LLM(大语言模型)解码时是怎么生成文本的?
Part1配置及参数
transformers==4.28.1
源码地址:transformers/configuration_utils.py at v4.28.1 · huggingface/transformers (github.com)
文档地址:Generation (huggingface.co)
对于生成任务而言:text-decoder, text-to-text, speech-to-text, and vision-to-text models,有以下几种生成的方法:
greedy decoding by calling [ ~generation.GenerationMixin.greedy_search] ifnum_beams=1and
do_sample=Falsecontrastive search by calling [ ~generation.GenerationMixin.contrastive_search] ifpenalty_alpha>0.
andtop_k>1multinomial sampling by calling [ ~generation.GenerationMixin.sample] ifnum_beams=1and
do_sample=Truebeam-search decoding by calling [ ~generation.GenerationMixin.beam_search] ifnum_beams>1and
do_sample=Falsebeam-search multinomial sampling by calling [ ~generation.GenerationMixin.beam_sample] if
num_beams>1anddo_sample=Truediverse beam-search decoding by calling [ ~generation.GenerationMixin.group_beam_search], if
num_beams>1andnum_beam_groups>1constrained beam-search decoding by calling [ ~generation.GenerationMixin.constrained_beam_search], if
constraints!=Noneorforce_words_ids!=None
具体有以下参数可供选择:
(1)控制输出长度的参数
max_length (int, optional, defaults to 20) - 生成的tokens的最大长度。对应于输入提示的长度+max_new_tokens。如果还设置了max_new_tokens,则其作用被max_new_tokens覆盖。 max_new_tokens (int, optional) - 要生成的最大数量的tokens,忽略提示中的tokens数量。 min_length (int, optional, defaults to 0) - 要生成的序列的最小长度。对应于输入提示的长度+min_new_tokens。如果还设置了min_new_tokens,它的作用将被 min_new_tokens覆盖。 min_new_tokens (int, optional) - 要生成的最小数量的tokens,忽略提示中的tokens数量。 early_stopping (bool or str, optional, defaults to False) - 控制基于beam-based的停止条件,比如beam-search。是否在至少生成 num_beams个句子后停止 beam search,默认是False。max_time(float, optional) - 你允许计算运行的最大时间,以秒为单位。在分配的时间过后,生成仍然会完成当前的传递。
(2)控制输出策略的参数
do_sample (bool, optional, defaults to False) - 是否使用采样,否则使用贪婪解码 。
num_beams (int, optional, defaults to 1) - 集束搜索的集束数量。1意味着没有集束搜索 。
num_beam_groups (int, optional, defaults to 1) - 将num_beam分成的组数,以确保不同组的beams的多样性。https://arxiv.org/pdf/1610.02424.pdf
penalty_alpha (float, optional) - 平衡模型置信度和对比搜索解码中的退化惩罚的数值。
use_cache (bool, optional, defaults to True) - 模型是否应该使用过去最后的键/值注意力(如果适用于模型)来加速解码。
(3)控制模型输出Logits的参数
temperature(float, optional, defaults to 1.0) - 用于调节下一个标记概率的值。 top_k (int, optional, defaults to 50) - 为top-k过滤而保留的最高概率词汇标记的数量。 top_p (float, optional, defaults to 1.0) - 已知生成各个词的总概率是1(即默认是1.0)如果top_p小于1,则从高到低累加直到top_p,取这前N个词作为候选。 typical_p (float, optional, defaults to 1.0) - 局部典型性度量:在给定已生成的部分文本的情况下,预测下一个目标标记的条件概率与预测下一个随机标记的预期条件概率的相似程度。如果设置为float < 1,则保留概率加起来等于typical_p或更高的最小的本地典型tokens集以供生成。https://arxiv.org/pdf/2202.00666.pdf epsilon_cutoff (float, optional, defaults to 0.0) - 如果设置为严格介于0和1之间的浮点数 ,只有条件概率大于epsilon_cutoff的标记才会被采样。在论文中,建议的值在3e-4到 9e-4之间,取决于模型的大小。https://arxiv.org/abs/2210.15191 eta_cutoff (float, optional, defaults to 0.0) - Eta采样是局部典型采样和ε采样的混合体。 如果设置为严格介于0和1之间的浮点数,只有当一个token大于eta_cutoff或 sqrt(eta_cutoff) * exp(- entropy(softmax(next_token_logits)))时才会被考 虑。后者直观地是预期的下一个令牌概率,以sqrt(eta_cutoff)为尺度。在论文中 ,建议值从3e-4到2e-3不等,取决于模型的大小。https://arxiv.org/abs/2210.15191 diversity_penalty (float, optional, defaults to 0.0) - 如果一个beam在某一特定时间产生一 个与其他组的任何beam相同的标记,这个值将从beam的分数中减去。请注意,多样性惩罚只有在group-beam-search被启用时才有效。 repetition_penalty (float, optional, defaults to 1.0) - 重复处罚的参数。1.0意味着没有惩罚。https://arxiv.org/pdf/1909.05858.pdf encoder_repetition_penalty (float, optional, defaults to 1.0) - encoder_repetition_penalty的参数。对不在原始输入中的序列进行指数式惩罚。 1.0意味着没有惩罚。 length_penalty (float, optional, defaults to 1.0) - 对长度的指数惩罚,用于beam-based的生成 。它作为指数应用于序列的长度,反过来用于划分序列的分数。由于分数是序列的对数 能性(即负数),length_penalty > 0.0会促进更长的序列,而length_penalty < 0.0会鼓励更短的序列。 no_repeat_ngram_size (int, optional, defaults to 0) - 如果设置为int > 0,所有该尺寸的 ngrams只能出现一次。 bad_words_ids(List[List[int]], optional) - 不允许生成的标记ID的列表。为了获得不 应该出现在生成的文本中的词的标记ID,使用tokenizer(bad_words, add_prefix_space=True, add_special_tokens=False).input_ids。 force_words_ids(List[List[int]] or List[List[List[int]]], optional) - 必须生成的 token ids列表。如果给定的是List[List[int]],这将被视为一个必须包含的简单单词列表,与bad_words_ids相反。如果给定的是List[List[List[int]]],这将触发一个 disjunctive约束,即可以允许每个词的不同形式。https://github.com/huggingface/transformers/issues/14081 renormalize_logits (bool, optional, defaults to False) - 在应用所有的logits处理器或 warpers(包括自定义的)之后,是否重新规范化logits。强烈建议将这个标志设置为 "True",因为搜索算法认为分数对数是正常化的,但一些对数处理器或翘曲器会破坏正常化。 constraints (List[Constraint], optional) - 自定义约束,可以添加到生成中,以确保输出将包含使用Constraint对象定义的某些标记,以最合理的方式。 forced_bos_token_id (int, optional, defaults to model.config.forced_bos_token_id) - 强制作为解码器_start_token_id之后第一个生成的令牌的id。对于像mBART这样的多语言模型,第一个生成的标记需要是目标语言的标记,这很有用。 forced_eos_token_id (Union[int, List[int]], optional, defaults to model.config.forced_eos_token_id) - 当达到max_length时,强制作为最后生成的令牌的id。可以选择使用一个列表来设置多个序列结束的标记。 remove_invalid_values (bool, optional, defaults to model.config.remove_invalid_values) - 是否删除模型可能的nan和inf输出以防 止生成方法崩溃。注意,使用remove_invalid_values会减慢生成速度。 exponential_decay_length_penalty (tuple(int, float), optional) - 这个Tuple在生成一 定数量的标记后,增加一个指数级增长的长度惩罚。该元组应包括: (start_index, decay_factor) 其中start_index表示惩罚开始的位置, decay_factor表示指数衰减的系数。 suppress_tokens (List[int], optional) - 在生成时将被抑制的tokens列表。 SupressTokens日志处理器将把它们的日志probs设置为-inf,这样它们就不会被采样 了。 forced_decoder_ids (List[List[int]], optional) - 一对整数的列表,表示从生成索引到token索引的映射,在采样前会被强制执行。例如,[[1, 123]]意味着第二个生成的token将总是索引为token的令牌。
