Day02——Python基本数据类型
一、运算符
1.算数运算符
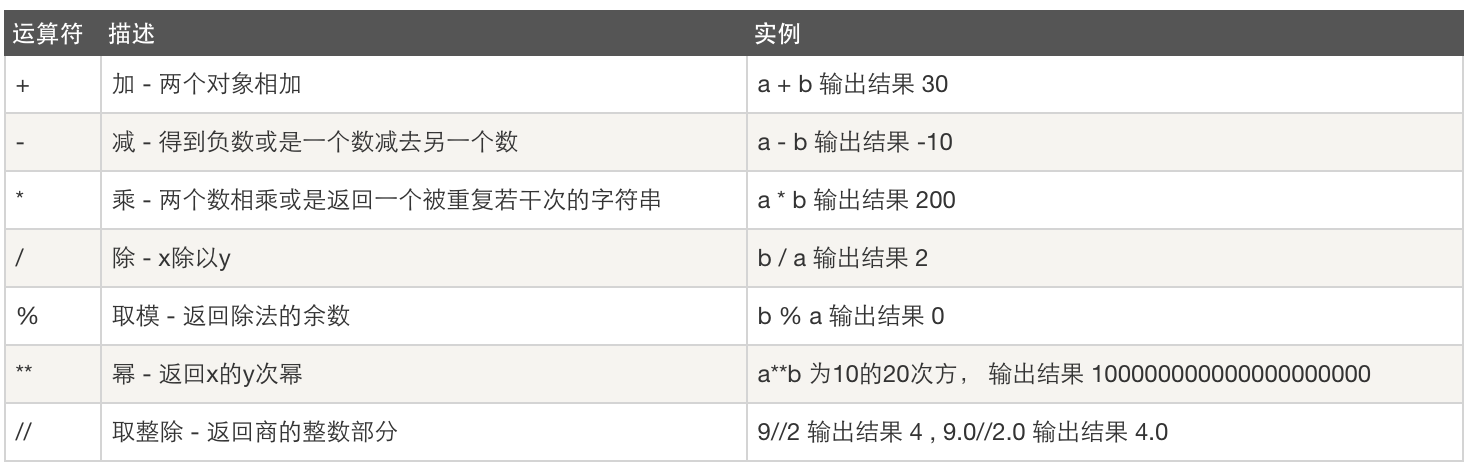
2.比较运算符

3.复制运算符
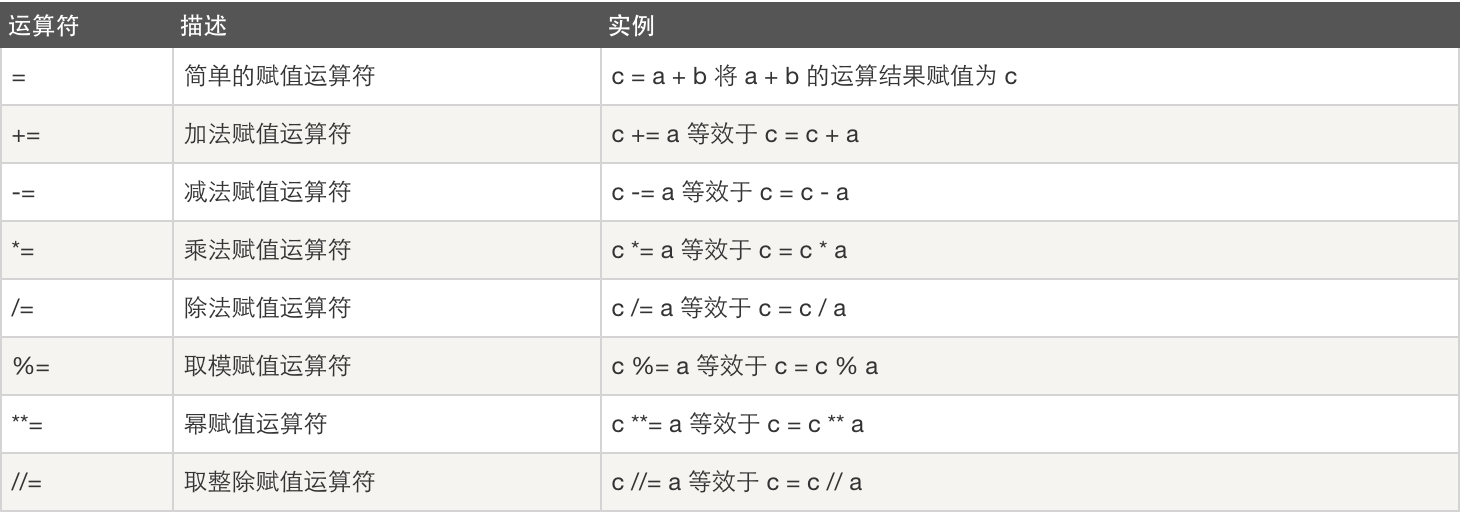
4.逻辑运算符

5.成员运算符

二、基本数据类型
1.数字
整数(int)
- 在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
- 在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
浮点数(fload)
- 浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,1.23x109和12.3x108是完全相等的。
浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e替代,1.23x109就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5
2.布尔值
- 真或假
- 1 或 0
3.字符串
- str="Hello world ! "
- 移除空白
- str.strip(self, chars=None)
- """ 移除两段空白 """
- 分割
- str.split(self, sep=None, maxsplit=None)
- """ 分割, maxsplit最多分割几次 """
- 长度 ##len(str)
- 索引 ##str[0] 获取字符串第一个元素
- 切片
- [:] 提取从开头(默认位置0)到结尾(默认位置-1)的整个字符串
- str[::5]
[start:end:step]
- [:end] 从开头提取到end - 1
[start:end] 从start 提取到end - 1
[start:end:step] 从start 提取到end - 1,每step 个字符提取一个
左侧第一个字符的位置/偏移量为0,右侧最后一个字符的位置/偏移量为-1
- 大小写转换
- str.swapcase(self)
- """ 大写变小写,小写变大写 """
- str.upper(self)
- str.lower(self)
- str.swapcase(self)
- 替换
- str.replace(self, old, new, count=None)
- 统计
- str.count('le') ##统计le在str出现的次数
- 格式输出
str.center(50,"-")
- ##输出 '--------------------- Hello world ! ----------------------'
- class str(basestring):
- """
- str(object='') -> string
- Return a nice string representation of the object.
