GreenPlum简单性能测试与分析--续
版权声明:本文由黄辉原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/259
来源:腾云阁 https://www.qcloud.com/community
之前对GreenPlum与Mysql进行了TPC-H类的对比测试,发现同等资源配比条件下,GreenPlum的性能远好于Mysql,有部分原因是得益于GreenPlum本身采用了更高效的算法,比如说做多表join时,采用的是hash join方式。如果采用同样高效的算法,两者的性能又如何?由于GreenPlum是由PostgreSQL演变而来,完全采用了PostgreSQL的优化算法,这次,我们将GreenPlum与PostgreSQL进行对比测试,在同等资源配比条件下,查看GreenPlum(分布式PostgreSQL)和单机版PostgreSQL的性能表现。
一.目的
- 比较在同等资源条件下具有分布式属性的GreenPlum与PostgreSQL在进行TPC-H类测试的性能区别。
- 分析和总结两种DB造成性能区别的原因。
二.测试环境与配置信息
测试环境:腾讯云
测试对象:GreenPlum、PostgreSQL,两者的配置信息统计如下:
表1 GreenPlum集群服务器
| Master Host | Segment Host | Segment Host | |
|---|---|---|---|
| 操作系统 | CentOS 6.7 64位 | CentOS 6.7 64位 | CentOS 6.7 64位 |
| CPU | Intel(R) Xeon(R) CPU E5-26xx v3 2核 | Intel(R) Xeon(R) CPU E5-26xx v3 2核 | Intel(R) Xeon(R) CPU E5-26xx v3 2核 |
| 内存 | 8GB | 8GB | 8GB |
| 公网带宽 | 100Mbps | 100Mbps | 100Mbps |
| IP | 123.207.228.40 | 123.207.228.21 | 123.207.85.105 |
| Segment数量 | 0 | 2 | 2 |
| 版本 | greenplum-db-4.3.8.1-build-1-RHEL5-x86_64 | greenplum-db-4.3.8.1-build-1-RHEL5-x86_64 | greenplum-db-4.3.8.1-build-1-RHEL5-x86_64 |
表2 PostgreSQL服务器
| 指标 | 参数 |
|---|---|
| 操作系统 | CentOS 6.7 64位 |
| cpu | Intel(R) Xeon(R) CPU E5-26xx v3 8核 |
| 内存 | 24GB |
| 公网带宽 | 100Mbps |
| IP | 119.29.229.209 |
| 版本 | PostgreSQL 9.5.4 |
三.测试结果与分析
1.总测试数据量为1G时
结果统计信息如下:
表3 总量为1GB时各测试表数据量统计
| 表名称 | 数据条数 |
|---|---|
| customer | 150000 |
| lineitem | 6001215 |
| nation | 25 |
| orders | 1500000 |
| part | 200000 |
| partsupp | 800000 |
| region | 5 |
| supplier | 10000 |
表4 总量为1GB时22条sql执行时间统计
| 执行的sql | GeenPlum执行时间(单位:秒) | PostgreSQL执行时间(单位:秒) |
|---|---|---|
| Q1 | 4.01 | 12.93 |
| Q2 | 0.50 | 0.62 |
| Q3 | 1.35 | 1.29 |
| Q4 | 0.11 | 0.52 |
| Q5 | 0.19 | 0.72 |
| Q6 | 0.01 | 0.79 |
| Q7 | 6.06 | 1.84 |
| Q8 | 1.46 | 0.59 |
| Q9 | 4.00 | 7.04 |
| Q10 | 0.14 | 2.19 |
| Q11 | 0.30 | 0.18 |
| Q12 | 0.08 | 2.15 |
| Q13 | 1.04 | 4.05 |
| Q14 | 0.04 | 0.42 |
| Q15 | 0.07 | 1.66 |
| Q16 | 0.51 | 0.80 |
| Q17 | 3.21 | 23.07 |
| Q18 | 14.23 | 5.86 |
| Q19 | 0.95 | 0.17 |
| Q20 | 0.16 | 3.10 |
| Q21 | 7.23 | 2.22 |
| Q22 | 0.96 | 0.28 |
分析:从以上的表4可以看出,PostgreSQL在22条sql中有8条sql的执行时间比GreenPlum少,接近一半的比例,我们直接放大10倍的测试数据量进行下一步测试。
2.总测试数据量为10G时
结果统计如下:
表5 总量为10GB时各测试表数据量统计
| 表名称 | 数据条数 |
|---|---|
| customer | 1500000 |
| lineitem | 59986052 |
| nation | 25 |
| orders | 15000000 |
| part | 2000000 |
| partsupp | 8000000 |
| region | 5 |
| supplier | 100000 |
表6 总量为10GB时22条sql执行时间统计
| 执行的sql | GeenPlum执行时间(单位:秒) | PostgreSQL执行时间(单位:秒) |
|---|---|---|
| Q1 | 36.98 | 130.61 |
| Q2 | 3.10 | 17.08 |
| Q3 | 14.39 | 117.83 |
| Q4 | 0.11 | 6.81 |
| Q5 | 0.20 | 114.46 |
| Q6 | 0.01 | 11.08 |
| Q7 | 80.12 | 42.96 |
| Q8 | 6.61 | 45.13 |
| Q9 | 49.72 | 118.36 |
| Q10 | 0.16 | 40.51 |
| Q11 | 2.28 | 3.06 |
| Q12 | 0.08 | 21.47 |
| Q13 | 19.29 | 68.83 |
| Q14 | 0.05 | 36.28 |
| Q15 | 0.09 | 23.16 |
| Q16 | 6.30 | 12.77 |
| Q17 | 134.22 | 127.79 |
| Q18 | 168.03 | 199.48 |
| Q19 | 6.25 | 1.96 |
| Q20 | 0.54 | 52.10 |
| Q21 | 84.68 | 190.59 |
| Q22 | 17.93 | 2.98 |
分析:放大数据量到10G后可以明显看出,PostgreSQL执行测试sql的时间大幅度增多,性能下降比较厉害,但仍有3条测试sql快于GreenPlum,我们选取其中一条对比查看下两者的性能区别原因。
这里我们以Q7为例,Greenplum的执行时间大约是PostgreSQL的两倍,Q7如下: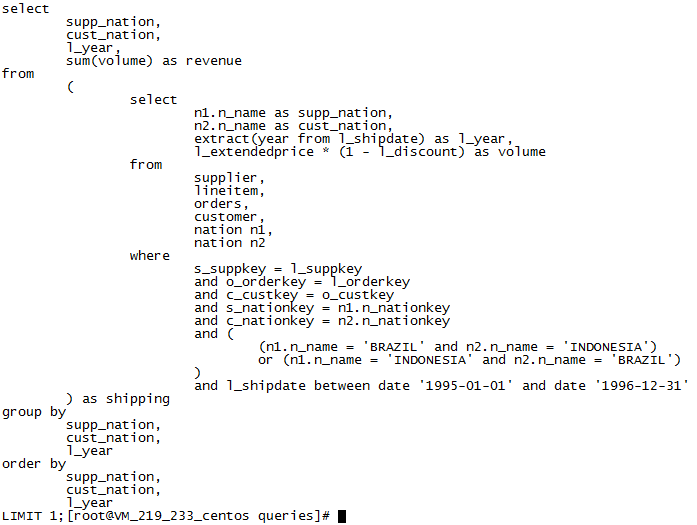
图1 Q7表示的sql语句
在PostgreSQL上执行explain Q7,得到结果如下: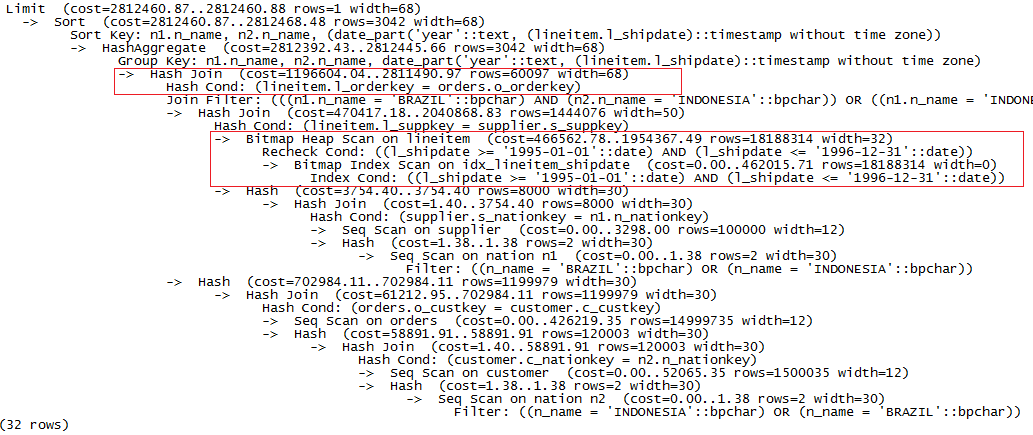
