Shading-JDBC、ShadingSphere、ShardingProxy 使用详解
ShadingSphere
ShardingSphere是一款起源于当当网内部的应用框架,2015年在当当网内部诞生,2016年由主要开发人员张亮带入京东数科,在国内经历了当当网、电信翼支付、京东数科等多家大型互联网企业的考验,在2017年开源。
并逐渐由原本只关注于关系型数据库增强工具的ShardingJDBC升级成为一整套以数据分片为基础的数据生态圈,更名为ShardingSphere;在2020年4月,成为Apache软件基金会顶级项目
Apache ShardingSphere 产品定位为 Database Plus,旨在构建多模数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。ShardingSphere 站在数据库的上层视角,关注他们之间的协作多于数据库自身。
连接、增量 和 可插拔 是 Apache ShardingSphere` 的核心概念。
连接:通过对数据库协议、SQL方言以及数据库存储的灵活适配,快速的连接应用与多模式的异构数据库;增量:获取数据库的访问流量,并提供流量重定向(数据分片、读写分离、影子库)、流量变形(数据加密、数据脱敏)、流量鉴权(安全、审计、权限)、流量治理(熔断、限流)以及流量分析(服务质量分析、可观察性)等透明化增量功能;可插拔:项目采用微内核 + 三层可插拔模型,使内核、功能组件以及生态对接完全能够灵活的方式进行插拔式扩展,开发者能够像使用积木一样定制属于自己的独特系统。

Apache ShardingSphere 由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的基于数据库作为存储节点的增量功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
关系型数据库当今依然占有巨大市场份额,是企业核心系统的基石,未来也难于撼动,我们更加注重在原有基础上提供增量,而非颠覆。
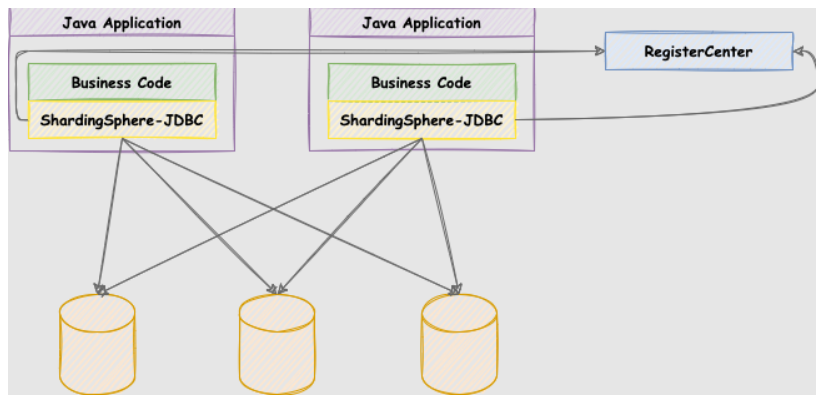
ShardingSphere-JDBC
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
适用于任何基于
JDBC的ORM框架,如:JPA,Hibernate,Mybatis,Spring JDBC Template或直接使用JDBC;支持任何第三方的数据库连接池,如:
DBCP,C3P0,BoneCP,HikariCP等;支持任意实现
JDBC规范的数据库,目前支持MySQL,PostgreSQL,Oracle,SQLServer以及任何可使用JDBC访问的数据库。
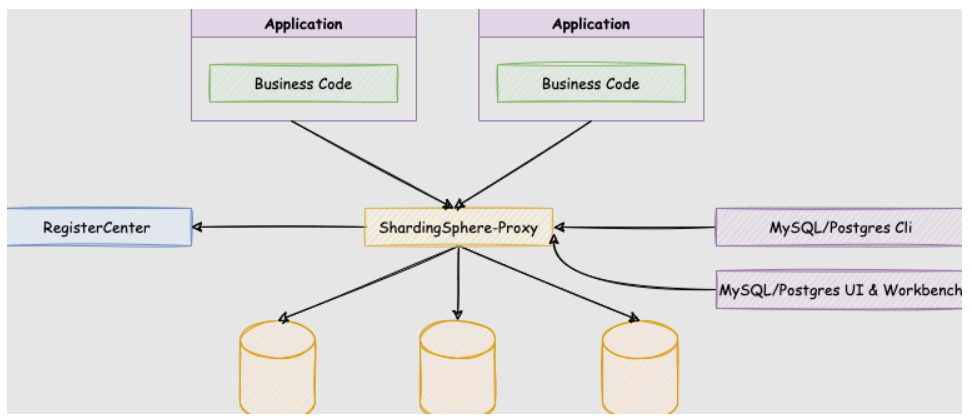
ShardingSphere-Proxy
ShardingSphere-Proxy 是 Apache ShardingSphere 的第二个产品。 它定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前提供 MySQL 和 PostgreSQL(兼容 openGauss 等基于 PostgreSQL 的数据库)版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据,对 DBA 更加友好。
向应用程序完全透明,可直接当做
MySQL/PostgreSQL使用。适用于任何兼容
