pandas模块(数据分析)------dataframe
DataFrame
DataFrame是一个表格型的数据结构,含有一组有序的列,是一个二维结构。
DataFrame可以被看做是由Series组成的字典,并且共用一个索引。
一、生成方式
import numpy as np
import pandas as pd
a=pd.DataFrame({'one':pd.Series([1,2,3],index=['a','b','c']), 'two':pd.Series([1,2,3,4],index=['b','a','c','d'])})
a

可以看出 有one和two两个Series组成,并且共用一组索引a,b,c,d
# 字典方式创建
b=pd.DataFrame({"today":[12,43,23,123],"tomory":[23,45,34,23]})
b

# 自定义索引
c=pd.DataFrame({"today":[12,43,23,123],"tomory":[23,45,34,23]},index=list("abcd"))
c

二、csv文件读取与写入
df = pd.read_csv("d:/601318.csv")
df

2470 rows × 8 columns
x=open("d:/601318.csv")
df=pd.read_csv(x)
df


2470 rows × 8 columns
# 保存到文件
df.to_csv("d:/new.csv") # index 获取行索引
df.index RangeIndex(start=0, stop=2470, step=1) a.index Index(['a', 'b', 'c', 'd'], dtype='object') # 返回列索引
df.columns Index(['id', 'date', 'open', 'close', 'high', 'low', 'volume', 'code'], dtype='object') # values 返回二维数组
df.values array([
[0, '2007/3/1', 22.074, ..., 20.22, 1977633.51, 601318],
[1, '2007/3/2', 20.75, ..., 20.256, 425048.32, 601318],
[2, '2007/3/5', 20.3, ..., 19.218, 419196.74, 601318],
...,
[2467, '2017/7/28', 52.2, ..., 51.8, 491294.0, 601318],
[2468, '2017/7/31', 51.88, ..., 51.41, 616005.0, 601318],
[2469, '2017/8/1', 52.2, ..., 52.2, 1147936.0, 601318]
],
dtype=object) # 倒置 行和列交换 a.T

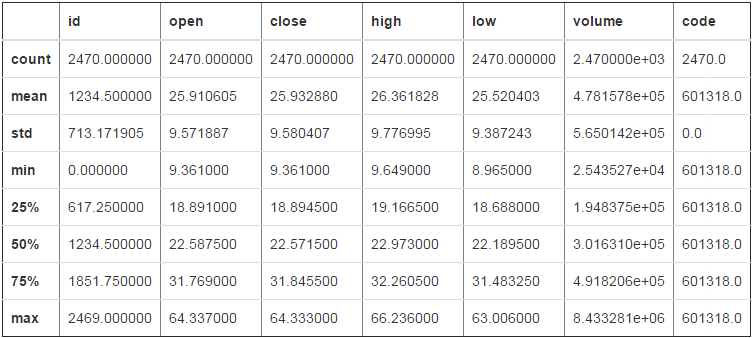
# describe 按列打印一些统计信息 df.describe()
# df 的columns 和index都有name属性 # 上面的数据中的index的name还没有值,可以设置一个
df.index.name='indexname'
df

2470 rows × 8 columns
#获取第一列的name
df.columns[0]
'id' df.columns[1]
'date' # 给列重命名,并没有修改原数据,这是下面是返回的数据
df.rename(columns={"close":"newclose","low":"newlow"})



2470 rows × 8 columns
三、索引和切片
df[0]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
d:\program files (x86)\python35\lib\site-packages\pandas\core\indexes\base.py in get_loc(self, key, method, tolerance)
2441 try:
-> 2442 return self._engine.get_loc(key)
2443 except KeyError:
pandas\_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc (pandas\_libs\index.c:5280)()
pandas\_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc (pandas\_libs\index.c:5126)()
pandas\_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item (pandas\_libs\hashtable.c:20523)()
pandas\_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item (pandas\_libs\hashtable.c:20477)()
KeyError: 0
During handling of the above exception, another exception occurred:
KeyError Traceback (most recent call last)
<ipython-input-18-9ae93f22b889> in <module>()
----> 1 df[0]
d:\program files (x86)\python35\lib\site-packages\pandas\core\frame.py in __getitem__(self, key)
1962 return self._getitem_multilevel(key)
1963 else:
-> 1964 return self._getitem_column(key)
1965
1966 def _getitem_column(self, key):
d:\program files (x86)\python35\lib\site-packages\pandas\core\frame.py in _getitem_column(self, key)
1969 # get column
1970 if self.columns.is_unique:
-> 1971 return self._get_item_cache(key)
1972
1973 # duplicate columns & possible reduce dimensionality
d:\program files (x86)\python35\lib\site-packages\pandas\core\generic.py in _get_item_cache(self, item)
1643 res = cache.get(item)
1644 if res is None:
-> 1645 values = self._data.get(item)
1646 res = self._box_item_values(item, values)
1647 cache[item] = res
d:\program files (x86)\python35\lib\site-packages\pandas\core\internals.py in get(self, item, fastpath)
3588
3589 if not isnull(item):
-> 3590 loc = self.items.get_loc(item)
3591 else:
3592 indexer = np.arange(len(self.items))[isnull(self.items)]
d:\program files (x86)\python35\lib\site-packages\pandas\core\indexes\base.py in get_loc(self, key, method, tolerance)
2442 return self._engine.get_loc(key)
2443 except KeyError:
-> 2444 return self._engine.get_loc(self._maybe_cast_indexer(key))
2445
2446 indexer = self.get_indexer([key], method=method, tolerance=tolerance)
pandas\_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc (pandas\_libs\index.c:5280)()
pandas\_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc (pandas\_libs\index.c:5126)()
pandas\_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item (pandas\_libs\hashtable.c:20523)()
pandas\_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item (pandas\_libs\hashtable.c:20477)()
KeyError: 0
df["close"]
indexname
0 20.657
1 20.489
2 19.593
3 19.977
4 20.520
5 20.273
6 20.101
7 19.739
8 19.818
9 19.841
10 19.849
11 19.960
12 20.211
13 19.911
14 20.026
15 19.938
16 20.282
17 20.269
18 20.565
19 20.927
20 20.772
21 21.364
22 21.284
23 21.099
24 21.156
25 21.196
26 22.785
27 23.319
28 23.637
29 23.593
...
2440 48.896
2441 48.609
2442 49.183
2443 49.183
2444 49.381
2445 48.085
2446 49.420
2447 49.074
2448 48.411
2449 47.403
2450 49.876
2451 50.835
2452 50.459
2453 50.578
2454 51.230
2455 50.610
2456 51.630
2457 52.770
2458 53.900
2459 53.470
2460 53.840
2461 54.010
2462 51.960
2463 52.610
2464 52.310
2465 51.890
2466 52.360
2467 51.890
2468 52.020
2469 54.850
Name: close, Length: 2470, dtype: float64
从上边可以看出,[]里边似乎要用来选择列才可以(后面知道,切片也可以)
# 花式索引 df[["close","low"]]