- If the argument is a string, the return value is the same object.
- """
- def capitalize(self):
- """ 首字母变大写 """
- """
- S.capitalize() -> string
- Return a copy of the string S with only its first character
- capitalized.
- """
- return ""
- def center(self, width, fillchar=None):
- """ 内容居中,width:总长度;fillchar:空白处填充内容,默认无 """
- """
- S.center(width[, fillchar]) -> string
- Return S centered in a string of length width. Padding is
- done using the specified fill character (default is a space)
- """
- return ""
- def count(self, sub, start=None, end=None):
- """ 子序列个数 """
- """
- S.count(sub[, start[, end]]) -> int
- Return the number of non-overlapping occurrences of substring sub in
- string S[start:end]. Optional arguments start and end are interpreted
- as in slice notation.
- """
- return 0
- def decode(self, encoding=None, errors=None):
- """ 解码 """
- """
- S.decode([encoding[,errors]]) -> object
- Decodes S using the codec registered for encoding. encoding defaults
- to the default encoding. errors may be given to set a different error
- handling scheme. Default is 'strict' meaning that encoding errors raise
- a UnicodeDecodeError. Other possible values are 'ignore' and 'replace'
- as well as any other name registered with codecs.register_error that is
- able to handle UnicodeDecodeErrors.
- """
- return object()
- def encode(self, encoding=None, errors=None):
- """ 编码,针对unicode """
- """
- S.encode([encoding[,errors]]) -> object
- Encodes S using the codec registered for encoding. encoding defaults
- to the default encoding. errors may be given to set a different error
- handling scheme. Default is 'strict' meaning that encoding errors raise
- a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
- 'xmlcharrefreplace' as well as any other name registered with
- codecs.register_error that is able to handle UnicodeEncodeErrors.
- """
- return object()
- def endswith(self, suffix, start=None, end=None):
- """ 是否以 xxx 结束 """
- """
- S.endswith(suffix[, start[, end]]) -> bool
- Return True if S ends with the specified suffix, False otherwise.
- With optional start, test S beginning at that position.
- With optional end, stop comparing S at that position.
- suffix can also be a tuple of strings to try.
- """
- return False
- def expandtabs(self, tabsize=None):
- """ 将tab转换成空格,默认一个tab转换成8个空格 """
- """
- S.expandtabs([tabsize]) -> string
- Return a copy of S where all tab characters are expanded using spaces.
- If tabsize is not given, a tab size of 8 characters is assumed.
- """
- return ""
- def find(self, sub, start=None, end=None):
- """ 寻找子序列位置,如果没找到,返回 -1 """
- """
- S.find(sub [,start [,end]]) -> int
- Return the lowest index in S where substring sub is found,
- such that sub is contained within S[start:end]. Optional
- arguments start and end are interpreted as in slice notation.
- Return -1 on failure.
- """
- return 0
- def format(*args, **kwargs): # known special case of str.format
- """ 字符串格式化,动态参数,将函数式编程时细说 """
- """
- S.format(*args, **kwargs) -> string
- Return a formatted version of S, using substitutions from args and kwargs.
- The substitutions are identified by braces ('{' and '}').
- """
- pass
- def index(self, sub, start=None, end=None):
- """ 子序列位置,如果没找到,报错 """
- S.index(sub [,start [,end]]) -> int
- Like S.find() but raise ValueError when the substring is not found.
- """
- return 0
- def isalnum(self):
- """ 是否是字母和数字 """
- """
- S.isalnum() -> bool
- Return True if all characters in S are alphanumeric
- and there is at least one character in S, False otherwise.
- """
- return False
- def isalpha(self):
- """ 是否是字母 """
- """
- S.isalpha() -> bool
- Return True if all characters in S are alphabetic
- and there is at least one character in S, False otherwise.
- """
- return False
- def isdigit(self):
- """ 是否是数字 """
- """
- S.isdigit() -> bool
- Return True if all characters in S are digits
- and there is at least one character in S, False otherwise.
- """
- return False
- def islower(self):
- """ 是否小写 """
- """
- S.islower() -> bool
- Return True if all cased characters in S are lowercase and there is
- at least one cased character in S, False otherwise.
- """
- return False
- def isspace(self):
- """
- S.isspace() -> bool
- Return True if all characters in S are whitespace
- and there is at least one character in S, False otherwise.
- """
- return False
- def istitle(self):
- """
- S.istitle() -> bool
- Return True if S is a titlecased string and there is at least one
- character in S, i.e. uppercase characters may only follow uncased
- characters and lowercase characters only cased ones. Return False
- otherwise.
- """
- return False
- def isupper(self):
- """
- S.isupper() -> bool
- Return True if all cased characters in S are uppercase and there is
- at least one cased character in S, False otherwise.
- """
- return False
- def join(self, iterable):
- """ 连接 """
- """
- S.join(iterable) -> string
- Return a string which is the concatenation of the strings in the
- iterable. The separator between elements is S.
- """
- return ""
- def ljust(self, width, fillchar=None):
- """ 内容左对齐,右侧填充 """
- """
- S.ljust(width[, fillchar]) -> string
- Return S left-justified in a string of length width. Padding is
- done using the specified fill character (default is a space).
- """
- return ""
- def lower(self):
- """ 变小写 """
- """
- S.lower() -> string
- Return a copy of the string S converted to lowercase.
- """
- return ""
- def lstrip(self, chars=None):
- """ 移除左侧空白 """
- """
- S.lstrip([chars]) -> string or unicode
- Return a copy of the string S with leading whitespace removed.
