EfficientFormer:轻量化ViT Backbone
论文:《EfficientFormer: Vision Transformers at MobileNet Speed 》
Vision Transformers (ViT) 在计算机视觉任务中取得了快速进展,开启了 Vision + Transformer 的先河,之后大量的论文和研究都基于 ViT 之上的。不过呢,Transformer 由于 Attention 的结构设计需要大量的参数,执行的性能也比经过特殊优化的 CNN 要慢一点。
像是之前介绍的 DeiT 利用 ViT + 蒸馏让训练得更快更方便,但是没有解决 ViT 在端侧实时运行的问题。于是后来有了各种 MateFormer、PoolFormer 等各种 XXXFormer 的变种。应该在不久之前呢,Facebook 就提出了 mobilevit,借鉴了端侧 YYDS 永远的神 mobileNet 的优势结构和 Block(CNN) + ViT 结合,让 ViT 开启了端侧可运行的先河。不管是 XXXFormer 还是 mobileNet,主要是试图通过网络架构搜索(AutoML)或与 MobileNet 块的混合设计来降低 ViT 的计算复杂度,但推理速度嘛,还是没办法跟 mobileNet 媲美。
这就引出了一个重要的问题:Transformer 能否在获得高性能的同时跑的跟 MobileNet 一样快?
作者重新审视基于 ViT 的模型中使用的网络架构和具体的算子,找到端侧低效的原因。然后引入了维度一致的 Transformer Block 作为设计范式。最后,通过网络模型搜索获得不同系列的模型 —— EfficientFormer。
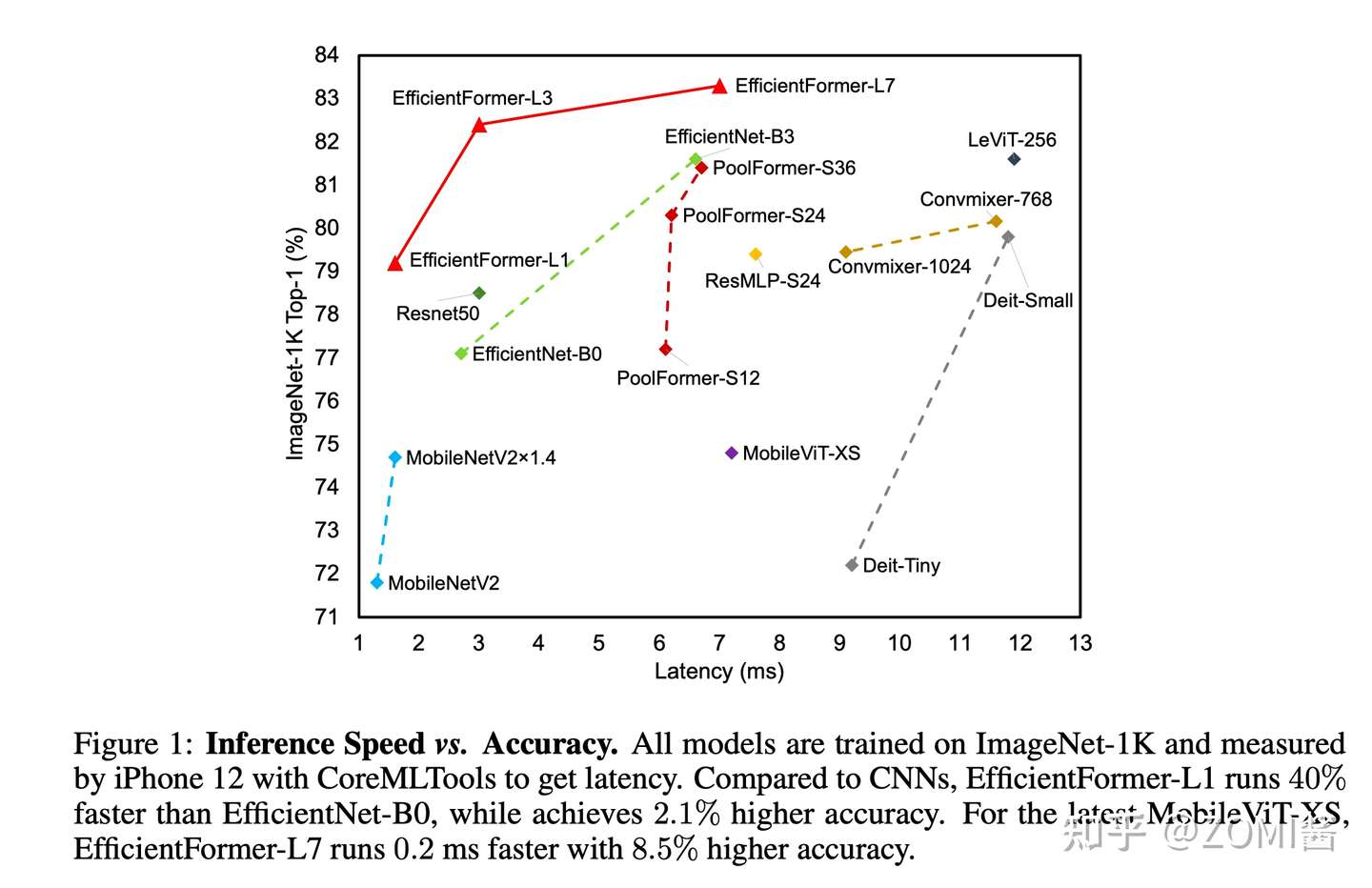
ViT 实时运行分析
图中作者作者对不同模型在端侧运行进行了一些分析,主要是分为 ViT 对图像进行分块的 Patch Embedding、Transformer 中的 Attention 和 MLP,另外还有 LeViT 提出的 Reshape 和一些激活等。基于下面这个表,提出了几个猜想,然后设计出了 EfficientFormer 结构。

- 猜想分析1:大 kernel 和 stride 的Patch embedding是速度瓶颈
Patch embedding 通常使用具有较大kernel-size和stride的非重叠卷积层来实现。大部分AI编译器都不能很好地支持大内核卷积,并且无法通过 Winograd 等现有算法进行加速。