2470 rows × 2 columns
df["close"][0] 20.656999999999996
df[“close”] 先得到一个Series,然后 再用标签索引0去查找
df[["close","low"]][0]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
d:\program files (x86)\python35\lib\site-packages\pandas\core\indexes\base.py in get_loc(self, key, method, tolerance)
2441 try:
-> 2442 return self._engine.get_loc(key)
2443 except KeyError:
pandas\_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc (pandas\_libs\index.c:5280)()
pandas\_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc (pandas\_libs\index.c:5126)()
pandas\_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item (pandas\_libs\hashtable.c:20523)()
pandas\_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item (pandas\_libs\hashtable.c:20477)()
KeyError: 0
During handling of the above exception, another exception occurred:
KeyError Traceback (most recent call last)
<ipython-input-22-7ed9e36ec1ab> in <module>()
----> 1 df[["close","low"]][0]
d:\program files (x86)\python35\lib\site-packages\pandas\core\frame.py in __getitem__(self, key)
1962 return self._getitem_multilevel(key)
1963 else:
-> 1964 return self._getitem_column(key)
1965
1966 def _getitem_column(self, key):
d:\program files (x86)\python35\lib\site-packages\pandas\core\frame.py in _getitem_column(self, key)
1969 # get column
1970 if self.columns.is_unique:
-> 1971 return self._get_item_cache(key)
1972
1973 # duplicate columns & possible reduce dimensionality
d:\program files (x86)\python35\lib\site-packages\pandas\core\generic.py in _get_item_cache(self, item)
1643 res = cache.get(item)
1644 if res is None:
-> 1645 values = self._data.get(item)
1646 res = self._box_item_values(item, values)
1647 cache[item] = res
d:\program files (x86)\python35\lib\site-packages\pandas\core\internals.py in get(self, item, fastpath)
3588
3589 if not isnull(item):
-> 3590 loc = self.items.get_loc(item)
3591 else:
3592 indexer = np.arange(len(self.items))[isnull(self.items)]
d:\program files (x86)\python35\lib\site-packages\pandas\core\indexes\base.py in get_loc(self, key, method, tolerance)
2442 return self._engine.get_loc(key)
2443 except KeyError:
-> 2444 return self._engine.get_loc(self._maybe_cast_indexer(key))
2445
2446 indexer = self.get_indexer([key], method=method, tolerance=tolerance)
pandas\_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc (pandas\_libs\index.c:5280)()
pandas\_libs\index.pyx in pandas._libs.index.IndexEngine.get_loc (pandas\_libs\index.c:5126)()
pandas\_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item (pandas\_libs\hashtable.c:20523)()
pandas\_libs\hashtable_class_helper.pxi in pandas._libs.hashtable.PyObjectHashTable.get_item (pandas\_libs\hashtable.c:20477)()
KeyError: 0
之所以报错,是因为df[[“close”,“low”]]得到的是一个DataFrame类型,它再加[],[]里边只能是列
# 切片,这个时候解释的就是行 df[0:10]
推荐使用loc和iloc索引
# 在loc里边,逗号左边表示行,右边表示列 # 在这里的0:10被解释为标签(不是行的下标)
ddf=df.loc[3:10,["close","low"]]
ddf

# 那我现在想拿到ddf里,"low"列,第5行的数据 # ddf["low"]得到的是一个Series,其索引是整数的,所以必须使用iloc指明使用下标取值
ddf["low"].iloc[4] 19.646000000000001
布尔值索引
# 过滤某一列 df[df["close"]<20]
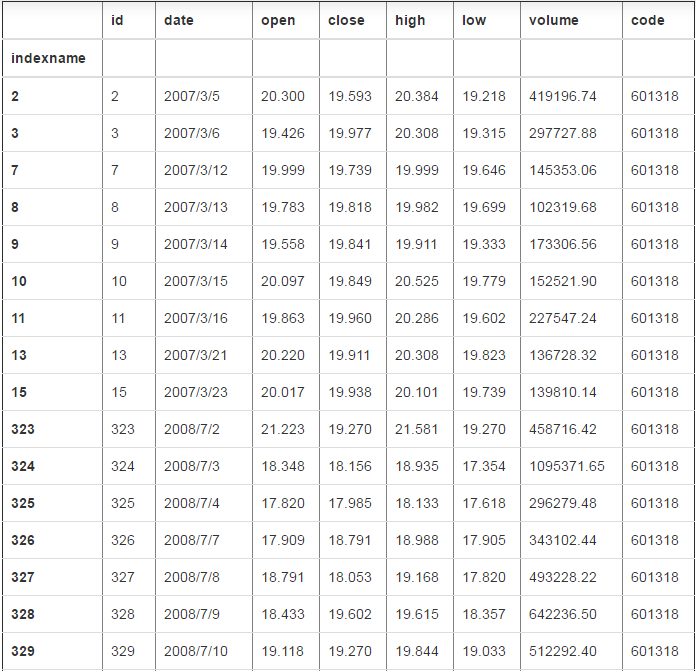

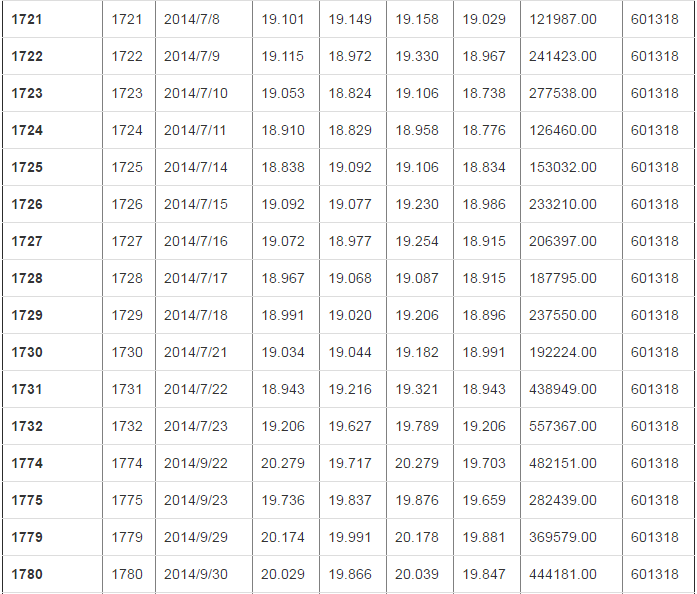

856 rows × 8 columns
# 过滤所有的位置 # dataframe会将所有位置上小于20的设置为nan(因为其不能确定该怎么舍弃数据,不可能因为一行中一个nan就删除整个一行或者一列) df[df<20]
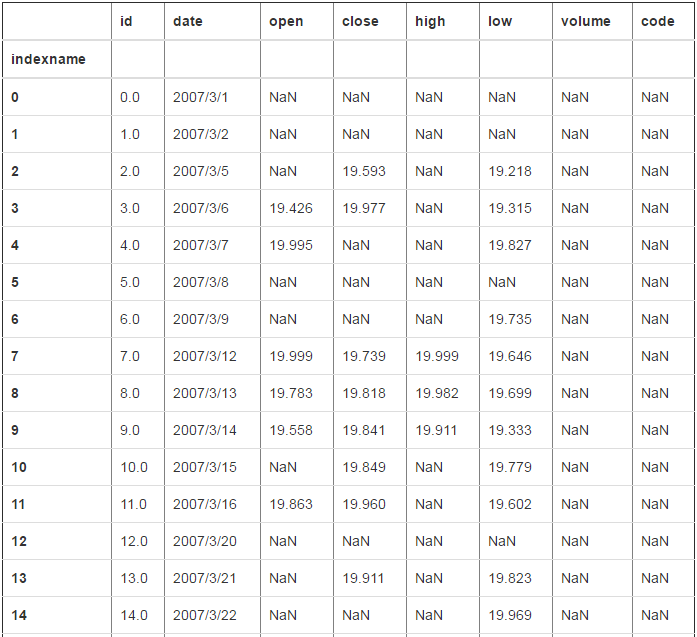