- If chars is given and not None, remove characters in chars instead.
- If chars is unicode, S will be converted to unicode before stripping
- """
- return ""
- def partition(self, sep):
- """ 分割,前,中,后三部分 """
- """
- S.partition(sep) -> (head, sep, tail)
- Search for the separator sep in S, and return the part before it,
- the separator itself, and the part after it. If the separator is not
- found, return S and two empty strings.
- """
- pass
- def replace(self, old, new, count=None):
- """ 替换 """
- """
- S.replace(old, new[, count]) -> string
- Return a copy of string S with all occurrences of substring
- old replaced by new. If the optional argument count is
- given, only the first count occurrences are replaced.
- """
- return ""
- def rfind(self, sub, start=None, end=None):
- """
- S.rfind(sub [,start [,end]]) -> int
- Return the highest index in S where substring sub is found,
- such that sub is contained within S[start:end]. Optional
- arguments start and end are interpreted as in slice notation.
- Return -1 on failure.
- """
- return 0
- def rindex(self, sub, start=None, end=None):
- """
- S.rindex(sub [,start [,end]]) -> int
- Like S.rfind() but raise ValueError when the substring is not found.
- """
- return 0
- def rjust(self, width, fillchar=None):
- """
- S.rjust(width[, fillchar]) -> string
- Return S right-justified in a string of length width. Padding is
- done using the specified fill character (default is a space)
- """
- return ""
- def rpartition(self, sep):
- """
- S.rpartition(sep) -> (head, sep, tail)
- Search for the separator sep in S, starting at the end of S, and return
- the part before it, the separator itself, and the part after it. If the
- separator is not found, return two empty strings and S.
- """
- pass
- def rsplit(self, sep=None, maxsplit=None):
- """
- S.rsplit([sep [,maxsplit]]) -> list of strings
- Return a list of the words in the string S, using sep as the
- delimiter string, starting at the end of the string and working
- to the front. If maxsplit is given, at most maxsplit splits are
- done. If sep is not specified or is None, any whitespace string
- is a separator.
- """
- return []
- def rstrip(self, chars=None):
- """
- S.rstrip([chars]) -> string or unicode
- Return a copy of the string S with trailing whitespace removed.
- If chars is given and not None, remove characters in chars instead.
- If chars is unicode, S will be converted to unicode before stripping
- """
- return ""
- def split(self, sep=None, maxsplit=None):
- """ 分割, maxsplit最多分割几次 """
- """
- S.split([sep [,maxsplit]]) -> list of strings
- Return a list of the words in the string S, using sep as the
- delimiter string. If maxsplit is given, at most maxsplit
- splits are done. If sep is not specified or is None, any
- whitespace string is a separator and empty strings are removed
- from the result.
- """
- return []
- def splitlines(self, keepends=False):
- """ 根据换行分割 """
- """
- S.splitlines(keepends=False) -> list of strings
- Return a list of the lines in S, breaking at line boundaries.
- Line breaks are not included in the resulting list unless keepends
- is given and true.
- """
- return []
- def startswith(self, prefix, start=None, end=None):
- """ 是否起始 """
- """
- S.startswith(prefix[, start[, end]]) -> bool
- Return True if S starts with the specified prefix, False otherwise.
- With optional start, test S beginning at that position.
- With optional end, stop comparing S at that position.
- prefix can also be a tuple of strings to try.
- """
- return False
- def strip(self, chars=None):
- """ 移除两段空白 """
- """
- S.strip([chars]) -> string or unicode
- Return a copy of the string S with leading and trailing
- whitespace removed.
- If chars is given and not None, remove characters in chars instead.
- If chars is unicode, S will be converted to unicode before stripping
- """
- return ""
- def swapcase(self):
- """ 大写变小写,小写变大写 """
- """
- S.swapcase() -> string
- Return a copy of the string S with uppercase characters
- converted to lowercase and vice versa.
- """
- return ""
- def title(self):
- """
- S.title() -> string
- Return a titlecased version of S, i.e. words start with uppercase
- characters, all remaining cased characters have lowercase.
- """
- return ""
- def translate(self, table, deletechars=None):
- """
- 转换,需要先做一个对应表,最后一个表示删除字符集合
- intab = "aeiou"
- outtab = ""
- trantab = maketrans(intab, outtab)
- str = "this is string example....wow!!!"
- print str.translate(trantab, 'xm')
- """
- """
- S.translate(table [,deletechars]) -> string
- Return a copy of the string S, where all characters occurring
- in the optional argument deletechars are removed, and the
- remaining characters have been mapped through the given
- translation table, which must be a string of length 256 or None.
- If the table argument is None, no translation is applied and
- the operation simply removes the characters in deletechars.
- """
- return ""
- def upper(self):
- """
- S.upper() -> string
- Return a copy of the string S converted to uppercase.
- """
- return ""
- def zfill(self, width):
- """方法返回指定长度的字符串,原字符串右对齐,前面填充0。"""
- """
- S.zfill(width) -> string
- Pad a numeric string S with zeros on the left, to fill a field
- of the specified width. The string S is never truncated.
- """
- return ""
- def _formatter_field_name_split(self, *args, **kwargs): # real signature unknown
- pass
- def _formatter_parser(self, *args, **kwargs): # real signature unknown
- pass
- def __add__(self, y):
- """ x.__add__(y) <==> x+y """
- pass
- def __contains__(self, y):
- """ x.__contains__(y) <==> y in x """
- pass
- def __eq__(self, y):
- """ x.__eq__(y) <==> x==y """
- pass
- def __format__(self, format_spec):
- """
- S.__format__(format_spec) -> string
- Return a formatted version of S as described by format_spec.
- """
- return ""
- def __getattribute__(self, name):
- """ x.__getattribute__('name') <==> x.name """
- pass
- def __getitem__(self, y):
- """ x.__getitem__(y) <==> x[y] """
- pass
- def __getnewargs__(self, *args, **kwargs): # real signature unknown
- pass
- def __getslice__(self, i, j):
- """
- x.__getslice__(i, j) <==> x[i:j]
- Use of negative indices is not supported.
