《数据结构与算法分析》学习笔记(三)——链表ADT
今天简单学习了下链表,待后续,会附上一些简单经典的题目的解析作为学习的巩固
首先要了解链表,链表其实就是由一个个结点构成的,然后每一个结点含有一个数据域和一个指针域,数据域用来存放数据,而指针域则用来存放下一个结点的地址。
一、链表的基本知识
1、先给出结点的定义。
- typedef struct Node *PtrToNode;
- typedef PtrToNode List;
- typedef PtrToNode Position;struct Node
- {
- ElementType Element;
- Position next;
- };
2、下面就是一些常见的链表的操作
- List init(List L);
- int IsEmpty(List L);
- int IsLast(Position P,List L);
- Position Find(ElementType X,List L);
- void Delete(ElementType X,List L);
- Position FindPrevious(ElementType X,List L);
- void Insert(ElementType X,List L,Position P);
- void DeleteList(List L);
- Position Header(List L);
- Position First(List L);
- void Print(List L);
3、具体每个的分析啦
- List init(List L)
- {
- L=new struct Node;
- L->next =nullptr;return L;
- }
这个是初始化链表,链表默认有一个空的头指针,不用来存放数据,只是用来处理一些特殊的情况,个人认为一个结点的代接换取代码的简洁是很好的选择,
- int IsEmpty(List L)
- {
- return L->next==nullptr;
- }
这个是判断链表是否为空。
Position Find(ElementType X,List L)
{
Position p;
p=L->next;
while (p!=nullptr&&p->Element!=X )
{
p=p->next;
}
return p;
}
由于链表跟指针不同,没有下标可以直接访问,所以我们需要一个个的遍历。
- int IsLast(Position P,List L)
- {
- Position p;
- p=L->next;
if (p->next!=nullptr)
{
p=p->next;
}- return p==P;
- }
判断是否是最后一个。
- void Delete(ElementType X,List L)
- {
- Position p,tempCell;
- p=FindPrevious(X,L);
- if(!IsLast(p,L))
- {
- tempCell=p->next;
- p->next=tempCell->next;
- delete tempCell;
- }
- }
删除的话重点是别忘记释放内存
- Position FindPrevious(ElementType X,List L)
- {
- Position p;
- p=L;
- while (p->next!=nullptr&&p->next->Element!=X)
- {
- p=p->next;
- }return p;
- }
与查找相关
- //Insert(after legal Position P)
- void Insert(ElementType X,List L,Position P)
- {
- Position tempCell;
tempCell = new struct Node;- if (tempCell==nullptr)
{
cout<<("Out of space!!")<<endl;
}- tempCell->Element=X;
- tempCell->next = P->next;
- P->next=tempCell;
- }
默认插入在结点的后面
- void DeleteList(List L)
- {
- Position p;
- p=L->next;
L->next=nullptr;
while (p!=nullptr)
{- Position pTemp=p->next;
delete p;
p=pTemp;
}- }
清空链表
- void Print(List L)
- {
- Position p;
- p=L->next;
while(p!=nullptr)
{
cout << p->Element.coe << p->Element.index <<" “;
p=p->next- }
- cout<<endl;
- }
打印链表
二、多项式的加法(减法是类似的)
1、首先应该确定Elementtype是什么,在此我定义了一个结构体,其中包括系数coe和指数index。
- typedef struct
- {
- float coe;
- float index;}ElementType;
2、然后便是多项式加法的算法,首先默认多项式的系数是从小到大递增的。然后进行加法的时候,就用两个指针同时对两个链表进行遍历,碰到相同系数的就相加,不同的就直接加入到新链表中,然后记得相加为0的时候要进行删除。
代码如下:
- typedef struct Node *PtrToNode;
- typedef PtrToNode List;
- typedef PtrToNode Position;
- typedef struct
- {
- float coe;
- float index;
- }ElementType;
struct Node
{
ElementType Element;
Position next;- };
- //实现相应的函数的功能
- List init(List L);
- void Print(List L);
- void initPolynomial(List L);
- void hebing(List L);
- void polyAdd(List L1,List L2,List L3);
- void polySub(List L1,List L2,List L3);
- void select(List L);
- List init(List L)
{
L->next =nullptr;- return L;
}
void Print(List L)
{
Position p;
p=L->next;- while(p!=nullptr)
{
cout << p->Element.coe <<"X^"<< p->Element.index;
