java自带的四种线程池
java预定义的哪四种线程池?
- newSingleThreadExexcutor:单线程数的线程池(核心线程数=最大线程数=1)
- newFixedThreadPool:固定线程数的线程池(核心线程数=最大线程数=自定义)
- newCacheThreadPool:可缓存的线程池(核心线程数=0,最大线程数=Integer.MAX_VALUE)
- newScheduledThreadPool:支持定时或周期任务的线程池(核心线程数=自定义,最大线程数=Integer.MAX_VALUE)
四种线程池有什么区别?
上面四种线程池类都继承ThreadPoolExecutor,在创建时都是直接返回new ThreadPoolExecutor(参数),它们的区别是定义的ThreadPoolExecutor(参数)中参数不同,而ThreadPoolExecutor又继承ExecutorService接口类
- newFixedThreadPool
定义:
ExecutorService executorService=Executors.newFixedThreadPool(2);
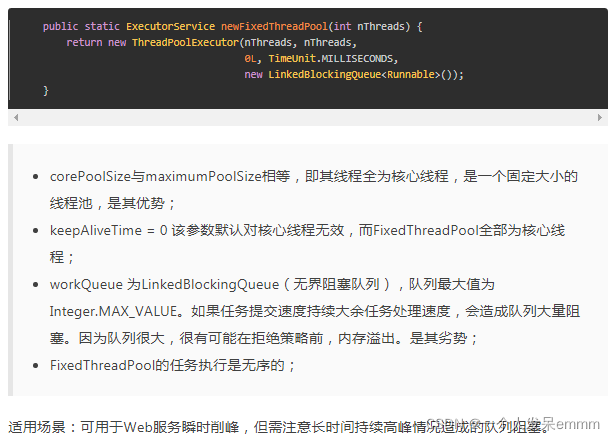
缺点:使用了LinkBlockQueue的链表型阻塞队列,当任务的堆积速度大于处理速度时,容易堆积任务而导致OOM内存溢出
- newSingleThreadExecutor
定义:ExecutorService executorService =Executors.newSingleThreadExecutor();
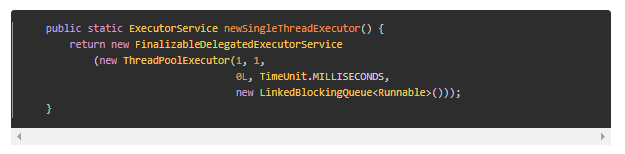
上面代码神似new FixedThreadPoop(1),但又有区别,因为外面多了一层FinalizableDelegatedExecutorService,其作用:
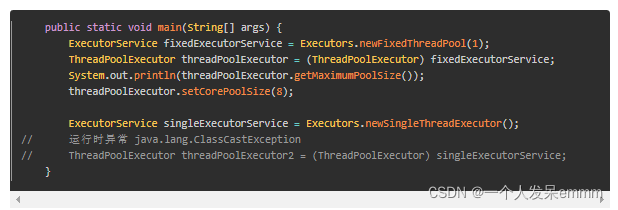
可知,fixedExecutorService的本质是ThreadPoolExecutor,所以fixedExecutorService可以强转成ThreadPoolExecutor,但singleExecutorService与ThreadPoolExecutor无任何关系,所以强转失败,故newSingleThreadExecutor()被创建后,无法再修改其线程池参数,真正地做到single单个线程。
缺点:使用了LinkBlockQueue的链表型阻塞队列,当任务的堆积速度大于处理速度时,容易堆积任务而导致OOM内存溢出
- newCacheThreadPool
定义:ExecutorService executorService=Executors.newCacheThreadPool();
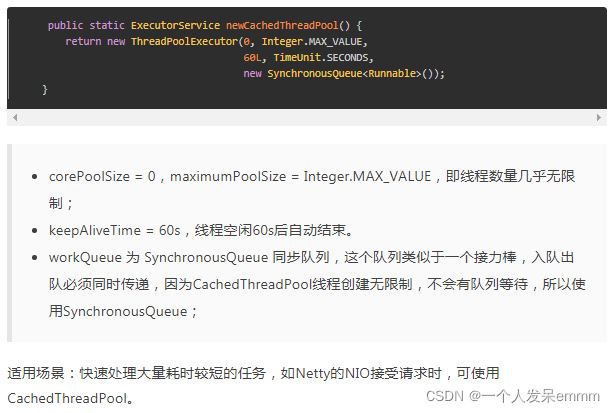
缺点:SynchronousQueue是BlockingQueue的一种实现,它也是一个队列,因为最大线程数为Integer.MAX_VALUE,所有当线程过多时容易OOM内存溢出
- ScheduledThreadPool
定义:ExecutorService executorService=Executors.newScheduledThreadPool(2);
源码:
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
//ScheduledThreadPoolExecutor继承ThreadPoolExecutor
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
//ScheduledThreadPoolExecutor继承ThreadPoolExecutor,故super()会调用ThreadPoolExecutor的构造函数初始化并返回一个ThreadPoolExecutor,而ThreadPoolExecutor使实现ExecutorService接口的
//最终ScheduledThreadPoolExecutor也和上面几种线程池一样返回的是ExecutorService接口的实现类ThreadPoolExecutor
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
线程池有哪几个重要参数?
