python字符编码与解码 unicode,str
解释以下几个问题:
(1)python2中str和unicode是两种字符串类型,与字符编码方式是什么关系?
(2)str和unicode是怎么相互转换的?
(3)'\x...';'\u...', '\U...'; u'...',u'\u...',u'\U...'这些都是什么意思?
(4)字符“汉”在str类型下显示为 '\xe6\xb1\x89',在unicode类型下为啥是这样: u'\u6c49',两者之间什么关系?
(5)unicode-escape又是啥?
回答如下:
一、字符编码
首先一点是“字符编码”(charcater coding)问题,即每个字符与某个数值(编码)的一一映射,
称为码位值(code point or code position)。早期的ASCII编码用8位二进制(一个字节),
即数值0~255范围编码了128个字符,因为英文字母就那26个,加上大小写以及一些标点符号,也够用了。
但是各国语言符号多种多样,0~255范围显然不够用,于是又有了GBK等各种编码,
最后,为了编码所有的字符,产生了统一标准:Unicode(此Unicode非pyhton中的unicode类型),
各种字符都能在Unicode中找到对应的码位值。
注:在下文中,各种进制用英文缩写代替:十进制:DEC,十六进制:HEX, 二进制:BIN。
比如,汉字字符“汉”在Unicode下的码位值为:
| DEC | 27721 |
| HEX | 6c49 |
| BIN | 0110 1100 0100 1001 |
接下来的问题就是,Unicode具体怎样存储和传输,如果用两个字节,最大就是65535,汉字据说有超过十万个,
再加上其他语言的字符,这显然不够,需要更多字节。Unicode有两种格式:UCS-2和UCS-4,UCS-2就是用2个字节,
UCS-4用4个字节,4个字节最大可达42亿,应该是够了。但是,假如为了涵盖各种字符编码,每个字符都用4个字节,
那在存储和传输中就浪费了大量空间,比如英文字母只需一个字节,而字符“汉”只需两个字节。为了节省空间,
变长编码应运而生,但是计算机在读取二进制编码时,怎么知道一个字符该读几个字节,这就需要把字符所需字节数的信息
也编码到二进制中,UTF-8就是这样的编码。
在UTF-8中,对于单字节字符,UTF-8兼容ASCII,两者编码相同;对于多字节字符,字节数的信息编码在第一个字节中,
字节数用1的个数表示,再用0隔开,接着是原来的Unicode编码,后面每个字节均以10开头,具体如下所示:
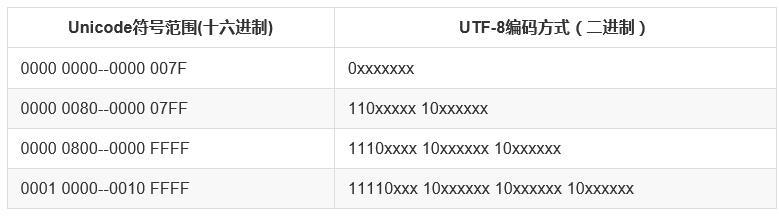
还是以字符“汉”为例,来对比下Unicode编码和UTF-8编码,
其中,utf8二进制前4个数为1110,即表示此字符占用三个字节:
| Unicode(HEX) | 6c 49 |
| Unicode(BIN) | , |
| UTF-8(BIN) | 1110 , 1011 , 10 |
| UTF-8(HEX) | e6 b1 89 |
二、str和unicode
python2中的str和unicode是两种字符串类型(class)。
unicode就是以Unicode编码为基础的字符串类型,赋值格式为u'xxx',
相较于一般的字符串赋值,多了一个前缀"u",还是以字符“汉”为例,我看到的格式有三种:
# === 第一种,直接是字符 ===
In [10]: u'汉'
Out[10]: u'\u6c49'
In [11]: print u'汉'
汉 # === 第二种,双字节十六进制,\u小写 ===
In [14]: u'\u6c49'
Out[14]: u'\u6c49'
In [15]: print u'\u6c49'
汉 # === 第三种,四字节十六进制,\U大写 ===
In [16]: u'\U00006c49'
Out[16]: u'\u6c49'
In [17]: print u'\U00006c49'
汉
注意如果把第三种中的4个0省掉,会报错。
str是另一种字符串,用于存储和传输的编码字符串,因此不同于unicode类型,
unicode类型字符串需要经过再次编码(encode)得到str类型字符串。
In [19]: su = u'汉'
In [20]: su
Out[20]: u'\u6c49'
In [21]: s = su.encode('utf8')
In [22]: s
Out[22]: '\xe6\xb1\x89' # 三个字节构成
In [23]: print s
汉
In [24]: sg = su.encode('gbk')
In [25]: sg
Out[25]: '\xba\xba' # 两个字节构成
In [26]: print sg
ºº # 环境默认编码不是gbk,因此显示乱码 In [30]: len(su)
Out[30]: 1
In [31]: len(s)
Out[31]: 3
In [32]: len(sg)
Out[32]: 2
反过来,str也可以解码(decode)得到unicode类型。(这里的“\x”是十六进制转义的意思,后面跟的是十六进制数字)
In [34]: s.decode('utf8')
Out[34]: u'\u6c49'
In [35]: print s.decode('utf8')
汉
In [36]: sg.decode('gbk')
Out[36]: u'\u6c49'
In [37]: print sg.decode('gbk')
汉
即:
str -- (decode) --> unicode
unicode -- (encode) --> str
还有一个问题,字符串'\u6c49'是什么意思,注意这里的'\u6c49'是str类型。
In [40]: ss = '\u6c49'
In [41]: ss
Out[41]: '\\u6c49'
In [42]: print ss
\u6c49 In [44]: ss.decode('unicode-escape')
Out[44]: u'\u6c49' In [45]: print ss.decode('unicode-escape')
汉
这其实表示的是unicode-escape编码的str变量,类似的还有'\U00006c49':
In [52]: ss = '\U00006c49'
In [55]: ss.decode('unicode-escape')
Out[55]: u'\u6c49'
In [56]: print ss.decode('unicode-escape')
汉
完毕。
参考文章
【1】字符编码笔记:ASCII,Unicode和UTF-8 by 阮一峰
【2】 https://www.zhihu.com/question/31833164 关注刘志军的回答
【3】 http://www.pitt.edu/~naraehan/python2/unicode.html handling unicode.