- """
- pass
- def __ge__(self, y):
- """ x.__ge__(y) <==> x>=y """
- pass
- def __gt__(self, y):
- """ x.__gt__(y) <==> x>y """
- pass
- def __hash__(self):
- """ x.__hash__() <==> hash(x) """
- pass
- def __init__(self, string=''): # known special case of str.__init__
- """
- str(object='') -> string
- Return a nice string representation of the object.
- If the argument is a string, the return value is the same object.
- # (copied from class doc)
- """
- pass
- def __len__(self):
- """ x.__len__() <==> len(x) """
- pass
- def __le__(self, y):
- """ x.__le__(y) <==> x<=y """
- pass
- def __lt__(self, y):
- """ x.__lt__(y) <==> x<y """
- pass
- def __mod__(self, y):
- """ x.__mod__(y) <==> x%y """
- pass
- def __mul__(self, n):
- """ x.__mul__(n) <==> x*n """
- pass
- @staticmethod # known case of __new__
- def __new__(S, *more):
- """ T.__new__(S, ...) -> a new object with type S, a subtype of T """
- pass
- def __ne__(self, y):
- """ x.__ne__(y) <==> x!=y """
- pass
- def __repr__(self):
- """ x.__repr__() <==> repr(x) """
- pass
- def __rmod__(self, y):
- """ x.__rmod__(y) <==> y%x """
- pass
- def __rmul__(self, n):
- """ x.__rmul__(n) <==> n*x """
- pass
- def __sizeof__(self):
- """ S.__sizeof__() -> size of S in memory, in bytes """
- pass
- def __str__(self):
- """ x.__str__() <==> str(x) """
- pass
- str
字符串类
4. 列表
列表创建
- name_list = ['alex', 'seven', 'eric']
- 或
- name_list = list(['alex', 'seven', 'eric'])
基本操作:
- names = ['Alex',"Tenglan",'Eric']
- >>> names[0]
- 'Alex'
- >>> names[2]
- 'Eric'
- >>> names[-1]
- 'Eric'
- >>> names[-2] #还可以倒着取
- 'Tenglan'
索引
- >>> names
- ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy']
- >>> names.append("我是新来的")
- >>> names
- ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
追加
- >>> names
- ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
- >>> names.insert(2,"强行从Eric前面插入")
- >>> names
- ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
- >>> names.insert(5,"从eric后面插入试试新姿势")
- >>> names
- ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
插入
- >>> names
- ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
- >>> names[2] = "该换人了"
- >>> names
- ['Alex', 'Tenglan', '该换人了', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
修改
- >>> del names[2]
- >>> names
- ['Alex', 'Tenglan', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
- >>> del names[4]
- >>> names
- ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
- >>>
- >>> names.remove("Eric") #删除指定元素
- >>> names
- ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', '我是新来的']
- >>> names.pop() #删除列表最后一个值
- '我是新来的'
- >>> names
- ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy']
删除
- >>> names
- ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy']
- >>> b = [1,2,3]
- >>> names.extend(b)
- >>> names
- ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3]
扩展
- >>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"]
- >>> names[1:4] #取下标1至下标4之间的数字,包括1,不包括4
- ['Tenglan', 'Eric', 'Rain']
- >>> names[1:-1] #取下标1至-1的值,不包括-1
- ['Tenglan', 'Eric', 'Rain', 'Tom']
- >>> names[0:3]
- ['Alex', 'Tenglan', 'Eric']
- >>> names[:3] #如果是从头开始取,0可以忽略,跟上句效果一样
- ['Alex', 'Tenglan', 'Eric']
- >>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写
- ['Rain', 'Tom', 'Amy']
- >>> names[3:-1] #这样-1就不会被包含了
- ['Rain', 'Tom']
- >>> names[0::2] #后面的2是代表,每隔一个元素,就取一个
- ['Alex', 'Eric', 'Tom']
- >>> names[::2] #和上句效果一样
- ['Alex', 'Eric', 'Tom']
切片
- class list(object):
- """
- list() -> new empty list
- list(iterable) -> new list initialized from iterable's items
- """
- def append(self, p_object): # real signature unknown; restored from __doc__
- """ L.append(object) -- append object to end """
- pass
- def count(self, value): # real signature unknown; restored from __doc__
- """ L.count(value) -> integer -- return number of occurrences of value """
- return 0
- def extend(self, iterable): # real signature unknown; restored from __doc__
- """ L.extend(iterable) -- extend list by appending elements from the iterable """
- pass
- def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__
- """
- L.index(value, [start, [stop]]) -> integer -- return first index of value.
- Raises ValueError if the value is not present.
- """
- return 0
- def insert(self, index, p_object): # real signature unknown; restored from __doc__
- """ L.insert(index, object) -- insert object before index """
- pass
- def pop(self, index=None): # real signature unknown; restored from __doc__
- """
- L.pop([index]) -> item -- remove and return item at index (default last).
- Raises IndexError if list is empty or index is out of range.
- """
- pass
- def remove(self, value): # real signature unknown; restored from __doc__
- """
- L.remove(value) -- remove first occurrence of value.
- Raises ValueError if the value is not present.
- """
- pass
- def reverse(self): # real signature unknown; restored from __doc__
- """ L.reverse() -- reverse *IN PLACE* """
- pass
- def sort(self, cmp=None, key=None, reverse=False): # real signature unknown; restored from __doc__
- """
- L.sort(cmp=None, key=None, reverse=False) -- stable sort *IN PLACE*;
- cmp(x, y) -> -1, 0, 1
- """
- pass
- def __add__(self, y): # real signature unknown; restored from __doc__
- """ x.__add__(y) <==> x+y """
- pass
- def __contains__(self, y): # real signature unknown; restored from __doc__
- """ x.__contains__(y) <==> y in x """
- pass
- def __delitem__(self, y): # real signature unknown; restored from __doc__
- """ x.__delitem__(y) <==> del x[y] """
- pass
- def __delslice__(self, i, j): # real signature unknown; restored from __doc__
- """
- x.__delslice__(i, j) <==> del x[i:j]
- Use of negative indices is not supported.