if(p->next!=nullptr&&p->Element.coe>)
{
cout<<"+";
}
p=p->next;
}
cout<<endl;
}
void initPolynomial(List L)
{
DeleteList(L);- Position p,pre;
pre=L;
int coe,index;- while ()
{
cout<<"Please scanf coe and index(以0 0退出):";
cin>>coe>>index;- if(coe== && index==)
{
break;
}
else
{
p=new struct Node;
p->Element.coe=coe;
p->Element.index=index;
p->next=nullptr;
pre->next=p;
pre=p;
}
}
hebing(L);- }
- void hebing(List L)
{
Position pi,pj,pk2,pk1;
pi=L->next;
if(pi==nullptr||pi->next==nullptr)
{
return ;
}
for(pk1=L,pi=L->next;pi!=nullptr&&pi->next!=nullptr;pi=pi->next)
{
for(pj=pi->next,pk2=pi;pj!=nullptr;pj=pj->next)
{
if(pi->Element.index==pj->Element.index)
{
pi->Element.coe+=pj->Element.coe;
pk2->next=pj->next;
Position pTemp=pj;
delete pTemp;
pj=pk2;
}
pk2=pj;
}
if(pi->Element.coe==)
{
pk1->next=pi->next;
Position pTemp=pi;
free(pTemp);
pi=pk1;
}
pk1=pi;
}
select(L);
}- void select(List L)
{
Position pi,pj;
pi=L->next;
if(pi==nullptr||pi->next==nullptr)
{
return ;
}- for(pi=L->next;pi->next!=nullptr;pi=pi->next)
{
Position ptemp=pi;
for(pj=pi->next;pj!=nullptr;pj=pj->next)
{
if(pj->Element.index<pi->Element.index)
{
ptemp=pj;
}
}- ElementType temp=ptemp->Element;
ptemp->Element=pi->Element;
pi->Element=temp;
}- }
- void polySub(List L1,List L2,List L3)
{
Position p1=L1->next;
Position p2=L2->next;- Position p3=L3;
- while (p1!=nullptr&&p2!=nullptr)
{
if(p1!=nullptr&&p2!=nullptr&&p1->Element.index==p2->Element.index)
{
Position p=new struct Node;
p->Element.index=p2->Element.index;
p->Element.coe=-p2->Element.coe+p1->Element.coe;
p->next=p3->next;
p3->next=p;
p3=p;- p1=p1->next;
p2=p2->next;- }
- while(p1!=nullptr&&p2!=nullptr&&p1->Element.index>p2->Element.index)
{
Position p = new struct Node;
p->Element.index=p2->Element.index;
p->Element.coe=p2->Element.coe;
p->next=p3->next;
p3->next=p;
p3=p;- p2=p2->next;
}- while (p1!=nullptr&&p2!=nullptr&&p1->Element.index<p2->Element.index)
{
Position p = new struct Node;
p->Element.index=p1->Element.index;
p->Element.coe=p1->Element.coe;
p->next=p3->next;
p3->next=p;
p3=p;- p1=p1->next;
}- }
if(p1!=nullptr)
{
while(p1!=nullptr)
{
Position p = new struct Node;
p->Element.index=p1->Element.index;
p->Element.coe=p1->Element.coe;
p->next=p3->next;
p3->next=p;
p3=p;
p1=p1->next;
}
}
if(p2!=nullptr)
{
while(p2!=nullptr)
{
Position p = new struct Node;
p->Element.index=p2->Element.index;
p->Element.coe=-p2->Element.coe;
p->next=p3->next;
p3->next=p;
p3=p;- p2=p2->next;
}
}
hebing(L3);
}- void polyAdd(List L1,List L2,List L3)
{
Position p1=L1->next;
Position p2=L2->next;- Position p3=L3;
- while (p1!=nullptr&&p2!=nullptr)
{
if(p1!=nullptr&&p2!=nullptr&&p1->Element.index==p2->Element.index)
{
Position p=new struct Node;
p->Element.index=p2->Element.index;
p->Element.coe=p2->Element.coe+p1->Element.coe;
p->next=p3->next;
p3->next=p;
p3=p;- p1=p1->next;
p2=p2->next;- }
- while(p1!=nullptr&&p2!=nullptr&&p1->Element.index>p2->Element.index)
{
Position p = new struct Node;