ThreadPoolExecutor构造方法如下:
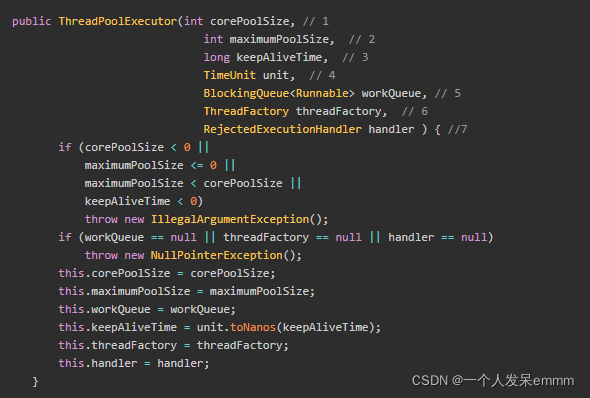
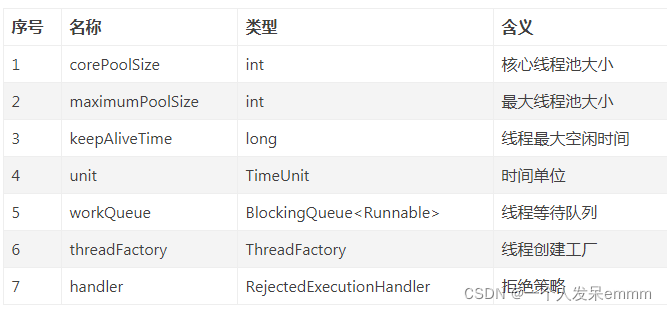
- keepAliveTime是指当前线程数位于 [核心线程数,最大线程数] 之间的这些非核心线程等待多久空闲时间而没有活干时,就退出线程池;
- 等待丢列的大小与最大线程数是没有任何关系的,线程创建优先级=核心线程 > 阻塞队列 > 扩容的线程(当前核心线程数小于最大线程数时才能扩容线程)
- 假如核心线程数5,等待队列长度为3,最大线程数10:当线程数不断在增加时,先创建5个核心线程,核心线程数满了再把线程丢进等待丢列,等待队列满了(3个线程),此时会比较最大线程数(只有等待丢列满了最大线程数才能出场),还可以继续创建2个线程(5+3+2),若线程数超过了最大线程数,则执行拒绝策略;
- 假如核心线程数5,等待队列长度为3,最大线程数7:当线程数不断在增加时,先创建5个核心线程,核心线程数满了再把线程丢进等待丢列,当等待队列中有2个线程时达到了最大线程数(5+2=7),但是等待丢列还没满所以不用管最大线程数,直到等待丢列满了(3个阻塞线程),此时会比较最大线程数(只有等待丢列满了最大线程数才能出场),此时核心+等待丢列=5+3=8>7=最大线程数,即已经达到最大线程数了,则执行拒绝策略;
- 如果把等待丢列设置为LinkedBlockingQueue无界丢列,这个丢列是无限大的,就永远不会走到判断最大线程数那一步了
如何自定义线程池
可以使用有界队列,自定义线程创建工厂ThreadFactory和拒绝策略handler来自定义线程池
public class ThreadTest {
public static void main(String[] args) throws InterruptedException, IOException {
int corePoolSize = 2;
int maximumPoolSize = 4;
long keepAliveTime = 10;
TimeUnit unit = TimeUnit.SECONDS;
BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(2);
ThreadFactory threadFactory = new NameTreadFactory();
RejectedExecutionHandler handler = new MyIgnorePolicy();
ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, unit,
workQueue, threadFactory, handler);
executor.prestartAllCoreThreads(); // 预启动所有核心线程
for (int i = 1; i <= 10; i++) {
MyTask task = new MyTask(String.valueOf(i));
executor.execute(task);
}
System.in.read(); //阻塞主线程
}
static class NameTreadFactory implements ThreadFactory {
private final AtomicInteger mThreadNum = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r, "my-thread-" + mThreadNum.getAndIncrement());
System.out.println(t.getName() + " has been created");
return t;
}
}
public static class MyIgnorePolicy implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
doLog(r, e);
}
private void doLog(Runnable r, ThreadPoolExecutor e) {
// 可做日志记录等
System.err.println( r.toString() + " rejected");
// System.out.println("completedTaskCount: " + e.getCompletedTaskCount());
}
}
static class MyTask implements Runnable {
private String name;
public MyTask(String name) {
this.name = name;
}
@Override
public void run() {
try {
System.out.println(this.toString() + " is running!");
Thread.sleep(3000); //让任务执行慢点
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public String getName() {
return name;
}
@Override
public String toString() {
return "MyTask [name=" + name + "]";
}
}
}
运行结果:

其中7-10号线程被拒绝策略拒绝了,1、2号线程执行完后,3、6号线程进入核心线程池执行,此时4、5号线程在任务队列等待执行,3、6线程执行完再通知4、5线程执行
java自带的四种线程池的更多相关文章
- Java通过Executors提供四种线程池
http://cuisuqiang.iteye.com/blog/2019372 Java通过Executors提供四种线程池,分别为:newCachedThreadPool创建一个可缓存线程池,如果 ...