2470 rows × 8 columns
# 将所有小于20的值改为0 # 请注意这里,会将为False的位置改为0,所以我们要写大于20,这样的话小于20的才是False
df[df>20].fillna(0)


2470 rows × 8 columns
# 选择date 为2017/7/25 和2017/7/3 的值 # 这里的date是字符串类型,不是datetime类型 df[(df["date"]=="2017/7/25") | (df["date"]=="2017/7/3")]

# 这里还可以用isin方法去过滤一个范围 df[df["date"].isin(["2017/7/25","2017/7/3"])]

df[df["high"].isin([53.050,54.150])]

修改值的时候要注意类型的问题
# 比如要将所有小于20的位置变为0 # 做法一:
df[df>20].fillna(0) # 做法二:等号赋值
df[df<20]=0
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-45-ea838d192259> in <module>()
5
6 # 做大二:等号赋值
----> 7 df[df<20]=0
d:\program files (x86)\python35\lib\site-packages\pandas\core\frame.py in __setitem__(self, key, value)
2326 self._setitem_array(key, value)
2327 elif isinstance(key, DataFrame):
-> 2328 self._setitem_frame(key, value)
2329 else:
2330 # set column
d:\program files (x86)\python35\lib\site-packages\pandas\core\frame.py in _setitem_frame(self, key, value)
2362 raise TypeError('Must pass DataFrame with boolean values only')
2363
-> 2364 self._check_inplace_setting(value)
2365 self._check_setitem_copy()
2366 self._where(-key, value, inplace=True)
d:\program files (x86)\python35\lib\site-packages\pandas\core\generic.py in _check_inplace_setting(self, value)
3197 pass
3198
-> 3199 raise TypeError('Cannot do inplace boolean setting on '
3200 'mixed-types with a non np.nan value')
3201
TypeError: Cannot do inplace boolean setting on mixed-types with a non np.nan value
报错的原因是因为,date这列是字符串类型,设置为0,类型转换失败
# 现在通过切片,去掉date列,看能否转换成功 df2=df.loc[:10,"open":"code"]
df2

df2[df2<20]=0
df2

可以看出,如果列里边没有字符串类型,是可以转换成功的
四、数据对齐和数据缺失
df3=df + df2
df3

2470 rows × 8 columns
新的数据,列和行都要对齐,列date和id都是nan,是因为df2中没有这两列,这些其实跟Series的道理是一样的
处理缺失数据的相关方法:
- dropna() 过滤掉值为NaN的行
- fillna() 填充缺失数据
- isnull() 返回布尔数组,缺失值对应为True
- notnull() 返回布尔数组,缺失值对应为False
跟Series的方法是一样的
df3.dropna()

在这里,dropna默认的规则,只要行里有nan,就会清除掉整行,但是可以设置参数去改变
df3.dropna(how="any") ---->默认是any,只要有nan就删除;how='all'的话,就是行里全是nan才删除
那如果我想对列进行操作,就还需要另外一个才做,要记住默认的规则是对行的
df3.dropna(how="any",axis=0)--->axis默认等于0,表示是对行进行规则,axis=1的话,就表示对列进行规则
- df3.dropna(how="any",axis=0)--->清除掉行里含有nan的行
- df3.dropna(how="all",axis=0)--->清除掉行里都是nana的行
- df3.dropna(how="any",axis=1)--->清除掉列里含有nan的列
- df3.dropna(how="all",axis=1)--->清除掉列里都是nana的列
# 将位置是nan的地方替换为0 df3.fillna(0)


2470 rows × 8 columns
五、常用函数
mean 得出每个列的平均值
df2.mean()
open 11.258000
close 9.276364
high 15.107000
low 5.513000
volume 388403.913636
code 601318.000000
dtype: float64
# 单列的平均值(Series) df2["close"].mean() 9.2763636363636355
sum 求出每列的和
字符串的话,就是字符串的拼接
df.sum()
id 3049215
date 2007/3/12007/3/22007/3/52007/3/62007/3/72007/3...
open 63999.2
close 64054.2
high 65113.7
low 63035.4
volume 1.18105e+09
code 1485255460
dtype: object
sort 排序
sort_index 按照索引排序(行索引和列索引)
ascending默认为True ,表示按照升序排序;False表示降序
axis为0 ,代表按行索引;1代表用列索引 - sort_index(ascending=False,axis=0) - sort_index(ascending=False,axis=0) - sort_index(ascending=False,axis=0) - sort_index(ascending=False,axis=0)
# ascending默认为True ,表示按照升序排序;False表示降序 df.sort_index(ascending=False)


2470 rows × 8 columns
# ascending默认为True ,表示按照升序排序;False表示降序 df.sort_index(ascending=False)



2470 rows × 8 columns
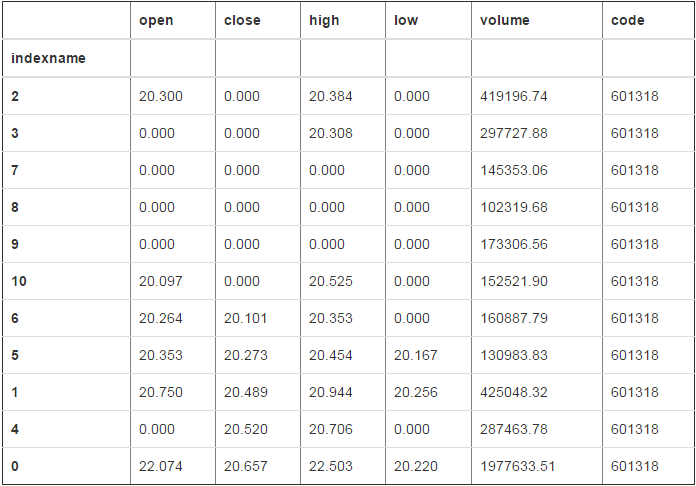
sort_values 按照值排序
# 按照close列升序排序
df2.sort_values("close")
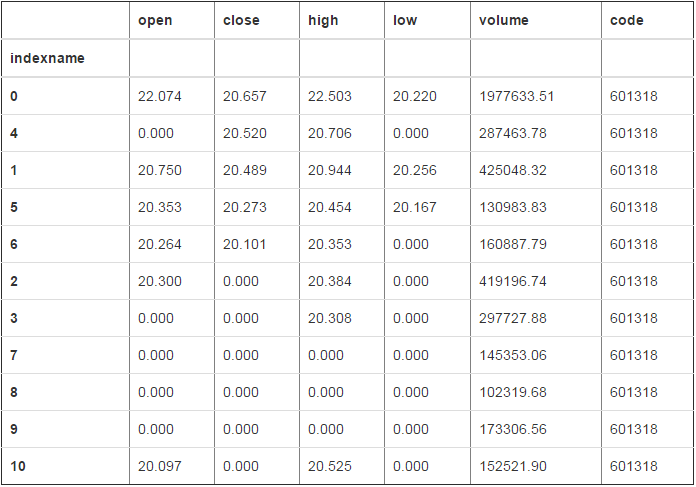
# 按照close列降序
df2.sort_values("close",ascending=False)
# 按照close列升序排序,如果有close值相同,再按照low列排序 df2.sort_values(["close","low"])