- 猜想分析2:特征维度一致对于 token mixer 的选择很重要
很多翻译这里写得很玄乎,ZOMI酱的理解是特征维度一致比多头注意力机制对延迟的影响更重要啦,也就是 MLP 实际上并没有那么耗时,但是如果 tensor 的shape一会大一会小,就会影响计算时延。所以 EfficientFormer 提出了具有 4D 特征实现和 3D 多头注意力的维度一致网络,并且消除了低效且频繁 Reshape 操作(主要指 LeViT 中的 Reshape 操作)。
- 猜想分析3:CONV + BN 比 MLP + LN 效率更高
在 CNN 结构中最经典的就是使用3x3卷积 Conv + Batch Normalization(BN)的组合方式(获取局部特征),而在 Transformer 中最典型的方式是使用 linear projection(MLP)+ layer normalization(LN)(获取全局特征)的组合。不过作者对比测试中发现呀,CONV + BN 比 MLP + LN 效率更高。
- 猜想分析4:激活函数取决于编译器
最后这个就比较简单,激活函数包括 GeLU、ReLU 和 HardSwish 的性能在 TensorRT 或者 CoreML 中都不一样,所以激活的优化主要是看用什么端侧编译器。
EfficientFormer 架构
第4个点不太重要,主要是关注1,2,3点。于是引出了 EfficientFormer 的总结架构啦。 EfficientFormer 由 patch embedding (PatchEmbed) 和 meta transformer blocks 组成,表示为 MB:
X_0 是输入图像,Batch Size 为 B,featur map 大小为 [H,W],Y 是输出,m 是Block的数量。MB 由未指定的 TokenMixer 和 MLP Block 组成,可以表示如下:
X_i 是第 i 个 MB 的featur map。进一步将 Stage 定义为处理具有相同空间大小的特征的几个 MetaBlock 的堆栈,图 N_1x 表示 S1 具有 N_1 个 MetaBlock。
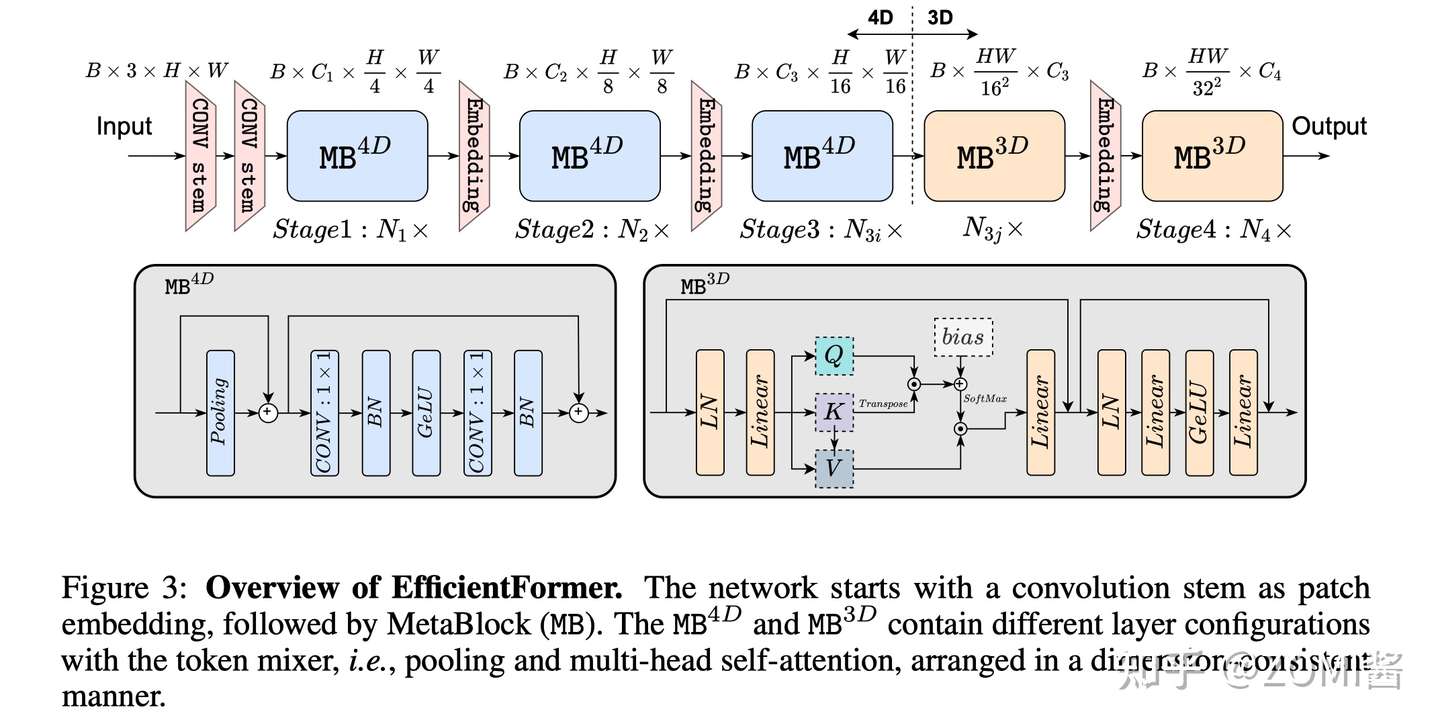
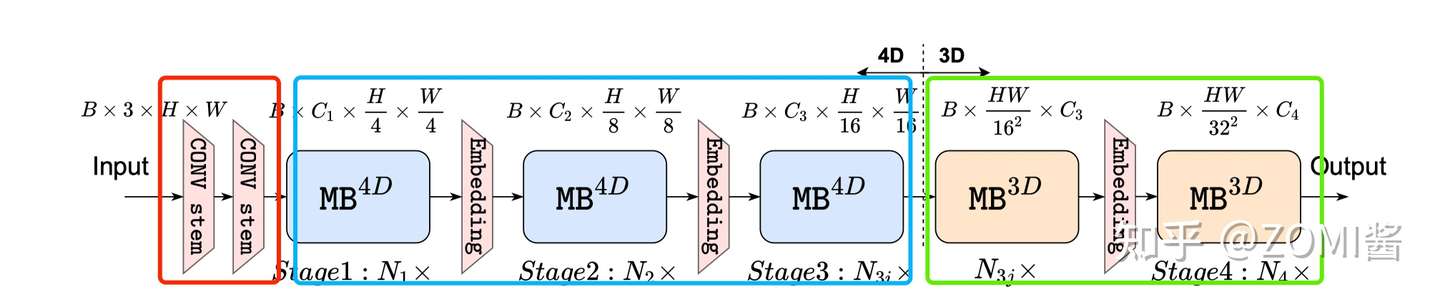