(4)定义generate输出变量的参数
num_return_sequences(int, optional, defaults to 1) - 批次中每个元素独立计算的返回序列的数量。 output_attentions (bool, optional, defaults to False) - 是否返回所有注意力层的注意力张量。更多细节请参见返回的张量下的注意力。 output_hidden_states (bool, optional, defaults to False) - 是否要返回所有层的隐藏状 态。更多细节请参见返回张量下的hidden_states。 output_scores (bool, optional, defaults to False) - 是否返回预测的分数。更多细节请参见返回张量下的分数。 return_dict_in_generate (bool, optional, defaults to False) - 是否返回ModelOutput而不是普通元组。 synced_gpus (bool, optional, defaults to False) - 是否继续运行while循环直到max_length(ZeRO第三阶段需要)。
(5)可在生成时使用的特殊参数
pad_token_id (int, optional) - 填充token的ID。 bos_token_id (int, optional) - 序列开始标记的id。 eos_token_id (Union[int, List[int]], optional) - 序列结束标记的id。可以选择使用 一个列表来设置多个序列结束标记。
(6)编码器-解码器模型独有的生成参数
encoder_no_repeat_ngram_size (int, optional, defaults to 0) - 如果设置为int > 0,所有出现在encoder_input_ids中的该大小的ngrams都不能出现在decoder_input_ids中 。
decoder_start_token_id (int, optional) - 如果一个编码器-解码器模型以不同于bos的 token开始解码,则这就是该token的id。
Part2配置基本使用
1使用预训练模型定义的生成参数
我们可以这么使用、保存预训练模型已经定义好的参数:
from transformers import AutoTokenizer, AutoModelForCausalLM, TextGenerationPipeline, GenerationConfig
model_name_or_path = "uer/gpt2-chinese-cluecorpussmall"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
generation_config = model.generation_config
generation_config_dict = generation_config.to_dict()
generation_config_dict["num_beams"] = 2
generation_config = GenerationConfig.from_dict(generation_config_dict)
print(generation_config)
generation_config.save_pretrained("./")
"""
{
"_from_model_config": true,
"bos_token_id": 50256,
"eos_token_id": 50256,
"num_beams": 2,
"transformers_version": "4.28.1"
}
"""
需要注意的是,如果参数是默认的值得话,则不会显示出来。另外,GenerationConfig类里面有许多可用的方法,具体可以去看看源代码。
2一般使用方法
在定义好config之后,我们可以这么使用:
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("t5-small")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
translation_generation_config = GenerationConfig(
num_beams=4,
early_stopping=True,
decoder_start_token_id=0,
eos_token_id=model.config.eos_token_id,
pad_token=model.config.pad_token_id,
)
translation_generation_config.save_pretrained("t5-small", "translation_generation_config.json", push_to_hub=True)
# You could then use the named generation config file to parameterize generation
# 可以加载我们自己本地保存的generation_config
generation_config = GenerationConfig.from_pretrained("t5-small", "translation_generation_config.json")
inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
outputs = model.generate(**inputs, generation_config=generation_config)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
Part3生成结果
使用transformers库的生成模型生成结果有三种方式,暂时不要在意参数:
3pipeline
指定为text-generation
from transformers import pipeline
generator = pipeline(
'text-generation',
model="uer/gpt2-chinese-cluecorpussmall",
)
text_inputs = ["昨天已经过去,"]
generator(text_inputs, max_length=100)
4TextGenerationPipeline
from transformers import AutoTokenizer, AutoModelForCausalLM, TextGenerationPipeline
tokenizer = AutoTokenizer.from_pretrained("uer/gpt2-chinese-cluecorpussmall")
model = AutoModelForCausalLM.from_pretrained("uer/gpt2-chinese-cluecorpussmall")
text_generator = TextGenerationPipeline(model, tokenizer)
text_inputs = ["昨天已经过去,"]
text_generator(text_inputs, max_length=100)
5model.generate()
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch, os
tokenizer = AutoTokenizer.from_pretrained("uer/gpt2-chinese-cluecorpussmall")
model = AutoModelForCausalLM.from_pretrained("uer/gpt2-chinese-cluecorpussmall")
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = model.to(device)
texts = ["昨天已经过去,"]
#用batch输入的时候一定要设置padding
encoding = tokenizer(texts, return_tensors='pt', padding=True).to(device)
model.eval()
with torch.no_grad():
generated_ids = model.generate(**encoding, max_length=100)
generated_texts = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
for text in generated_texts:
print(text)
我们捋一捋它们之间的关系:最基础的还是model.generate(),而TextGenerationPipeline在_forward里面调用了model.generate(),pipeline实际上是对TextGenerationPipeline的进一步封装:
"text-generation": {
"impl": TextGenerationPipeline,
"tf": TFAutoModelForCausalLM if is_tf_available() else None,
"pt": AutoModelForCausalLM if is_torch_available() else None,
"default": {"model": {"pt": "gpt2", "tf": "gpt2"}},
},
6流式打印
在介绍不同的生成方法之前,先介绍下流式打印。使用过ChatGPT的玩家都知道,在生成结果的时候,它是一部分一部分的返回生成的文本并展示的,transformers该版本也有这个功能,我们接下来看。
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
tokenizer = AutoTokenizer.from_pretrained("uer/gpt2-chinese-cluecorpussmall")
model = AutoModelForCausalLM.from_pretrained("uer/gpt2-chinese-cluecorpussmall")
input_text = "昨天已经过去,"
inputs = tokenizer([input_text], return_tensors="pt", add_special_tokens=False)
streamer = TextStreamer(tokenizer)