# axis=1,按照行排序,在这里一定要注意,必须保证这一行的数据类型是一致的,比如df中有字符串类型,就会报错 # df2 行类的数据类型都是一致的是没有问题的,第一个参数是说按照行的索引号,df中,0和1的结果就不一样
df2.sort_values(0,axis=1)
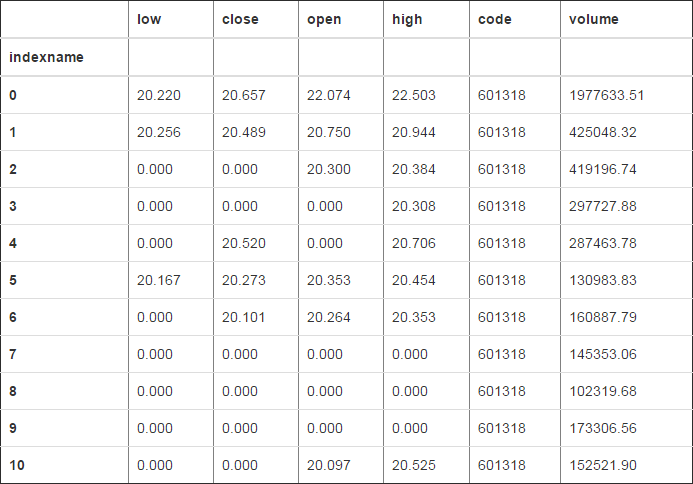
df2.sort_values(1,axis=1)

numpy的通用函数用眼适用于pandas
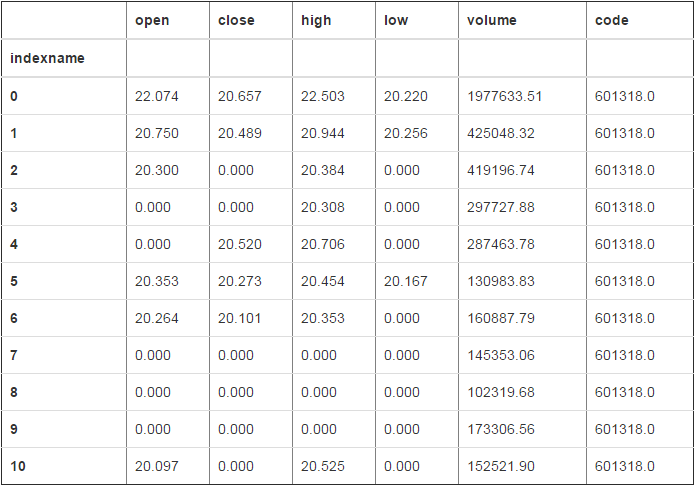
# 请主要类型 df.abs()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-98-db394c0c0cf4> in <module>()
1 # 请主要类型
2
----> 3 df.abs()
d:\program files (x86)\python35\lib\site-packages\pandas\core\generic.py in abs(self)
5661 abs: type of caller
5662 """
-> 5663 return np.abs(self)
5664
5665 def describe(self, percentiles=None, include=None, exclude=None):
TypeError: bad operand type for abs(): 'str'
df2.abs()
六、自定义函数
applymap(函数名),作用域DataFrame上,这个的函数的应用是针对于df里的每个位置去执行
apply(函数名),作用域DataFrame上,将操作应用于整列或者整行上(整行要修改axis=1)
map作用于Series上
import numpy as np import pandas as pd
df=pd.read_csv("d:/601318.csv")
df