- """
- pass
- def __eq__(self, y): # real signature unknown; restored from __doc__
- """ x.__eq__(y) <==> x==y """
- pass
- def __getattribute__(self, name): # real signature unknown; restored from __doc__
- """ x.__getattribute__('name') <==> x.name """
- pass
- def __getitem__(self, y): # real signature unknown; restored from __doc__
- """ x.__getitem__(y) <==> x[y] """
- pass
- def __getslice__(self, i, j): # real signature unknown; restored from __doc__
- """
- x.__getslice__(i, j) <==> x[i:j]
- Use of negative indices is not supported.
- """
- pass
- def __ge__(self, y): # real signature unknown; restored from __doc__
- """ x.__ge__(y) <==> x>=y """
- pass
- def __gt__(self, y): # real signature unknown; restored from __doc__
- """ x.__gt__(y) <==> x>y """
- pass
- def __iadd__(self, y): # real signature unknown; restored from __doc__
- """ x.__iadd__(y) <==> x+=y """
- pass
- def __imul__(self, y): # real signature unknown; restored from __doc__
- """ x.__imul__(y) <==> x*=y """
- pass
- def __init__(self, seq=()): # known special case of list.__init__
- """
- list() -> new empty list
- list(iterable) -> new list initialized from iterable's items
- # (copied from class doc)
- """
- pass
- def __iter__(self): # real signature unknown; restored from __doc__
- """ x.__iter__() <==> iter(x) """
- pass
- def __len__(self): # real signature unknown; restored from __doc__
- """ x.__len__() <==> len(x) """
- pass
- def __le__(self, y): # real signature unknown; restored from __doc__
- """ x.__le__(y) <==> x<=y """
- pass
- def __lt__(self, y): # real signature unknown; restored from __doc__
- """ x.__lt__(y) <==> x<y """
- pass
- def __mul__(self, n): # real signature unknown; restored from __doc__
- """ x.__mul__(n) <==> x*n """
- pass
- @staticmethod # known case of __new__
- def __new__(S, *more): # real signature unknown; restored from __doc__
- """ T.__new__(S, ...) -> a new object with type S, a subtype of T """
- pass
- def __ne__(self, y): # real signature unknown; restored from __doc__
- """ x.__ne__(y) <==> x!=y """
- pass
- def __repr__(self): # real signature unknown; restored from __doc__
- """ x.__repr__() <==> repr(x) """
- pass
- def __reversed__(self): # real signature unknown; restored from __doc__
- """ L.__reversed__() -- return a reverse iterator over the list """
- pass
- def __rmul__(self, n): # real signature unknown; restored from __doc__
- """ x.__rmul__(n) <==> n*x """
- pass
- def __setitem__(self, i, y): # real signature unknown; restored from __doc__
- """ x.__setitem__(i, y) <==> x[i]=y """
- pass
- def __setslice__(self, i, j, y): # real signature unknown; restored from __doc__
- """
- x.__setslice__(i, j, y) <==> x[i:j]=y
- Use of negative indices is not supported.
- """
- pass
- def __sizeof__(self): # real signature unknown; restored from __doc__
- """ L.__sizeof__() -- size of L in memory, in bytes """
- pass
- __hash__ = None
- list
列表类
5.元组
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
创建元组
- ages = (11, 22, 33, 44, 55)
- 或
- ages = tuple((11, 22, 33, 44, 55))
- 索引
- 切片
- lass tuple(object):
- """
- tuple() -> empty tuple
- tuple(iterable) -> tuple initialized from iterable's items
- If the argument is a tuple, the return value is the same object.
- """
- def count(self, value): # real signature unknown; restored from __doc__
- """ T.count(value) -> integer -- return number of occurrences of value """
- return 0
- def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__
- """
- T.index(value, [start, [stop]]) -> integer -- return first index of value.
- Raises ValueError if the value is not present.
- """
- return 0
- def __add__(self, y): # real signature unknown; restored from __doc__
- """ x.__add__(y) <==> x+y """
- pass
- def __contains__(self, y): # real signature unknown; restored from __doc__
- """ x.__contains__(y) <==> y in x """
- pass
- def __eq__(self, y): # real signature unknown; restored from __doc__
- """ x.__eq__(y) <==> x==y """
- pass
- def __getattribute__(self, name): # real signature unknown; restored from __doc__
- """ x.__getattribute__('name') <==> x.name """
- pass
- def __getitem__(self, y): # real signature unknown; restored from __doc__
- """ x.__getitem__(y) <==> x[y] """
- pass
- def __getnewargs__(self, *args, **kwargs): # real signature unknown
- pass
- def __getslice__(self, i, j): # real signature unknown; restored from __doc__
- """
- x.__getslice__(i, j) <==> x[i:j]
- Use of negative indices is not supported.
- """
- pass
- def __ge__(self, y): # real signature unknown; restored from __doc__
- """ x.__ge__(y) <==> x>=y """
- pass
- def __gt__(self, y): # real signature unknown; restored from __doc__
- """ x.__gt__(y) <==> x>y """
- pass
- def __hash__(self): # real signature unknown; restored from __doc__
- """ x.__hash__() <==> hash(x) """
- pass
- def __init__(self, seq=()): # known special case of tuple.__init__
- """
- tuple() -> empty tuple
- tuple(iterable) -> tuple initialized from iterable's items
- If the argument is a tuple, the return value is the same object.
