Hibernate 一对多,多对多,多对一检索策略
一.概述
我们先来谈谈检索数据时的两个问题:
1.不浪费内存 2.更好的检索效率
以上说的问题都是我们想要避免的,接下来就引出了我们要讨论的话题---------------hibernate检索策略
二.hibernate检索策略分为三种:
1.类级别的检索策略
2.一对多和多对多检索策略
3.多对一和一对一关联的检索策略
(1)类级别的检索策略分为立即检索和延迟检索,默认为延迟检索。
立即检索:立即加载检索方法指定的对象,立即发送SQL.
延迟检索:延迟加载检索方法指定的对象,在使用具体的对象时,再进行加载,发送SQL.
lazy有两个取值:false(立即加载) 和 true(延迟加载)
讨论一:当用get()方法检索数据时,在类级别检索策略不管是不是延迟加载都会立即检索
接下来看看代码实现是不是跟我说的一样:
配置文件中:
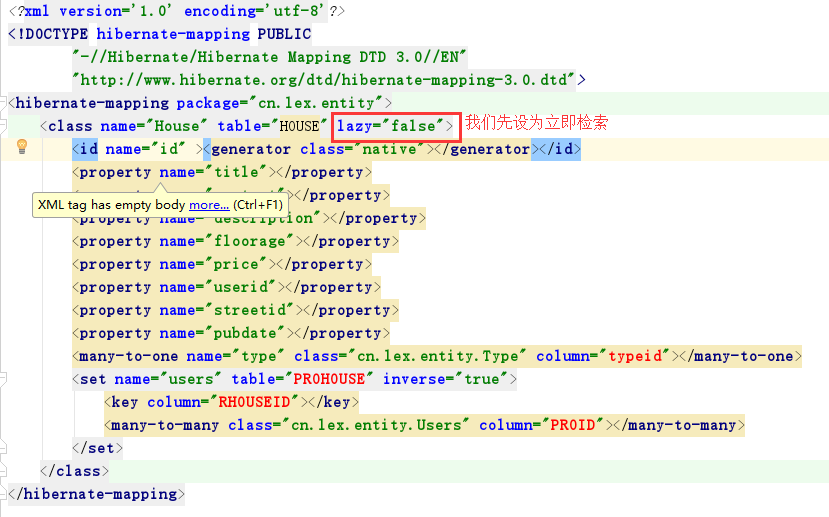
测试类代码:
@Test
public void select1(){
Session session = HibernateUtil.currentSession();
Transaction tx = session.beginTransaction();
House house = session.get(House.class, );
System.out.println("===========================");
// System.out.println(house.getType().getName());
tx.commit();
HibernateUtil.closeSession();
}
接下来看看测试的效果:

接下来我们把lazy设为true:

效果:

大家注意没,测试类有一行代码我是注释掉的,为的就是让我们很好的理解,如果我把下面的代码放开是什么效果呢?大家要注意现在我们的查询是get()方法:


我们得到的结果是一样的,这样就说明了当使用类级别检索时,使用get()方法都会立即加载。
讨论二:我们在来看看load()方法(也是类级别的检索),我们只需要修改代码即可:
@Test
public void select1(){
Session session = HibernateUtil.currentSession();
Transaction tx = session.beginTransaction();
House house = session.load(House.class, );
System.out.println("=========lazy:false==================");
//System.out.println(house.getType().getName());
tx.commit();
HibernateUtil.closeSession();
}
lazy:false时:

我们把lazy设为true时效果如下:
我们看到只打印了分割线,到这里我们可以看出get()和load()方法在类级别检索时的区别,接下来我们看看当放开注释的代码时会发生什么呢?


