HDFS 机架感知与副本放置策略
HDFS 机架感知与副本放置策略
机架感知(RackAwareness)
通常,大型 Hadoop 集群会分布在很多机架上,在这种情况下,
- 希望不同节点之间的通信能够尽量发生在同一个机架之内,而不是跨机架。
- 为了提高容错能力,名称节点会尽可能把数据块的副本放到多个机架上。
综合考虑这两点的基础上 Hadoop 设计了机架感知功能
外在脚本实现机架感知
HDFS 不能够自动判断集群中各个 DataNode 的网络拓扑情况。这种机架感知需要 net.topology.script.file.name 属性定义的可执行文件(或者脚本)来实现,文件提供了 DataNode 的IP 地址与机架 rackid 之间的映射关系。NameNode 通过这个映射关系,获得集群中各个 DataNode 机器的机架 rackid。如果 topology.script.file.name 没有设定,则每个 DataNode 的 IP地址都会默认映射成 default-rack,即可同一个机架。
为了获取机架 rackid,可以写一个小脚本来定义 DataNode 的 IP 地址(或DNS域名),并把想要的机架 rackid 打印到标准输出 stdout
这个脚本必须要在配置文件 hadoop-site.xml 里通过属性 ’net.topology.script.file.name’ 来指定。
<property>
<name>net.topology.script.file.name</name>
<value>/root/apps/hadoop-3.2.1/topology.py</value>
</property>
用 Python 语言编写的脚本范例:
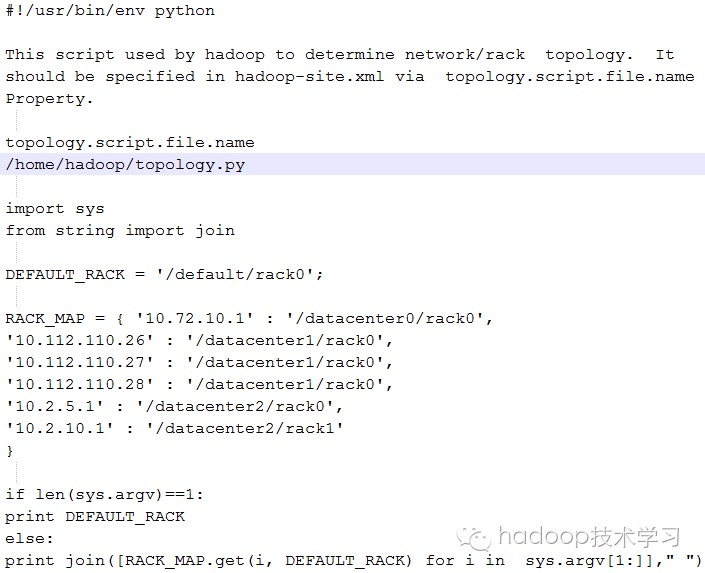
内部Java类实现机架感知
该处采用配置 topology.node.switch.mapping.impl 来实现机架感知,需在 core-site.xml 配置文件中加入以下配置项:
<property>
<name>topology.node.switch.mapping.impl</name>
<value>com.dmp.hadoop.cluster.topology.JavaTestBasedMapping</value>
</property>
还需编写一个JAVA类,一个示例如下所示:
public class JavaTestBasedMapping implements DNSToSwitchMapping {
//key:ip value:rack
private staticConcurrentHashMap<String,String> cache = new ConcurrentHashMap<String,String>();
static {
//rack0 16
cache.put("192.168.5.116","/ht_dc/rack0");
cache.put("192.168.5.117","/ht_dc/rack0");
cache.put("192.168.5.118","/ht_dc/rack0");
cache.put("192.168.5.120","/ht_dc/rack0");
cache.put("192.168.5.121","/ht_dc/rack0");
cache.put("host116","/ht_dc/rack0");
cache.put("host117","/ht_dc/rack0");
cache.put("host118","/ht_dc/rack0");
cache.put("host120","/ht_dc/rack0");
cache.put("host121","/ht_dc/rack0");
}
@Override
publicList<String> resolve(List<String> names) {