MySQL/PostgreSQL协议的的客户端。
| 项目说明 | ShardingSphere-JDBC | ShardingSphere-Proxy |
|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 仅Java | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
ShardingSphere-Proxy 的优势在于对异构语言的支持,以及为 DBA 提供可操作入口。
ShadingJDBC使用
① 分片
一般我们在提到分库分表的时候,大多是以水平切分模式(水平分库、分表)为基础来说的,数据分片将原本一张数据量较大的表 t_order 拆分生成数个表结构完全一致的小数据量表 t_order_0、t_order_1、···、t_order_n,每张表只存储原大表中的一部分数据,当执行一条SQL时会通过 分库策略、分片策略 将数据分散到不同的数据库、表内。
② 数据节点
数据节点是分库分表中一个不可再分的最小数据单元(表),它由数据源名称和数据表组成,例如上图中 order_db_1.t_order_0、order_db_2.t_order_1 就表示一个数据节点。
③ 逻辑表
逻辑表是指一组具有相同逻辑和数据结构表的总称。比如我们将订单表t_order 拆分成 t_order_0 ··· t_order_9 等 10张表。此时我们会发现分库分表以后数据库中已不在有 t_order 这张表,取而代之的是 t_order_n,但我们在代码中写 SQL 依然按 t_order 来写。此时 t_order 就是这些拆分表的逻辑表。

④ 真实表
真实表也就是上边提到的 t_order_n 数据库中真实存在的物理表。
⑤ 分片键
用于分片的数据库字段。我们将 t_order 表分片以后,当执行一条SQL时,通过对字段 order_id 取模的方式来决定,这条数据该在哪个数据库中的哪个表中执行,此时 order_id 字段就是 t_order 表的分片健。

⑥ 分片算法
上边我们提到可以用分片健取模的规则分片,但这只是比较简单的一种,在实际开发中我们还希望用 >=、<=、>、<、BETWEEN 和 IN 等条件作为分片规则,自定义分片逻辑,这时就需要用到分片策略与分片算法。
从执行 SQL 的角度来看,分库分表可以看作是一种路由机制,把 SQL 语句路由到我们期望的数据库或数据表中并获取数据,分片算法可以理解成一种路由规则。
咱们先捋一下它们之间的关系,分片策略只是抽象出的概念,它是由分片算法和分片健组合而成,分片算法做具体的数据分片逻辑。
分库、分表的分片策略配置是相对独立的,可以各自使用不同的策略与算法,每种策略中可以是多个分片算法的组合,每个分片算法可以对多个分片健做逻辑判断。

分片算法和分片策略的关系
sharding-jdbc 提供了4种分片算法:
1:精确分片算法
精确分片算法(PreciseShardingAlgorithm)用于单个字段作为分片键,SQL中有 = 与 IN 等条件的分片,需要在标准分片策略(StandardShardingStrategy )下使用。
2:范围分片算法
范围分片算法(RangeShardingAlgorithm)用于单个字段作为分片键,SQL中有 BETWEEN AND、>、<、>=、<= 等条件的分片,需要在标准分片策略(StandardShardingStrategy )下使用。
3:复合分片算法
