请使用 Array.indexOf ...
- 初识Java——第一章 初识Java
1. 计算机程序: 为了让计算机执行某些操作或解决某个问题而编写的一系列有序指令的集合. 2. JAVA相关的技术: 1).安装和运行在本机上的桌面程序 2).通过浏览器访问的面向 ...
- 在vue中如何实现购物车checkbox的三级联动
最近用vue写一个电商项目,自然就少不了要写一个购物车的相关页面,功能完整的购物车的checkbox应该是三级联动的,1级checkbox是选中购物车中所有的商品,2级checkbox是选中某个店铺下 ...
- form表单的一个页面多个上传按钮实例
/* * 图片上传 */ @RequestMapping("/uploadFile") @ResponseBody public String uploadFile(@Reques ...
- react组件间传值详解
一.父子组件间传值 <1>父传子 父组件:
- Asp.Net Core使用Log4Net优化日志【项目开源】
我在前一篇文章中介绍了一种使用Log4Net的方法,但是那种方法打出来的日志不是很直观 然后我前不久阅读了一篇非常不错的博客:https://www.cnblogs.com/guolianyu/p/9 ...