我们可以很直观的看出来,得到的结果不一样,当延迟加载的情况下,当我们有后续操作时才会向数据库发送SQL,查询结果。而立即加载在我们有后续操作之前,已经先查询了一道,然后再根据后续操作查询结果。
通过以上我们做的测试,我们可以得出一个结论:
当类级别检索时:get()方法不管延迟加载还是延迟加载都会先查询一道,有后续操作再向数据库发送SQL,得到结果。
load()方法:当是延迟加载的情况下,有后续操作才会向数据库发送SQL,查询结果。
当是立即加载的情况下,就和get()方法一样,先查询一道,有后续从操作在查询。
总的来说,load()方法受类级别检索策略影响,get()方法不受影响。
(2)一对多和多对多检索策略
在映射文件中,用<set>元素来配置一对多和多对多关联关系
lazy取值有:false(立即加载),true(延迟加载)和extra(加强延迟加载)
配置文件:
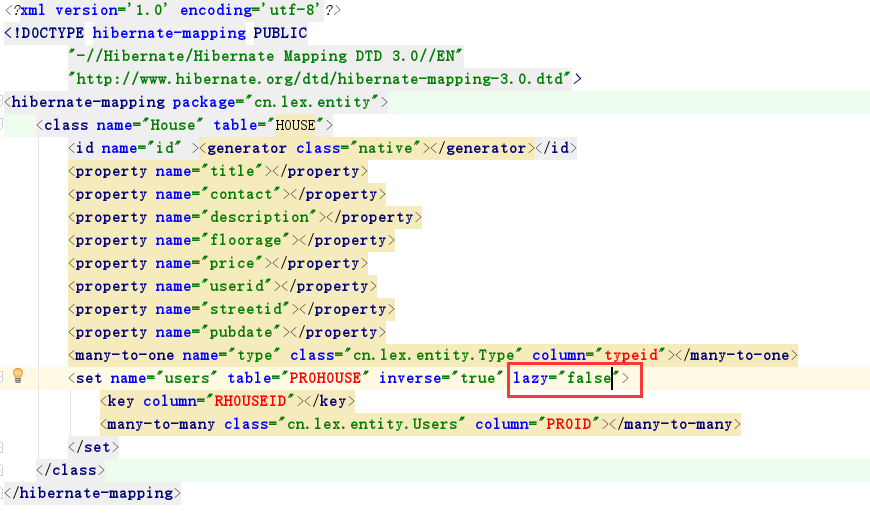
测试类代码:
@Test
public void select(){
Session session = HibernateUtil.currentSession();
Transaction tx = session.beginTransaction();
House house = session.load(House.class, 1);
System.out.println("==========lazy:false===================");
System.out.println(house.getClass());
// System.out.println(house.getTitle());
tx.commit();
HibernateUtil.closeSession();
}
先来看看当我们使用load()加载数据时,我们输出的结果:
当lazy取值为false:

当lazy取值为true:

都没有后续操作时,没有不同。接下来我们看一下当有后续操作时(解开注释的代码),会发生什么?
lazy:true时:

lazy为false时:

我们可以明显的看出这两个的不同,延迟加载时发送了一条SQL,立即加载时发送了两条SQL,延迟加载的后续操作是根据你的条件查询的,立即加载根据你的条件查询之后,如果有与之相关的表,也会进行两表查询。
get()方法获取时,没有后续操作:
lazy:true

lazy:false:
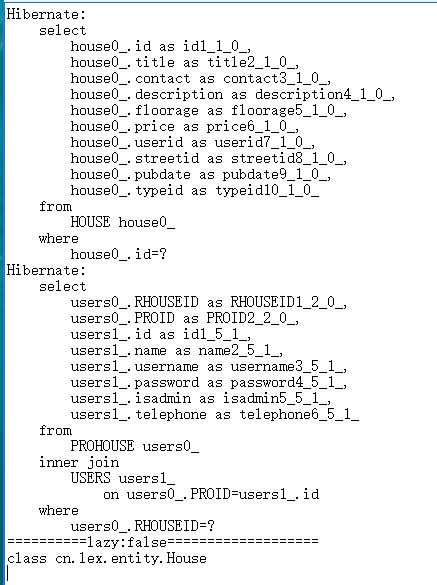
当有后续操作时,看看是什么情况?
lazy:true时,

lazy:false时,

由此可以看出,当使用get()方法时,不管有没有后续操作,都会先向数据库发送SQL语句,保存对象的信息,而且我们也看出来不管load()和get()在立即加载情况下,会向数据库发送SQL,根据你查询对象所关联的表的个数来决定向数据库发送几条SQL语句,(我列举的例子是发送两条)。
当lazy取值为extra(加强延迟加载),接下来的测试,我们主要探讨的是获取集合的size()时有什么不同:
配置文件:

测试类代码:
@Test
public void select(){
Session session = HibernateUtil.currentSession();
Transaction tx = session.beginTransaction();
Users users = session.get(Users.class, );
System.out.println("==========lazy:true===================");
System.out.println(users.getClass());
//System.out.println(users.getHouse().size());
tx.commit();
HibernateUtil.closeSession();
}
先来探讨没有后续操作时,get()和load()方法
get()方法:

load()方法:

当有后续操作时,get()和load()方法的结果:
get()方法:

load()方法:

当有后续操作时,get()和load()方法向数据库索要数据的语句相同。不同的是get()方法不管有没有后续操作都会向数据库发送SQL,
而load()方法是在你用到它的属性的时候才会向数据库发送SQL。
最后看一下当取值为true 和 false时语句有什么不同?
在延迟加载的情况下:
get()方法获取数据 load()方法获取数据
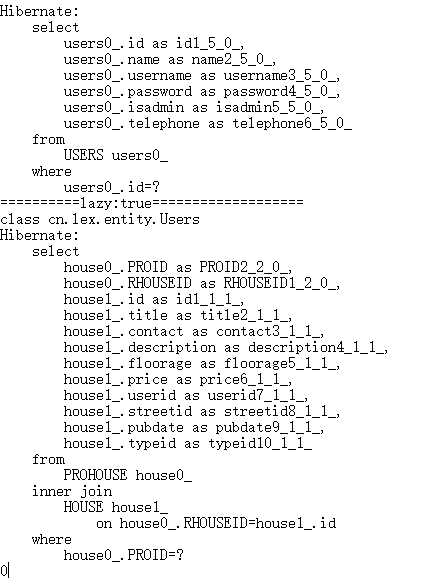
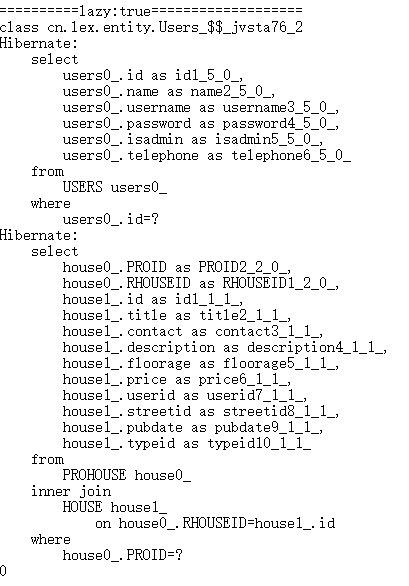
在立即加载的情况下:
get()方法加载数据: load()方法加载数据:

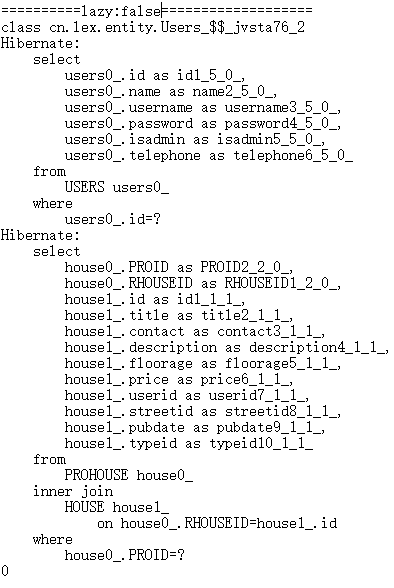
这里写的可能有点啰嗦了,但是总的一句话:
Extra:极其懒惰,只有访问集合对象的属性时才会加载,访问集合本身的属性时(例如,集合大小,生成count),不会立即加载。
最后来给大家总结一下:
类级别检索策略:仅仅适用于load()加载
好了,就讨论到这里吧,可能我写的也不是太好,这就需要自己下来多多练习,熟练实践.......
Hibernate 一对多,多对多,多对一检索策略的更多相关文章
- 攻城狮在路上(壹) Hibernate(十二)--- Hibernate的检索策略
本文依旧以Customer类和Order类进行说明.一.引言: Hibernate检索Customer对象时立即检索与之关联的Order对象,这种检索策略为立即检索策略.立即检索策略存在两大不足: A ...
- Hibernate的检索策略和优化
一.检索策略概述 当我们实现了一对多或者多对多的映射后,在检索数据库时需要注意两个问题: 1.使用尽可能小的内存:当 Hibernate 从数据库中加载一个客户信息时, 如果同时加载所有关联这个客户的 ...
- 【Hibernate】Hibernate系列5之检索策略
检索策略 5.1.类级别检索策略 5.2.set多对多.一对多检索策略 5.3.多对一.一对一检索策略 HQL作用: http://zhidao.baidu.com/link?url=dnAdJWR7 ...
- Hibernate 一对多/多对多
一对多关联(多对一): 一对多关联映射: 在多的一端添加一个外键指向一的一端,它维护的关系是一指向多 多对一关联映射: 咋多的一端加入一个外键指向一的一端,它维护的关系是多指向一 在配置文件中添加: ...
- 【Jpa hibernate】一对多@OneToMany,多对一@ManyToOne的使用
项目中使用实体之间存在一对多@OneToMany,多对一@ManyToOne的映射关系,怎么设置呢? GitHub地址:https://github.com/AngelSXD/myagenorderd ...
- hibernate一对多和多对一配置
public class Dept { private int deptId; private String deptName; // [一对多] 部门对应的多个员工 private Set<E ...
- Java进阶知识10 Hibernate一对多_多对一双向关联(Annotation+XML实现)
本文知识点(目录): 1.Annotation 注解版(只是测试建表) 2.XML版 的实现(只是测试建表) 3.附录(Annotation 注解版CRUD操作)[注解版有个问题:插入值时 ...
- hibernate(八) Hibernate检索策略(类级别,关联级别,批量检索)详解
序言 很多看起来很难的东西其实并不难,关键是看自己是否花费了时间和精力去看,如果一个东西你能看得懂,同样的,别人也能看得懂,体现不出和别人的差距,所以当你觉得自己看了很多书或者学了很多东西的时候,你要 ...
- Hibernate检索策略之延迟加载和立即加载
延迟加载:延迟加载(lazy load懒加载)是当在真正需要数据时,才执行SQL语句进行查询.避免了无谓的性能开销. 延迟加载分类: 1.类级别的查询策略 2.一对多和多对多关联的查询策略 3.多对 ...
随机推荐
- Flask 发布 1.0 稳定版
简评:现在都开始版本大跃进了吗?对,别看别人,说的就是你 pipenv(名单太长,待补齐...) Flask 其实早就已经十分稳定了,而在第一个 commit 大概 8 年之后,版本号才最终反映出了这 ...
- 二叉搜索树 思想 JAVA实现
二叉搜索树:一棵二叉搜索树是以一棵二叉树来组织的,这样一棵树可以使用链表的数据结构来表示(也可以采用数组来实现).除了key和可能带有的其他数据外,每个节点还包含Left,Right,Parent,它 ...
- C++默认构造函数的问题
C++ defaul construct :缺省构造函数(默认构造函数) 定义:第一种 构造函数没有参数,即是 A()形式的 第二种 构造函数的全部参数由缺省值提供,A(int a=0,int ...
- 四大算法解决最短路径问题(Dijkstra+Bellman-ford+SPFA+Floyd)
什么是最短路径问题? 简单来讲,就是用于计算一个节点到其他所有节点的最短路径. 单源最短路算法:已知起点,求到达其他点的最短路径. 常用算法:Dijkstra算法.Bellman-ford算法.SPF ...
- POJ_3268 Silver Cow Party 【最短路】
一.题面 POJ3268 二.分析 该题的意思就是给定了一个由每个节点代表农场的有向图,选定一个农场X办party,其余农场的都要去,每个农场的cow都走最短路,走的时间最久的cow耗时多少. 了解题 ...
- WebFrom页面绑定数据过于冗长的处理方法
嘛 这个是当时写完东西之后 功能没什么问题 但是由于页面绑定的数据太长 破坏了整体的样式(对于本人来说 样式就是浮云....) 所以测试就跟我说必须弄好看点 于是乎 我就找到了下面这种方法 因为我这 ...
- 服务器重启后Jenkins项目部分丢失问题解决方法
1.进入webapps/jenkins/WEB-INF目录下,vi web.xml 2.修改 HUDSON_HOME下的value为/root/.jenkins 3.重启Jenkins:http:/ ...
- Jmeter使用指南----压力测试工具
来源: https://blog.csdn.net/u012111923/article/details/80705141 https://www.cnblogs.com/st-leslie/p/51 ...
- Oracle 删除监听程服务
1.开始->运行->输入regidit ->->->->->红框内的右键删除 2.开始->运行->输入regidit ->->-> ...
- 014-CallbackServlet代码
package ${enclosing_package}; import java.io.IOException; import java.util.ResourceBundle; import ja ...