R 数据可视化: PCA 主成分分析图
简介
主成分分析(Principal Component Analysis,PCA)是一种无监督的数据降维方法,通过主成分分析可以尽可能保留下具备区分性的低维数据特征。主成分分析图能帮助我们直观地感受样本在降维后空间中的分簇和聚合情况,这在一定程度上亦能体现样本在原始空间中的分布情况,这对于只能感知三维空间的人类来说,不失为一种不错的选择。
再举个形象的栗子,假如你是一本养花工具宣传册的摄影师,你正在拍摄一个水壶。水壶是三维的,但是照片是二维的,为了更全面的把水壶展示给客户,你需要从不同角度拍几张图片。下图是你从四个方向拍的照片:

第一张图里水壶的背面可以看到,但是看不到前面。
第二张图是拍前面,可以看到壶嘴,这张图可以提供了第一张图缺失的信息,但是壶把看不到了。
第三张俯视图既可以看到壶嘴,也可以看到壶把,但是无法看出壶的高度。
第四张图是你打算放进目录的,水壶的高度,顶部,壶嘴和壶把都清晰可见。
PCA的设计理念与此类似,它可以将高维数据集映射到低维空间的同时,尽可能的保留更多变量。
开始作图
使用 R 语言能做出像 SIMCA-P 一样的 PCA 图吗?
答案是肯定的,使用 R 语言不仅能做出像 SIMCA-P 一样的 PCA 图,还能做出比 SIMCA-P 更好看的图,而且好看的上限仅取决于个人审美风格。
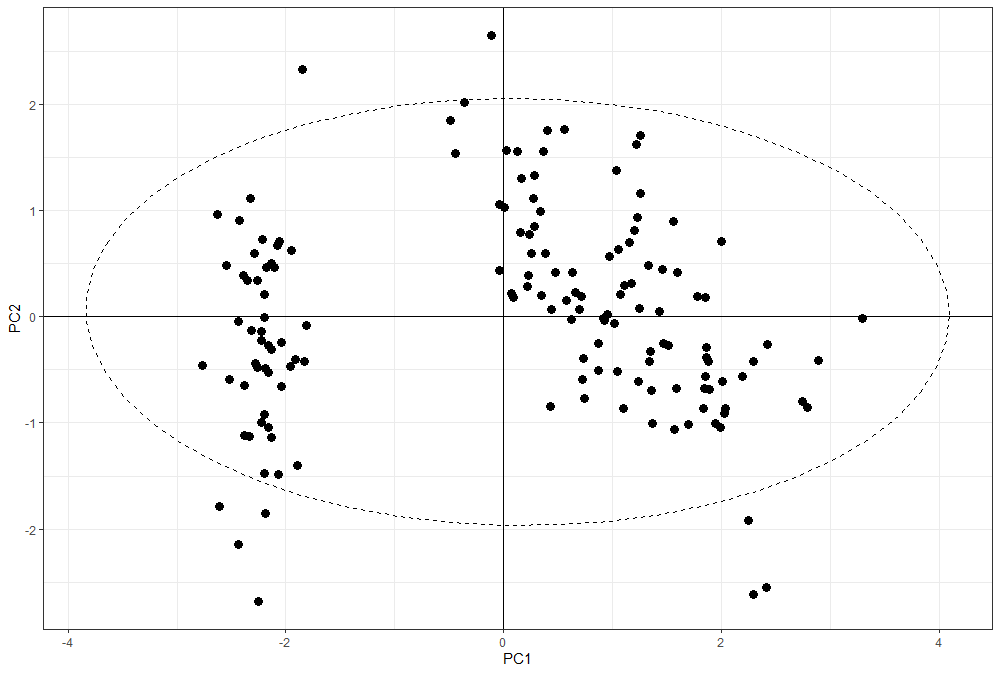
1. PCA 分析图本质上是散点图
主成分分析图 = 散点图 + 置信椭圆,散点的横纵坐标对应 PCA 的第一主成分、第二主成分。
library(ggplot2)
# 数据准备
data = subset(iris, select = -Species)
class = iris[["Species"]]
# PCA
pca = prcomp(data, center = T, scale. = T)
