08 分布式计算MapReduce--词频统计
def getText():
txt=open("D:\\test.txt","r").read()
txt=txt.lower()
punctuation = r"""!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~“”?,!【】()、。:;’‘……¥·"""
for ch in punctuation:
txt=txt.replace(ch,"")
return txt
hamletTxt=getText()
words=hamletTxt.split()
counts={}
for word in words:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(100):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words=line.split()
for word in words:
print("{}\t{}".format(word,1))
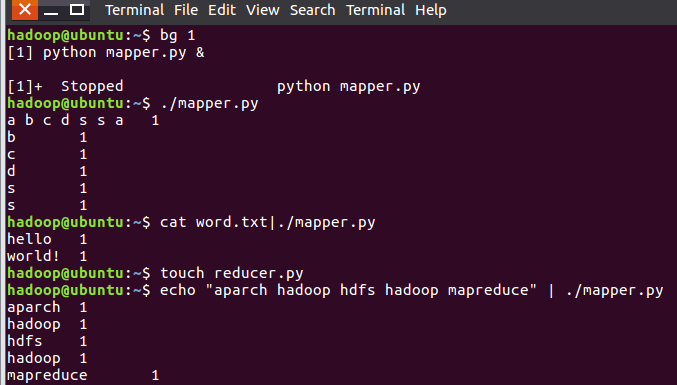
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print "%s\t%s" % (current_word, current_count)
current_count = count
current_word = word
if word == current_word:
print "%s\t%s" % (current_word, current_count)

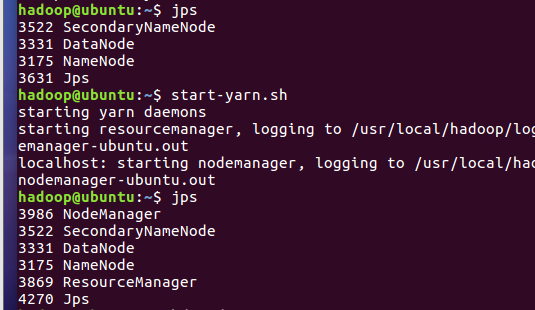
2.3分布式运行自带词频统计示例
- 启动HDFS与YARN
- 准备待处理文件
- 上传HDFS