复合分片算法(ComplexKeysShardingAlgorithm)用于多个字段作为分片键的分片操作,同时获取到多个分片健的值,根据多个字段处理业务逻辑。需要在复合分片策略(ComplexShardingStrategy )下使用。
4:Hint分片算法
Hint分片算法(HintShardingAlgorithm)稍有不同,上边的算法中我们都是解析SQL 语句提取分片键,并设置分片策略进行分片。但有些时候我们并没有使用任何的分片键和分片策略,可还想将 SQL 路由到目标数据库和表,就需要通过手动干预指定SQL的目标数据库和表信息,这也叫强制路由。
注意:sharding-jdbc 并没有直接提供分片算法的实现,需要开发者根据业务自行实现。
⑦ 分片策略
上边讲分片算法的时候已经说过,分片策略是一种抽象的概念,实际分片操作的是由分片算法和分片健来完成的。
1:标准分片策略
标准分片策略适用于单分片键,此策略支持 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。
其中 PreciseShardingAlgorithm 是必选的,用于处理 = 和 IN 的分片。RangeShardingAlgorithm 是可选的,用于处理BETWEEN AND, >, <,>=,<= 条件分片,如果不配置RangeShardingAlgorithm,SQL中的条件等将按照全库路由处理。
2:复合分片策略
复合分片策略,同样支持对 SQL语句中的 =,>, <, >=, <=,IN和 BETWEEN AND 的分片操作。不同的是它支持多分片键,具体分配片细节完全由应用开发者实现。
3:行表达式分片策略 inline
行表达式分片策略,支持对 SQL语句中的 = 和 IN 的分片操作,但只支持单分片键。这种策略通常用于简单的分片,不需要自定义分片算法,可以直接在配置文件中接着写规则。
t_order_$->{t_order_id % 4} 代表 t_order 对其字段 t_order_id取模,拆分成4张表,而表名分别是t_order_0 到 t_order_3。
4:Hint分片策略
Hint分片策略,对应上边的Hint分片算法,通过指定分片健而非从 SQL中提取分片健的方式进行分片的策略。
⑧ 分布式主键
数据分⽚后,不同数据节点⽣成全局唯⼀主键是⾮常棘⼿的问题,同⼀个逻辑表(t_order)内的不同真实表(t_order_n)之间的⾃增键由于⽆法互相感知而产⽣重复主键。
尽管可通过设置⾃增主键 初始值 和 步⻓ 的⽅式避免ID碰撞,但这样会使维护成本加大,乏完整性和可扩展性。如果后去需要增加分片表的数量,要逐一修改分片表的步长,运维成本非常高,所以不建议这种方式。
实现分布式主键⽣成器的方式很多,可以参考我之前写的9种分布式ID生成方式。
为了让上手更加简单,ApacheShardingSphere 内置了UUID、SNOWFLAKE 两种分布式主键⽣成器,默认使⽤雪花算法(snowflake)⽣成64bit的⻓整型数据。不仅如此它还抽离出分布式主键⽣成器的接口,⽅便我们实现⾃定义的⾃增主键⽣成算法。
⑨ 广播表
广播表:存在于所有的分片数据源中的表,表结构和表中的数据在每个数据库中均完全一致。一般是为字典表或者配置表 t_config,某个表一旦被配置为广播表,只要修改某个数据库的广播表,所有数据源中广播表的数据都会跟着同步。
⑩ 绑定表
绑定表:那些分片规则一致的主表和子表。比如:t_order 订单表和 t_order_item 订单服务项目表,都是按 order_id 字段分片,因此两张表互为绑定表关系。
那绑定表存在的意义是啥呢?