图2 数据量为10G时PostgreSQL上执行explain Q7的结果
对执行进行分析,可以看出,整个过程最耗时的部分如上图红色框部分标识,对应的条件查询操作分别是:
1).在lineitem表上对l_shipdata字段按条件查询,因为在字段有索引,采用了高效的Bitmap索引查询(Bitmap索引查询分两步:1.建位图;2.扫表。详细了解可看http://kb.cnblogs.com/page/515258/ )。
2).lineitem和orders表hash join操作。
为了方便进一步分析,我们加上analyze参数,获取详细的执行时间,由于内容过多,这里只截取部分重要信息如下:

图3 数据量为10G时PostgreSQL上执行explain analyze Q7的部分结果
根据以上信息,我们可以得出这两部分操作的具体执行时间,但由于PostgreSQL采取多任务并行,因此,我们需要对每步操作计算出一个滞留时间(该时间段内系统只执行该步操作),缩短滞留时间可直接提升执行速度,每步的滞留时间为前步的结束时间与该步结束时间之差。两部分的滞留时间分别为:
1).Bitmap Heap Scan:20197-2233=17964ms
2).Hash join:42889-26200=16689ms
PostgreSQL执行Q7的总时间为42963ms,因此,可以印证系统的耗时主要集中在上述两步操作上。
接下来,我们在GreenPlum上执行explain Q7,结果如下:
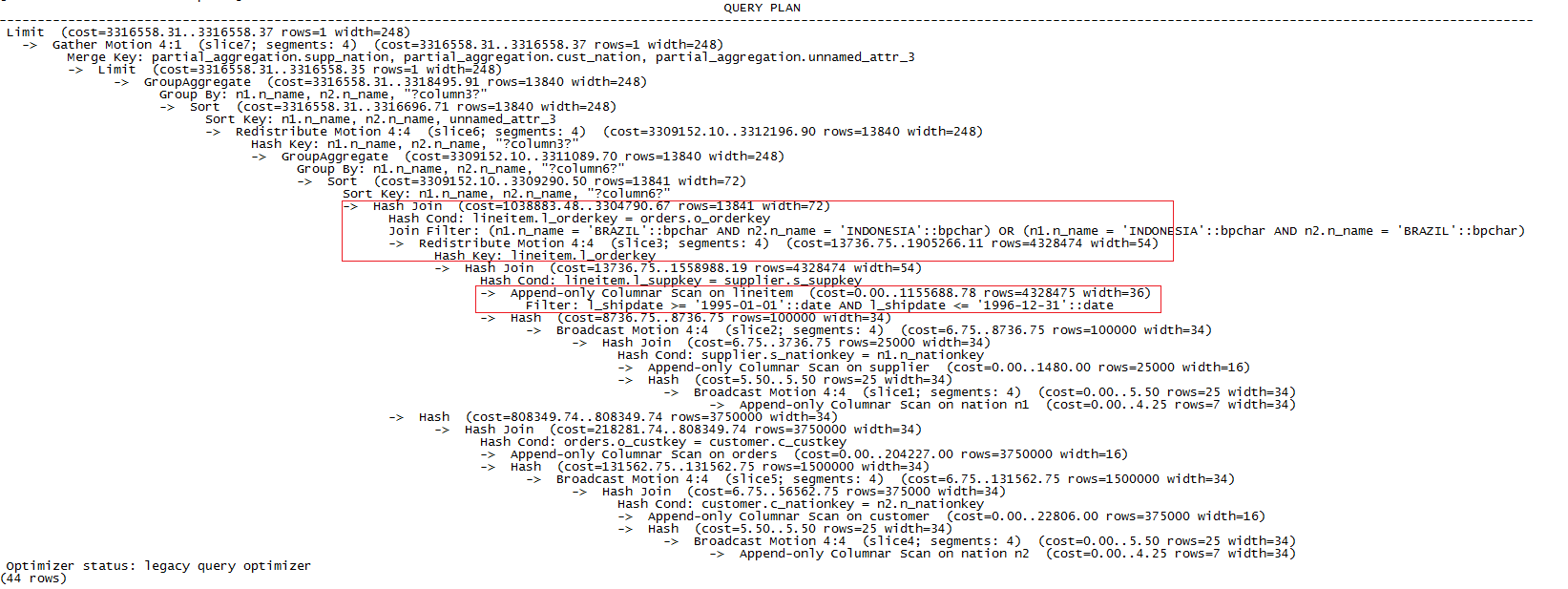
图4 数据量为10G时GreenPlum上执行explain Q7的结果
与PostgreSQL不同的是,GreenPlum的耗时多了数据重分布部分。同样,我们通过analyze参数得到详细的执行时间如下: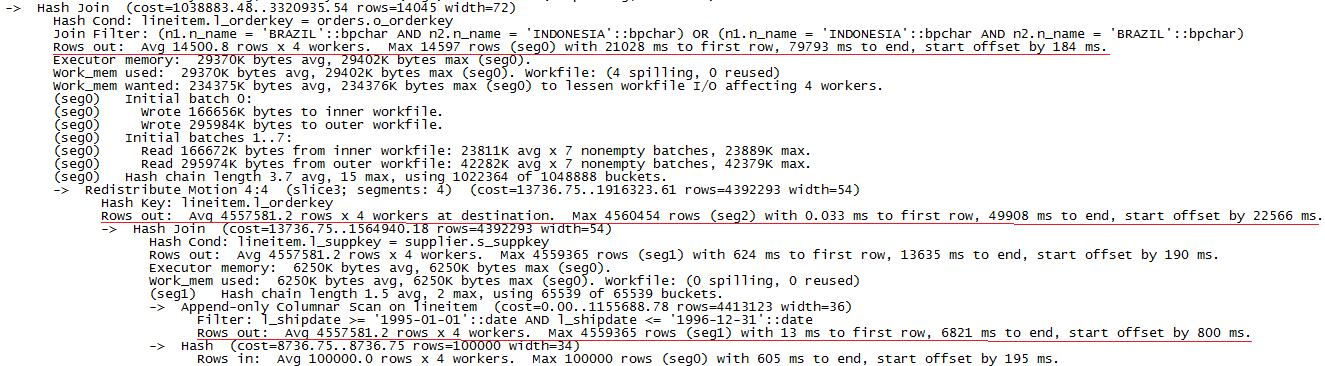
图5 数据量为10G时GreenPlum上执行explain analyze Q7的部分结果
根据执行计划信息,选出耗时最长的三步操作,计算出在一个segment(耗时最长的)上这三部分的滞留时间为:
1).Scan lineitem: 6216ms
2).Redistribute: 36273ms
3).Hash join: 29885ms
GreenPlum执行Q7的总时间为80121ms,可见数据重分布的时间占据了整个执行时间的一半,进行Hash join操作的时间占比也较多,主要是segment的内存不足,引起了磁盘的IO。
小结:对比PostgreSQL和GreenPlum在Q7的执行计划,GreenPlum的耗时较多的原因主要是数据重分布的大量时间消耗和hash join时超出内存引起磁盘IO。虽然GreenPlum各segment并行扫lineitem表节省了时间,但占比较小,对总时间的消耗影响较小。
基于此,是否可以减少数据重分布操作的耗时占比?我们尝试进一步增加测试的数据量,比较10G的测试数据对于真实的OLAP场景还是过少,扩大5倍的测试量,继续查看耗时情况是否有所改变。
3. 总测试数据量为50G时
表7 总量为50GB时各测试表数据量统计
| 表名称 | 数据条数 |
|---|---|
| customer | 7500000 |
| lineitem | 300005811 |
| nation | 25 |
| orders | 75000000 |
| part | 10000000 |
| partsupp | 40000000 |
| region | 5 |
| supplier | 500000 |
表8 总量为50GB时22条sql执行时间统计
| 执行的sql | GeenPlum执行时间(单位:秒) | PostgreSQL执行时间(单位:秒) |
|---|---|---|
| Q1 | 212.27 | 802.24 |
| Q2 | 16.53 | 164.20 |
| Q3 | 156.31 | 2142.18 |
| Q4 | 0.13 | 2934.76 |
| Q5 | 0.23 | 2322.92 |
| Q6 | 0.01 | 6439.26 |
| Q7 | 535.66 | 11906.74 |
| Q8 | 76.76 | 9171.83 |
| Q9 | 313.91 | >26060.36 |
| Q10 | 0.41 | 1905.13 |
| Q11 | 7.71 | 17.65 |
| Q12 | 0.19 | >3948.07 |
| Q13 | 108.05 | 354.59 |
| Q14 | 0.05 | 8054.72 |
| Q15 | 0.07 | >2036.03 |
| Q16 | 34.74 | 221.49 |
| Q17 | 862.90 | >9010.56 |
| Q18 | 913.97 | 3174.24 |
| Q19 | 129.14 | 8666.38 |
| Q20 | 2.28 | 9389.21 |
| Q21 | 1064.67 | >26868.31 |
| Q22 | 90.90 | 1066.44 |
分析:从结果表可明显看出,在22条SQL中,GreenPlum的执行效率都比PostgreSQL高出很多,我们还是以Q7为例,查看两种数据量下执行效率不一致的直接原因。
经过对执行计划的分析,发现区别还是集中在步骤2提到的几个部分,这里就不再重复给出整体的查询计划,直接查看耗时较多的部分如下:

图6 数据量为50G时PostgreSQL上执行explain analyze Q7的部分结果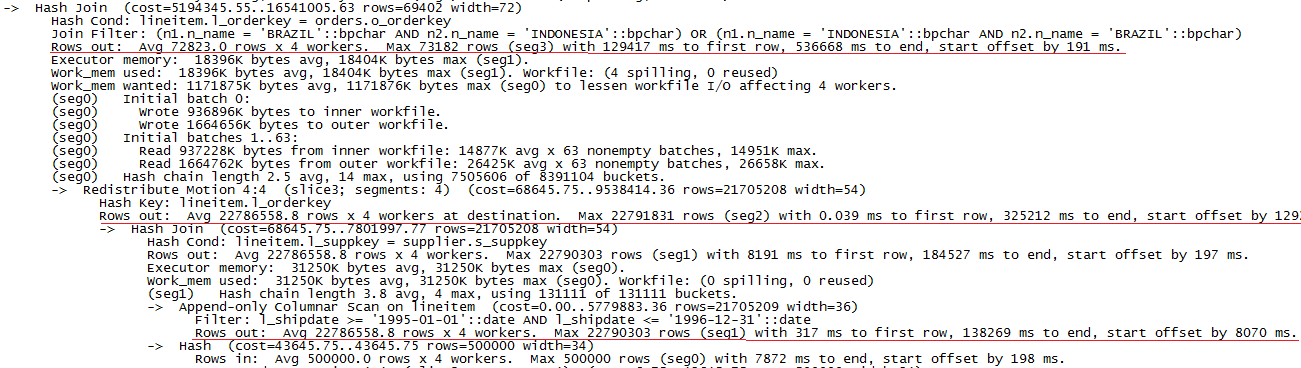
图7 数据量为50G时GreenPlum上执行explain analyze Q7的部分结果
PostgreSQL的主要滞留时间有:
1).Bitmap Heap Scan: 9290197ms
2).Hash join: 713138ms
总执行时间为10219009ms,可见主要的耗时集中在Bitmap Heap Scan上,
GreenPlum的主要滞留时间有:
1).Scan lineitem: 130397ms
2).Redistribute: 140685ms
3).Hash join: 211456ms
总的执行时间为537134ms,相比步骤2的10G测试数据量,数据重分布的耗时占比明显下降,主要耗时已集中在hash join操作上。
GreenPlum和PostgreSQL在执行同样的wheret条件时,扫表的方式不一样,原因在于GreenPlum里的lineitem表为列存储,直接扫表更方便更快。
对比PostgreSQL两次的测试结果,发现Bitmao Heap Scan操作的性能下降比较明显,第一次扫18188314 行用时17秒,而第二次扫90522811行用时9190秒。
小结:增大数据量,会减少数据重分布耗时对整体执行时间的影响比重,主要耗时集中在内部数据的计算上。由于扫表涉及到磁盘IO,GreenPlum将扫表任务分割给多个segment同时进行,减少了单个节点要执行的扫表量,相当于并行IO操作,对整体的性能提升较大。
四.总结