可以看到 EfficientFormer 一共有4个阶段。每个阶段都有一个 Embeding(两个3x3的Conv组成一个Embeding) 来投影 Token 长度(可以理解为CNN中的feature map)。可以看到啦,EfficientFormer 是一个完全基于Transformer设计的模型,没有集成 MobileNet 相关内容啦。
最后通过 AUTOML 来搜索 MB_3D 和 MB_4D block 相关参数。
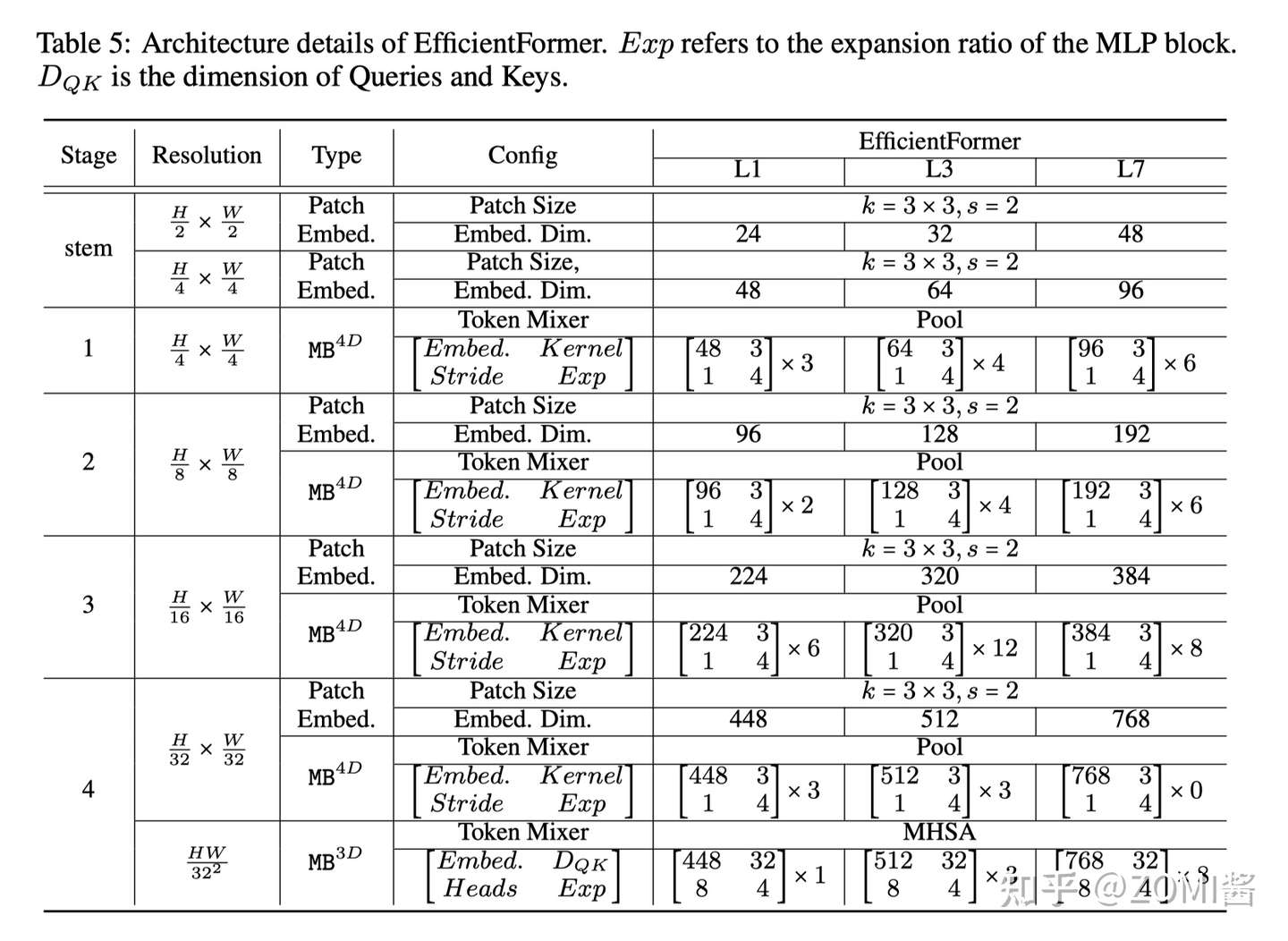
维度一致性 dimension-consistent
根据 猜想分析2:特征维度一致对于 token mixer 的选择很重要 EfficientFormer 提出了一种维度一致的设计,将网络分成一个 MB_4D,以 CNN 结构为主 (MB4D) 实现;以及一个 MB_3D ,MLP 线性投影和 Attention 注意力在 3D tensor 上运行。网络从 patch embedding 开始,然后就到了 4D 分区,3D 分区在最后阶段应用。最后 4D 和 3D 分区的实际长度是稍后通过架构搜索指定的。
这里面的 4D 主要是指 CNN 结构中 tensor 的维度 [B, C, W, H],而 3D 主要是指 Tran 结构中 tensor 的维度 [B, W, H]。