# Despite returning the usual output, the streamer will also print the generated text to stdout.
_ = model.generate(**inputs, streamer=streamer, max_new_tokens=86)
如果想要一次性返回结果再打印,则是这样的:
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
from threading import Thread
tokenizer = AutoTokenizer.from_pretrained("uer/gpt2-chinese-cluecorpussmall")
model = AutoModelForCausalLM.from_pretrained("uer/gpt2-chinese-cluecorpussmall")
input_text = "昨天已经过去,"
inputs = tokenizer([input_text], return_tensors="pt", add_special_tokens=False)
streamer = TextIteratorStreamer(tokenizer)
# Run the generation in a separate thread, so that we can fetch the generated text in a non-blocking way.
generation_kwargs = dict(inputs, streamer=streamer, max_new_tokens=100)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
generated_text = ""
for new_text in streamer:
generated_text += new_text
generated_text
Part4多种生成方式
接下来将以之前训练好的观点评论生成的GPT来生成不同的结果,我们每次都使用三种方式对比看看结果。
7Greedy Search
generate默认使用贪婪的搜索解码,所以你不需要传递任何参数来启用它。这意味着参数num_beams被设置为1,do_sample=False。
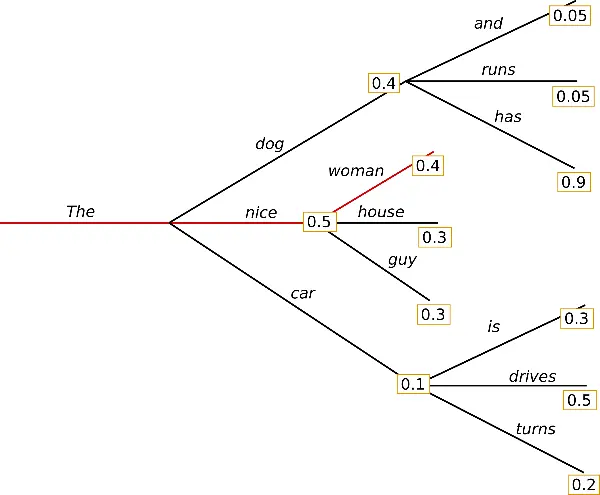
如图上所属,每次选择概率值最高的词。贪心搜索的主要缺点是它错过了隐藏在低概率词后面的高概率词,比如has=0.9不会被选择到。
from transformers import AutoTokenizer, AutoModelForCausalLM, TextGenerationPipeline, pipeline
tokenizer = AutoTokenizer.from_pretrained("./gpt2-chinese")
model = AutoModelForCausalLM.from_pretrained("./gpt2-chinese")
from datasets import load_dataset
data_file = "./ChnSentiCorp_htl_all.csv"
dataset = load_dataset("csv", data_files=data_file)
dataset = dataset.filter(lambda x: x["review"] is not None)
dataset = dataset["train"].train_test_split(0.2, seed=123)
import random
example = random.choice(dataset["train"])
text = example["review"]
input_text = text[:10]
print(input_text)
# greedy search
model.eval()
with torch.no_grad():
encoding = tokenizer(input_text,
return_tensors='pt',
padding=False,
add_special_tokens=False,
return_token_type_ids=False,
return_attention_mask=False,)
generated_ids = model.generate(**encoding,
max_length=100,
eos_token_id=0,
pad_token_id=0,
num_beams=1,
do_sample=False)
generated_texts = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_texts)
text_generator = TextGenerationPipeline(model, tokenizer)
print(text_generator(input_text,
max_length=100,
eos_token_id=0,
num_beams=1,
do_sample=False,
pad_token_id=0))
generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
generation_config = {
"max_length": 100,
"eos_token_id": 0,
"pad_token_id": 0,
"num_beams": 1,
"do_sample": False,
}
print(generator(input_text, **generation_config))
"""
虽然说是4星级,不过
['虽 然 说 是 4 星 级 , 不 过 感 觉 和 3 星 没 什 么 两 样 , 只 是 服 务 水 准 差 了 点 而 已']
[{'generated_text': '虽然说是4星级,不过 感 觉 和 3 星 没 什 么 两 样 , 只 是 服 务 水 准 差 了 点 而 已'}]
[{'generated_text': '虽然说是4星级,不过 感 觉 和 3 星 没 什 么 两 样 , 只 是 服 务 水 准 差 了 点 而 已'}]
"""
答案是一致的,和我们之前的推测一样,但需要注意的是model.gneerate()对单条预测的时候我们在tokenizer的时候设置padding为False了,如果设置为True,则得不到相同的结果。
8Contrastive search
对比搜索解码策略是在2022年的论文A Contrastive Framework for Neural Text Generation https://arxiv.org/abs/2202.06417中提出的。它展示了生成非重复但连贯的长输出的优越结果。要了解对比性搜索的工作原理,请查看这篇博文https://huggingface.co/blog/introducing-csearch。启用和控制对比性搜索行为的两个主要参数是punice_alpha和top_k:
from transformers import AutoTokenizer, AutoModelForCausalLM, TextGenerationPipeline, pipeline
tokenizer = AutoTokenizer.from_pretrained("./gpt2-chinese")
model = AutoModelForCausalLM.from_pretrained("./gpt2-chinese")
from datasets import load_dataset
data_file = "./ChnSentiCorp_htl_all.csv"
dataset = load_dataset("csv", data_files=data_file)
dataset = dataset.filter(lambda x: x["review"] is not None)
dataset = dataset["train"].train_test_split(0.2, seed=123)
import random
example = random.choice(dataset["train"])
# text = dataset["train"][0]
text = example["review"]
input_text = text[:10]
print(input_text)
# greedy search
model.eval()
with torch.no_grad():
encoding = tokenizer(input_text,
return_tensors='pt',
padding=False,
add_special_tokens=False,
return_token_type_ids=False,
return_attention_mask=False,)
generated_ids = model.generate(**encoding,
max_length=100,
eos_token_id=0,
pad_token_id=0,
do_sample=False,
num_beams=1,
penalty_alpha=0.6,
top_k=4)
generated_texts = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_texts)
text_generator = TextGenerationPipeline(model, tokenizer)
print(text_generator(input_text,
max_length=100,
eos_token_id=0,
num_beams=1,
do_sample=False,
pad_token_id=0,
penalty_alpha=0.6,
top_k=4
))
generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
generation_config = {
"max_length": 100,
"eos_token_id": 0,
"pad_token_id": 0,
"num_beams": 1,
"do_sample": False,
# "penalty_alpha":0.6,
# "top_k":4,
}
print(generator(input_text, **generation_config))
"""
['极 差 ! 停 车 收 十 元 钱 ! 穷 则 思 变 ! 房 间 潮 湿 得 不 得 了 , 晚 上 居 然 停 了 一 个 多 小 时 , 上 网 一 会 有 信 号 一 会 没 有 。 电 视 遥 控 器 不 管 用 , 打 电 话 给 客 房 中 心 , 得 到 的 回 复 居 然 是 坏 的 房 间 在 维 修 , 不 知 道']
[{'generated_text': '极差!停车收十元钱! 穷 则 思 变 ! 房 间 潮 湿 得 不 得 了 , 晚 上 居 然 停 了 一 个 多 小 时 , 上 网 一 会 有 信 号 一 会 没 有 。 电 视 遥 控 器 不 管 用 , 打 电 话 给 客 房 中 心 , 得 到 的 回 复 居 然 是 坏 的 房 间 在 维 修 , 不 知 道'}]
[{'generated_text': '极差!停车收十元钱! 穷 则 思 变 ! 房 间 设 施 差 就 一 个 招 待 所 , 最 多 三 星 级 !'}]
"""
可以对比和贪婪解码看一下结果。
9Multinomial sampling
与总是选择概率最高的标记作为下一个标记的贪婪搜索相反,多项式抽样(也称为祖先抽样)根据模型给出的整个词汇的概率分布来随机选择下一个标记。每个概率不为零的符号都有机会被选中,从而减少了重复的风险。
from transformers import AutoTokenizer, AutoModelForCausalLM, TextGenerationPipeline, pipeline
tokenizer = AutoTokenizer.from_pretrained("./gpt2-chinese")
model = AutoModelForCausalLM.from_pretrained("./gpt2-chinese")
from datasets import load_dataset
data_file = "./ChnSentiCorp_htl_all.csv"
dataset = load_dataset("csv", data_files=data_file)
dataset = dataset.filter(lambda x: x["review"] is not None)
dataset = dataset["train"].train_test_split(0.2, seed=123)
import random
example = random.choice(dataset["train"])
# text = dataset["train"][0]
text = example["review"]
input_text = text[:10]
print(input_text)
# greedy search
model.eval()
with torch.no_grad():
encoding = tokenizer(input_text,
return_tensors='pt',
padding=False,
add_special_tokens=False,
return_token_type_ids=False,
return_attention_mask=False,)
generated_ids = model.generate(**encoding,