通过对不同数据量(1G,10G,50G)的测试对比以及分析,可以看出,在TPC-H类的测试时,数据量越大,GreenPlum性能越好于单机版的PostgreSQL。由于GreenPlum采用分布式架构,为了实现各节点并行计算能力,需要在节点间进行广播或者数据重分布,对整体的性能有一定影响,当数据量较小时,计算量小,广播或者重分布耗时占总耗时比例大,影响整体的执行效率,可能会出现GreenPlum不如单机版PostgreSQL效率高;当数据量较大时,整体计算的量很大,广播或者重分布耗时不再是影响性能的关键因素,分布式属性的GreenPlum在关于复杂语句执行查询效率较高,原因在于,一是多节点同时进行计算(hash join、sort等),提升计算速度,且可以充分利用系统CPU资源;二是扫表时,将任务分派到多节点,减少了单个节点的IO次数,达到并行IO的目的,更适用于OLAP场景。
五.其他事项
由于原生的TPC-H的测试用例不直接支持GreenPlum和PostgreSQL,因此需要修改测试脚本,生成新的建表语句如《附录一》所示,测试sql如《附录二》。
GreenPlum的数据导入可以使用GreenPlum自带的gpfdist工具,搭建多个gpfdsit文件服务器并行导入,但文件服务器的数量不能多于segment数量,这点官方文档并未说明。
附录一:建表语句
GreenPlum:
BEGIN;
CREATE TABLE PART (
P_PARTKEY SERIAL8,
P_NAME VARCHAR(55),
P_MFGR CHAR(25),
P_BRAND CHAR(10),
P_TYPE VARCHAR(25),
P_SIZE INTEGER,
P_CONTAINER CHAR(10),
P_RETAILPRICE DECIMAL,
P_COMMENT VARCHAR(23)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (p_partkey);
COPY part FROM '/tmp/dss-data/part.csv' WITH csv DELIMITER '|';
COMMIT;
BEGIN;
CREATE TABLE REGION (
R_REGIONKEY SERIAL8,
R_NAME CHAR(25),
R_COMMENT VARCHAR(152)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (r_regionkey);
COPY region FROM '/tmp/dss-data/region.csv' WITH csv DELIMITER '|';
COMMIT;
BEGIN;
CREATE TABLE NATION (
N_NATIONKEY SERIAL8,
N_NAME CHAR(25),
N_REGIONKEY BIGINT NOT NULL, -- references R_REGIONKEY
N_COMMENT VARCHAR(152)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (n_nationkey);
COPY nation FROM '/tmp/dss-data/nation.csv' WITH csv DELIMITER '|';
COMMIT;
BEGIN;
CREATE TABLE SUPPLIER (
S_SUPPKEY SERIAL8,
S_NAME CHAR(25),
S_ADDRESS VARCHAR(40),
S_NATIONKEY BIGINT NOT NULL, -- references N_NATIONKEY
S_PHONE CHAR(15),
S_ACCTBAL DECIMAL,
S_COMMENT VARCHAR(101)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (s_suppkey);
COPY supplier FROM '/tmp/dss-data/supplier.csv' WITH csv DELIMITER '|';
COMMIT;
BEGIN;
CREATE TABLE CUSTOMER (
C_CUSTKEY SERIAL8,
C_NAME VARCHAR(25),
C_ADDRESS VARCHAR(40),
C_NATIONKEY BIGINT NOT NULL, -- references N_NATIONKEY
C_PHONE CHAR(15),
C_ACCTBAL DECIMAL,
C_MKTSEGMENT CHAR(10),
C_COMMENT VARCHAR(117)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (c_custkey);
COPY customer FROM '/tmp/dss-data/customer.csv' WITH csv DELIMITER '|';
COMMIT;
BEGIN;
CREATE TABLE PARTSUPP (
PS_PARTKEY BIGINT NOT NULL, -- references P_PARTKEY
PS_SUPPKEY BIGINT NOT NULL, -- references S_SUPPKEY
PS_AVAILQTY INTEGER,
PS_SUPPLYCOST DECIMAL,
PS_COMMENT VARCHAR(199)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (ps_partkey,ps_suppkey);
COPY partsupp FROM '/tmp/dss-data/partsupp.csv' WITH csv DELIMITER '|';
COMMIT;
BEGIN;
CREATE TABLE ORDERS (
O_ORDERKEY SERIAL8,
O_CUSTKEY BIGINT NOT NULL, -- references C_CUSTKEY
O_ORDERSTATUS CHAR(1),
O_TOTALPRICE DECIMAL,
O_ORDERDATE DATE,
O_ORDERPRIORITY CHAR(15),
O_CLERK CHAR(15),
O_SHIPPRIORITY INTEGER,
O_COMMENT VARCHAR(79)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (o_orderkey);
COPY orders FROM '/tmp/dss-data/orders.csv' WITH csv DELIMITER '|';
COMMIT;
BEGIN;
CREATE TABLE LINEITEM (
L_ORDERKEY BIGINT NOT NULL, -- references O_ORDERKEY
L_PARTKEY BIGINT NOT NULL, -- references P_PARTKEY (compound fk to PARTSUPP)
L_SUPPKEY BIGINT NOT NULL, -- references S_SUPPKEY (compound fk to PARTSUPP)
L_LINENUMBER INTEGER,
L_QUANTITY DECIMAL,
L_EXTENDEDPRICE DECIMAL,
L_DISCOUNT DECIMAL,
L_TAX DECIMAL,
L_RETURNFLAG CHAR(1),
L_LINESTATUS CHAR(1),
L_SHIPDATE DATE,
L_COMMITDATE DATE,
L_RECEIPTDATE DATE,
L_SHIPINSTRUCT CHAR(25),
L_SHIPMODE CHAR(10),