List<String>m = new ArrayList<String>();
if (names ==null || names.size() == 0) {
m.add("/default-rack");
return m;
}
for (Stringname : names) {
Stringrack = cache.get(name);
if (rack!= null) {
m.add(rack);
}
}
return m;
}
}
将上述Java类打成jar包,加上执行权限;然后放到$HADOOP_HOME/lib目录下运行。
网络拓扑(NetworkTopology)
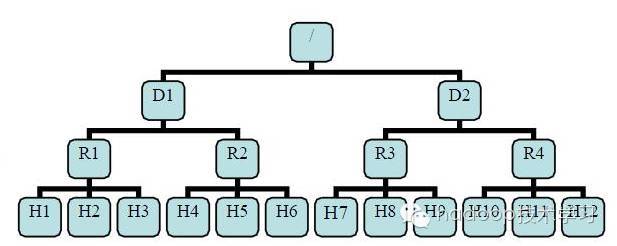
有了机架感知,NameNode 就可以画出上图所示的 DataNode 网络拓扑图。D1,R1都是交换机,最底层是 DataNode。则H1 的 rackid=/D1/R1/H1,H1 的 parent 是R1,R1 的是 D1。这些机架 rackid 信息可以通过 net.topology.script.file.name配置。有了这些机架 rackid 信息就可以计算出任意两台 DataNode 之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
副本放置策略(BPP:blockplacement policy)
- 第一个 block 副本放在和客户端所在的 node 里(如果client不在集群范围内,则这第一个node是随机选取的,当然系统会尝试不选择哪些太满或者太忙的node)。
- 第二个副本放置在与第一个节点不同的机架中的node中(随机选择)。
- 第三个副本和第二个在同一个机架,随机放在不同的node中。
如果还有更多的副本,则在遵循以下限制的前提下随机放置。
- 1个节点最多放置1个副本
- 如果副本数少于2倍机架数,不可以在同一机架放置超过2个副本
当发生数据读取的时候,NameNode 节点首先检查客户端是否位于集群中。如果是的话,就可以按照由近到远的优先次序决定由哪个 DataNode 节点向客户端发送它需要的数据块。也就是说,对于拥有同一数据块副本的节点来说,在网络拓扑中距离客户端近的节点会优先响应。
Hadoop 的副本放置策略在可靠性(block 在不同的机架)和带宽(一个管道只需要穿越一个网络节点)中做了一个很好的平衡。
下图是副本数量为3的情况下一个管道的三个 DataNode的分布情况
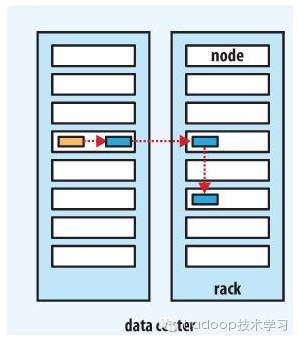
HDFS 机架感知与副本放置策略的更多相关文章
- HDFS副本放置策略和机架感知
副本放置策略 的副本放置策略的基本思想是: 第一block在复制和client哪里node于(假设client它不是群集的范围内,则这第一个node是随机选取的.当然系统会尝试不选择哪些太满或者太忙的 ...
- HDFS网络拓扑概念及机架感知(副本节点选择)
网络拓扑概念 在本地网络中,两个节点被称为“彼此近邻”是什么意思?在海量数据处理中,其主要限制因素是节点之间数据的传输速率——带宽很稀缺.这里将两个节点间的带宽作为距离的衡量标准. 节点距离:两个节点 ...
- HDFS机架感知功能原理(rack awareness)
转自:http://www.jianshu.com/p/372d25352d3a HDFS NameNode对文件块复制相关所有事物负责,它周期性接受来自于DataNode的HeartBeat和Blo ...
- hadoop(三):hdfs 机架感知
client 向 Active NN 发送写请求时,NN为这些数据分配DN地址,HDFS文件块副本的放置对于系统整体的可靠性和性能有关键性影响.一个简单但非优化的副本放置策略是,把副本分别放在不同机架 ...
