《Applying Deep Learning to Answer Selection: A Study And an Open Task》文章理解小结
本篇论文是2015年的IBM watson团队的。
论文地址:
这是一篇关于QA问题的一篇论文:
相关论文讲解1、https://www.jianshu.com/p/48024e9f7bb22、http://www.52nlp.cn/qa%E9%97%AE%E7%AD%94%E7%B3%BB%E7%BB%9F%E4%B8%AD%E7%9A%84%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%8A%80%E6%9C%AF%E5%AE%9E%E7%8E%B0 文章代码:https://github.com/white127/insuranceQA-cnn-lstm
看完第一篇的总结:
(1)写论文的过程中:
- 摘要部分主要分为三点:
(1)将深度学习框架应用到了QA问题上
(2)构建并发布了一个新的QA语料并在保险领域引入了一个新的任务
(3)实验证明在测试集上top-1的准确率达到了65.3%
- Introduction:
(1)背景(首先介绍主题是什么,自己实验的定义):介绍了目前的主流的人工对话系统,引出主要任务是进行答案选择和匹配。并定义自己实验的QA:给定问题q和一个答案候选池{a1....as},从中找出最佳答案ak(1<=k<=s),如果ak在q的正确答案集中(q不止一个正确答案),则认为正确,否则认为错误。可以看做一个2分类问题。匹配度最高的为最佳匹配答案。
(2) 本论文工作的初步介绍
答案候选池的构建:可以通过搜索引擎(Google或者信息检索软件Apache Lucence)
介绍本文构建的语料库(来源、规模):所有的问题和答案对都来自保险领域,并在发布的语料库1上创建了开放任务,研究人员都可以使用。其次语料库分为训练集、开发集、test1和test2.在表一中给出了数据估计。并说明是第一次发布的保险领域QA任务。
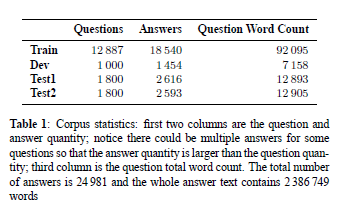
答案池的构建过程:为语料中的开发集、test1和test2中的每个问题都制定一个答案候选池。语料中共有24981个唯一答案。如果使用整个答案集作为候选池,每个问题都要和答案集里的所有答案进行比较,比较耗时。故将答案池大小设为500,将真正的答案放入答案池中,再从答案空间中随机抽取错区答案(就是负采样),直至达到500。
(3)论文结构
- Model Description:论文的主体结构(基线系统,剩下的就是自己所要用的系统,损失函数,所有涉及到的模型结构以及图形)
所有不同学习框架的主要思想是相同的:学习给定问题和其候选答案的向量表示,并使用相似性指标去衡量他的匹配程度。
两个基线系统:bag-of-words 和IR中主流的WD(权重依赖)模型。
基于CNN的系统:采用CNN三大优点稀疏交互(过程中的输入输出非全连接)、参数共享(卷积核参数共享)和等变表示(池化)。
训练和损失函数:训练过程最小化ranking loss。具体做法是: 训练模型时每个样本包括问题Q,正确回答A+和错误回答A-。分别计算余弦距离cos(Q,A+)与cos(Q,A-)。当满足cos(Q,A+)- cos(Q,A-) < m 时,m为一阈值,说明模型不能够将A+ 答案排在足够靠前,那么进行权重更新。如果cos(Q,A+)- cos(Q,A-) >= m,不需要更新模型,更换A-回答,直到cos(Q,A+)- cos(Q,A-) < m。
为了减少运算时间,需要设置最大重选A-次数,论文中设置为50。
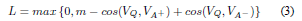
模型结构设置:共6种模型 结构1为Q和A分别训练自己的隐藏层、CNN层、Pooling层和最后的非线性映射,这里的激活函数选择是tanh。结构2为在隐层和CNN层时Q和A共同训练,之后再分别进行pooling、非线性映射。结构3是在结构2的基础上,最后又分别加入了一层隐藏层。结构4则是将最后一层的隐层变为二者共同层。结构5则为在结构2的CNN后面又加入了一层CNN层。结构6为在5的基础上,两层CNN的输出共同作为后面pooling层的输入
从实验结果表Table2中可以看出:结构1将问题和答案分别进行学习表示,效果比较差,并且还会同时学习双倍的参数,时间长效率低速度慢。结构2可以看出随着CNN卷积核数量的增多,效果越来越好,当达到卷积核数量为4000时,效果最佳。此外对结构2采用skip-bigram(结构2中在进行CNN卷积时,作者还使用skip-gram的方式,即当前词并不与相邻词作为整体与卷积核进行卷积,而是与再下一个词,把中间的一个词跳过,所以被称为skip-gram。)。结构3和结构4在增加隐含层后结果没提升反而降低,表明在经过卷积之后就已经学到足够的信息,没有必要再增加隐含层。结构5和6说明增加卷积层还是可以进一步提高结果的。
- EXPERIMENTAL SETUP:通过设置不同参数,找到最佳结果;之后通过不同的相似的计算方式来进行效果比对,书写实验结果