L_COMMENT VARCHAR(44)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (l_orderkey, l_linenumber);
COPY lineitem FROM '/tmp/dss-data/lineitem.csv' WITH csv DELIMITER '|';
COMMIT;
PostgreSQL:
BEGIN;
CREATE TABLE PART (
P_PARTKEY SERIAL,
P_NAME VARCHAR(55),
P_MFGR CHAR(25),
P_BRAND CHAR(10),
P_TYPE VARCHAR(25),
P_SIZE INTEGER,
P_CONTAINER CHAR(10),
P_RETAILPRICE DECIMAL,
P_COMMENT VARCHAR(23)
);
COPY part FROM '/tmp/dss-data-copy/part.csv' WITH csv DELIMITER '|';
COMMIT;
BEGIN;
CREATE TABLE REGION (
R_REGIONKEY SERIAL,
R_NAME CHAR(25),
R_COMMENT VARCHAR(152)
);
COPY region FROM '/tmp/dss-data-copy/region.csv' WITH (FORMAT csv, DELIMITER '|');
COMMIT;
BEGIN;
CREATE TABLE NATION (
N_NATIONKEY SERIAL,
N_NAME CHAR(25),
N_REGIONKEY BIGINT NOT NULL, -- references R_REGIONKEY
N_COMMENT VARCHAR(152)
);
COPY nation FROM '/tmp/dss-data-copy/nation.csv' WITH (FORMAT csv, DELIMITER '|');
COMMIT;
BEGIN;
CREATE TABLE SUPPLIER (
S_SUPPKEY SERIAL,
S_NAME CHAR(25),
S_ADDRESS VARCHAR(40),
S_NATIONKEY BIGINT NOT NULL, -- references N_NATIONKEY
S_PHONE CHAR(15),
S_ACCTBAL DECIMAL,
S_COMMENT VARCHAR(101)
);
COPY supplier FROM '/tmp/dss-data-copy/supplier.csv' WITH (FORMAT csv, DELIMITER '|');
COMMIT;
BEGIN;
CREATE TABLE CUSTOMER (
C_CUSTKEY SERIAL,
C_NAME VARCHAR(25),
C_ADDRESS VARCHAR(40),
C_NATIONKEY BIGINT NOT NULL, -- references N_NATIONKEY
C_PHONE CHAR(15),
C_ACCTBAL DECIMAL,
C_MKTSEGMENT CHAR(10),
C_COMMENT VARCHAR(117)
);
COPY customer FROM '/tmp/dss-data-copy/customer.csv' WITH (FORMAT csv, DELIMITER '|');
COMMIT;
BEGIN;
CREATE TABLE PARTSUPP (
PS_PARTKEY BIGINT NOT NULL, -- references P_PARTKEY
PS_SUPPKEY BIGINT NOT NULL, -- references S_SUPPKEY
PS_AVAILQTY INTEGER,
PS_SUPPLYCOST DECIMAL,
PS_COMMENT VARCHAR(199)
);
COPY partsupp FROM '/tmp/dss-data-copy/partsupp.csv' WITH (FORMAT csv, DELIMITER '|');
COMMIT;
BEGIN;
CREATE TABLE ORDERS (
O_ORDERKEY SERIAL,
O_CUSTKEY BIGINT NOT NULL, -- references C_CUSTKEY
O_ORDERSTATUS CHAR(1),
O_TOTALPRICE DECIMAL,
O_ORDERDATE DATE,
O_ORDERPRIORITY CHAR(15),
O_CLERK CHAR(15),
O_SHIPPRIORITY INTEGER,
O_COMMENT VARCHAR(79)
);
COPY orders FROM '/tmp/dss-data-copy/orders.csv' WITH (FORMAT csv, DELIMITER '|');
COMMIT;
BEGIN;
CREATE TABLE LINEITEM (
L_ORDERKEY BIGINT NOT NULL, -- references O_ORDERKEY
L_PARTKEY BIGINT NOT NULL, -- references P_PARTKEY (compound fk to PARTSUPP)
L_SUPPKEY BIGINT NOT NULL, -- references S_SUPPKEY (compound fk to PARTSUPP)
L_LINENUMBER INTEGER,
L_QUANTITY DECIMAL,
L_EXTENDEDPRICE DECIMAL,
L_DISCOUNT DECIMAL,
L_TAX DECIMAL,
L_RETURNFLAG CHAR(1),
L_LINESTATUS CHAR(1),
L_SHIPDATE DATE,
L_COMMITDATE DATE,
L_RECEIPTDATE DATE,
L_SHIPINSTRUCT CHAR(25),
L_SHIPMODE CHAR(10),
L_COMMENT VARCHAR(44)
);
COPY lineitem FROM '/tmp/dss-data-copy/lineitem.csv' WITH (FORMAT csv, DELIMITER '|');
COMMIT;
附录二:查询语句
Q1:
-- using 1471398061 as a seed to the RNG
select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count(*) as count_order
from
lineitem
where
l_shipdate <= date '1998-12-01' - interval '85' day
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus
LIMIT 1;
Q2:
-- using 1471398061 as a seed to the RNG
select
s_acctbal,
s_name,
n_name,
p_partkey,
p_mfgr,
s_address,
s_phone,
s_comment
from
part,
supplier,
partsupp,
nation,
region
where