- # (copied from class doc)
- """
- pass
- def __iter__(self): # real signature unknown; restored from __doc__
- """ x.__iter__() <==> iter(x) """
- pass
- def __len__(self): # real signature unknown; restored from __doc__
- """ x.__len__() <==> len(x) """
- pass
- def __le__(self, y): # real signature unknown; restored from __doc__
- """ x.__le__(y) <==> x<=y """
- pass
- def __lt__(self, y): # real signature unknown; restored from __doc__
- """ x.__lt__(y) <==> x<y """
- pass
- def __mul__(self, n): # real signature unknown; restored from __doc__
- """ x.__mul__(n) <==> x*n """
- pass
- @staticmethod # known case of __new__
- def __new__(S, *more): # real signature unknown; restored from __doc__
- """ T.__new__(S, ...) -> a new object with type S, a subtype of T """
- pass
- def __ne__(self, y): # real signature unknown; restored from __doc__
- """ x.__ne__(y) <==> x!=y """
- pass
- def __repr__(self): # real signature unknown; restored from __doc__
- """ x.__repr__() <==> repr(x) """
- pass
- def __rmul__(self, n): # real signature unknown; restored from __doc__
- """ x.__rmul__(n) <==> n*x """
- pass
- def __sizeof__(self): # real signature unknown; restored from __doc__
- """ T.__sizeof__() -- size of T in memory, in bytes """
- pass
- tuple
元组类
- lass tuple(object):
6.字典(无序)
字典是一种Key-value数据类型,无序但key必须是唯一值
创建字典
- person = {"name": "mr.wu", 'age': 18}
- 或
- person = dict({"name": "mr.wu", 'age': 18})
常用操作:
- >>> info["stu1104"] = "苍井空"
- >>> info
- {'stu1102': 'LongZe Luola', 'stu1104': '苍井空', 'stu1103': 'XiaoZe Maliya', 'stu1101': 'TengLan Wu'}
增加
- >>> info['stu1101'] = "武藤兰"
- >>> info
- {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤兰'}
修改
- >>> info
- {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤兰'}
- >>> info.pop("stu1101") #标准删除姿势
- '武藤兰'
- >>> info
- {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
- >>> del info['stu1103'] #换个姿势删除
- >>> info
- {'stu1102': 'LongZe Luola'}
- >>>
- >>>
- >>>
- >>> info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
- >>> info
- {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} #随机删除
- >>> info.popitem()
- ('stu1102', 'LongZe Luola')
- >>> info
- {'stu1103': 'XiaoZe Maliya'}
删除
- >>> info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
- >>>
- >>> "stu1102" in info #标准用法
- True
- >>> info.get("stu1102") #获取
- 'LongZe Luola'
- >>> info["stu1102"] #同上,但是看下面
- 'LongZe Luola'
- >>> info["stu1105"] #如果一个key不存在,就报错,get不会,不存在只返回None
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- KeyError: 'stu1105'
查找
- av_catalog = {
- "欧美":{
- "www.youporn.com": ["很多免费的,世界最大的","质量一般"],
- "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],
- "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],
- "x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"]
- },
- "日韩":{
- "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]
- },
- "大陆":{
- "":["全部免费,真好,好人一生平安","服务器在国外,慢"]
- }
- }
- av_catalog["大陆"][""][1] += ",可以用爬虫爬下来"
- print(av_catalog["大陆"][""])
- #ouput
- ['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']
字典嵌套
- #values
- >>> info.values()
- dict_values(['LongZe Luola', 'XiaoZe Maliya'])
- #keys
- >>> info.keys()
- dict_keys(['stu1102', 'stu1103'])
- #setdefault
- >>> info.setdefault("stu1106","Alex")
- 'Alex'
- >>> info
- {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'}
- >>> info.setdefault("stu1102","龙泽萝拉")
- 'LongZe Luola'
- >>> info
- {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'}
- #update
- >>> info
- {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'}
- >>> b = {1:2,3:4, "stu1102":"龙泽萝拉"}
- >>> info.update(b)
- >>> info
- {'stu1102': '龙泽萝拉', 1: 2, 3: 4, 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'}
- #items
- info.items()
- dict_items([('stu1102', '龙泽萝拉'), (1, 2), (3, 4), ('stu1103', 'XiaoZe Maliya'), ('stu1106', 'Alex')])
- #通过一个列表生成默认dict,有个没办法解释的坑,少用吧这个
- >>> dict.fromkeys([1,2,3],'testd')
- {1: 'testd', 2: 'testd', 3: 'testd'}
key-value
- #方法1
- for key in info:
- print(key,info[key])
- #方法2
- for k,v in info.items(): #会先把dict转成list,数据里大时莫用
- print(k,v)
循环
- class dict(object):
- """
- dict() -> new empty dictionary
- dict(mapping) -> new dictionary initialized from a mapping object's
- (key, value) pairs
- dict(iterable) -> new dictionary initialized as if via:
- d = {}
- for k, v in iterable:
- d[k] = v
- dict(**kwargs) -> new dictionary initialized with the name=value pairs
- in the keyword argument list. For example: dict(one=1, two=2)
- """
- def clear(self): # real signature unknown; restored from __doc__
- """ 清除内容 """
- """ D.clear() -> None. Remove all items from D. """
- pass
- def copy(self): # real signature unknown; restored from __doc__
- """ 浅拷贝 """
- """ D.copy() -> a shallow copy of D """
- pass
- @staticmethod # known case
- def fromkeys(S, v=None): # real signature unknown; restored from __doc__
- """
- dict.fromkeys(S[,v]) -> New dict with keys from S and values equal to v.
- v defaults to None.