采用word2vec进行词向量的训练,采用随机梯度下降SGD的优化方法和 l2规范式(权重0.0001,学习率0.01,判断阈值0.009),对一些超参数进行设置实验,并提出了两种新的相似度度量指标AESD和GESD
- RESULTS AND DISCUSSIONS: (积累一些经验,结论)
自己的框架要比Baseline好;
Q和A放入统一的神经网络时效果要比分别各自的神经网络要好;
CNN已经获取了足够的特征,不再需要再在之后增加其他隐层;
增加CNN层数可以获取更多的特征;
增加CNN卷积核的数量可以获得更多特征;
Layer-wise supervision可以缓解神经网络的高效学习的难题(即结构6的处理方法);
skip-gram的方式在某些数据集上有些提升;
选择有效的计算相似度的方式会使得结果有所提升;
- Related work:其实即为该研究的一些其他人的工作,深度学习CNN的应用,即为国内外研究现状。
- CONCLUSIONS:在该部分上,其实所有做的工作取得成果在第一部分已经介绍了大部分,也就意味着和第一部分差不多
Some Thoughts:(1)QA方面论文的第一篇,时间也是2015年的论文,所提出的神经网络结构也较为简单,也没有加入RNN的部分,没有去刻画自然语言的序列特征,包括激活函数也是tanh。(自己弄一个模型,加上这个部分)
要把深度学习运用到聊天机器人中,关键在于以下几点:
1. 对几种神经网络结构的选择、组合、优化
2. 因为是有关自然语言处理,所以少不了能让机器识别的词向量
3. 当涉及到相似或匹配关系时要考虑相似度计算,典型的方法是cos距离
4. 如果需求涉及到文本序列的全局信息就用CNN或LSTM
5. 当精度不高时可以加层
6. 当计算量过大时别忘了参数共享和池化
(2)参考别的文章:
- 字向量不是固定的,在训练中会更新。
- Dropout的使用对最高的准确率没有很大的影响,但是使用了Dropout的结果更稳定,准确率的波动会更小,所以建议还是要使用Dropout的。不过Dropout也不易过度使用,比如Dropout的keep_prob概率如果设置到0.25,则模型收敛得更慢,训练时间长很多,效果也有可能会更差,设置会差很多。我这版代码使用的keep_prob为0.5,同时保证准确率和训练时间。另外,Dropout只应用到了max-pooling的结果上,其他地方没有再使用了,过多的使用反而不好。
- 如何生成训练集。每个训练case需要一个问题+一个正向答案+一个负向答案,很明显问题和正向答案都是有的,负向答案的生成方法就是随机采样,这样就不需要涉及任何人工标注工作了,可以很方便的应用到大数据集上。
- HL层的效果不明显,有很微量的提升。如果HL层的大小是200,字向量是100,则HL层相当于将字向量再放大一倍,这个感觉没有多少信息可利用的,还不如直接将字向量设置成200,还省去了HL这一层的变换。
- margin的值一般都设置得比较小。这里用的是0.05
- 如果将Cosine_similarity这一层换成分类或者回归,印象中效果是不如Cosine_similarity的(具体数据忘了)
- num_filters越大并不是效果越好,基本到了一定程度就很难提升了,反而会降低训练速度。
- 同时也写了tensorflow版本代码,对比theano的,效果差不多。
- Adam和SGD两种训练方法比较,Adam训练速度貌似会更快一些,效果基本也持平吧,没有太细节的对比。不过同样的网络+SGD,theano好像训练要更快一些。
- Loss和Accuracy是比较重要的监控参数。如果写一个新的网络的话,类似的指标是很有必要的,可以在每个迭代中评估网络是否正在收敛。因为调试比较麻烦,所以通过这些参数能评估你的网络写对没,参数设置是否正确。
- 网络的参数还是比较重要的,如果一些参数设置不合理,很有可能结果千差万别,记得最初用tensorflow实现的时候,应该是dropout设置得太小,导致效果很差,很久才找到原因。所以调参和微调网络还是需要一定的技巧和经验的,做这版代码的时候就经历了一段比较痛苦的调参过程,最开始还怀疑是网络设计或是代码有问题,最后总结应该就是参数没设置好。
- 结语:如果关注这个东西的人多的话,后面还可以有tensorflow版本的QA CNN,以及LSTM的代码奉上:)
- 补充:tensorflow的CNN代码已添加到github上,https://github.com/white127/insuranceQA-cnn-lstm Contact: jiangwen127@gmail.com weibo:码坛奥沙利
源代码: https://github.com/shuzi/insuranceQA.git
《Applying Deep Learning to Answer Selection: A Study And an Open Task》文章理解小结的更多相关文章
- (转)Nuts and Bolts of Applying Deep Learning
Kevin Zakka's Blog About Nuts and Bolts of Applying Deep Learning Sep 26, 2016 This weekend was very ...