p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and p_size = 48
and p_type like '%STEEL'
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'AFRICA'
and ps_supplycost = (
select
min(ps_supplycost)
from
partsupp,
supplier,
nation,
region
where
p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'AFRICA'
)
order by
s_acctbal desc,
n_name,
s_name,
p_partkey
LIMIT 100;
Q3:
-- using 1471398061 as a seed to the RNG
select
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) as revenue,
o_orderdate,
o_shippriority
from
customer,
orders,
lineitem
where
c_mktsegment = 'HOUSEHOLD'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < date '1995-03-03'
and l_shipdate > date '1995-03-03'
group by
l_orderkey,
o_orderdate,
o_shippriority
order by
revenue desc,
o_orderdate
LIMIT 10;
Q4:
-- using 1471398061 as a seed to the RNG
select
o_orderpriority,
count(*) as order_count
from
orders
where
o_orderdate >= date '1993-06-01'
and o_orderdate < date '1993-06-01' + interval '3' month
and exists (
select
*
from
lineitem
where
l_orderkey = o_orderkey
and l_commitdate < l_receiptdate
)
group by
o_orderpriority
order by
o_orderpriority
LIMIT 1;
Q5:
-- using 1471398061 as a seed to the RNG
select
n_name,
sum(l_extendedprice * (1 - l_discount)) as revenue
from
customer,
orders,
lineitem,
supplier,
nation,
region
where
c_custkey = o_custkey
and l_orderkey = o_orderkey
and l_suppkey = s_suppkey
and c_nationkey = s_nationkey
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'AMERICA'
and o_orderdate >= date '1993-01-01'
and o_orderdate < date '1993-01-01' + interval '1' year
group by
n_name
order by
revenue desc
LIMIT 1;
Q6:
-- using 1471398061 as a seed to the RNG
select
sum(l_extendedprice * l_discount) as revenue
from
lineitem
where
l_shipdate >= date '1993-01-01'
and l_shipdate < date '1993-01-01' + interval '1' year
and l_discount between 0.02 - 0.01 and 0.02 + 0.01
and l_quantity < 24
LIMIT 1;
Q7:
-- using 1471398061 as a seed to the RNG
select
supp_nation,
cust_nation,
l_year,
sum(volume) as revenue
from
(
select
n1.n_name as supp_nation,
n2.n_name as cust_nation,
extract(year from l_shipdate) as l_year,
l_extendedprice * (1 - l_discount) as volume
from
supplier,
lineitem,
orders,
customer,
nation n1,
nation n2
where
s_suppkey = l_suppkey
and o_orderkey = l_orderkey
and c_custkey = o_custkey
and s_nationkey = n1.n_nationkey
and c_nationkey = n2.n_nationkey
and (
(n1.n_name = 'BRAZIL' and n2.n_name = 'INDONESIA')
or (n1.n_name = 'INDONESIA' and n2.n_name = 'BRAZIL')
)
and l_shipdate between date '1995-01-01' and date '1996-12-31'
) as shipping
group by
supp_nation,
cust_nation,
l_year
order by
supp_nation,
cust_nation,
l_year
LIMIT 1;
Q8:
-- using 1471398061 as a seed to the RNG
select
o_year,
sum(case
when nation = 'INDONESIA' then volume
else 0
end) / sum(volume) as mkt_share
from
(
select
extract(year from o_orderdate) as o_year,
l_extendedprice * (1 - l_discount) as volume,
n2.n_name as nation
from
part,
supplier,
lineitem,
orders,
customer,
nation n1,
nation n2,
region
where
p_partkey = l_partkey
and s_suppkey = l_suppkey
and l_orderkey = o_orderkey
and o_custkey = c_custkey
and c_nationkey = n1.n_nationkey
and n1.n_regionkey = r_regionkey
and r_name = 'ASIA'
and s_nationkey = n2.n_nationkey
and o_orderdate between date '1995-01-01' and date '1996-12-31'