max_length=100,
eos_token_id=0,
pad_token_id=0,
do_sample=True,
num_beams=1,
)
generated_texts = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_texts)
text_generator = TextGenerationPipeline(model, tokenizer)
print(text_generator(input_text,
max_length=100,
eos_token_id=0,
num_beams=1,
do_sample=True,
pad_token_id=0,
))
generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
generation_config = {
"max_length": 100,
"eos_token_id": 0,
"pad_token_id": 0,
"num_beams": 1,
"do_sample": True,
}
print(generator(input_text, **generation_config))
"""
['房 间 : 建 筑 风 格 比 较 独 特 , 但 不 显 现 空 间 特 色 。 地 理 位 置 不 是 很 好 , 离 九 华 山 比 较 远 , 出 租 车 还 比 较 难 找 。 门 童 服 务 蛮 好 , 门 口 迎 宾 也 很 热 情 。 房 间 设 施 : 住 9 楼 标 房 , 朝 西 , 马 路 上 的 喧 嚣 比 较']
[{'generated_text': '房间:建筑风格比较独 特 , 墙 壁 由 黑 色 为 主 , 给 人 一 种 温 馨 的 感 觉 , 房 间 内 少 点 什 么 装 饰 , 总 体 还 算 可 以 。 交 通 : 订 一 辆 出 租 车 , 一 天 之 内 送 完 了 , 一 天 后 再 打 车 , 车 子 要 走 到 春 熙 路 , 十 分 方 便'}]
[{'generated_text': '房间:建筑风格比较独 特 , 比 较 特 别 的 是 窗 外 的 自 然 环 境 , 很 漂 亮 , 房 间 内 的 设 施 也 不 错 , 有 独 立 的 阳 台 , 所 谓 的 山 景 房 看 风 景 也 能 看 到 大 草 坪 和 远 处 的 大 海 。 服 务 : 因 为 我 和 的 朋 友 预 定 的 是 山'}]
"""
10Beam-search decoding
与贪婪搜索不同的是,集束搜索解码在每个时间步骤中保留几个假设,并最终选择对整个序列具有最高概率的假设。这具有识别高概率序列的优势,这些序列从较低概率的初始标记开始,会被贪婪搜索所忽略。
要启用这种解码策略,需要指定num_beams(又称要跟踪的假说数量)大于1。集束搜索通过在每个时间步保留最可能的 num_beams 个词,并从中最终选择出概率最高的序列来降低丢失潜在的高概率序列的风险。以 num_beams=2 为例:
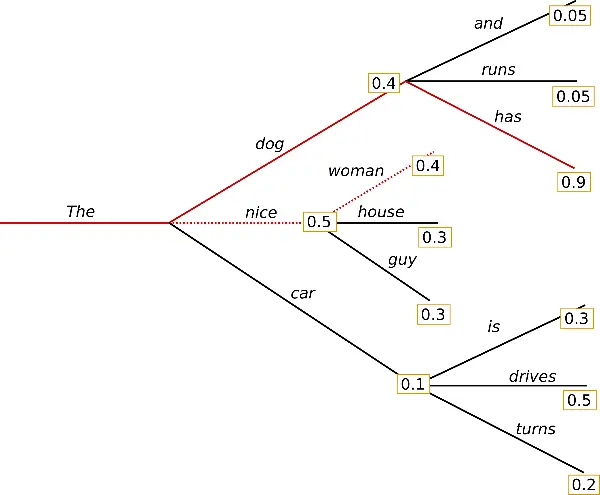
最终得到:the dog has (0.4+0.9) > the nice woman (0.5+0.4)。
缺点:虽然结果比贪心搜索更流畅,但输出中仍然包含重复。
from transformers import AutoTokenizer, AutoModelForCausalLM, TextGenerationPipeline, pipeline
tokenizer = AutoTokenizer.from_pretrained("./gpt2-chinese")
model = AutoModelForCausalLM.from_pretrained("./gpt2-chinese")
from datasets import load_dataset
data_file = "./ChnSentiCorp_htl_all.csv"
dataset = load_dataset("csv", data_files=data_file)
dataset = dataset.filter(lambda x: x["review"] is not None)
dataset = dataset["train"].train_test_split(0.2, seed=123)
import random
example = random.choice(dataset["train"])
# text = dataset["train"][0]
text = example["review"]
input_text = text[:10]
print(input_text)
# greedy search
model.eval()
with torch.no_grad():
encoding = tokenizer(input_text,
return_tensors='pt',
padding=False,
add_special_tokens=False,
return_token_type_ids=False,
return_attention_mask=False,)
generated_ids = model.generate(**encoding,
max_length=100,
eos_token_id=0,
pad_token_id=0,
do_sample=False,
num_beams=4,
)
generated_texts = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_texts)
text_generator = TextGenerationPipeline(model, tokenizer)
print(text_generator(input_text,
max_length=100,
eos_token_id=0,
num_beams=4,
do_sample=False,
pad_token_id=0,
))
generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
generation_config = {
"max_length": 100,
"eos_token_id": 0,
"pad_token_id": 0,
"num_beams": 4,
"do_sample": False,
}
print(generator(input_text, **generation_config))
"""
酒店的整体服务意识相
['酒 店 的 整 体 服 务 意 识 相 当 好 , 对 于 未 按 照 预 订 时 间 到 达 的 客 户 , 还 能 够 保 留 预 订 , 但 是 沟 通 技 巧 不 是 很 好 , 还 有 对 于 未 按 预 订 时 间 到 达 的 客 户 , 还 要 给 携 程 的 工 作 带 来 很 大 麻 烦 。']