pca.data = data.frame(pca$x)
pca.variance = pca$sdev^2 / sum(pca$sdev^2)
ggplot(pca.data, aes(x = PC1, y = PC2)) +
geom_point(size = 3) +
geom_hline(yintercept = 0) +
geom_vline(xintercept = 0) +
stat_ellipse(aes(x = PC1, y = PC2), linetype = 2, size = 0.5, level = 0.95) +
theme_bw()
2. 为不同类别着色
接下来想给散点加上分类颜色:
library(ggplot2)
# 数据准备
data = subset(iris, select = -Species)
class = iris[["Species"]]
# PCA
pca = prcomp(data, center = T, scale. = T)
pca.data = data.frame(pca$x)
pca.variance = pca$sdev^2 / sum(pca$sdev^2)
ggplot(pca.data, aes(x = PC1, y = PC2, color = class)) +
geom_point(size = 3) +
geom_hline(yintercept = 0) +
geom_vline(xintercept = 0) +
stat_ellipse(aes(x = PC1, y = PC2), linetype = 2, size = 0.5, level = 0.95) +
theme_bw()
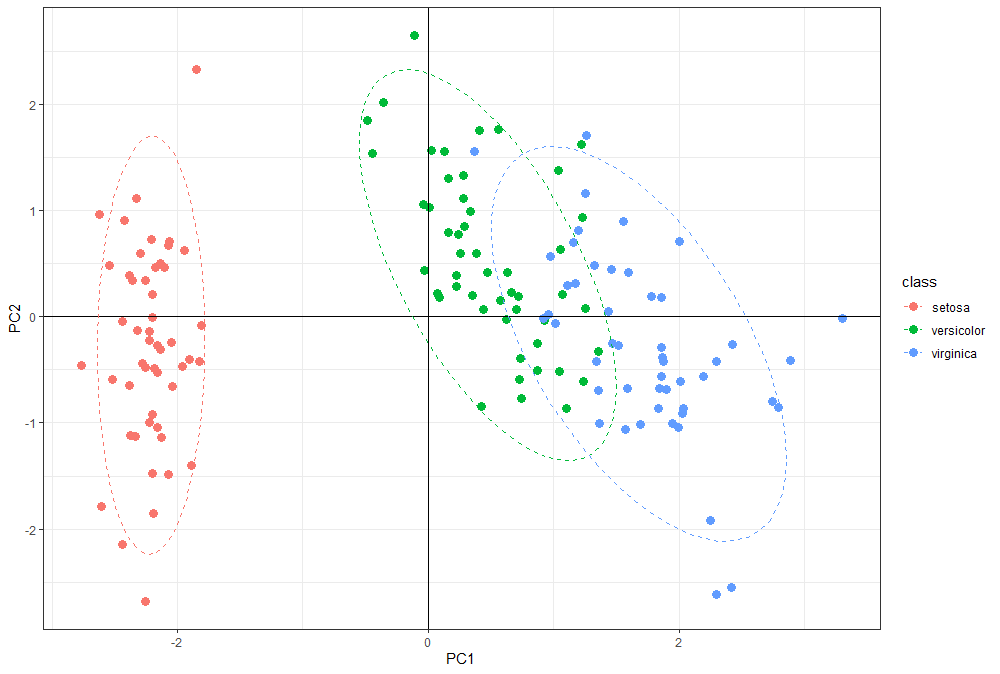
颜色是加上了,但是椭圆咋变成了 3 个?