- [HDFS_add_3] HDFS 机架感知
0. 说明 HDFS 副本存放策略 && 配置机架感知 1. HDFS 的副本存放策略 HDFS 的副本存放策略是将一个副本存放在本地机架节点上,另外两个副本放在不同机架的不同节点上 ...
- Hadoop 副本放置策略的源码阅读和设置
本文通过MetaWeblog自动发布,原文及更新链接:https://extendswind.top/posts/technical/hadoop_block_placement_policy 大多数 ...
- 014_HDFS存储架构、架构可靠性分析、副本放置策略、各组件之间的关系
1.HDFS存储架构
- HDFS副本放置策略
1.第一个副本放置在上传文件的DataNode上,如果是集群外提交,则随机挑选一个磁盘不太满,CPU不太忙的节点. 2.第二个副本放置在与第一个副本不同的机架上. 3.第三个副本放置在与第二个副本同机 ...
- hdfs 机架感知
一.背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高 ...
- HDFS机架感知
Hadoop版本:2.9.2 什么是机架感知 通常大型 Hadoop 集群是以机架的形式来组织的,同一个机架上的不同节点间的网络状况比不同机架之间的更为理想,NameNode 设法将数据块副本保存在不 ...
随机推荐
- Spyder无法使用搜狗输入中文的解决办法
Ubuntu 18.04 LTS系统下,spyder4编辑器无法使用搜狗输入中文.系统输入法为fcitx+搜狗拼音,chrome浏览器无此问题.网上答案: Spyder (以及其他PyQt程序) 无法 ...
- 利用shell脚本来监控linux系统的负载与CPU占用情况
一.安装linux下面的一个邮件客户端msmtp软件(类似于一个foxmail的工具) 1.下载安装: http://downloads.sourceforge.net/msmtp/msmtp-1.4 ...
- Java基础学习:8、构造器(构造方法)和this
一.构造器: 1.定义:构造器是类的特殊方法,它的主要作用是完成对象的初始化. 即在创建对象时初始化对象. 本质是方法. 2.特点: a.方法名和类名一致. b.无返回值. c. ...
- css可继承与不可继承的属性
一.可继承性的属性 字体相关的:font-size/font-family/font-weight/font-style/font-variant/font-stretch 文本相关的:color/t ...
- CTF Show web入门 1——20(信息收集)wp和一些感想
web1 信息搜集 此题为 [从0开始学web]系列第一题 此系列题目从最基础开始,题目遵循循序渐进的原则 希望对学习CTF WEB的同学有所帮助. 开发注释未及时删除 此题有以上备注,可以想到备注未 ...
- Linux LVM分区相关知识
Linux分区有多种方式,一种是LVM格式的比较方便,另一种是标准分区扩容比较麻烦,麻烦的事情那么出错的概率也就越大,所以建议生产环境上分区都使用LVM格式硬盘分区. 一. 什么叫LVM? L ...
- 《Spring Boot从零开始学(视频教学版)》快速入门Spring Boot应用开发
#好书推荐##好书奇遇季#<Spring Boot从零开始学(视频教学版)>,目前为止较好的一本Spring Boot入门书.京东当当天猫都有发售.本书配套示例代码.课件与教学视频.定价7 ...
- kernel32.dll函数简介
kernel32.dll是非常重要的32位动态链接库文件,属于内核级文件.它控制着系统的内存管理.数据的输入输出操作和中断处理,当Windows启动时,kernel32.dll就驻留在内存中特定的写保 ...
- 用dig或nslookup命令查询txt解析记录
这几天想把HTTPS装上,阿里云的免费证书需要在域名解析的地方添加TXT记录.文档里用的是dig命令,我本地装了nslookup.试验下如何用咯. dig命令 dig用法很多,这里只使用dig txt ...
- llinux day02 基础操作 帮助 文件管理 马
免密码登录(只是为了方便教学,免了图形界面的密码) 1,Linux免密自动以root身份登录图形化界面,修改etc/gdm/custom.conf 在deamon下面添加两行,注意区分大小写 [dae ...