[{'generated_text': '酒店的整体服务意识相 当 好 , 对 于 未 按 照 预 订 时 间 到 达 的 客 户 , 还 能 够 保 留 预 订 , 但 是 沟 通 技 巧 不 是 很 好 , 还 有 对 于 未 按 预 订 时 间 到 达 的 客 户 , 还 要 给 携 程 的 工 作 带 来 很 大 麻 烦 。'}]
[{'generated_text': '酒店的整体服务意识相 当 好 , 对 于 未 按 照 预 订 时 间 到 达 的 客 户 , 还 能 够 保 留 预 订 , 但 是 沟 通 技 巧 不 是 很 好 , 还 有 对 于 未 按 预 订 时 间 到 达 的 客 户 , 还 要 给 携 程 的 工 作 带 来 很 大 麻 烦 。'}]
"""
11Beam-search multinomial sampling
顾名思义,这种解码策略结合了集束搜索和多指标采样。你需要指定num_beams大于1,并设置do_sample=True来使用这种解码策略。
from transformers import AutoTokenizer, AutoModelForCausalLM, TextGenerationPipeline, pipeline
tokenizer = AutoTokenizer.from_pretrained("./gpt2-chinese")
model = AutoModelForCausalLM.from_pretrained("./gpt2-chinese")
from datasets import load_dataset
data_file = "./ChnSentiCorp_htl_all.csv"
dataset = load_dataset("csv", data_files=data_file)
dataset = dataset.filter(lambda x: x["review"] is not None)
dataset = dataset["train"].train_test_split(0.2, seed=123)
import random
example = random.choice(dataset["train"])
# text = dataset["train"][0]
text = example["review"]
input_text = text[:10]
print(input_text)
# greedy search
model.eval()
with torch.no_grad():
encoding = tokenizer(input_text,
return_tensors='pt',
padding=False,
add_special_tokens=False,
return_token_type_ids=False,
return_attention_mask=False,)
generated_ids = model.generate(**encoding,
max_length=100,
eos_token_id=0,
pad_token_id=0,
do_sample=True,
num_beams=4,
)
generated_texts = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_texts)
text_generator = TextGenerationPipeline(model, tokenizer)
print(text_generator(input_text,
max_length=100,
eos_token_id=0,
num_beams=4,
do_sample=True,
pad_token_id=0,
))
generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
generation_config = {
"max_length": 100,
"eos_token_id": 0,
"pad_token_id": 0,
"num_beams": 4,
"do_sample": True,
}
print(generator(input_text, **generation_config))
"""
['酒 店 在 肇 庆 闹 市 区 , 但 交 通 非 常 方 便 , 酒 店 服 务 员 态 度 非 常 好 , 酒 店 硬 件 条 件 还 可 以 , 就 是 房 间 隔 音 效 果 非 常 不 好 , 隔 壁 的 电 视 声 音 、 走 廊 人 说 话 声 等 清 清 楚 楚 , 住 在 一 楼 还 能 听 到 隔 壁 房 间 的 电']
[{'generated_text': '酒店在肇庆闹市区,但 交 通 非 常 方 便 , 酒 店 服 务 态 度 很 好 , 房 间 干 净 整 洁 , 下 次 去 肇 庆 还 会 选 择 该 酒 店 。'}]
[{'generated_text': '酒店在肇庆闹市区,但 交 通 非 常 方 便 , 酒 店 环 境 不 错 , 房 间 比 较 干 净 , 服 务 员 态 度 也 很 好 , 总 的 来 说 是 一 家 不 错 的 酒 店 。'}]
"""
12Diverse beam search decoding
多样化集束搜索解码策略是对集束搜索策略的扩展,可以生成更多样化的集束序列供人们选择。要了解它的工作原理,请参考《多样化集束搜索》https://arxiv.org/pdf/1610.02424.pdf: 从神经序列模型解码多样化的解决方案。这种方法有两个主要参数:num_beams和num_beam_groups。组的选择是为了确保它们与其他组相比有足够的区别,并在每个组内使用常规集束搜索。
from transformers import AutoTokenizer, AutoModelForCausalLM, TextGenerationPipeline, pipeline
tokenizer = AutoTokenizer.from_pretrained("./gpt2-chinese")
model = AutoModelForCausalLM.from_pretrained("./gpt2-chinese")
from datasets import load_dataset
data_file = "./ChnSentiCorp_htl_all.csv"
dataset = load_dataset("csv", data_files=data_file)
dataset = dataset.filter(lambda x: x["review"] is not None)
dataset = dataset["train"].train_test_split(0.2, seed=123)
import random