python字符编码与解码 unicode,str的更多相关文章
- 【转】python 字符编码与解码——unicode、str和中文:UnicodeDecodeError: 'ascii' codec can't decode
原文网址:http://blog.csdn.net/trochiluses/article/details/16825269 摘要:在进行python脚本的编写时,如果我们用python来处理网页数据 ...
- Python字符编码详解,str,bytes
什么是明文 “明文”是可以是文本,音乐,可以编码成mp3文件.明文可以是图像的,可以编码为gif.png或jpg文件.明文是电影的,可以编码成wmv文件.不一而足. 什么是编码?把明文变成计算机语言 ...
- 【ABAP系列】SAP ABAP 字符编码与解码、Unicode
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[ABAP系列]SAP ABAP 字符编码与解码 ...
- Python 字符编码 zz
http://www.cnblogs.com/huxi/archive/2010/12/05/1897271.html 1. 字符编码简介 1.1. ASCII ASCII(American Stan ...
- Python字符编码详解
1. 字符编码简介 1.1. ASCII ASCII(American Standard Code for Information Interchange),是一种单字节的编码.计算机世界里一开始只有 ...
- 【转】Python字符编码详解
转自:http://www.cnblogs.com/huxi/archive/2010/12/05/1897271.html 1. 字符编码简介 1.1. ASCII ASCII(American S ...
- Python字符编码讲解
声明:本文参考 Python字符编码详解 在计算机中我们不管用什么语言和程序,最终数据在计算机中的都是字节码(也就是01形式)的形式存在的,如果 计算机直接把字节码显示在屏幕上,很明显一般人看不懂字节 ...
- Python2/3的中、英文字符编码与解码输出: UnicodeDecodeError: 'ascii' codec can't decode/encode
摘要:Python中文虐我千百遍,我待Python如初恋.本文主要介绍在Python2/3交互模式下,通过对中文.英文的处理输出,理解Python的字符编码与解码问题(以点破面). 前言:字符串的编码 ...
- 深入理解Python字符编码--转
http://blog.51cto.com/9478652/2057896 不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久,你一定遇到过UnicodeEncodeError ...
随机推荐
- bzoj2064: 分裂(集合DP)
......咸鱼了将近一个月,因为沉迷ingress作业越来越多一直没时间搞OI呜呜呜 题目大意:有一个初始集合(n个元素)和一个目标集合(m个元素)(1<=n,m<=10),两个操作 ...
- [PKUWC2018]随机算法
题意:https://loj.ac/problem/2540 给定一个图(n<=20),定义一个求最大独立集的随机化算法 产生一个排列,依次加入,能加入就加入 求得到最大独立集的概率 loj25 ...
- Widows与linux关于隐形文件和非隐形文件の对比
Widows与linux关于隐形文件和非隐形文件の对比 对于windows来说 ,它本身有一些隐藏文件,为了防止一些菜鸟不小心把电脑的主要文件删除,还有就是里面存放一些你不知道的后门. 对此我们一些同 ...
- supervisor安装、配置和运行
supervisor是python写的进程管理工具,supervisor能够批量对进程执行启动,停止,重启等操作,有效提高了运维效率.注意supervisor只能管理前台进程,supervisor会自 ...
- lightoj 1245
lightoj 1245 Harmonic Number (II) 题意:给定一个 n ,求 n/1 + n/2 + …… + n/n 的值(这里的 "/" 是计算机的整数除法,向 ...
- HDU1711 KMP(模板题)
Number Sequence Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- [Luogu 2604] ZJOI2010 网络扩容
[Luogu 2604] ZJOI2010 网络扩容 第一问直接最大流. 第二问,添加一遍带费用的边,边权 INF,超级源点连源点一条容量为 \(k\) 的边来限流,跑费用流. 大约是第一次用 nam ...
- 在vsagent上运行.dll录制文件。
https://msdn.microsoft.com/en-us/library/ms182487.aspx 1. cd C:\Program Files (x86)\Microsoft Visual ...
- Bzoj2832 / Bzoj3874 宅男小C
Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 124 Solved: 26 Description 众所周知,小C是个宅男,所以他的每天的食物要靠外 ...
- max_element和min_element的用法
首先,max_element和min_elemetn看字面意思是求最大值和最小值,这个确实是这个意思.不过,需要注意的是,他返回的是最大值(最小值)的地址,而非最大值(最小值).对于一般数组的用法则是 ...