and p_type = 'ECONOMY BURNISHED BRASS'
) as all_nations
group by
o_year
order by
o_year
LIMIT 1;
Q9:
-- using 1471398061 as a seed to the RNG
select
nation,
o_year,
sum(amount) as sum_profit
from
(
select
n_name as nation,
extract(year from o_orderdate) as o_year,
l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity as amount
from
part,
supplier,
lineitem,
partsupp,
orders,
nation
where
s_suppkey = l_suppkey
and ps_suppkey = l_suppkey
and ps_partkey = l_partkey
and p_partkey = l_partkey
and o_orderkey = l_orderkey
and s_nationkey = n_nationkey
and p_name like '%powder%'
) as profit
group by
nation,
o_year
order by
nation,
o_year desc
LIMIT 1;-- using 1471398061 as a seed to the RNG
Q10
select
c_custkey,
c_name,
sum(l_extendedprice * (1 - l_discount)) as revenue,
c_acctbal,
n_name,
c_address,
c_phone,
c_comment
from
customer,
orders,
lineitem,
nation
where
c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate >= date '1993-06-01'
and o_orderdate < date '1993-06-01' + interval '3' month
and l_returnflag = 'R'
and c_nationkey = n_nationkey
group by
c_custkey,
c_name,
c_acctbal,
c_phone,
n_name,
c_address,
c_comment
order by
revenue desc
LIMIT 20;
Q11
-- using 1471398061 as a seed to the RNG
select
ps_partkey,
sum(ps_supplycost * ps_availqty) as value
from
partsupp,
supplier,
nation
where
ps_suppkey = s_suppkey
and s_nationkey = n_nationkey
and n_name = 'PERU'
group by
ps_partkey having
sum(ps_supplycost * ps_availqty) > (
select
sum(ps_supplycost * ps_availqty) * 0.0001000000
from
partsupp,
supplier,
nation
where
ps_suppkey = s_suppkey
and s_nationkey = n_nationkey
and n_name = 'PERU'
)
order by
value desc
LIMIT 1;-- using 1471398061 as a seed to the RNG
Q12
select
l_shipmode,
sum(case
when o_orderpriority = '1-URGENT'
or o_orderpriority = '2-HIGH'
then 1
else 0
end) as high_line_count,
sum(case
when o_orderpriority <> '1-URGENT'
and o_orderpriority <> '2-HIGH'
then 1
else 0
end) as low_line_count
from
orders,
lineitem
where
o_orderkey = l_orderkey
and l_shipmode in ('REG AIR', 'RAIL')
and l_commitdate < l_receiptdate
and l_shipdate < l_commitdate
and l_receiptdate >= date '1993-01-01'
and l_receiptdate < date '1993-01-01' + interval '1' year
group by
l_shipmode
order by
l_shipmode
LIMIT 1;-- using 1471398061 as a seed to the RNG
Q13
select
c_count,
count(*) as custdist
from
(
select
c_custkey,
count(o_orderkey)
from
customer left outer join orders on
c_custkey = o_custkey
and o_comment not like '%pending%packages%'
group by
c_custkey
) as c_orders (c_custkey, c_count)
group by
c_count
order by
custdist desc,
c_count desc
Q14
LIMIT 1;-- using 1471398061 as a seed to the RNG
select
100.00 * sum(case
when p_type like 'PROMO%'
then l_extendedprice * (1 - l_discount)
else 0
end) / sum(l_extendedprice * (1 - l_discount)) as promo_revenue
from
lineitem,
part
where
l_partkey = p_partkey
and l_shipdate >= date '1993-09-01'
and l_shipdate < date '1993-09-01' + interval '1' month
LIMIT 1;
Q15
-- using 1471398061 as a seed to the RNG
create view revenue0 (supplier_no, total_revenue) as
select
l_suppkey,
sum(l_extendedprice * (1 - l_discount))
from
lineitem
where
l_shipdate >= date '1994-11-01'
and l_shipdate < date '1994-11-01' + interval '3' month
group by
l_suppkey;
select
s_suppkey,
s_name,
s_address,
s_phone,
total_revenue