- """
- pass
- def get(self, k, d=None): # real signature unknown; restored from __doc__
- """ 根据key获取值,d是默认值 """
- """ D.get(k[,d]) -> D[k] if k in D, else d. d defaults to None. """
- pass
- def has_key(self, k): # real signature unknown; restored from __doc__
- """ 是否有key """
- """ D.has_key(k) -> True if D has a key k, else False """
- return False
- def items(self): # real signature unknown; restored from __doc__
- """ 所有项的列表形式 """
- """ D.items() -> list of D's (key, value) pairs, as 2-tuples """
- return []
- def iteritems(self): # real signature unknown; restored from __doc__
- """ 项可迭代 """
- """ D.iteritems() -> an iterator over the (key, value) items of D """
- pass
- def iterkeys(self): # real signature unknown; restored from __doc__
- """ key可迭代 """
- """ D.iterkeys() -> an iterator over the keys of D """
- pass
- def itervalues(self): # real signature unknown; restored from __doc__
- """ value可迭代 """
- """ D.itervalues() -> an iterator over the values of D """
- pass
- def keys(self): # real signature unknown; restored from __doc__
- """ 所有的key列表 """
- """ D.keys() -> list of D's keys """
- return []
- def pop(self, k, d=None): # real signature unknown; restored from __doc__
- """ 获取并在字典中移除 """
- """
- D.pop(k[,d]) -> v, remove specified key and return the corresponding value.
- If key is not found, d is returned if given, otherwise KeyError is raised
- """
- pass
- def popitem(self): # real signature unknown; restored from __doc__
- """ 获取并在字典中移除 """
- """
- D.popitem() -> (k, v), remove and return some (key, value) pair as a
- 2-tuple; but raise KeyError if D is empty.
- """
- pass
- def setdefault(self, k, d=None): # real signature unknown; restored from __doc__
- """ 如果key不存在,则创建,如果存在,则返回已存在的值且不修改 """
- """ D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D """
- pass
- def update(self, E=None, **F): # known special case of dict.update
- """ 更新
- {'name':'alex', 'age': 18000}
- [('name','sbsbsb'),]
- """
- """
- D.update([E, ]**F) -> None. Update D from dict/iterable E and F.
- If E present and has a .keys() method, does: for k in E: D[k] = E[k]
- If E present and lacks .keys() method, does: for (k, v) in E: D[k] = v
- In either case, this is followed by: for k in F: D[k] = F[k]
- """
- pass
- def values(self): # real signature unknown; restored from __doc__
- """ 所有的值 """
- """ D.values() -> list of D's values """
- return []
- def viewitems(self): # real signature unknown; restored from __doc__
- """ 所有项,只是将内容保存至view对象中 """
- """ D.viewitems() -> a set-like object providing a view on D's items """
- pass
- def viewkeys(self): # real signature unknown; restored from __doc__
- """ D.viewkeys() -> a set-like object providing a view on D's keys """
- pass
- def viewvalues(self): # real signature unknown; restored from __doc__
- """ D.viewvalues() -> an object providing a view on D's values """
- pass
- def __cmp__(self, y): # real signature unknown; restored from __doc__
- """ x.__cmp__(y) <==> cmp(x,y) """
- pass
- def __contains__(self, k): # real signature unknown; restored from __doc__
- """ D.__contains__(k) -> True if D has a key k, else False """
- return False
- def __delitem__(self, y): # real signature unknown; restored from __doc__
- """ x.__delitem__(y) <==> del x[y] """
- pass
- def __eq__(self, y): # real signature unknown; restored from __doc__
- """ x.__eq__(y) <==> x==y """
- pass
- def __getattribute__(self, name): # real signature unknown; restored from __doc__
- """ x.__getattribute__('name') <==> x.name """
- pass
- def __getitem__(self, y): # real signature unknown; restored from __doc__
- """ x.__getitem__(y) <==> x[y] """
- pass
- def __ge__(self, y): # real signature unknown; restored from __doc__
- """ x.__ge__(y) <==> x>=y """
- pass
- def __gt__(self, y): # real signature unknown; restored from __doc__
- """ x.__gt__(y) <==> x>y """
- pass
- def __init__(self, seq=None, **kwargs): # known special case of dict.__init__
- """
- dict() -> new empty dictionary
- dict(mapping) -> new dictionary initialized from a mapping object's
- (key, value) pairs
- dict(iterable) -> new dictionary initialized as if via:
- d = {}
- for k, v in iterable:
- d[k] = v
- dict(**kwargs) -> new dictionary initialized with the name=value pairs
- in the keyword argument list. For example: dict(one=1, two=2)
- # (copied from class doc)
- """
- pass
- def __iter__(self): # real signature unknown; restored from __doc__
- """ x.__iter__() <==> iter(x) """
- pass
- def __len__(self): # real signature unknown; restored from __doc__
- """ x.__len__() <==> len(x) """
- pass
- def __le__(self, y): # real signature unknown; restored from __doc__
- """ x.__le__(y) <==> x<=y """
- pass
- def __lt__(self, y): # real signature unknown; restored from __doc__
- """ x.__lt__(y) <==> x<y """
- pass
- @staticmethod # known case of __new__
- def __new__(S, *more): # real signature unknown; restored from __doc__
- """ T.__new__(S, ...) -> a new object with type S, a subtype of T """
- pass
- def __ne__(self, y): # real signature unknown; restored from __doc__
- """ x.__ne__(y) <==> x!=y """
- pass
- def __repr__(self): # real signature unknown; restored from __doc__
- """ x.__repr__() <==> repr(x) """
- pass
- def __setitem__(self, i, y): # real signature unknown; restored from __doc__
- """ x.__setitem__(i, y) <==> x[i]=y """
- pass
- def __sizeof__(self): # real signature unknown; restored from __doc__
- """ D.__sizeof__() -> size of D in memory, in bytes """
- pass
- __hash__ = None
- dict
字典类
- class dict(object):
7.其他
- for循环(支持break ,continue)
- li = [11,22,33,44]
- for item in li:
- print item
- enumrate(为可迭代对象添加序号)
- li = [11,22,33]
- for k,v in enumerate(li, 1):
- print(k,v)
- range和xrange(指定范围,生成随机数)
- print range(1, 10)
- # 结果:[1, 2, 3, 4, 5, 6, 7, 8, 9]
- print range(1, 10, 2)
- # 结果:[1, 3, 5, 7, 9]
- print range(30, 0, -2)
- # 结果:[30, 28, 26, 24, 22, 20, 18, 16, 14, 12, 10, 8, 6, 4, 2]
三、练习题
1、元素分类
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66的所有值, 'k2': 小于66的所有值}
2、查找
查找列表中元素,移除每个元素的空格,并查找以 a或A开头 并且以 c 结尾的所有元素。
li = ["alec", " aric", "Alex", "Tony", "rain"]
tu = ("alec", " aric", "Alex", "Tony", "rain")
dic = {'k1': "alex", 'k2': ' aric', "k3": "Alex", "k4": "Tony"}
3、输出商品列表,用户输入序号,显示用户选中的商品
商品 li = ["手机", "电脑", '鼠标垫', '游艇']
4、购物车
功能要求:
要求用户输入总资产,例如:2000
显示商品列表,让用户根据序号选择商品,加入购物车
购买,如果商品总额大于总资产,提示账户余额不足,否则,购买成功。
附加:可充值、某商品移除购物车
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998},
]
5、用户交互,显示省市县三级联动的选择
dic = {
"河北": {
"石家庄": ["鹿泉", "藁城", "元氏"],
"邯郸": ["永年", "涉县", "磁县"],
}
"河南": {
...