2470 rows × 8 columns
df2=df.loc[:15,"close":"code"]
df2

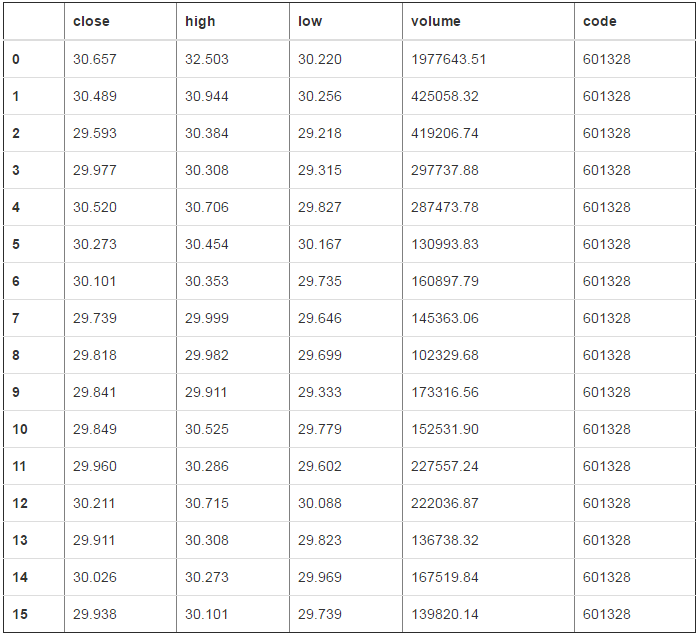
#df2中每个位置都是加10 df2.applymap(lambda x:x+10)
# map作用域Series df4=df2["close"]
df4.map(lambda x:x+100)
0 120.657
1 120.489
2 119.593
3 119.977
4 120.520
5 120.273
6 120.101
7 119.739
8 119.818
9 119.841
10 119.849
11 119.960
12 120.211
13 119.911
14 120.026
15 119.938
Name: close, dtype: float64
#apply 将操作应用到每一列上 df2.apply(lambda x:x.sum()+1)
close 321.903
high 328.752
low 317.416
volume 5166066.460
code 9621089.000
dtype: float64
#apply 将操作应用到每一行上 df2.apply(lambda x:x.sum()+1,axis=1)
pandas之dataframe(下)
自定义函数
applymap(函数名),作用域DataFrame上,这个的函数的应用是针对于df里的每个位置去执行 apply(函数名),作用域DataFrame上,将操作应用于整列或者整行上(整行要修改axis=1) map作用于Series上 import numpy as np import pandas as pd
df=pd.read_csv("d:/601318.csv")
df
id date open close high low volume code
0 0 2007/3/1 22.074 20.657 22.503 20.220 1977633.51 601318
1 1 2007/3/2 20.750 20.489 20.944 20.256 425048.32 601318
2 2 2007/3/5 20.300 19.593 20.384 19.218 419196.74 601318
3 3 2007/3/6 19.426 19.977 20.308 19.315 297727.88 601318
4 4 2007/3/7 19.995 20.520 20.706 19.827 287463.78 601318
5 5 2007/3/8 20.353 20.273 20.454 20.167 130983.83 601318
6 6 2007/3/9 20.264 20.101 20.353 19.735 160887.79 601318
7 7 2007/3/12 19.999 19.739 19.999 19.646 145353.06 601318
8 8 2007/3/13 19.783 19.818 19.982 19.699 102319.68 601318
9 9 2007/3/14 19.558 19.841 19.911 19.333 173306.56 601318
10 10 2007/3/15 20.097 19.849 20.525 19.779 152521.90 601318
11 11 2007/3/16 19.863 19.960 20.286 19.602 227547.24 601318
12 12 2007/3/20 20.662 20.211 20.715 20.088 222026.87 601318
13 13 2007/3/21 20.220 19.911 20.308 19.823 136728.32 601318
14 14 2007/3/22 20.066 20.026 20.273 19.969 167509.84 601318
15 15 2007/3/23 20.017 19.938 20.101 19.739 139810.14 601318
16 16 2007/3/26 19.955 20.282 20.397 19.946 223266.79 601318
17 17 2007/3/27 20.216 20.269 20.467 20.145 139338.19 601318
18 18 2007/3/28 20.264 20.565 20.706 20.123 258263.69 601318
19 19 2007/3/29 20.666 20.927 21.540 20.520 461986.18 601318
20 20 2007/3/30 20.732 20.772 21.134 20.626 144617.20 601318
21 21 2007/4/2 20.772 21.364 21.501 20.772 231445.03 601318
22 22 2007/4/3 21.377 21.284 21.527 21.147 132712.04 601318
23 23 2007/4/4 21.289 21.099 21.412 20.993 122454.69 601318
24 24 2007/4/5 21.103 21.156 21.191 20.838 122865.38 601318
25 25 2007/4/6 21.050 21.196 21.611 20.971 195208.52 601318
26 26 2007/4/9 21.231 22.785 22.909 21.059 462770.21 601318
27 27 2007/4/10 22.516 23.319 23.699 22.516 407823.90 601318
28 28 2007/4/11 23.346 23.637 24.361 23.222 243446.50 601318
29 29 2007/4/12 23.832 23.593 25.606 23.377 159270.43 601318
... ... ... ... ... ... ... ... ...
2440 2440 2017/6/21 47.778 48.896 49.025 47.046 849757.00 601318
2441 2441 2017/6/22 48.669 48.609 49.925 48.520 1146464.00 601318
2442 2442 2017/6/23 48.708 49.183 49.361 48.263 873719.00 601318
2443 2443 2017/6/26 49.450 49.183 50.222 48.817 953192.00 601318
2444 2444 2017/6/27 49.163 49.381 49.411 48.402 780835.00 601318
2445 2445 2017/6/28 49.163 48.085 49.203 48.026 691322.00 601318
2446 2446 2017/6/29 48.273 49.420 49.510 47.858 753228.00 601318
2447 2447 2017/6/30 49.262 49.074 49.658 48.748 598630.00 601318
2448 2448 2017/7/3 49.262 48.411 49.262 48.026 563199.00 601318
2449 2449 2017/7/4 48.273 47.403 48.313 47.393 683920.00 601318
2450 2450 2017/7/5 47.482 49.876 50.152 47.482 1272537.00 601318
2451 2451 2017/7/6 49.876 50.835 51.438 49.529 1137814.00 601318
2452 2452 2017/7/7 50.598 50.459 51.063 49.984 533925.00 601318
2453 2453 2017/7/10 50.469 50.578 51.399 50.143 570776.00 601318
2454 2454 2017/7/11 50.810 51.230 52.010 50.610 699539.00 601318
2455 2455 2017/7/12 51.360 50.610 52.500 50.420 870117.00 601318
2456 2456 2017/7/13 50.980 51.630 51.860 50.830 665342.00 601318
2457 2457 2017/7/14 51.690 52.770 52.790 51.300 707791.00 601318
2458 2458 2017/7/17 53.010 53.900 55.090 52.420 1408791.00 601318
2459 2459 2017/7/18 53.600 53.470 54.260 52.510 879029.00 601318
2460 2460 2017/7/19 53.680 53.840 54.480 53.110 771180.00 601318
2461 2461 2017/7/20 53.550 54.010 54.150 52.820 659198.00 601318
2462 2462 2017/7/21 53.200 51.960 53.280 51.900 1294791.00 601318
2463 2463 2017/7/24 52.080 52.610 53.100 51.680 904595.00 601318
2464 2464 2017/7/25 52.620 52.310 53.050 52.180 506834.00 601318
2465 2465 2017/7/26 52.100 51.890 52.500 51.280 657610.00 601318
2466 2466 2017/7/27 51.850 52.360 52.740 51.090 667132.00 601318
2467 2467 2017/7/28 52.200 51.890 52.460 51.800 491294.00 601318
2468 2468 2017/7/31 51.880 52.020 52.640 51.410 616005.00 601318
2469 2469 2017/8/1 52.200 54.850 54.900 52.200 1147936.00 601318
2470 rows × 8 columns df2=df.loc[:15,"close":"code"]
df2
close high low volume code
0 20.657 22.503 20.220 1977633.51 601318
1 20.489 20.944 20.256 425048.32 601318
2 19.593 20.384 19.218 419196.74 601318
3 19.977 20.308 19.315 297727.88 601318
4 20.520 20.706 19.827 287463.78 601318
5 20.273 20.454 20.167 130983.83 601318
6 20.101 20.353 19.735 160887.79 601318
7 19.739 19.999 19.646 145353.06 601318
8 19.818 19.982 19.699 102319.68 601318
9 19.841 19.911 19.333 173306.56 601318
10 19.849 20.525 19.779 152521.90 601318
11 19.960 20.286 19.602 227547.24 601318
12 20.211 20.715 20.088 222026.87 601318
13 19.911 20.308 19.823 136728.32 601318
14 20.026 20.273 19.969 167509.84 601318
15 19.938 20.101 19.739 139810.14 601318
#df2中每个位置都是加10 df2.applymap(lambda x:x+10)
close high low volume code
0 30.657 32.503 30.220 1977643.51 601328
1 30.489 30.944 30.256 425058.32 601328
2 29.593 30.384 29.218 419206.74 601328
3 29.977 30.308 29.315 297737.88 601328
4 30.520 30.706 29.827 287473.78 601328
5 30.273 30.454 30.167 130993.83 601328
6 30.101 30.353 29.735 160897.79 601328
7 29.739 29.999 29.646 145363.06 601328
8 29.818 29.982 29.699 102329.68 601328
9 29.841 29.911 29.333 173316.56 601328
10 29.849 30.525 29.779 152531.90 601328
11 29.960 30.286 29.602 227557.24 601328
12 30.211 30.715 30.088 222036.87 601328
13 29.911 30.308 29.823 136738.32 601328
14 30.026 30.273 29.969 167519.84 601328
15 29.938 30.101 29.739 139820.14 601328
# map作用域Series df4=df2["close"]
df4.map(lambda x:x+100) 0 120.657
1 120.489
2 119.593
3 119.977
4 120.520
5 120.273
6 120.101
7 119.739
8 119.818
9 119.841
10 119.849
11 119.960
12 120.211
13 119.911
14 120.026
15 119.938
Name: close, dtype: float64
#apply 将操作应用到每一列上 df2.apply(lambda x:x.sum()+1) close 321.903
high 328.752
low 317.416
volume 5166066.460
code 9621089.000
dtype: float64
#apply 将操作应用到每一行上 df2.apply(lambda x:x.sum()+1,axis=1) 0 2579015.890
1 1026429.009
2 1020574.935
3 899106.480
4 888843.833
5 732363.724
6 762266.979
7 746731.444
8 703698.179
9 774684.645
10 753901.053
11 828926.088
12 823406.884
13 738107.362
14 768889.108
15 741188.918
dtype: float64
# 层次索引 内容更新中....
# 从文件读取 - read_csv:默认分隔符是逗号 - read_table:默认分隔符是/t(tab键) 参数: - sep 执行分隔符 - header=None 指定文件无列名 - names 指定列名 - index_col 指定某列作为索引 - skiprows 指定跳过哪一行 - na_values 指定某些字符串缺失值 - parse_dates 指定某些列是否被拆解为日期,布尔值或列表 - nrows 指定读取几行文件 - chunksize 分块读取文件,指定快大小
# read_table 默认是以/t(tab)为分割
pd.read_table("d:/new.csv")