通常在我们的业务中都会使用 t_order 和 t_order_item 等表进行多表联合查询,但由于分库分表以后这些表被拆分成N多个子表。如果不配置绑定表关系,会出现笛卡尔积关联查询,将产生如下四条SQL。
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id

笛卡尔积查询
而配置绑定表关系后再进行关联查询时,只要对应表分片规则一致产生的数据就会落到同一个库中,那么只需 t_order_0 和 t_order_item_0 表关联即可。
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
绑定表关系
注意:在关联查询时 t_order 它作为整个联合查询的主表。所有相关的路由计算都只使用主表的策略,t_order_item 表的分片相关的计算也会使用 t_order 的条件,所以要保证绑定表之间的分片键要完全相同。
案例准备
我们基于MyBatisPlus+ShadingJDBC实现数据库分片、读写分离功能,准备了工程shading-jdbc,该工程是一个SpringBoot+MyBatisPlus实现了MySQL增加和查询的案例,我们要将ShadingJDBC集成进来,将它改造成具备分表分库、读写分离的案例。
准备数据库 sd1、sd2,在每个数据库中创建表,
表结构说明: goods 用于数据库分片。goods_0, goods_1用于表分片
创建脚本如下:
-- 数据库sd1
CREATE database `sd1` DEFAULT CHARACTER SET utf8 ;
CREATE TABLE sd1.`goods` (
`id` bigint(20) NOT NULL,
`goods_name` varchar(100) DEFAULT NULL,
`type` bigint(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
create table sd1.`goods_0` as select * from sd1.`goods` where 1=2;
create table sd1.`goods_1` as select * from sd1.`goods` where 1=2;
-- 数据库sd2
CREATE database `sd2` DEFAULT CHARACTER SET utf8 ;
create table sd2.`goods` as select * from sd1.`goods` where 1=2;
create table sd2.`goods_0` as select * from sd1.`goods` where 1=2;
create table sd2.`goods_1` as select * from sd1.`goods` where 1=2;
案例说明:
上面创建的表,虽然是goods_0和goods_1,但案例中Pojo用到了逻辑表,如下:
@Data
@TableName(value = "goods") //这里用的是逻辑表
public class Goods {
@TableId(value = "id",type = IdType.INPUT)
private Long id;
@TableField(value = "goods_name")
private String goodsName;
@TableField(value = "type")
private Long type;
}
处理上面之外,案例提供了三个方法:
package com.execise.controller;
import com.execise.domain.Goods;
import com.execise.service.GoodsService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
@Controller
@RequestMapping("/goods")
public class GoodsController {
@Autowired
private GoodsService goodsService;
@GetMapping
public List<Goods> list(){
return goodsService.list();
}
//@GetMapping("/{id}")
public Goods getOne(@PathVariable int id){
return goodsService.getById(id);
}
@GetMapping("/add/{goodsName}/{type}")
public String add(@PathVariable String goodsName, @PathVariable int type){
Goods goods = new Goods();
goods.setGoodsName(goodsName);
goods.setType(type);
goodsService.save(goods);
return "添加成功!";
}
}
分库案例
我们使用ShadingJDBC实现数据分片,将一部分数据添加到sd1一部分数据添加到sd2中,一部分数据添加到goods_0中,一部分数据添加到goods_1中。
我们先实现将一部分数据添加到sd1中,一部分数据添加到sd2中,这种操作就是分库操作,分库操作可以减少每个数据库中存储的数据,当数据少了,查询的时候,单台数据库查找的数据量就减少了,从而加速了每台数据库查找速度。
分库策略

分库策略如上图:
#求余算法
添加数据的时候,我们由于只有2台数据库,我们可以根据某个字段 column%2 求余,来确定数据存入哪个数据库,这种算法是很常规的算法。
#案例求余
在案例中,我们可以把type作为求余的column,用type%2的余数作为数据库的下标,这种算法是非常简单的。
分库配置
修改application.yml,配置分库策略,配置如下:
spring:
shardingsphere:
# 数据源配置
datasource:
# 名称随意,但必须唯一
names: ds1,ds2
# 这里的名称需要在datasource.names中存在
ds1:
# jdbc需要配置连接池
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
url: jdbc:mysql://localhost:3306/sd1?serverTimezone=Asia/Shanghai&characterEncoding=utf8&autoReconnect=true&zeroDateTimeBehavior=convertToNull&useSSL=false