p->Element.index=p2->Element.index;
p->Element.coe=p2->Element.coe;
p->next=p3->next;
p3->next=p;
p3=p;- p2=p2->next;
}- while (p1!=nullptr&&p2!=nullptr&&p1->Element.index<p2->Element.index)
{
Position p = new struct Node;
p->Element.index=p1->Element.index;
p->Element.coe=p1->Element.coe;
p->next=p3->next;
p3->next=p;
p3=p;- p1=p1->next;
}- }
if(p1!=nullptr)
{
while(p1!=nullptr)
{
Position p = new struct Node;
p->Element.index=p1->Element.index;
p->Element.coe=p1->Element.coe;
p->next=p3->next;
p3->next=p;
p3=p;
p1=p1->next;
}
}
if(p2!=nullptr)
{
while(p2!=nullptr)
{
Position p = new struct Node;
p->Element.index=p2->Element.index;
p->Element.coe=p2->Element.coe;
p->next=p3->next;
p3->next=p;
p3=p;- p2=p2->next;
}
}- }
3、桶式排序与基数排序
(1)桶式排序:假如有N哥整数,范围从1到M,我们可以创建一个数组Count,大小为M并初始化为0,于是,Count有M个桶,开始他们是空的,当i被读入的时候Count[i]增加1,在所有的输入都被读完以后,扫一遍数组Count,然后便可以打印出来排好序的表。
- int A[];
- memset((void *)A, , *sizeof(int)); //初始化0;
- int temp;
cout<<"Please scanf the numbers(数字在【1,1000】,以0退出);"<<endl;
while()
{- cin>>temp;
- if(temp<||temp>)
{
cout<<"temp输入有误,该数已排除"<<endl; //排除超限的数
cin>>temp;
}- if(temp==)
{
break; //循环出口
}- A[temp]++;
}
for(int i=;i<;i++)
{
if (A[i]!=)
{
cout<<i<<" "; //打印处结果
}
}
cout<<endl;- return ;
(2)基数排序
基数排序是对桶式排序的一种推广,由于桶式排序对空间的需求太高,所以我们考虑可以多次桶排序,降低M的值,就可以达到降低空间的需求,例如正整数的排序,我们可以把每一位都拆分出来,这样M的范围只有从0到9,也就是说我们一下子省去N多不必要的空间,碰到,有相同数的我们考虑接到这个i值下的链表即可。然后我COPY书上的图,让我们更好的理解
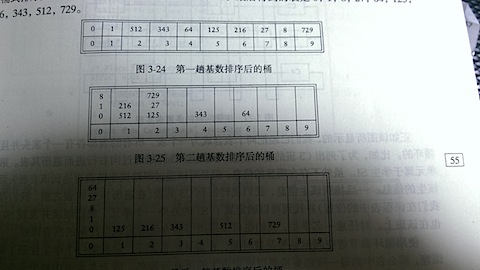
最后贴出代码。
- typedef struct Node
- {
- int element;
- Node *next;
- }Node;
- typedef Node* pNode;
- int main(int argc, const char * argv[])
- {
- Node A[];
- for(int i=;i<;i++)
- {
- A[i].next=nullptr;
- }
- int temp,Max=;
- cout<<"请输入要进行排序的数(范围≥0,以-1退出)"<<endl;
- while()
- {
- cin>>temp;
- if(temp<-)
- {
- cout<<temp<<"Scanf Error!"<<endl;
- cin>>temp;
- }
- if(temp==-)
- {
- break;
- }
- if(temp>Max)
- {
- Max=temp;
- }
- int i=temp%;
- auto node = new Node;
- node->element=temp;
- node->next=nullptr;
- pNode p= A+i;
- while (p->next!=nullptr)
- {
- p=p->next;
- }
- p->next=node;
- }
- int N=;
- while (Max)
- {
- N++;
- Max/=;
- }
- int n=;
- int XX=;
- while (n!=N+)
- {
- XX*=;
- for (int i=; i<; i++)
- {
- pNode p = (A+i)->next;
- pNode q = (A+i);
- while (p!=nullptr)
- {
- int temp=p->element/(XX)%;
- if(temp==i)
- {
- q=p;
- p=p->next;
- continue;
- }
- else
- {
- q->next=p->next;
- pNode ptemp=A+temp;
- while(ptemp->next!=nullptr)
- {
- ptemp=ptemp->next;
- }
- p->next=nullptr;
- ptemp->next=p;
- p=q->next;
- }
- }
- }
- n++;
- }
- for(int i=;i<;i++)
- {
- pNode p=A+i;
- p=p->next;
- while (p!=nullptr)
- {
- cout<<p->element<<" ";
- p=p->next;
- }
- cout<<endl;
- }
- return ;
- }
《数据结构与算法分析》学习笔记(三)——链表ADT的更多相关文章
- <数据结构与算法分析>读书笔记--最大子序列和问题的求解
现在我们将要叙述四个算法来求解早先提出的最大子序列和问题. 第一个算法,它只是穷举式地尝试所有的可能.for循环中的循环变量反映了Java中数组从0开始而不是从1开始这样一个事实.还有,本算法并不计算 ...
- <数据结构与算法分析>读书笔记--利用Java5泛型实现泛型构件
一.简单的泛型类和接口 当指定一个泛型类时,类的声明则包括一个或多个类型参数,这些参数被放入在类名后面的一对尖括号内. 示例一: package cn.generic.example; public ...