原来是 stat_ellipse 函数默认对每个类别的数据计算自己的置信区间。如何对多类样本只计算一个置信区间呢?查看 stat_ellipse 的帮助文档:
inherit.aes
default TRUE, If FALSE, overrides the default aesthetics, rather than combining with them. This is most useful for helper functions that define both data and aesthetics and shouldn't inherit behaviour from the default plot specification,
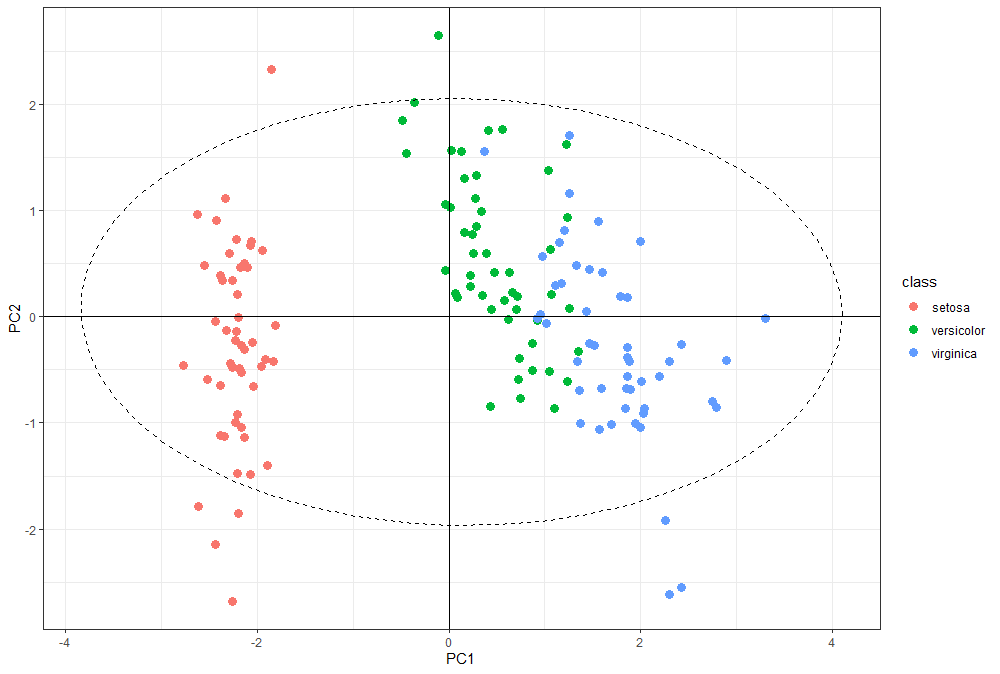
原来是 stat_ellipse 函数默认会继承 ggplot 中的 aes 设置,如果希望 stat_ellipse 使用自己的 aes 设置,需要将参数 inherit.aes 设置为 FALSE。
library(ggplot2)
# 数据准备
data = subset(iris, select = -Species)
class = iris[["Species"]]
# PCA
pca = prcomp(data, center = T, scale. = T)
pca.data = data.frame(pca$x)
pca.variance = pca$sdev^2 / sum(pca$sdev^2)
ggplot(pca.data, aes(x = PC1, y = PC2, color = class)) +
geom_point(size = 3) +
geom_hline(yintercept = 0) +
geom_vline(xintercept = 0) +
stat_ellipse(aes(x = PC1, y = PC2), linetype = 2, size = 0.5, level = 0.95, inherit.aes = FALSE) +
theme_bw()
3. 样式微调
接下来对样式进行微调:为不同类别样本自定义着色,添加 x 轴、y 轴标题,添加 title:
library(ggplot2)
# 数据准备
data = subset(iris, select = -Species)
class = iris[["Species"]]
# PCA
pca = prcomp(data, center = T, scale. = T)
pca.data = data.frame(pca$x)
pca.variance = pca$sdev^2 / sum(pca$sdev^2)
# 自定义颜色
palette = c("mediumseagreen", "darkorange", "royalblue")
