【原创】MapReduce实战(一)
应用场景:
用户每天会在网站上产生各种各样的行为,比如浏览网页,下单等,这种行为会被网站记录下来,形成用户行为日志,并存储在hdfs上。格式如下:
17:03:35.012ᄑpageviewᄑ{"device_id":"4405c39e85274857bbef58e013a08859","user_id":"0921528165741295","ip":"61.53.69.195","session_id":"9d6dc377216249e4a8f33a44eef7576d","req_url":"http://www.bigdataclass.com/product/1527235438747427"}
这是一个类Json 的非结构化数据,主要内容是用户访问网站留下的数据,该文本有device_id,user_id,ip,session_id,req_url等属性,前面还有17:03:20.586ᄑpageviewᄑ,这些非结构化的数据,我们想把该文本通过mr程序处理成被数仓所能读取的格式,比如Json串形式输出,具体形式如下:
{"time_log":1527584600586,"device_id":"4405c39e85274857bbef58e013a08859","user_id":"0921528165741295","active_name":"pageview","ip":"61.53.69.195","session_id":"9d6dc377216249e4a8f33a44eef7576d","req_url":"http://www.bigdataclass.com/my/0921528165741295"}
代码工具:intellij idea, maven,jdk1.8
操作步骤:
- 配置 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>netease.bigdata.course</groupId>
<artifactId>etl</artifactId>
<version>1.0-SNAPSHOT</version> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.6</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.4</version>
</dependency>
</dependencies> <build>
<sourceDirectory>src/main</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>
jar-with-dependencies
</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin> </plugins>
</build> </project>
2.编写主类这里为了简化代码量,我将方法类和执行类都写在ParseLogJob.java类中
package com.bigdata.etl.job; import com.alibaba.fastjson.JSONObject;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat; public class ParseLogJob extends Configured implements Tool {
//日志解析函数 (输入每一行的值)
public static Text parseLog(String row) throws ParseException {
String[] logPart = StringUtils.split(row, "\u1111");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
long timeLog = dateFormat.parse(logPart[0]).getTime();
String activeName = logPart[1];
JSONObject bizData=JSONObject.parseObject(logPart[2]);