pd.read_table("d:/new.csv",sep=",")

sep 还可以是正则表达式,比如 sep="\s+",表示任意长度的空白字符
# 在读取数据的时候,会默认将第一列指定为列名,可以通过修改header=None,指定第一行不是列名
pd.read_table("d:/new.csv",sep=",",header=None)

当设置header=None时,会自动取一个列名0,1,2,3,4,5,6,7
# 如果想自己取一个列名,可以修改names
pd.read_table("d:/new.csv",sep=",",header=None,names=["id","date","open","close","high","low","volumw","code"])

# 还可以设置跳过哪些行 #完整的
pd.read_table("d:/new.csv",sep=",")

pd.read_table("d:/new.csv",sep=",",skiprows=[0])

从上边可以看出。它跳是从表格的第一行开始,索引为0(在这里第一行列名就是索引0的位置)
pd.read_table("d:/new.csv",sep=",",skiprows=[1])

# 在导入的时候,默认会生成行索引,如果我们想使用某一列作为行索引,可以使用index_col,可以使用多列["id","close"]
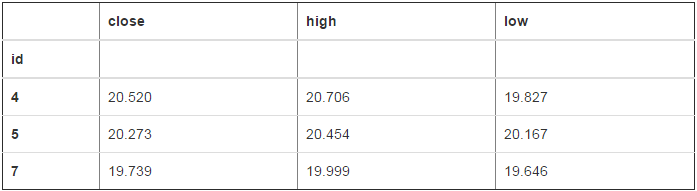
df=pd.read_table("d:/new2.csv",sep=",",index_col=["id"])
df

df.loc[4:7,"close":"low"]
# 一般在实际场景中,我们经常用用date作为行索引
df=pd.read_table("d:/new2.csv",sep=",",index_col="date")
df

type(df.index[0]) str
# 这里的date是一个字符串,我们可以将这个date转化为一个时间类型:设置parse_dates
df=pd.read_table("d:/new2.csv",sep=",",index_col="date",parse_dates=["date"])
type(df.index[0])
pandas._libs.tslib.Timestamp
在文件里如果有nan这个字符(我们之前讲的是内存里边nan),如何去识别?
# 设置na_values # 凡是"nan","None","null","xxx"这样的字符串都解析为nan,否则整列都被解析为字符串(记住,是整列,因为一列的数据类型必须一致)
df=pd.read_table("d:/new3.csv",sep=",")
df

df["id"][0]
'None' type(df["id"].iloc[1])
str df=pd.read_table("d:/new3.csv",sep=",",na_values=["nan","None","null","xxx"])
df