}
"山西": {
...
}
}
Day02——Python基本数据类型的更多相关文章
- Day02 - Python 基本数据类型
1 基本数据类型 Python有五个标准的数据类型: Numbers(数字) String(字符串) List(列表) Tuple(元组) Dictionary(字典) 1.1 数字 数字数据类型用于 ...
- day02 Python 的模块,运算,数据类型以及方法
初识pyhton的模块: 什么是模块: 我的理解就是实现一个功能的函数,把它封装起来,在你需要使用的时候直接调用即可,我的印象里类似于shell 的单独函数脚本. python 的模块分为标准的和第三 ...
- python 基本数据类型分析
在python中,一切都是对象!对象由类创建而来,对象所拥有的功能都来自于类.在本节中,我们了解一下python基本数据类型对象具有哪些功能,我们平常是怎么使用的. 对于python,一切事物都是对象 ...
- python常用数据类型内置方法介绍
熟练掌握python常用数据类型内置方法是每个初学者必须具备的内功. 下面介绍了python常用的集中数据类型及其方法,点开源代码,其中对主要方法都进行了中文注释. 一.整型 a = 100 a.xx ...
- 闲聊之Python的数据类型 - 零基础入门学习Python005
闲聊之Python的数据类型 让编程改变世界 Change the world by program Python的数据类型 闲聊之Python的数据类型所谓闲聊,goosip,就是屁大点事可以咱聊上 ...
- python自学笔记(二)python基本数据类型之字符串处理
一.数据类型的组成分3部分:身份.类型.值 身份:id方法来看它的唯一标识符,内存地址靠这个查看 类型:type方法查看 值:数据项 二.常用基本数据类型 int 整型 boolean 布尔型 str ...
- Python入门-数据类型
一.变量 1)变量定义 name = 100(name是变量名 = 号是赋值号100是变量的值) 2)变量赋值 直接赋值 a=1 链式赋值 a=b=c=1 序列解包赋值 a,b,c = 1,2,3 ...
- Python基础:八、python基本数据类型
一.什么是数据类型? 我们人类可以很容易的分清数字与字符的区别,但是计算机并不能,计算机虽然很强大,但从某种角度上来看又很傻,除非你明确告诉它,"1"是数字,"壹&quo ...
- python之数据类型详解
python之数据类型详解 二.列表list (可以存储多个值)(列表内数字不需要加引号) sort s1=[','!'] # s1.sort() # print(s1) -->['!', ' ...
随机推荐
- GCC 7.3.0版本编译http-parser-2.1问题
http-paser是一个用c编写的http消息解析器,地址:https://github.com/nodejs/http-parser,目前版本2.9 今天用gcc 7.3.0编译其2.1版本时,编 ...
- Java - 冒泡排序的优化算法(尚学堂第七章数组)
import java.util.Arrays; public class TestBubbleSort2 { public static void main(String[] args) { int ...
- (转)MySQL- 5.7 sys schema笔记,mysql-schema
原文:http://www.bkjia.com/Mysql/1222405.html http://www.ywnds.com/?p=5045 performance_schema提供监控策略及大量监 ...
- JS框架设计之模块加载系统
任何语言一到大规模应用阶段,必然要拆封模块,有利于维护和团队协作,与Java走得最近的dojo率先引进了加载器,使用document.write与同步Ajax请求实现,后台dojo以JSONP的方法来 ...
- execution(* *..BookManager.save(..))的解读
execution(* *..BookManager.save(..))的解读: 第一颗* 代表ret-type-pattern 返回值可任意, *..BookManager 代表任意Pacakge里 ...
- 《图解http协议》之HTTPs学习笔记
对于IP协议,并不陌生.TP协议是TCP/IP协议簇中的核心协议,也是TCP/IP的载体.所有的TCP,UDP,ICMP及IGMP数据都以IP数据报格式传输.IP提供不可靠的,无连接的数据传送服务.I ...
- 修改MyEclipse8.5的workspaces
到MyEclipse8.5的安装目录下 我安装在D盘,路径为:D:\Genuitec\MyEclipse 8.5\configuration\config.ini 打开config.ini文件: ...
- 如何限制html标签input的长度
如何限制html标签input的长度 示例: <form action="/example/html/form_action.asp" method="get&qu ...
- 有意思的MySQL之最
写在前面 在平时工作中特别是架构设计阶段,咨询量最多的也就是MySQL之最了,在不经意间发现原来MySQL手册里面已经列举了,顺手拿来翻译下,如果有翻译错误或者不当的地方,欢迎批评指正. 最大和最小 ...
- input textbox tag
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAb8AAAB0CAIAAACaKavmAAAJ0klEQVR4nO3dO2wb5wHA8YOHIkOLrk