网络从使用由具有2个 kernel-size为 3×3, Stride=2 的卷积组成的 Conv stem 处理后的图像作为 patch embedding:
其中 C_j 是第 j 个阶段的通道数(宽度)。然后网络从 MB_4D 开始,使用简单的 Pool ing 来提取 low level特征:
其中 Conv_B,G 是指卷积后是否分加上BN和GeLU。
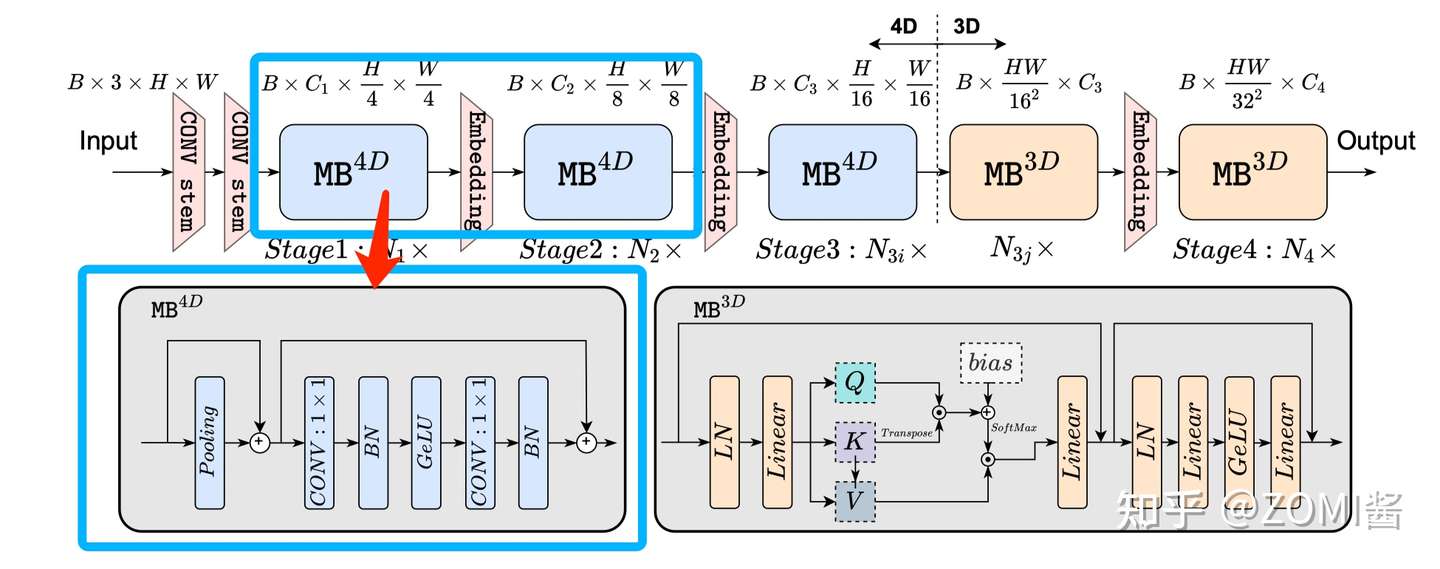
在处理完所有 MB4D 块后,执行一次Reshape以变换 freature map 并进入 3D 分区。MB3D 遵循传统的 ViT,不过作者把 ReLU 换成了 GeLU 哦。
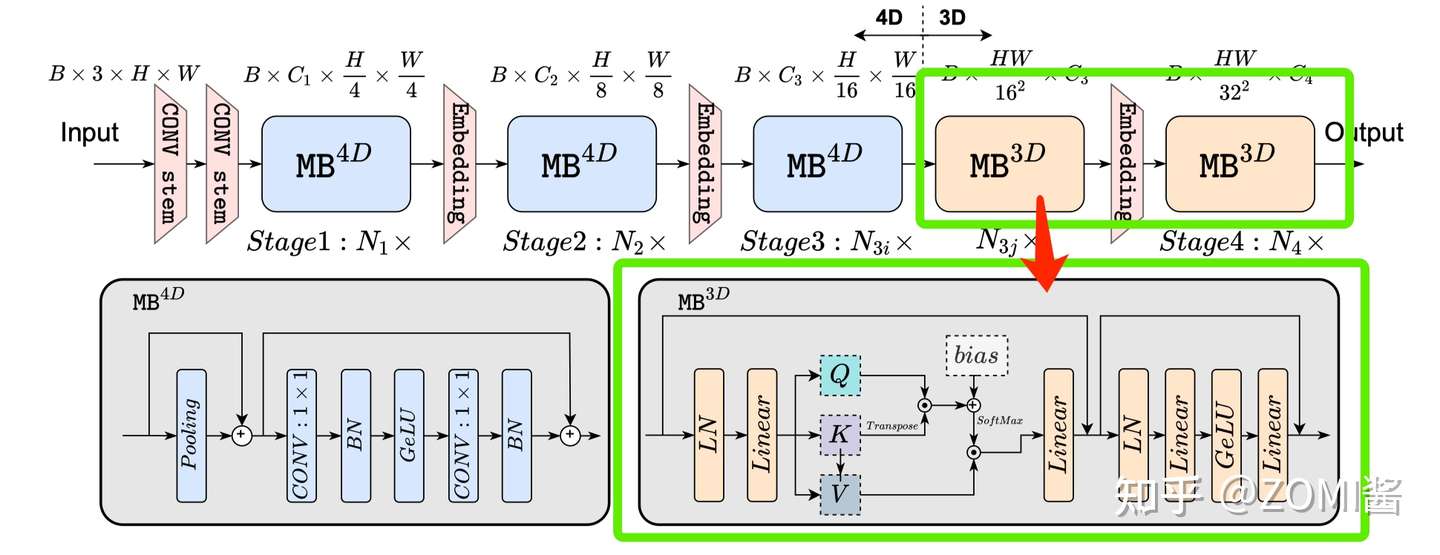
实时运行模型瘦身 Latency Driven Slimming
基于 dimension-consistent,EfficientFormer 构建了一个 Supernet,用于搜索 EfficientFormer 架构的高效模型。下面定义一个 MetaPath (MP):