example = random.choice(dataset["train"])
# text = dataset["train"][0]
text = example["review"]
input_text = text[:10]
print(input_text)
# greedy search
model.eval()
with torch.no_grad():
encoding = tokenizer(input_text,
return_tensors='pt',
padding=False,
add_special_tokens=False,
return_token_type_ids=False,
return_attention_mask=False,)
generated_ids = model.generate(**encoding,
max_length=100,
eos_token_id=0,
pad_token_id=0,
do_sample=False,
num_beams=4,
num_beam_groups=4,
)
generated_texts = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_texts)
text_generator = TextGenerationPipeline(model, tokenizer)
print(text_generator(input_text,
max_length=100,
eos_token_id=0,
num_beams=4,
do_sample=False,
pad_token_id=0,
num_beam_groups=4,
))
generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
generation_config = {
"max_length": 100,
"eos_token_id": 0,
"pad_token_id": 0,
"num_beams": 4,
"do_sample": False,
"num_beam_groups": 4,
}
print(generator(input_text, **generation_config))
"""
住过如此之多的如家酒
['住 过 如 此 之 多 的 如 家 酒 店 , 这 一 家 是 最 差 的 , 服 务 差 , 房 间 老 旧 , 而 且 价 格 还 不 低 。 下 次 不 会 再 住 了 。']
[{'generated_text': '住过如此之多的如家酒 店 , 这 一 家 是 最 差 的 , 服 务 差 , 房 间 老 旧 , 而 且 价 格 还 不 低 。 下 次 不 会 再 住 了 。'}]
[{'generated_text': '住过如此之多的如家酒 店 , 这 一 家 是 最 差 的 , 服 务 差 , 房 间 老 旧 , 而 且 价 格 还 不 低 。 下 次 不 会 再 住 了 。'}]
"""
Part5补充
13常用的一些参数:
no_repeat_ngram_size:限制任意 N-gram 不会出现两次。但是, n-gram 惩罚使用时必须谨慎,如一篇关于 纽约 这个城市的文章就不应使用 2-gram 惩罚,否则,城市名称在整个文本中将只出现一次! num_return_sequences :选择返回句子的数量,记得确保 num_return_sequences <= num_beamstop_p top_k temperature repetition_penalty
14采样
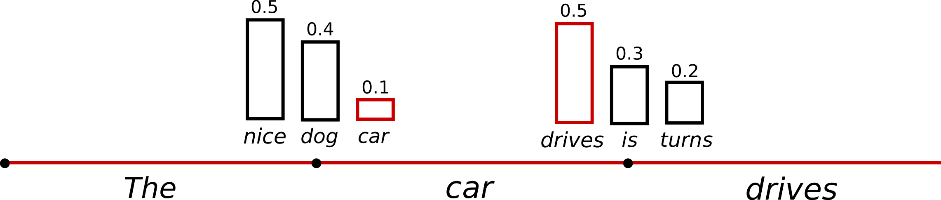
采样意味着根据当前条件概率分布随机选择输出词 ,使用采样方法时文本生成本身不再是确定性的。对单词序列进行采样时的大问题: 模型通常会产生不连贯的乱码。可以设置top_k=0关闭采样。缓解这一问题的一个技巧是通过降低所谓的 softmax 的“温度”使分布 更陡峭。而降低“温度”,本质上是增加高概率单词的似然并降低低概率单词的似然。
将温度应用到于我们的例子中后,结果如下图所示。
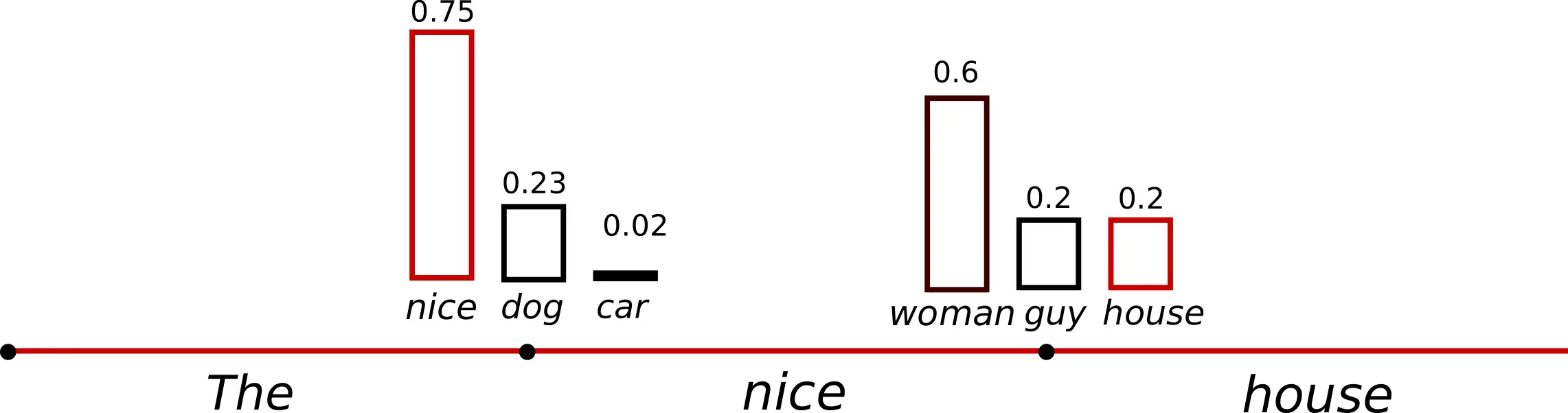
时刻单词的条件分布变得更加陡峭,几乎没有机会选择单词 “car” 了。虽然温度可以使分布的随机性降低,但极限条件下,当“温度”设置为 0 时,温度缩放采样就退化成贪心解码了,因此会遇到与贪心解码相同的问题。
15Top-K采样
在 Top-K 采样中,概率最大的 K 个词会被选出,然后这 K 个词的概率会被重新归一化,最后就在这重新被归一化概率后的 K 个词中采样。 GPT2 采用了这种采样方案,这也是它在故事生成这样的任务上取得成功的原因之一。
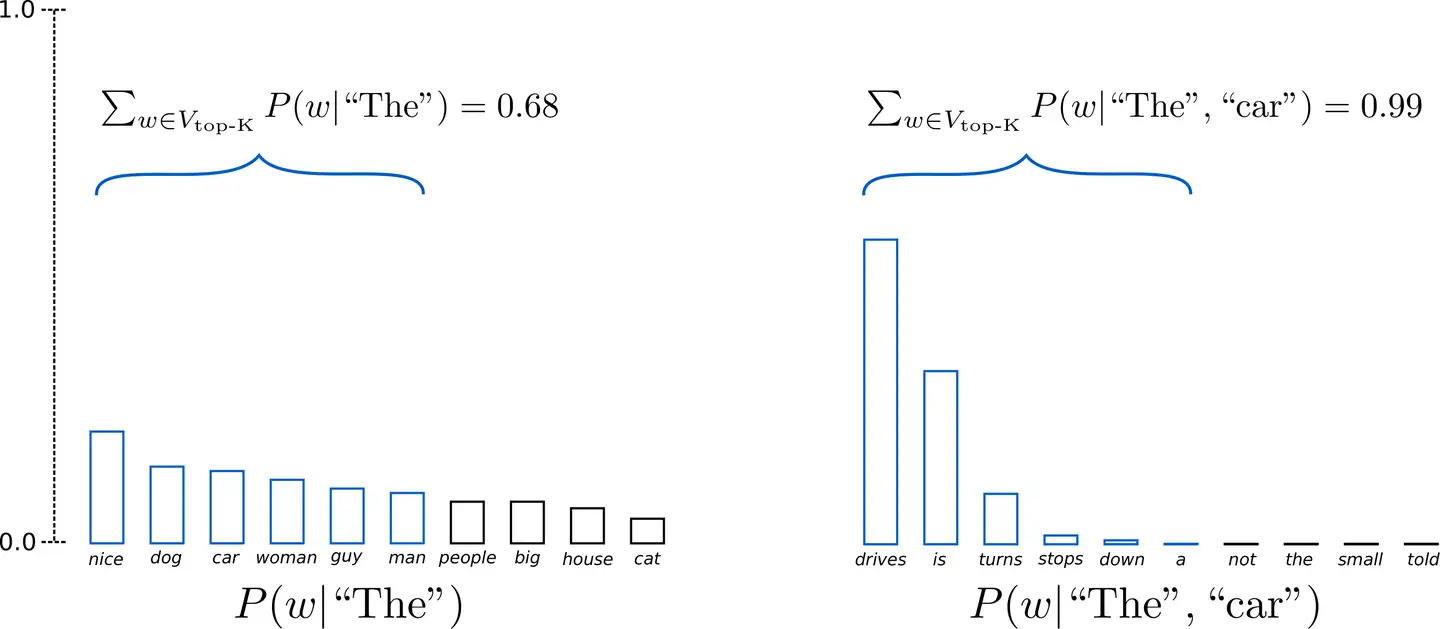
假设:top_k=6
输入:the, the的下一个词从概率最大的top6里面采样到car,the car的下一个词从概率最大的top6里面采样。可以看到后面一些奇怪的词就可以被忽略掉。
16Top-P采样
在 Top-p 中,采样不只是在最有可能的 K 个单词中进行,而是在累积概率超过概率 p 的最小单词集中进行。然后在这组词中重新分配概率质量。这样,词集的大小 (又名 集合中的词数) 可以根据下一个词的概率分布动态增加和减少。好吧,说的很啰嗦,一图胜千言。
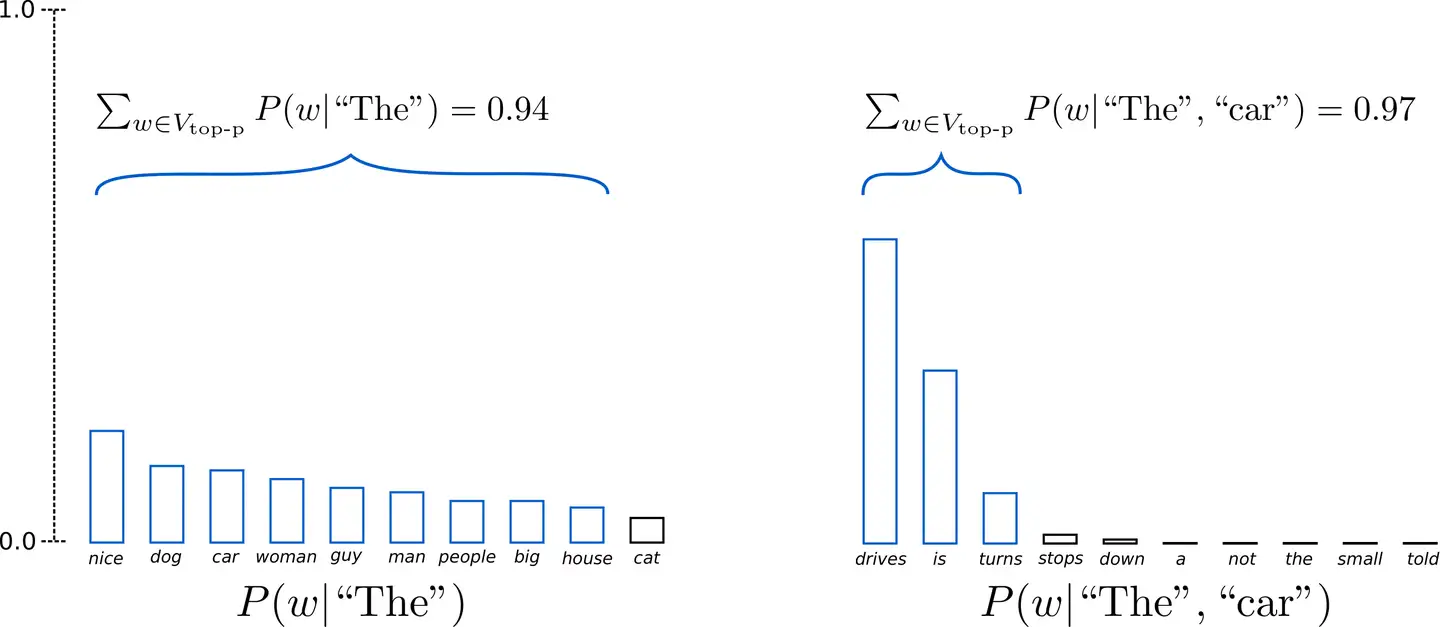
假设 p=0.92 , Top-p 采样对单词概率进行降序排列并累加,然后选择概率和首次超过 p=0.92 的单词集作为采样池,可以看出,在单词比较不可预测时,它保留了更多的候选词。而当单词似乎更容易预测时,只保留了几个候选词。
一般而言,结合top_k和top_p会有不错的效果。
Part6参考
Text generation strategies (huggingface.co)
transformers/configuration_utils.py at v4.28.1 · huggingface/transformers · GitHub
transformers/text_generation.py at v4.28.1 · huggingface/transformers · GitHub
基于 transformers 的 generate() 方法实现多样化文本生成:参数含义和算法原理解读_transformers generate_木尧大兄弟的博客-CSDN博客
https://zhuanlan.zhihu.com/p/624636122
文中部分文字和图摘自上述文章。
LLM(大语言模型)解码时是怎么生成文本的?的更多相关文章
- 利用RNN(lstm)生成文本【转】
本文转载自:https://www.jianshu.com/p/1a4f7f5b05ae 致谢以及参考 最近在做序列化标注项目,试着理解rnn的设计结构以及tensorflow中的具体实现方法.在知乎 ...