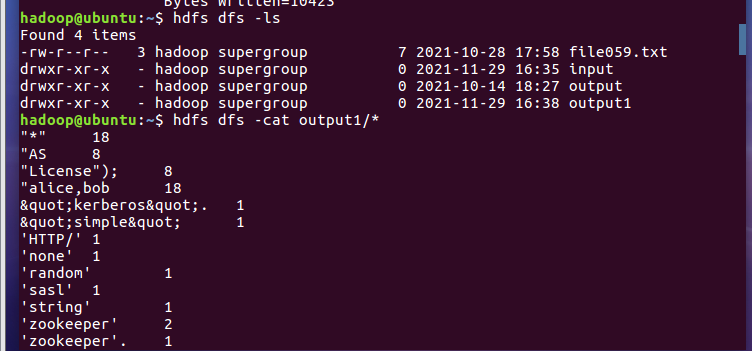
- 运行hadoop-mapreduce-examples-2.7.1.jar

- 查看结果
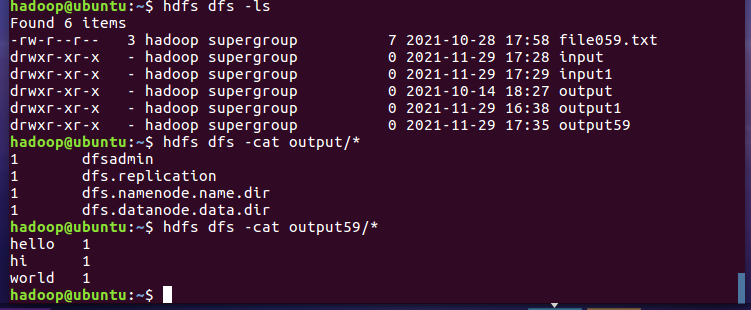
2.4 分布式运行自写的词频统计
- 停止HDFS与YARN

08 分布式计算MapReduce--词频统计的更多相关文章
- MapReduce词频统计
自定义Mapper实现 import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; impor ...
- MapReduce实现词频统计
问题描述:现在有n个文本文件,使用MapReduce的方法实现词频统计. 附上统计词频的关键代码,首先是一个通用的MapReduce模块: class MapReduce: __doc__ = ''' ...
- Hadoop之词频统计小实验
声明: 1)本文由我原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Ubuntu操作系统,hadoop1-2-1,jdk1.8.0. 3)统计词频工作在单节点的伪分布上,至于真正实 ...
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- Hive简单编程实践-词频统计
一.使用MapReduce的方式进行词频统计 (1)在HDFS用户目录下创建input文件夹 hdfs dfs -mkdir input 注意:林子雨老师的博客(http://dblab.xmu.ed ...
- hive进行词频统计
统计文件信息: $ /opt/cdh-5.3.6/hadoop-2.5.0/bin/hdfs dfs -text /user/hadoop/wordcount/input/wc.input hadoo ...
- Hadoop的改进实验(中文分词词频统计及英文词频统计)(4/4)
声明: 1)本文由我bitpeach原创撰写,转载时请注明出处,侵权必究. 2)本小实验工作环境为Windows系统下的百度云(联网),和Ubuntu系统的hadoop1-2-1(自己提前配好).如不 ...
- 初学Hadoop之中文词频统计
1.安装eclipse 准备 eclipse-dsl-luna-SR2-linux-gtk-x86_64.tar.gz 安装 1.解压文件. 2.创建图标. ln -s /opt/eclipse/ec ...
- 初学Hadoop之WordCount词频统计
1.WordCount源码 将源码文件WordCount.java放到Hadoop2.6.0文件夹中. import java.io.IOException; import java.util.Str ...
随机推荐
- tcpdump: error while loading shared libraries: libpcap.so.1: cannot open shared object file: No such file or directory
[root@inner ~]# tcpdump -i any -s 0 -w trunkm.pcaptcpdump: error while loading shared libraries: lib ...
- JS回文检查(FreeCodeCamp项目)
需求 如果传入的字符串是回文字符串,则返回 true. 否则返回 false 回文 palindrome,指在忽略标点符号.大小写和空格的前提下,正着读和反着读一模一样. 注意:检查回文时,你需要先去 ...
- 《Python 3.8从入门到精通(视频教学版)》PDF电子书赠阅
<Python 3.8从入门到精通(视频教学版)>PDF电子书赠阅,个人学习使用,禁止任何形式的商用. https://pan.baidu.com/s/1U_8-N9YJVG8UsUHbQ ...
- 【Ubuntu】Ubuntu 技巧集锦
『Ubuntu 22.04 国内镜像 阿里云/163源/清华大学/中科大』 『各种 Proxy 设置 GUI/Terminal/APT』 『设置 wget Proxy』 『设置右键菜单-新建文档』 『 ...
- ValueError: Unable to determine SOCKS version from socks
unset all_proxy && unset ALL_PROXY export all_proxy="socks5://127.0.0.1:1080" 参考: ...
- java,抽象类,接口的方法,子类继承是不是必须全部实现
普通类继承,并非一定要重写父类方法. 抽象类继承,如果子类也是一个抽象类,并不要求一定重写父类方法.如果子类不是抽象类,则要求子类一定要实现父类中的抽象方法. 接口类继承.如果是一个子接口,可以扩展父 ...
- rdlc 中文在win10中显示异常,在非win10中显示正常
RDLC中的默认字体Arial. 在win10中,RDLC为Arial时,显示中文会异常,这个时候,只需要将Font修改为中文字体就可以了,例如修改为宋体.
- windows 设置修改本地 hosts 访问 github 快速访问 提高访问 github 速度
获取IP地址 查询 以下域名IP地址 github.com github.global.ssl.fastly.net assets-cdn.github.com 通过在线网址查询:https://we ...
- ARC(Automatic Reference Counting)自动引用计数 unowned、weak 使用区别
自动引用计数 引用类型(类.函数.闭包) 当声明一个变量指向某个引用类型时 当前引用类型的引用计数就会加1 当变量不指向该类型时 引用类型就会 -1 当引用计数为0时 当前引用类型就会被系统回收 i ...
- MSSQL 查看数据库所有的触发器
SELECT object_name(a.parent_obj) as [表名] ,a.name as [触发器名称] ,(case when b.is_disabled=0 then '启用' el ...