- Java中常用的四种线程池
在Java中使用线程池,可以用ThreadPoolExecutor的构造函数直接创建出线程池实例,如何使用参见之前的文章Java线程池构造参数详解.不过,在Executors类中,为我们提供了常用线程 ...
- Java四种线程池的使用
Java通过Executors提供四种线程池,分别为:newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程.newFixe ...
- Java 四种线程池的使用
java线程线程池监控 Java通过Executors提供四种线程池,分别为: newCachedThreadPool:创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收 ...
- Java四种线程池的学习与总结
在Java开发中,有时遇到多线程的开发时,直接使用Thread操作,对程序的性能和维护上都是一个问题,使用Java提供的线程池来操作可以很好的解决问题. 一.new Thread的弊端 执行一个异步任 ...
- 【转】Java四种线程池的使用
Java通过Executors提供四种线程池,分别为:newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程.newFixe ...
- 线程池是什么?Java四种线程池的使用介绍
使用线程池的好处有很多,比如节省系统资源的开销,节省创建和销毁线程的时间等,当我们需要处理的任务较多时,就可以使用线程池,可能还有很多用户不知道Java线程池如何使用?下面小编给大家分享Java四种线 ...
- Java 四种线程池newCachedThreadPool,newFixedThreadPool,newScheduledThreadPool,newSingleThreadExecutor
介绍new Thread的弊端及Java四种线程池的使用,对Android同样适用.本文是基础篇,后面会分享下线程池一些高级功能. 1.new Thread的弊端执行一个异步任务你还只是如下new T ...
- Java四种线程池
Java四种线程池newCachedThreadPool,newFixedThreadPool,newScheduledThreadPool,newSingleThreadExecutor 时间:20 ...
随机推荐
- Kerberos与各大组件的集成
1. 概述 Kerberos可以与CDH集成,CDH里面可以管理与hdfs.yarn.hbase.yarn.kafka等相关组件的kerberos凭证.但当我们不使用CDH的时候,也需要了解hdfs. ...
- Java中的软引用、弱引用、虚引用的适用场景以及释放机制
Java的强引用,软引用,弱引用,虚引用及其使用场景 从 JDK1.2 版本开始,把对象的引用分为四种级别,从而使程序能更加灵活的控制对象的生命周期.这四种级别由高到低依次为:强引用.软引用.弱引 ...
- 使用 rabbitmq 的场景?
1.服务间异步通信 2.顺序消费 3.定时任务 4.请求削峰
- 什么是 zuul路由网关?
(1)Zuul 包含了对请求的路由和过滤两个最主要的功能:其中 责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础而过滤器功能则负 请求的处理过程进行干预,是实现请求校验.服务聚合等功 ...
- redis 为什么是单线程的?
一.Redis为什么是单线程的? 因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽.既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理 ...
- Java 中,Serializable 与 Externalizable 的区别?
Serializable 接口是一个序列化 Java 类的接口,以便于它们可以在网络上传输 或者可以将它们的状态保存在磁盘上,是 JVM 内嵌的默认序列化方式,成本高. 脆弱而且不安全.Externa ...
- jdk代理和cglib代理源代码之我见
以前值是读过一遍jdk和cglib的代理,时间长了,都忘记入口在哪里了,值是记得其中的一些重点了,今天写一篇博客,当作是笔记.和以前一样,关键代码,我会用红色标记出来. 首先,先列出我的jdk代理对象 ...
- scrapy --爬取媒体文件示例详解
scrapy 图片数据的爬取 基于scrapy进行图片数据的爬取: 在爬虫文件中只需要解析提取出图片地址,然后将地址提交给管道 配置文件中写入文件存储位置:IMAGES_STORE = './imgs ...
- 学习heartbeat-01简介
1.Heartbeat介绍 Heartbeat 是一个基于Linux开源的,被广泛使用的高可用集群系统,自1999年开始到现在,发布了众多版本,是目前开源Linux-HA项目最成功的一个例子,在行业内 ...
- Java根路径设置(在获取本地路径时会获取到这个文件夹,,这样就可以专门放配置文件了)
在获取本地路径时会获取到这个文件夹,,这样就可以专门放配置文件了