type(df["id"].iloc[1]) numpy.float64
# 写入到文件 to_csv 主要参数: - sep 指定分隔符 - na_sep 指定缺失值转换的字符串,默认为空字符串 - header=False 不输出第一行的列名 - index=False 不输出行的索引一列 - columns 输出指定列
# 默认是行名和列名都输出,缺失值转换的字符串转换为空
df.to_csv("d:/ceshi.csv",header=False,index=False,na_rep="DD",columns=["close"])
还可以导出成其它的文件类型:json,xml,Html,数据库
# 时间序列
# to_datetime 可以将字符串转换为一种特定的时间类型 pd.to_datetime(df["date"])
0 2007-03-01
1 2007-03-02
2 2007-03-05
3 2007-03-06
4 2007-03-07
5 2007-03-08
6 2007-03-12
7 2007-03-13
8 2007-03-14
9 2007-03-15
10 2007-03-16
11 2007-03-20
12 2007-03-21
13 2007-03-22
Name: date, dtype: datetime64[ns]
时间处理对象:date_range
参数: - start 开始时间 - end 结束时间 - periods 时间长度 - freq 时间频率,默认为"D",可选H(our),W(wwk),B(usiness),M(onth),S(econd),A(year),T
# date_range 产生一组时间
pd.date_range("2017-06-01","2017-07-01")
DatetimeIndex(['2017-06-01', '2017-06-02', '2017-06-03', '2017-06-04',
'2017-06-05', '2017-06-06', '2017-06-07', '2017-06-08',
'2017-06-09', '2017-06-10', '2017-06-11', '2017-06-12',
'2017-06-13', '2017-06-14', '2017-06-15', '2017-06-16',
'2017-06-17', '2017-06-18', '2017-06-19', '2017-06-20',
'2017-06-21', '2017-06-22', '2017-06-23', '2017-06-24',
'2017-06-25', '2017-06-26', '2017-06-27', '2017-06-28',
'2017-06-29', '2017-06-30', '2017-07-01'],
dtype='datetime64[ns]', freq='D')
# 假如要每一周出一天(默认是每一天出一个) # 这里是星期日为标准
pd.date_range("2017-06-01","2017-08-01",freq="W")
``` DatetimeIndex(['2017-06-04', '2017-06-11', '2017-06-18', '2017-06-25', '2017-07-02', '2017-07-09', '2017-07-16', '2017-07-23', '2017-07-30'], dtype='datetime64[ns]', freq='W-SUN')
```python
# 假如要只出工作日 pd.date_range("2017-06-01","2017-08-01",freq="B")
DatetimeIndex(['2017-06-01', '2017-06-02', '2017-06-05', '2017-06-06',
'2017-06-07', '2017-06-08', '2017-06-09', '2017-06-12',
'2017-06-13', '2017-06-14', '2017-06-15', '2017-06-16',
'2017-06-19', '2017-06-20', '2017-06-21', '2017-06-22',
'2017-06-23', '2017-06-26', '2017-06-27', '2017-06-28',
'2017-06-29', '2017-06-30', '2017-07-03', '2017-07-04',
'2017-07-05', '2017-07-06', '2017-07-07', '2017-07-10',
'2017-07-11', '2017-07-12', '2017-07-13', '2017-07-14',
'2017-07-17', '2017-07-18', '2017-07-19', '2017-07-20',
'2017-07-21', '2017-07-24', '2017-07-25', '2017-07-26',
'2017-07-27', '2017-07-28', '2017-07-31', '2017-08-01'],
dtype='datetime64[ns]', freq='B')
# 半个月
pd.date_range("2017-06-01","2017-08-01",freq="SM") DatetimeIndex(['2017-06-15', '2017-06-30', '2017-07-15', '2017-07-31'], dtype='datetime64[ns]', freq='SM-15') # 一个月
pd.date_range("2017-06-01","2017-08-01",freq="M") DatetimeIndex(['2017-06-30', '2017-07-31'], dtype='datetime64[ns]', freq='M') # 分钟
pd.date_range("2017-06-01","2017-08-01",freq="T")
DatetimeIndex(['2017-06-01 00:00:00', '2017-06-01 00:01:00',
'2017-06-01 00:02:00', '2017-06-01 00:03:00',
'2017-06-01 00:04:00', '2017-06-01 00:05:00',
'2017-06-01 00:06:00', '2017-06-01 00:07:00',
'2017-06-01 00:08:00', '2017-06-01 00:09:00',
...
'2017-07-31 23:51:00', '2017-07-31 23:52:00',
'2017-07-31 23:53:00', '2017-07-31 23:54:00',
'2017-07-31 23:55:00', '2017-07-31 23:56:00',
'2017-07-31 23:57:00', '2017-07-31 23:58:00',
'2017-07-31 23:59:00', '2017-08-01 00:00:00'],
dtype='datetime64[ns]', length=87841, freq='T')
# 年
pd.date_range("2017-06-01","2019-08-01",freq="A") DatetimeIndex(['2017-12-31', '2018-12-31'], dtype='datetime64[ns]', freq='A-DEC') # 星期一
pd.date_range("2017-06-01","2017-08-01",freq="W-MON") DatetimeIndex(['2017-06-05', '2017-06-12', '2017-06-19', '2017-06-26',
'2017-07-03', '2017-07-10', '2017-07-17', '2017-07-24',
'2017-07-31'],
dtype='datetime64[ns]', freq='W-MON')
periods 指定时间长度
# 从2017-06-01开始,产生20天
pd.date_range("2017-06-01",periods=20)
DatetimeIndex(['2017-06-01', '2017-06-02', '2017-06-03', '2017-06-04',
'2017-06-05', '2017-06-06', '2017-06-07', '2017-06-08',
'2017-06-09', '2017-06-10', '2017-06-11', '2017-06-12',
'2017-06-13', '2017-06-14', '2017-06-15', '2017-06-16',
'2017-06-17', '2017-06-18', '2017-06-19', '2017-06-20'],
dtype='datetime64[ns]', freq='D')
# 从2017-06-01开始,产生20个周
pd.date_range("2017-06-01",periods=20,freq="W")
DatetimeIndex(['2017-06-04', '2017-06-11', '2017-06-18', '2017-06-25',
'2017-07-02', '2017-07-09', '2017-07-16', '2017-07-23',
'2017-07-30', '2017-08-06', '2017-08-13', '2017-08-20',
'2017-08-27', '2017-09-03', '2017-09-10', '2017-09-17',
'2017-09-24', '2017-10-01', '2017-10-08', '2017-10-15'],
dtype='datetime64[ns]', freq='W-SUN')
df=pd.read_csv("d:/601318.csv",index_col="date",parse_dates=["date"])
df




2470 rows × 7 columns
type(df.index) pandas.core.indexes.datetimes.DatetimeIndex
可以看到df.index的类型就是pd.date_range之后的类型:DatetimeIndex DatetimeIndex这个类型可以在查找时非常方便
# 查找 2017年的数据 df[""]



141 rows × 7 columns
# 查找 2017年8月的数据 df["2017-8"]

# 查找 2017年6月到9月的数据 df["2017-06":"2017-09"]


这里是按照时间对象索引(类似于标签索引),顾前也顾尾
df[:10]

七、测验
求出股票行情的前5日和前10日的平均值(这里是close列的平均值)
import numpy as np
import pandas as pd
df=pd.read_csv("d:/ceshi.csv",index_col="date",parse_dates=["date"])
df



2470 rows × 7 columns
方案1:手动计算
# 思路:拿出每一行前5行的"close"列的数据,再mean()求出平均值,赋值给列"ma5"
df2=df[:10].copy()
df2.loc["2007-03-07","ma5"]=df2["close"][:6].mean()
df2.loc["2007-03"]
# 创建两列,并初始化为nan df["ma5"]=np.nan
df["ma10"]=np.nan
df