ggplot(pca.data, aes(x = PC1, y = PC2, color = class)) +
geom_point(size = 3) +
geom_hline(yintercept = 0) +
geom_vline(xintercept = 0) +
stat_ellipse(aes(x = PC1, y = PC2), linetype = 2, size = 0.5, level = 0.95, inherit.aes = FALSE) +
theme_bw() +
scale_color_manual(values = palette) +
theme(panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
panel.grid.major.y = element_blank(),
panel.grid.minor.y = element_blank()) +
labs(x = paste0("PC1: ", signif(pca.variance[1] * 100, 3), "%"),
y = paste0("PC2: ", signif(pca.variance[2] * 100, 3), "%"),
title = paste0("PCA of iris")) +
theme(plot.title = element_text(hjust = 0.5))
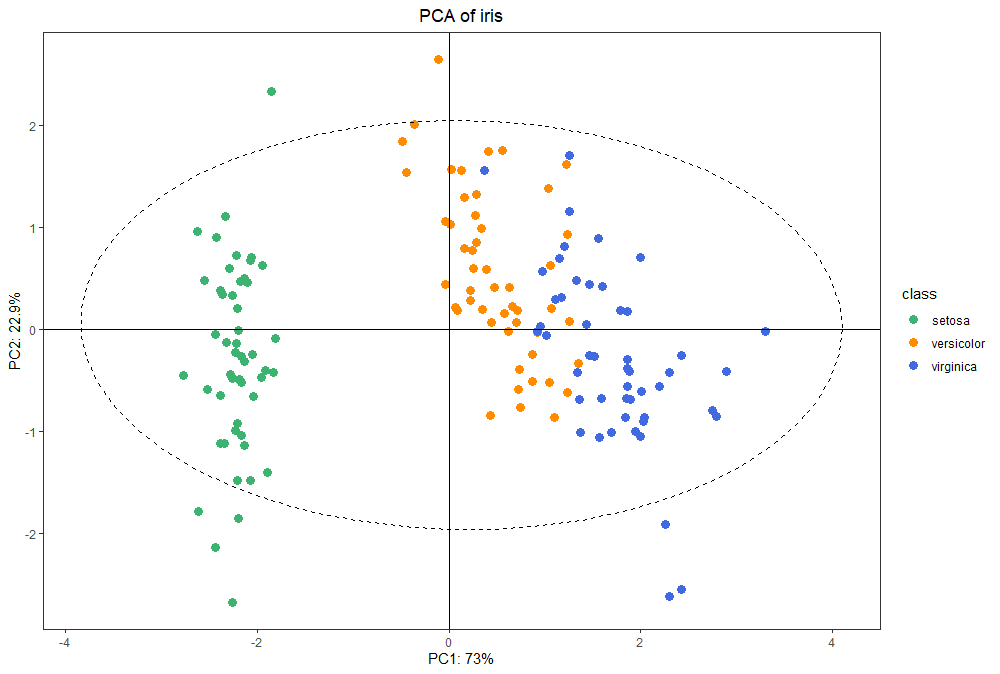
将作图结果和 SIMCA-P 对比,散点、椭圆基本完全一致,只是比它更顺眼一些罢了~
欢迎留言讨论,如果本文有帮助到你,点个赞就更好啦!
参考
[1] Master Machine Learning With scikit-learn
相关文章
[1] R 数据可视化:水平渐变色柱状图
[2] R 数据可视化:双坐标系柱线图
[3] R 数据可视化:BoxPlot
[4] R 数据可视化:环形柱状图
R 数据可视化: PCA 主成分分析图的更多相关文章
- 【笔记】求数据的对应主成分PCA(第一主成分)
求数据的第一主成分 (在notebook中) 将包加载好,再创建出一个虚拟的测试用例,生成的X有两个特征,特征一为0到100之间随机分布,共一百个样本,对于特征二,其和特征一有一个基本的线性关系(为什 ...
- 推荐《R数据可视化手册》高清英文版PDF+中文版PDF+源代码
绝大多数的绘图案例都是以强大.灵活制图而著称的R包ggplot2实现的,充分展现了ggplot2生动.翔实的一面.从如何画点图.线图.柱状图,到如何添加注解.修改坐标轴和图例,再到分面的使用和颜色的选 ...
- R数据可视化手册学习——条形图
1. 绘制简单条形图 # 使用ggplot2和gcookbook library(ggplot2); library(gcookbook) g <- ggplot(data = pg_mean, ...