from
supplier,
revenue0
where
s_suppkey = supplier_no
and total_revenue = (
select
max(total_revenue)
from
revenue0
)
order by
s_suppkey
LIMIT 1;
Q16
drop view revenue0;-- using 1471398061 as a seed to the RNG
select
p_brand,
p_type,
p_size,
count(distinct ps_suppkey) as supplier_cnt
from
partsupp,
part
where
p_partkey = ps_partkey
and p_brand <> 'Brand#22'
and p_type not like 'STANDARD PLATED%'
and p_size in (34, 17, 18, 16, 15, 49, 1, 48)
and ps_suppkey not in (
select
s_suppkey
from
supplier
where
s_comment like '%Customer%Complaints%'
)
group by
p_brand,
p_type,
p_size
order by
supplier_cnt desc,
p_brand,
p_type,
p_size
LIMIT 1;
Q17:
-- using 1471398061 as a seed to the RNG
select
sum(l_extendedprice) / 7.0 as avg_yearly
from
lineitem,
part,
(SELECT l_partkey AS agg_partkey, 0.2 * avg(l_quantity) AS avg_quantity FROM lineitem GROUP BY l_partkey) part_agg
where
p_partkey = l_partkey
and agg_partkey = l_partkey
and p_brand = 'Brand#21'
and p_container = 'JUMBO JAR'
and l_quantity < avg_quantity
LIMIT 1;
Q18
-- using 1471398061 as a seed to the RNG
select
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalprice,
sum(l_quantity)
from
customer,
orders,
lineitem
where
o_orderkey in (
select
l_orderkey
from
lineitem
group by
l_orderkey having
sum(l_quantity) > 312
)
and c_custkey = o_custkey
and o_orderkey = l_orderkey
group by
c_name,
c_custkey,
o_orderkey,
o_orderdate,
o_totalprice
order by
o_totalprice desc,
o_orderdate
LIMIT 100;-- using 1471398061 as a seed to the RNG
Q19
select
sum(l_extendedprice* (1 - l_discount)) as revenue
from
lineitem,
part
where
(
p_partkey = l_partkey
and p_brand = 'Brand#42'
and p_container in ('SM CASE', 'SM BOX', 'SM PACK', 'SM PKG')
and l_quantity >= 7 and l_quantity <= 7 + 10
and p_size between 1 and 5
and l_shipmode in ('AIR', 'AIR REG')
and l_shipinstruct = 'DELIVER IN PERSON'
)
or
(
p_partkey = l_partkey
and p_brand = 'Brand#22'
and p_container in ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK')
and l_quantity >= 20 and l_quantity <= 20 + 10
and p_size between 1 and 10
and l_shipmode in ('AIR', 'AIR REG')
and l_shipinstruct = 'DELIVER IN PERSON'
)
or
(
p_partkey = l_partkey
and p_brand = 'Brand#25'
and p_container in ('LG CASE', 'LG BOX', 'LG PACK', 'LG PKG')
and l_quantity >= 21 and l_quantity <= 21 + 10
and p_size between 1 and 15
and l_shipmode in ('AIR', 'AIR REG')
and l_shipinstruct = 'DELIVER IN PERSON'
)
LIMIT 1;
Q20
-- using 1471398061 as a seed to the RNG
select
s_name,
s_address
from
supplier,
nation
where
s_suppkey in (
select
ps_suppkey
from
partsupp,
(
select
l_partkey agg_partkey,
l_suppkey agg_suppkey,
0.5 * sum(l_quantity) AS agg_quantity
from
lineitem
where
l_shipdate >= date '1994-01-01'
and l_shipdate < date '1994-01-01' + interval '1' year
group by
l_partkey,
l_suppkey
) agg_lineitem
where
agg_partkey = ps_partkey
and agg_suppkey = ps_suppkey
and ps_partkey in (
select
p_partkey
from
part
where
p_name like 'forest%'
)
and ps_availqty > agg_quantity
)
and s_nationkey = n_nationkey
and n_name = 'FRANCE'
order by
s_name
LIMIT 1;
Q21
-- using 1471398061 as a seed to the RNG
select
s_name,
count(*) as numwait
from
supplier,
lineitem l1,
orders,
nation
where
s_suppkey = l1.l_suppkey
and o_orderkey = l1.l_orderkey
and o_orderstatus = 'F'