JSONObject logData = new JSONObject(); logData.put("active_name",activeName);
logData.put("time_log",timeLog);
logData.putAll(bizData);
return new Text(logData.toJSONString());
} //输入key类型,输入value类型,输出。。(序列化类型)
public static class LogMapper extends Mapper<LongWritable,Text,NullWritable,Text>{
//输入key值 输入value值 map运行的上下文变量
public void map(LongWritable key ,Text value ,Context context) throws IOException,InterruptedException{
try {
Text parseLog = parseLog(value.toString());
context.write(null,parseLog);
} catch (ParseException e) {
e.printStackTrace();
} }
} public int run(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration config = getConf();
Job job= Job.getInstance(config);
job.setJarByClass(ParseLogJob.class);
job.setJobName("parseLog");
job.setMapperClass(LogMapper.class);
//设置reduce 为0
job.setNumReduceTasks(0);
//命令行第一个参数作为输入路径
FileInputFormat.addInputPath(job,new Path(args[0]));
//第二个参数 输出路径
Path outPutPath = new Path(args[1]);
FileOutputFormat.setOutputPath(job,outPutPath);
//防止报错 删除输出路径
FileSystem fs = FileSystem.get(config);
if (fs.exists(outPutPath)){
fs.delete(outPutPath,true);
}
if (!job.waitForCompletion(true)){
throw new RuntimeException(job.getJobName()+"fail");
}
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new ParseLogJob(), args);
System.exit(res);
}
}
3.打包上传到服务器
4.执行程序
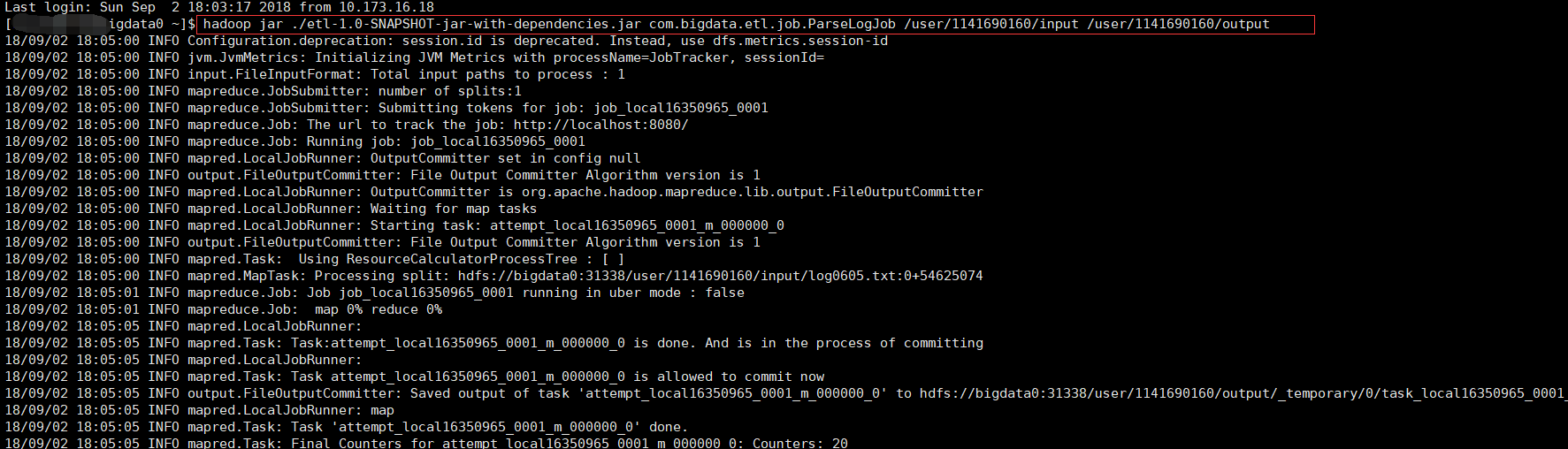
我们在hdfs 中创建了input和output做为输入输出路径
hadoop jar ./etl-1.0-SNAPSHOT-jar-with-dependencies.jar com.bigdata.etl.job.ParseLogJob /user/1141690160/input /user/1141690160/output
程序已经map完,因为我们没有对reduce进行操作,所以reduce为0
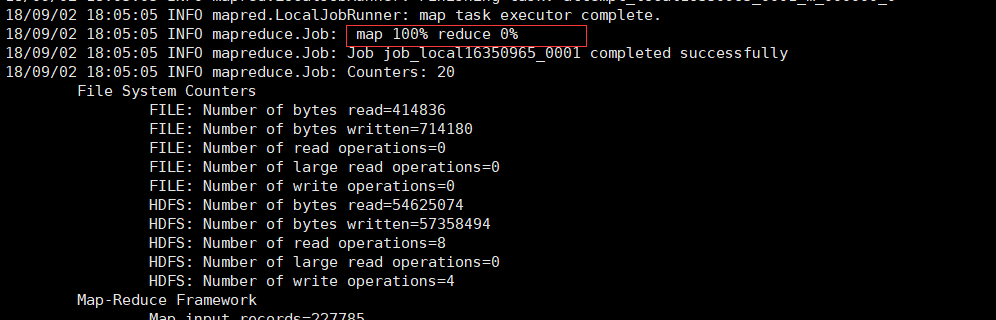
去hdfs 查看一下我们map完的文件

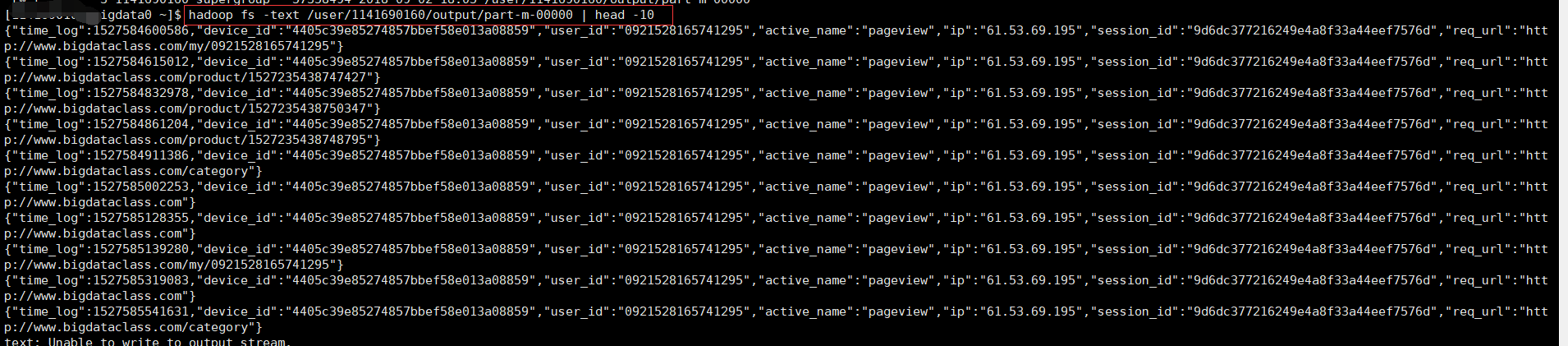
至此,一个简单的mr程序跑完了。
【原创】MapReduce实战(一)的更多相关文章
- MapReduce实战:邮箱统计及多输出格式实现
紧接着上一篇博文我们学习了MapReduce得到输出格式之后,在这篇博文里,我们将通过一个实战小项目来熟悉一下MultipleOutputs(多输出)格式的用法. 项目需求: 假如这里有一份邮箱数据文 ...