- R数据可视化手册学习简单的绘制常见的图形
1.绘制散点图 # 使用ggplot2 library(ggplot2) ggplot(data = mtcars, aes(x = wt, y = mpg)) + geom_point() 2.绘制 ...
- 机器学习:PCA(使用梯度上升法求解数据主成分 Ⅰ )
一.目标函数的梯度求解公式 PCA 降维的具体实现,转变为: 方案:梯度上升法优化效用函数,找到其最大值时对应的主成分 w : 效用函数中,向量 w 是变量: 在最终要求取降维后的数据集时,w 是参数 ...
- 【笔记】求数据前n个主成分以及对高维数据映射为低维数据
求数据前n个主成分并进行高维数据映射为低维数据的操作 求数据前n个主成分 先前的将多个样本映射到一个轴上以求使其降维的操作,其中的样本点本身是二维的样本点,将其映射到新的轴上以后,还不是一维的数据,对 ...
- Spark2 oneHot编码--标准化--主成分--聚类
1.导入包 import org.apache.spark.sql.SparkSession import org.apache.spark.sql.Dataset import org.apache ...
- Spark 2.0 PCA主成份分析
PCA在Spark2.0中用法比较简单,只需要设置: .setInputCol(“features”)//保证输入是特征值向量 .setOutputCol(“pcaFeatures”)//输出 .se ...
- 第三篇:数据可视化 - ggplot2
前言 R语言的强大之处在于统计和作图.其中统计部分的内容很多很强大,因此会在以后的实例中逐步介绍:而作图部分的套路相对来说是比较固定的,现在可以先对它做一个总体的认识. 在上一篇文章中,介绍了使用gr ...
随机推荐
- Servlet的会话机制?
因为http协议是无状态协议,又称为一次性连接,所以webapp必须有一种机制 能够记住用户的一系列操作,并且唯一标示一个用户. Cookie: 又称为小饼干,实际就是使用一个短文本保存用户信息, 在 ...
- Mybatis的XML文件调用静态方法
如果需要在Mapper文件中调用静态方法,需要 <choose> // 需要静态方法返回true还是false <when test="@staticClass@stati ...
- Java 中的final关键字有哪些用法?
(1)修饰类:表示该类不能被继承:(2)修饰方法:表示方法不能被重写:(3)修饰变量:表示变量只能一次赋值以后值不能被修改(常量).
- mybatis基础(全)
参考链接:Mybatis学习系列(一)入门简介 Mybatis学习系列(二)Mapper映射文件 Mybatis学习系列(三)动态SQL Mybatis学习系列(四)Mapper接口动态代理 Myba ...
- 学习openstack(八)
一.OpenStack初探 1.1 OpenStack简介 OpenStack是一整套开源软件项目的综合,它允许企业或服务提供者建立.运行自己的云计算和存储设施.Rackspace与NASA是最初 ...
- 【C语言】预处理、宏定义、内联函数 _
一.由源码到可执行程序的过程 1. 预处理: 源码经过预处理器的预处理变成预处理过的.i中间文件 1 gcc -E test.c -o test.i 2. 编译: 中间文件经过编译器编译形成.s的 ...
- simulink中scope图像显示添加图例
1. 在scope中添加图例 (1)首先打开配置属性(configuration properties),在display下面的show legend前面打钩 这样就允许图例显示出来 (2)对scop ...
- MOS管工作原理精讲
- 「入门篇」初识JVM (下下) - GC
垃圾收集主要是针对堆和方法区进行:程序计数器.虚拟机栈和本地方法栈这三个区域属于线程私有的,只存在于> 线程的生命周期内,线程结束之后也会消失,因此不需要对这三个区域进行垃圾回收. GC - J ...
- 技能篇:linux服务性能问题排查及jvm调优思路
只要业务逻辑代码写正确,处理好业务状态在多线程的并发问题,很少会有调优方面的需求.最多就是在性能监控平台发现某些接口的调用耗时偏高,然后再发现某一SQL或第三方接口执行超时之类的.如果你是负责中间件或 ...