2470 rows × 9 columns
# 使用for循环一个一个的去赋值 for i in range(4,len(df)):
df.loc[df.index[i],"ma5"]=df["close"][i-4:i+1].mean() for i in range(9,len(df)):
df.loc[df.index[i],"ma10"]=df["close"][i-9:i+1].mean() df
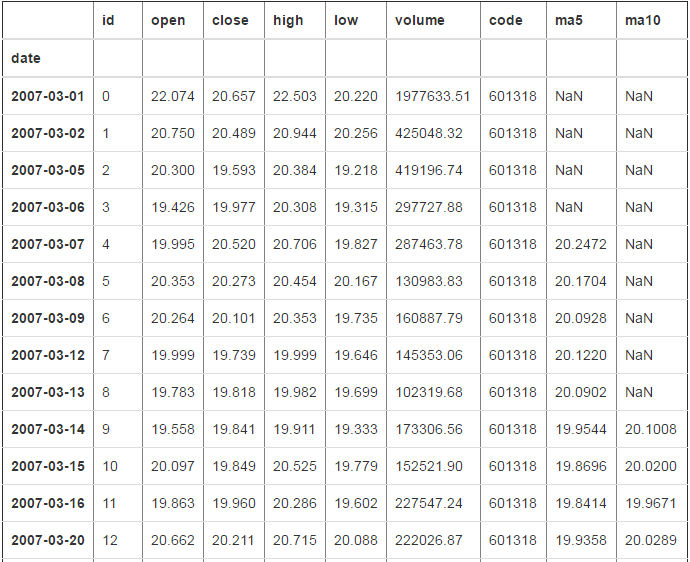
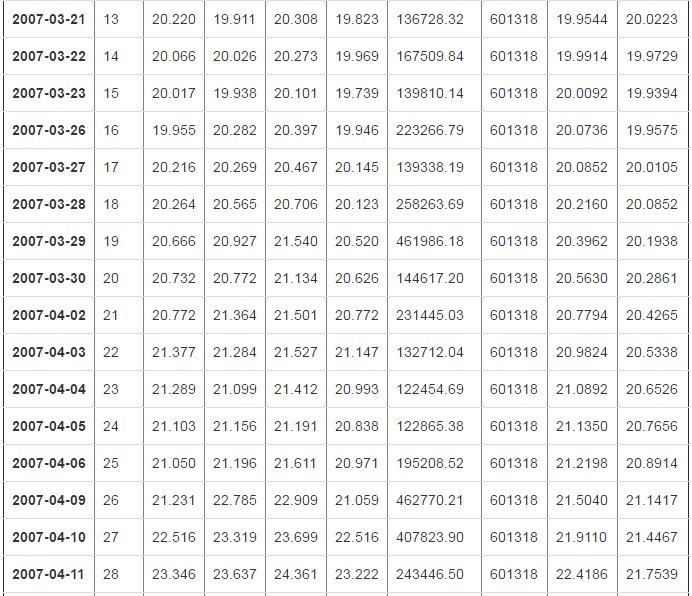


2470 rows × 9 columns
pandas模块(数据分析)------dataframe的更多相关文章
- Python 数据处理扩展包: pandas 模块的DataFrame介绍(创建和基本操作)
DataFrame是Pandas中的一个表结构的数据结构,包括三部分信息,表头(列的名称),表的内容(二维矩阵),索引(每行一个唯一的标记). 一.DataFrame的创建 有多种方式可以创建Data ...
- 5 pandas模块,DataFrame类
DataFrame DataFrame是一个[表格型]的数据结构,可以看作是[由Series组成的字典](共用同一个索引).DataFrame由一定顺序排列的多列数据组 ...
- 吴裕雄--天生自然python学习笔记:pandas模块删除 DataFrame 数据
Pandas 通过 drop 函数删除 DataFrarne 数据,语法为: 例如,删除陈聪明(行标题)的成绩: import pandas as pd datas = [[65,92,78,83,7 ...
- 吴裕雄--天生自然python学习笔记:pandas模块用 dataframe.loc 通过行、列标题读取数据
用 df.va lue s 读取数据的前提是必须知道学生及科目的位置,非常麻烦 . 而 df.loc 可直接通过行.列标题读取数据,使用起来更为方便 . 使用 df.loc 的语法为: 行标题或列标题 ...
- Python 数据处理扩展包: pandas 模块的DataFrame介绍(读写数据库的操作)
1.读取表中的内容,如下例子: import MySQLdb try: conn = MySQLdb.connect(host='127.0.0.1',user='root',passwd='root ...
- Pandas模块:表计算与数据分析
目录 Pandas之Series Pandas之DataFrame 一.pandas简单介绍 1.pandas是一个强大的Python数据分析的工具包.2.pandas是基于NumPy构建的. 3.p ...
- Python数据分析 Pandas模块 基础数据结构与简介(一)
pandas 入门 简介 pandas 组成 = 数据面板 + 数据分析工具 poandas 把数组分为3类 一维矩阵:Series 把ndarray强大在可以存储任意数据类型可以专门处理时间数据 二 ...
- python重要的第三方库pandas模块常用函数解析之DataFrame
pandas模块常用函数解析之DataFrame 关注公众号"轻松学编程"了解更多. 以下命令都是在浏览器中输入. cmd命令窗口输入:jupyter notebook 打开浏览器 ...
- python数据分析之pandas库的DataFrame应用二
本节介绍Series和DataFrame中的数据的基本手段 重新索引 pandas对象的一个重要方法就是reindex,作用是创建一个适应新索引的新对象 ''' Created on 2016-8-1 ...
- python数据分析pandas中的DataFrame数据清洗
pandas中的DataFrame中的空数据处理方法: 方法一:直接删除 1.查看行或列是否有空格(以下的df为DataFrame类型,axis=0,代表列,axis=1代表行,以下的返回值都是行或列 ...
随机推荐
- python切片技巧
写一个程序,打印数字1到100,3的倍数打印“Fizz”来替换这个数,5的倍数打印“Buzz”,对于既是3的倍数又是5的倍数的数字打印“FizzBuzz” for x in range(101): p ...
- java核心技术 笔记
一 . 总览 1. 类加载机制:jdk内嵌的class_loader有哪些,类加载过程.--后面需要补充 2. 垃圾收集基本原理,常见的垃圾收集器,各自适用的场景.--后面需要补充 3. 运行时动态编 ...
- VT-x VT-d 虚拟化在win10中的问题
win10真的是非常非常非常非常非常非常非常非常非常非常坑坑坑坑坑坑坑坑坑坑坑坑坑坑坑坑!!!!!! 自带虚拟Buff不说,我不用竟然会有冲突!!!! 一度让我怀疑,我的CPU VT-x坏掉了!!! ...
- C++ 学习笔记之——STL 库 queue
1. 队列 queue 队列是一种容器适配器,专门用来满足先进先出的操作,也就是元素在容器的一端插入并从另一端提取. bool empty() const; 返回队列是否为空: size_type s ...
- Trie 树——搜索关键词提示
当你在搜索引擎中输入想要搜索的一部分内容时,搜索引擎就会自动弹出下拉框,里面是各种关键词提示,这个功能是怎么实现的呢?其实底层最基本的就是 Trie 树这种数据结构. 1. 什么是 "Tri ...
- c# 编译的dll看不见注释问题
1.项目属性---->生成----->勾选XML文档文件: 2.使用的时候该文件和dll放在一块.
- matlab 直方图均衡化(含rgb)
步骤: 统计原图像素每个像素的个数 统计原图像<每个灰度级的像素的累积个数 家里灰度级得映射规则 将原图每个像素点的灰度映射到新图 代码: clear all I=imread('1.jpg') ...
- Git使用笔记一(关于如何设置密钥及提交)(Windows)
如何设置密钥 ssh-keygen -t rsa或ssh-keygen -t rsa -C ‘邮箱’ (注意 1.-t前有一个空格:2.keygen是key generate的缩写:3.而后连续输入三 ...
- C#及时释放代码
using语句,定义一个范围,在范围结束时释放对象. 场景: 当在某个代码段中使用了类的实例,而希望无论因为什么原因,只要离开了这个代码段就自动调用这个类实例的Dispose. 要达到这样的目的,用t ...
- A+B 输入输出练习I
while True: try: s=raw_input() a,b=s.split(' ') a,b=int(a),int(b) print a+b except EOFError: break A ...