ds2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
url: jdbc:mysql://localhost:3306/sd2?serverTimezone=Asia/Shanghai&characterEncoding=utf8&autoReconnect=true&zeroDateTimeBehavior=convertToNull&useSSL=false
# 分片配置
sharding:
# 需要分片的表配置
tables:
# 需要分片的表名,逻辑名,随意
goods:
# 数据节点配置ds${}组成上面names中的数据源名称, 1..2代表 1到2之间的数值
# 数据库中表的语法:schema.表名 = database.表名
actualDataNodes: ds${1..2}.goods
# 分库策略
databaseStrategy:
# 使用inline分片算法
inline:
# 分片键 为表中某个字段
shardingColumn: type
# 具体分片时的表达式
algorithmExpression: ds${type % 2 + 1}
props:
# 是否打印sql
sql.show: true
logging:
pattern:
console: '%d{HH:mm:ss} %msg %n\'
level:
root: info
com:
execise: debug
分表案例
基于上面的案例,我们再实现分表操作,一部分数据存入goods_0,一部分数据存入goods_1。
分表策略

如上图:
#分表策略
我们需要将数据存入到goods_0或者goods_1中,也可以采用求余法,采用id作为求余的列, id%2的余数作为数据库表的下标。
分表配置
修改application.yml,配置分表策略,配置如下:
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: ds1,ds2
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
url: jdbc:mysql://localhost:3306/sd1?serverTimezone=Asia/Shanghai&characterEncoding=utf8&autoReconnect=true&zeroDateTimeBehavior=convertToNull&useSSL=false
ds2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
url: jdbc:mysql://localhost:3306/sd2?serverTimezone=Asia/Shanghai&characterEncoding=utf8&autoReconnect=true&zeroDateTimeBehavior=convertToNull&useSSL=false
sharding:
tables:
goods:
actualDataNodes: ds${1..2}.goods_${0..1}
databaseStrategy:
inline:
shardingColumn: type
algorithmExpression: ds${type % 2 + 1}
# 表分片策略
tableStrategy:
inline:
shardingColumn: id
algorithmExpression: goods_${id % 2}
keyGenerator:
type: SNOWFLAKE
column: id
props:
sql.show: true
logging:
pattern:
console: '%d{HH:mm:ss} %msg %n\'
level:
root: info
com:
execise: debug
配置参数说明
上面我们完成了分表分库的配置,但很多配置并未说明是什么意思,参数详情如下:
dataSources: # 省略数据源配置,请参考使用手册
rules:
- !SHARDING
tables: # 数据分片规则配置
<logic-table-name> (+): # 逻辑表名称
actualDataNodes (?): # 由数据源名 + 表名组成(参考Inline语法规则)
databaseStrategy (?): # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
shardingAlgorithmName: # 分片算法名称
complex: # 用于多分片键的复合分片场景
shardingColumns: #分片列名称,多个列以逗号分隔
shardingAlgorithmName: # 分片算法名称
hint: # Hint 分片策略
shardingAlgorithmName: # 分片算法名称
none: # 不分片
tableStrategy: # 分表策略,同分库策略
keyGenerateStrategy: # 分布式序列策略
column: # 自增列名称,缺省表示不使用自增主键生成器
keyGeneratorName: # 分布式序列算法名称
autoTables: # 自动分片表规则配置
t_order_auto: # 逻辑表名称
actualDataSources (?): # 数据源名称
shardingStrategy: # 切分策略
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
shardingAlgorithmName: # 自动分片算法名称
bindingTables (+): # 绑定表规则列表
- <logic_table_name_1, logic_table_name_2, ...>
- <logic_table_name_1, logic_table_name_2, ...>
broadcastTables (+): # 广播表规则列表
- <table-name>
- <table-name>
defaultDatabaseStrategy: # 默认数据库分片策略
defaultTableStrategy: # 默认表分片策略
defaultKeyGenerateStrategy: # 默认的分布式序列策略
defaultShardingColumn: # 默认分片列名称
# 分片算法配置
shardingAlgorithms:
<sharding-algorithm-name> (+): # 分片算法名称
type: # 分片算法类型
props: # 分片算法属性配置
# ...
# 分布式序列算法配置
keyGenerators:
<key-generate-algorithm-name> (+): # 分布式序列算法名称
type: # 分布式序列算法类型
props: # 分布式序列算法属性配置
# ...
props:
# ...
ShardingProxy 使用
下载与安装
访问 https://shardingsphere.apache.org/document/current/en/downloads/ 下载
也可获取历史版本的下载
https://archive.apache.org/dist/shardingsphere/
- 解压缩后修改conf/server.yaml和以config-前缀开头的文件,如:conf/config-xxx.yaml文件,进行分片规则、读写分离规则配置。
需要修改server.yaml后方可启动。把authentication这块原来的注释符(#)都删除即可

如果使用mysql数据库时,需要把mysql的jar复制到它的lib目录下。
windows下双击start.bat启动: 默认使用3307端口,可通过命令修改。
start.bat 端口

- Linux操作系统请运行
bin/start.sh,Windows操作系统请运行bin/start.bat启动Sharding-Proxy。如需配置启动端口、配置文件位置后进行启动
分库案例
修改配置文件config-sharding.yaml如下
schemaName: sharding_db
dataSources:
sp_1:
url: jdbc:mysql://127.0.0.1:3306/sd1?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 10
sp_2:
url: jdbc:mysql://127.0.0.1:3306/sd2?serverTimezone=UTC&useSSL=false
username: root
password: root
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 10
shardingRule:
tables:
student:
actualDataNodes: sp_${1..2}.student_${0..1}
tableStrategy:
inline:
shardingColumn: id
algorithmExpression: student_${id % 2}
databaseStrategy:
inline:
shardingColumn: grade
algorithmExpression: sp_${grade % 2 + 1}
keyGenerator:
type: SNOWFLAKE
column: id
bindingTables:
- student
分表案例
修改配置文件config-sharding.yaml如下
schemaName: sharding_db
dataSources:
master:
username: root
password: 123456
url: jdbc:mysql://192.168.136.160:3307/masterdb?serverTimezone=Asia/Shanghai&characterEncoding=utf8&autoReconnect=true&zeroDateTimeBehavior=convertToNull&useSSL=false
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 10
slave1:
username: root
password: 123456
url: jdbc:mysql://192.168.136.160:3308/masterdb?serverTimezone=Asia/Shanghai&characterEncoding=utf8&autoReconnect=true&zeroDateTimeBehavior=convertToNull&useSSL=false
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 10
slave2:
username: root
password: 123456
url: jdbc:mysql://192.168.136.160:3309/masterdb?serverTimezone=Asia/Shanghai&characterEncoding=utf8&autoReconnect=true&zeroDateTimeBehavior=convertToNull&useSSL=false
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 10
shardingRule:
tables:
goods:
actualDataNodes: ds_ms1.goods_${0..1}
tableStrategy:
inline:
shardingColumn: id
algorithmExpression: goods_${id%2}
keyGenerator:
type: SNOWFLAKE
column: id
bindingTables:
- goods
masterSlaveRules:
ds_ms1:
loadBalanceAlgorithmType: round_robin
masterDataSourceName: master
slaveDataSourceNames:
- slave1
- slave2
MySQL主从复制
① 创建master容器
创建配置
mkdir -p /data/mysql/master/conf
# master数据库配置
sudo tee /data/mysql/master/conf/mysqld.cnf <<-'EOF'
[mysqld]
server-id = 1 # 节点ID,确保唯一 # log config
log-bin = mysql-bin #开启mysql的binlog日志功能
sync_binlog = 1 #控制数据库的binlog刷到磁盘上去 , 0 不控制,性能最好,1每次事物提交都会刷到日志文件中,性能最差,最安全