- MapReduce实战项目:查找相同字母组成的字谜
实战项目:查找相同字母组成的字谜 项目需求:一本英文书籍中包含有成千上万个单词或者短语,现在我们要从中找出相同字母组成的所有单词. 数据集和期望结果举例: 思路分析: 1)在Map阶段,对每个word ...
- MapReduce实战:统计不同工作年限的薪资水平
1.薪资数据集 我们要写一个薪资统计程序,统计数据来自于互联网招聘hadoop岗位的招聘网站,这些数据是按照记录方式存储的,因此非常适合使用 MapReduce 程序来统计. 2.数据格式 我们使用的 ...
- mapreduce实战:统计美国各个气象站30年来的平均气温项目分析
气象数据集 我们要写一个气象数据挖掘的程序.气象数据是通过分布在美国各地区的很多气象传感器每隔一小时进行收集,这些数据是半结构化数据且是按照记录方式存储的,因此非常适合使用 MapReduce 程序来 ...
- MapReduce实战--倒排索引
本文地址:http://www.cnblogs.com/archimedes/p/mapreduce-inverted-index.html,转载请注明源地址. 1.倒排索引简介 倒排索引(Inver ...
- MapReduce实战(三)分区的实现
需求: 在实战(一)的基础 上,实现自定义分组机制.例如根据手机号的不同,分成不同的省份,然后在不同的reduce上面跑,最后生成的结果分别存在不同的文件中. 对流量原始日志进行流量统计,将不同省份的 ...
- MapReduce实战:自定义输入格式实现成绩管理
1. 项目需求 我们取有一份学生五门课程的期末考试成绩数据,现在我们希望统计每个学生的总成绩和平均成绩. 样本数据如下所示,每行数据的数据格式为:学号.姓名.语文成绩.数学成绩.英语成绩.物理成绩.化 ...
- 《OD大数据实战》MapReduce实战
一.github使用手册 1. 我也用github(2)——关联本地工程到github 2. Git错误non-fast-forward后的冲突解决 3. Git中从远程的分支获取最新的版本到本地 4 ...
- MapReduce实战1
MapReduce编程规范: (1)用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端) (2)Mapper的输入数据是KV对的形式(KV的类型可自定义) ...
随机推荐
- zTree第五章,zTree的nodes数据例子
var nodes1 = [ { name: "小学", iconOpen: folderOpen, iconClose: folder, chkDisabled :true, c ...
- ReactNative之坑:停在gradle一直出点
问题: 初次安装好React Native 环境后,运行项目,会停留在下载 gradle 的界面一直出点 原因: 下载gradle一直不成功 解决方案: 可以根据提示的版本信息,手动下载,放在目录中, ...
- 基于iTop4412的FM收音机系统设计(一)
说明:第一版架构为:APP+JNI(NDK)+Driver(linux),优点是开发简单,周期短,也作为自己的毕业设计 现在更新第二版,FM服务完全植入Android系统中,成为系统服务,架构为:AP ...
- inline-block BUG问题
使用inline-block会使父元素高度不正常,要慎用!!!可以给父元素添加font-size:0解决,或者使用用float或者flex布局.
- unity+Helios制作360°全景VR视频
unity版本 unity2017.2.0 Helios版本:Helios 1.3.6 ffmpeg:ffmpeg-20180909-404d21f-win64-static(地址:https:// ...
- Django Rest Framework(阿奇)
Django Rest Framework 一. 什么是RESTful REST与技术无关,代表的是一种软件架构风格,REST是Representational State Transfer的简称,中 ...
- Binder Native 层(二)
Binder 框架及 Native 层 Binder机制使本地对象可以像操作当前对象一样调用远程对象,可以使不同的进程间互相通信.Binder 使用 Client/Server 架构,客户端通过服务端 ...
- word-wrap:表示是否允许流浪器断句,word-break:表示怎样断句
word-wrap: break-word的话,流浪器可以断句,但是是按单词形式断句. 而加上 word-break: break-all的话,单词内部也断句. "whiteSpace&qu ...
- 消息摘要java.security.MessageDigest
这是一种与消息认证码结合使用以确保消息完整性的技术.主要使用单向散列函数算法,可用于检验消息的完整性,和通过散列密码直接以文本形式保存等,目前广泛使用的算法有MD4.MD5.SHA-1,jdk1.5对 ...
- Android Gson解析复杂Json
JSON原数据 {"total":1,"rows":[{"ID":1,"Title":"台州初级中学招收初一年 ...