- Oracle学习笔记三 SQL命令
SQL简介 SQL 支持下列类别的命令: 1.数据定义语言(DDL) 2.数据操纵语言(DML) 3.事务控制语言(TCL) 4.数据控制语言(DCL)
- [Firefly引擎][学习笔记三][已完结]所需模块封装
原地址:http://www.9miao.com/question-15-54671.html 学习笔记一传送门学习笔记二传送门 学习笔记三导读: 笔记三主要就是各个模块的封装了,这里贴 ...
- JSP学习笔记(三):简单的Tomcat Web服务器
注意:每次对Tomcat配置文件进行修改后,必须重启Tomcat 在E盘的DATA文件夹中创建TomcatDemo文件夹,并将Tomcat安装路径下的webapps/ROOT中的WEB-INF文件夹复 ...
- java之jvm学习笔记三(Class文件检验器)
java之jvm学习笔记三(Class文件检验器) 前面的学习我们知道了class文件被类装载器所装载,但是在装载class文件之前或之后,class文件实际上还需要被校验,这就是今天的学习主题,cl ...
- VSTO学习笔记(三) 开发Office 2010 64位COM加载项
原文:VSTO学习笔记(三) 开发Office 2010 64位COM加载项 一.加载项简介 Office提供了多种用于扩展Office应用程序功能的模式,常见的有: 1.Office 自动化程序(A ...
- Java IO学习笔记三
Java IO学习笔记三 在整个IO包中,实际上就是分为字节流和字符流,但是除了这两个流之外,还存在了一组字节流-字符流的转换类. OutputStreamWriter:是Writer的子类,将输出的 ...
- NumPy学习笔记 三 股票价格
NumPy学习笔记 三 股票价格 <NumPy学习笔记>系列将记录学习NumPy过程中的动手笔记,前期的参考书是<Python数据分析基础教程 NumPy学习指南>第二版.&l ...
- Learning ROS for Robotics Programming Second Edition学习笔记(三) 补充 hector_slam
中文译著已经出版,详情请参考:http://blog.csdn.net/ZhangRelay/article/category/6506865 Learning ROS for Robotics Pr ...
随机推荐
- Apache2.4.6 添加虚拟主机
apache2.4 与 apache2.2 的虚拟主机配置写法有所不同 apache2.2的写法: <VirtualHost *:80> ServerName domain.com Doc ...
- DT时代即将到来
今日,Sort Benchmark 在官方网站公布了 2015 年排序竞赛的最终成绩.其中,阿里云用不到 7 分钟(377 秒)就完成了 100TB 的数据排序,打破了 Apache Spark 的纪 ...
- C++中string,wstring,CString的基本概念和用法
一.概念 string和CString均是字符串模板类,string为标准模板类(STL)定义的字符串类,已经纳入C++标准之中.wstring是操作宽字符串的类.C++标准程序库对于string的设 ...
- 2.js模式-单例模式
1. 单例模式 单例模式的核心是确保只有一个实例,并提供全局访问. function xx(name){}; Singleton.getInstance = (function(){ var inst ...
- FZU 2165 v11(最小重复覆盖)+ codeforces 417D Cunning Gena
告诉你若干个(<=100)武器的花费以及武器能消灭的怪物编号,问消灭所有怪物(<=100)的最小花费...当然每个武器可以无限次使用,不然这题就太水了╮(╯▽╰)╭ 这题当时比赛的时候连题 ...
- codeforces 518B. Tanya and Postcard 解题报告
题目链接:http://codeforces.com/problemset/problem/518/B 题目意思:给出字符串 s 和 t,如果 t 中有跟 s 完全相同的字母,数量等于或者多过 s,就 ...
- jquery的基本事件大全
].name); });jQuery.getScript( url, [callback] ) 使用GET请求javascript文件并执行. $.getScript(”test.js”, funct ...
- osg四元数设置roll pitch heading角度
roll绕Y轴旋转 pitch绕X轴旋转 heading绕Z轴旋转 单位是弧度,可以使用osg::inDegrees(45)将45角度转换为弧度 定义一个四元数 osg::Quat q( roll,o ...
- grep(Global Regular Expression Print)
.grep -iwr --color 'hellp' /home/weblogic/demo 或者 grep -iw --color 'hellp' /home/weblogic/demo/* (-i ...
- Lua程序设计入门
在Lua中,一切都是变量,除了关键字.TTMD强大了. 1.注释 -- 表示注释一行 --[[ ]]表示注释一段代码,相当于C语言的/*....*/ 注意:[[ ... ]]表示一段字符串 2.lua ...