binlog_format = mixed #binlog日志格式,mysql默认采用statement,建议使用mixed
expire_logs_days = 7 #binlog过期清理时间
max_binlog_size = 100m #binlog每个日志文件大小
binlog_cache_size = 4m #binlog缓存大小
max_binlog_cache_size= 512m #最大binlog缓存大
binlog-ignore-db=mysql #不生成日志文件的数据库,多个忽略数据库可以用逗号拼接,或者 复制这句话,写多行 auto-increment-offset = 1 # 自增值的偏移量
auto-increment-increment = 1 # 自增值的自增量
slave-skip-errors = all #跳过从库错误
EOF创建容器
# 创建master数据库
docker run --name mysql-master -p 3307:3306 -e MYSQL_ROOT_PASSWORD=123456 \
-v /data/mysql/master/conf/mysqld.cnf:/etc/mysql/mysql.conf.d/mysqld.cnf \
-v /data/mysql/master/data:/var/lib/mysql \
-d mysql:5.7
② 创建2个slave容器
创建slave的配置
mkdir -p /data/mysql/slave1/conf
# slave数据库配置
sudo tee /data/mysql/slave1/conf/mysqld.cnf <<-'EOF'
[mysqld]
server-id = 101
log-bin=mysql-bin
relay-log = mysql-relay-bin
replicate-wild-ignore-table=mysql.%
replicate-wild-ignore-table=test.%
replicate-wild-ignore-table=information_schema.%
EOF mkdir -p /data/mysql/slave2/conf
# slave数据库配置
sudo tee /data/mysql/slave2/conf/mysqld.cnf <<-'EOF'
[mysqld]
server-id = 102
log-bin=mysql-bin
relay-log = mysql-relay-bin
replicate-wild-ignore-table=mysql.%
replicate-wild-ignore-table=test.%
replicate-wild-ignore-table=information_schema.%
EOF创建容器
docker run --name mysql-slave1 -p 3308:3306 -e MYSQL_ROOT_PASSWORD=123456 \
-v /data/mysql/slave1/conf/mysqld.cnf:/etc/mysql/mysql.conf.d/mysqld.cnf \
-v /data/mysql/slave1/data:/var/lib/mysql \
-d mysql:5.7 docker run --name mysql-slave2 -p 3309:3306 -e MYSQL_ROOT_PASSWORD=123456 \
-v /data/mysql/slave2/conf/mysqld.cnf:/etc/mysql/mysql.conf.d/mysqld.cnf \
-v /data/mysql/slave2/data:/var/lib/mysql \
-d mysql:5.7
③ master创建用户并授权
进入master的数据库,为master创建复制用户
# 进入master容器
docker exec -it mysql-master bash
# root用户连接mysql
mysql -uroot -p123456
# 创建用户
CREATE USER repl_user IDENTIFIED BY 'repl_passwd';赋予户复制的权限
grant replication slave on *.* to 'repl_user'@'%' identified by 'repl_passwd';
FLUSH PRIVILEGES;
④ 查看master的状态
# 记录 File与Position的值
show master status;

⑤ 从库配置
# 进入从库容器
docker exec -it mysql-slave bash
# 连接从库
mysql -uroot -p123456
CHANGE MASTER TO
MASTER_HOST = '192.168.136.160',
MASTER_USER = 'repl_user',
MASTER_PASSWORD = 'repl_passwd',
MASTER_PORT = 3307,
MASTER_LOG_FILE='mysql-bin.000003',
MASTER_LOG_POS=858,
MASTER_RETRY_COUNT = 60,
MASTER_HEARTBEAT_PERIOD = 10000;
start slave;
# MASTER_LOG_FILE='mysql-bin.000005',#与主库File 保持一致
# MASTER_LOG_POS=120 , #与主库Position 保持一致
show slave status\G

Shading-JDBC、ShadingSphere、ShardingProxy 使用详解的更多相关文章
- JAVA通过JDBC连接Oracle数据库详解【转载】
JAVA通过JDBC连接Oracle数据库详解 (2011-03-15 00:10:03) 转载▼http://blog.sina.com.cn/s/blog_61da86dd0100q27w.htm ...
- JDBC学习1:详解JDBC使用
什么是JDBC JDBC(Java Database Connectivity),即Java数据库连接,是一种用于执行SQL语句的Java API,可以为多种关系数据库提供同一访问,它由一组用Java ...
- JAVA采用JDBC连接操作数据库详解
JDBC连接数据库概述 一.JDBC基础知识 JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供 ...