- #Deep Learning回顾#之基于深度学习的目标检测(阅读小结)
原文链接:https://www.52ml.net/20287.html 这篇博文主要讲了深度学习在目标检测中的发展. 博文首先介绍了传统的目标检测算法过程: 传统的目标检测一般使用滑动窗口的框架,主 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- What are some good books/papers for learning deep learning?
What's the most effective way to get started with deep learning? 29 Answers Yoshua Bengio, ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料汇总 (上)
转载:http://dataunion.org/8463.html?utm_source=tuicool&utm_medium=referral <Brief History of Ma ...
- 机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(下)
转载:http://www.jianshu.com/p/b73b6953e849 该资源的github地址:Qix <Statistical foundations of machine lea ...
- Decision Boundaries for Deep Learning and other Machine Learning classifiers
Decision Boundaries for Deep Learning and other Machine Learning classifiers H2O, one of the leading ...
- Rolling in the Deep (Learning)
Rolling in the Deep (Learning) Deep Learning has been getting a lot of press lately, and is one of t ...
随机推荐
- 【Linux】- vi/vim
所有的 Unix Like 系统都会内建 vi 文书编辑器,其他的文书编辑器则不一定会存在. 但是目前我们使用比较多的是 vim 编辑器. vim 具有程序编辑的能力,可以主动的以字体颜色辨别语法的正 ...
- 发送缓冲区sk_wmem_queued
sk_wmem_queued是目前发送缓冲区的量 tcp_trim_head 把这快内存给去掉, 什么时候会加入到内存里呢?__tcp_add_write_queue_tail, skb里的内存是啥? ...
- DELPHI enablecontrols,disablecontrols函数
DisableControls方法是在程序修改或后台有刷新记录的时候切断数据组件,如TTABLE.ADOQUERY等等与组件数据源的联系.如果没有切断,数据源中只要一有数据的改动,尤其是批量改动的话, ...
- Activiti5工作流笔记三
组任务 直接指定办理人 流程图如下: import java.util.HashMap; import java.util.List; import java.util.Map; import org ...
- 【bzoj5001】搞事情 暴力
题目描述 给定一个NM的01矩阵,每次可以选定一个位置,将它和它相邻格子的数取反.问:怎样操作使得所有格子都变为0.当有多组解时,优先取操作次数最小的:当操作次数相同时,优先取字典序最小的. 输入 第 ...
- 【bzoj5089】最大连续子段和 分块+单调栈维护凸包
题目描述 给出一个长度为 n 的序列,要求支持如下两种操作: A l r x :将 [l,r] 区间内的所有数加上 x : Q l r : 询问 [l,r] 区间的最大连续子段和. 其中,一 ...
- [洛谷P5205]【模板】多项式开根
题目大意:给你$n$项多项式$A(x)$,求出$B(x)$满足$B^2(x)\equiv A(x)\pmod{x^n}$ 题解:考虑已经求出$B_0(x)$满足$B_0^2(x)\equiv A(x) ...
- Hyperledger Fabric 实战(十): Fabric node SDK 样例 - 投票DAPP
Fabric node SDK 样例 - 投票DAPP 参考 fabric-samples 下的 fabcar 加以实现 目录结构 . ├── app │ ├── controllers │ │ └─ ...
- POJ3348:Cows——题解
http://poj.org/problem?id=3348 题目大意:用已给出的点围出面积最大的凸包,输出面积/50(向下取整) —————————————————————————— 第一道凸包?以 ...
- c# 合并两个有序数组
, , , , , }; , , , }; ArrayList lists = new ArrayList(); ArrayList temp = new ArrayList(); lists.Add ...