- Sandcastle----强大的C#文档生成工具
最近客户索要产品的二次开发类库文档,由于开发过程中并没有考虑过此类文档,而且项目规范比较,持续时间比较长,经手人比较多,还真是麻烦,如果人工制作文档需要是一个比较大的工程.还好有这个文档生成工具,能够 ...
- NLP(二十一)根据已有文本LSTM自动生成文本
根据已有文本LSTM自动生成文本 原理 与股票预测类似,用前面的n个字符预测下一个字符 https://www.cnblogs.com/peng8098/p/keras_5.html 代码 from ...
- Python生成文本格式的excel\xlwt生成文本格式的excel\Python设置excel单元格格式为文本\Python excel xlwt 文本格式
Python生成文本格式的excel\xlwt生成文本格式的excel\Python设置excel单元格格式为文本\Python excel xlwt 文本格式 解决: xlwt 中设置单元格样式主要 ...
- 用迁移学习创造的通用语言模型ULMFiT,达到了文本分类的最佳水平
https://www.jqr.com/article/000225 这篇文章的目的是帮助新手和外行人更好地了解我们新论文,我们的论文展示了如何用更少的数据自动将文本分类,同时精确度还比原来的方法高. ...
- 为训练深度OCR 图像,生成文本图像
https://github.com/Sanster/text_renderer Generate text images for training deep learning ocr model 在 ...
- Linux命令应用大词典-第5章 显示文本和文件内容
5.1 cat:显示文本文件 5.2 more:分页显示文本文件 5.3 less:回卷显示文本文件 5.4 head:显示指定文件前若干行 5.5 tail:查看文件末尾数据 5.6 nl:显示文件 ...
- 借助ltp 逐步程序化实现规则库 文本生成引擎基于规则库和业务词库 去生成文本
[哪个地方做什么的哪家靠谱?地名词库行业.业务词库]苏州做网络推广的公司哪家靠谱?苏州镭射机维修哪家最专业?昆山做账的公司哪家比较好广州称重灌装机生产厂家哪家口碑比较好 [含有专家知识]郑州律师哪个好 ...
- Texygen文本生成,交大计算机系14级的朱耀明
文本生成哪家强?上交大提出基准测试新平台 Texygen 2018-02-12 13:11测评 新智元报道 来源:arxiv 编译:Marvin [新智元导读]上海交通大学.伦敦大学学院朱耀明, 卢思 ...
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
随机推荐
- Pytorch slp singleLayerPerceptron 单层感知机
单层感知机 \[\begin{aligned} & y = XW + b \\ & y = \sum x_i*w_i+b\\ \end{aligned} \] Derivative \ ...
- 6.3dmax小场景案例
# 知识点: 1.cut剪切 --- 快捷键 alt+c 2.仅影响轴.坐标轴回到物体中心 3.Mirror镜像 4.attach附加.detach分离 5.Collapse.Weld合点 6.bev ...
- Ubuntu 20.04 使用deb包安装mysql
Ubuntu 20.04 使用deb包安装mysql 1.环境 WSL2 + Ubuntu 20.04 2.下载mysql的Ubuntu / Debian安装包 MySQL :: Download M ...
- Matlab - 在Figure界面去掉图像的坐标刻度
Matlab版本:2018b 经过一番尝试,发现有两种方法 第一种:修改坐标轴的Visible属性,去掉坐标轴数字和坐标轴标签 第二种:删除Tick,只去掉坐标轴数字 第一种 ①原图 ②如果有多个子图 ...
- JMeter压测脚本实例:单接口
新建测试计划 添加线程组 添加HTTP请求 配置该请求相关参数 1.请求头部信息 ①HTTP请求同级线程组下添加HTTP信息头部管理器 ②填充该请求所需的头部信息 2.请求体 选中之前增加的HTTP请 ...
- DVWA-Brute Force(暴力破解)
暴力破解漏洞,没有对登录框做登录限制,攻击者可以不断的尝试暴力枚举用户名和密码 LOW 审计源码 <?php // 通过GET请求获取Login传参, // isset判断一个变量是否已设置,判 ...
- Flink模式
Per-job Cluster 该模式下,一个作业一个集群,作业之间相互隔离. 在Per-Job模式下,集群管理器框架用于为每个提交的Job启动一个 Flink 集群.Job完成后,集群将关闭,所有残 ...
- 干货 | BitSail Connector 开发详解系列一:Source
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 BitSail 是字节跳动自研的数据集成产品,支持多种异构数据源间的数据同步,并提供离线.实时.全量.增量场景下全 ...
- DFS总结
常见剪枝方法 优化搜索顺序 优先搜索决策树较小的点,例如在165. 小猫爬山一题中,优先搜索体重较大的扩展出的情况较少 排除冗余信息 如果某些情况在此前已经被搜索过了,那么无需继续搜索 可行性剪枝 如 ...
- 在k8s安装CICD-devtron
在k8s安装CICD-devtron 先前条件 <kubernetes(k8s) 存储动态挂载>参考我之前的文档进行部署https://www.oiox.cn/index.php/arch ...