- 原生jdbc操作mysql数据库详解
首先给大家说一下使用JDBC链接数据库的步骤 1.加载链接数据库驱动 2.建立数据库链接 3.创建数据库操作对象 4.编写sql语句,执行sql语句 5.获取结果集 6.释放资源 我这边采用的是mav ...
- Jdbc连接数据库基本步骤详解_java - JAVA
文章来源:嗨学网 敏而好学论坛www.piaodoo.com 欢迎大家相互学习 Jdbc连接数据库的基本步骤,供大家参考,具体内容如下 package demo.jdbc; import java.s ...
- logstash中关于Jdbc输入配置选项详解
Setting Input type Required clean_run boolean No columns_charset hash No connection_retry_attempts n ...
- JDBC常用接口详解
JDBC中常用接口详解 ***DriverManager 第一.注册驱动 第一种方式:DriverManager.registerDriver(new com.mysql.jdbc.Driver()) ...
- Jmeter操作MySQL数据库详解
一.jmeter操作数据库的原理 jmeter不可直接操作数据库,必须通过驱动程序来间接操作,但如果数据库不是在本地而是云服务器上的话就需要通过网络来操作. jmeter通过驱动程序来完成对MySQL ...
- Java的JDBC事务详解
Java的JDBC事务详解 分类: Hibernate 2010-06-02 10:04 12298人阅读 评论(9) ...
随机推荐
- 在半小时内从无到有开发并调试一款Chrome扩展(Chrome插件/谷歌浏览器插件)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_120 就在不久之前,我们目前这个毕业班的班长那日同学和我说,他正在公司开发Chrome扩展,看起来很高大上的技术,实际开发却非常简 ...
- PostGresql listen与notify命令
LISTEN与NOTIFY命令 PostgreSQL提供了client端和其他client端通过服务器端进行消息通信的机制.这种机制 是通过LISTEN和NOTIFY命令来完成的. 1.LISTEN与 ...
- Taurus.MVC WebAPI 入门开发教程2:添加控制器输出Hello World。
系列目录 1.Taurus.MVC WebAPI 入门开发教程1:框架下载环境配置与运行. 2.Taurus.MVC WebAPI 入门开发教程2:添加控制器输出Hello World. 3.Tau ...
- 如何让 JS 代码不可断点
绕过断点 调试 JS 代码时,单步执行(F11)可跟踪所有操作.例如这段代码,每次调用 alert 时都会被断住: debugger alert(11) alert(22) alert(33) ale ...
- MySQL Shell无法拉起MGR集群解决办法
MySQL Shell无法拉起MGR集群解决办法 用MySQL Shell要重新拉起一个MGR集群时,可能会提示下面的错误信息: Dba.rebootClusterFromCompleteOutage ...
- 简单html js css 轮播图片,不用jquery
这个是自己修改的轮播图片,在网上有的是flash 实现的轮播图片,对搜索引擎不友好, 比如:dedecms 的首页的轮播图是用flash实现滚动的. 所以这个自己修改了一下,实现html+js+css ...
- 牛客练习赛99—C
数的和与积 https://ac.nowcoder.com/acm/contest/34330/C 思路: 2和4是不可以的,除了3意外其他的都可以用三项解决,其中一项为1,剩余两项分别设为x,y. ...
- 校园网跨网段共享文件Samba+SSH
Introduction This tutorial contains screenshots for the English version of Windows 10. Separate inst ...
- Linux面试题 系统启动流程
BIOS:基本输入输出系统,帮助我们初始化硬件 硬盘分区有两类:MBR和GPT ; MBR单块硬盘不能大于2T,主分区的数量不能超过4个:MBR方案存储在第一个扇区的前446个字节(共512字节,后面 ...
- KingbaseES应对表年龄增长过快导致事务回卷
背景 前几天碰到这样一个场景,在KingbaseES数据库当作数据同步节点.其特点是接收过来的数据量巨大,其更新超级频繁,最大的数据库达到6TB.这还不是主要的,主要导致问题发生原因是同步数据库有很多 ...