and l1.l_receiptdate > l1.l_commitdate
and exists (
select
*
from
lineitem l2
where
l2.l_orderkey = l1.l_orderkey
and l2.l_suppkey <> l1.l_suppkey
)
and not exists (
select
*
from
lineitem l3
where
l3.l_orderkey = l1.l_orderkey
and l3.l_suppkey <> l1.l_suppkey
and l3.l_receiptdate > l3.l_commitdate
)
and s_nationkey = n_nationkey
and n_name = 'GERMANY'
group by
s_name
order by
numwait desc,
s_name
LIMIT 100;
Q22
-- using 1471398061 as a seed to the RNG
select
cntrycode,
count(*) as numcust,
sum(c_acctbal) as totacctbal
from
(
select
substring(c_phone from 1 for 2) as cntrycode,
c_acctbal
from
customer
where
substring(c_phone from 1 for 2) in
('16', '10', '34', '26', '33', '18', '11')
and c_acctbal > (
select
avg(c_acctbal)
from
customer
where
c_acctbal > 0.00
and substring(c_phone from 1 for 2) in
('16', '10', '34', '26', '33', '18', '11')
)
and not exists (
select
*
from
orders
where
o_custkey = c_custkey
)
) as custsale
group by
cntrycode
order by
cntrycode
LIMIT 1;GreenPlum简单性能测试与分析--续的更多相关文章
- Greenplum 简单性能测试与分析
如今,多样的交易模式以及大众消费观念的改变使得数据库应用领域不断扩大,现代的大型分布式应用系统的数据膨胀也对数据库的海量数据处理能力和并行处理能力提出了更高的要求,如何在数据呈现海量扩张的同时提高处理 ...
- GreenPlum简单性能测试与分析
版权声明:本文由黄辉原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/195 来源:腾云阁 https://www.qclou ...
- GREENPLUM简单介绍
原帖:http://www.itpub.net/thread-1409964-1-1.html 什么是GREENPLUM? 对于非常多IT人来说GREENPLUM是个陌生的名字.简单的说它就是一个与O ...
- LoadRunner性能测试结果分析(转载)
性能测试的需求指标:本次测试的要求是验证在30分钟内完成2000次用户登录系统,然后进行考勤业务,最后退出,在业务操作过程中页面的响应时间不超过3秒,并且服务器的CPU使用率.内存使用率分别不超过75 ...
- Linux安装程序Anaconda分析(续)
本来想写篇关于Anaconda的文章,但看到这里写的这么详细,转,原文在这里:Linux安装程序Anaconda分析(续) (1) disptach.py: 下面我们看一下Dispatcher类的主要 ...
- Web项目性能测试结果分析
1.测试结果分析 LoadRunner性能测试结果分析是个复杂的过程,通常可以从结果摘要.并发数.平均事务响应时间.每秒点击数.业务成功率.系统资源.网页细分图.Web服务器资源.数据库服务器资源等几 ...
- jquery实现简单瀑布流布局(续):图片懒加载
# jquery实现简单瀑布流布局(续):图片懒加载 这篇文章是jquery实现简单瀑布流布局思想的小小扩展.代码基于前作的代码继续完善. 图片懒加载就是符合某些条件时才触发图片的加载.最常见的具体表 ...
- LoadRunner性能测试结果分析
LoadRunner性能测试结果分析http://www.docin.com/p-793607435.html
- Apache ab性能测试结果分析
Apache ab性能测试结果分析 测试场景:模拟10个用户,对某页发起总共100次请求. 测试命令: ab -n 100 -c 10 地址 测试报告: Server Software: 被测服务器软 ...
随机推荐
- Maven-009-Nexus 用户密码加密(安全必须)
信息数据大爆发的时代,我们关心什么?没错,数据安全!数据安全!数据安全!(重要事情说三遍,哈哈哈...) 之前我们存放在 maven settings.xml 文件中的 Nexus 私服用户密码都是明 ...
- fiddler实现手机端抓包(代理)
一.fiddler设置代理 1.打开Fiddler->Tools->Fiddler Options在Connection面板里将 Allow remote computers to con ...
- asp.net页面间传值方式
使用asp.net开发项目,必然会在页面间进行传值,本文介绍几种常见的页面传值方式,仅作笔记,以便后续查找使用. 前提:新建两个页面:ValuePage.aspx,ObtainValue.aspx,本 ...
- 《转》Spring4 Freemarker框架搭建学习
这里原帖地址:http://www.cnblogs.com/porcoGT/p/4537064.html 完整配置springmvc4,最终视图选择的是html,非静态文件. 最近自己配置spring ...
- TextToSpeech之阅读文字
创建阅读类 /** * Created by RongGuang on 2014-11-21. * 中文朗读 */ public class ChineseToSpeech { private Tex ...
- 一面cvte
昨天上午去cvte参加一面,和好基友一块,离学校很近,10点多一点到了,一出电梯,傻眼了(不是美女很多),是人真的很多,等了2个小时才轮到我们,一个hr面3个人,我和基友,还有一个本科小盆友,问了5个 ...
- IIS 服务没有及时响应启动或控制请求
微软刚发布的补丁的原因,据说补丁KB939373.KB942831都会影响iis的正常运行,但是我在“添加或删除程序里”(要勾选:显示更新,才能会显示所打的补丁)没有发现以上两个补丁.最后,我发现把K ...
- Java判断访问设备为手机、微信、PC工具类
package com.lwj.util; import javax.servlet.http.HttpServletRequest; /** * 判断访问设备为PC或者手机--工具类 * * @de ...
- Xcode7编译打包后,iOS9设备无法打开http网址的问题
在info.plist中添加一个节点: <key>NSAppTransportSecurity</key> <dict> <key>NSAllowsAr ...
- Java 基础知识 练习题
利用文本编辑器输入课堂上练习的Hello.java,并在JDK环境下编译和运行.请将程序编译.运行的结果截图.