I 呢表示 identity path,j 表示第 j 个阶段,i 表示第 i 个块。搜索网络Supernet 中通过用 MP 代替 EfficientFormer 的 MB。
在 Supernet 的第1阶段和第2阶段中,每个 Block 可以选择 MB4D 或 I,而在第3阶段和第4阶段中,Block可以是 MB3D、MB4D 或 I。
EfficientFormer 只在最后两个阶段启用 MB3D,原因有2个:1)多头注意力的计算相对于Token长度呈二次增长,因此在模型早期集成会大大增加计算成本。2)将全局多头注意力应用于最后阶段符合直觉,即网络的早期阶段捕获低级特征,而后期层则学习长期依赖关系。
- 搜索空间
搜索空间包括 C_j(每个 Stage 的宽度)、N_j(每个 Stage 中的块数,即深度)和最后 N 个 MB3D 的块。
- 搜索算法
传统的硬件感知网络搜索方法,通常依赖于每个候选模型在搜索空间中的硬件部署来获得延迟,这是非常耗时的。EfficientFormer提出了基于梯度的搜索算法,以获得只需要训练一次Supernet的候选网络。
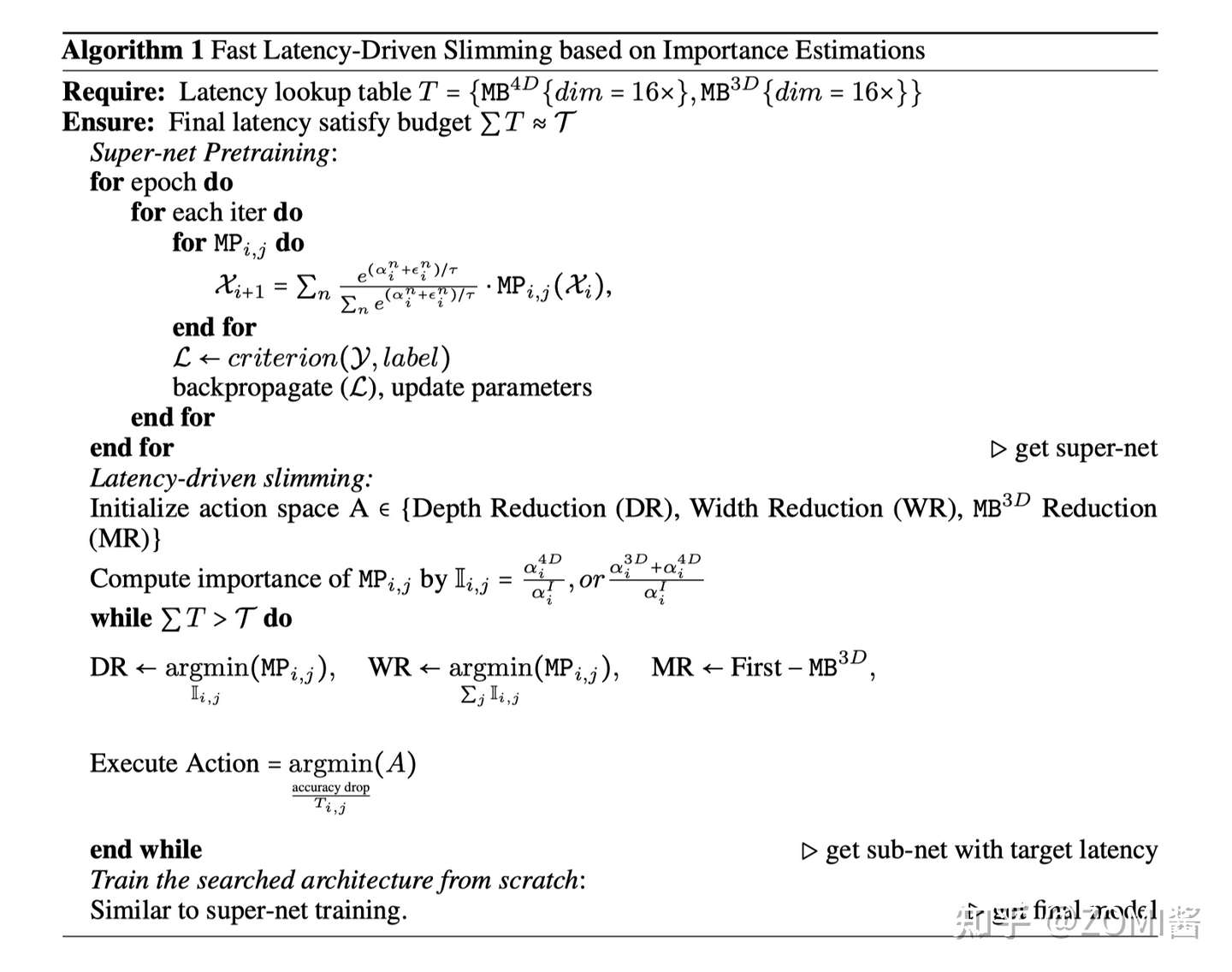
(后续可以针对 NASA 搜索进行详细补充这个内容。)
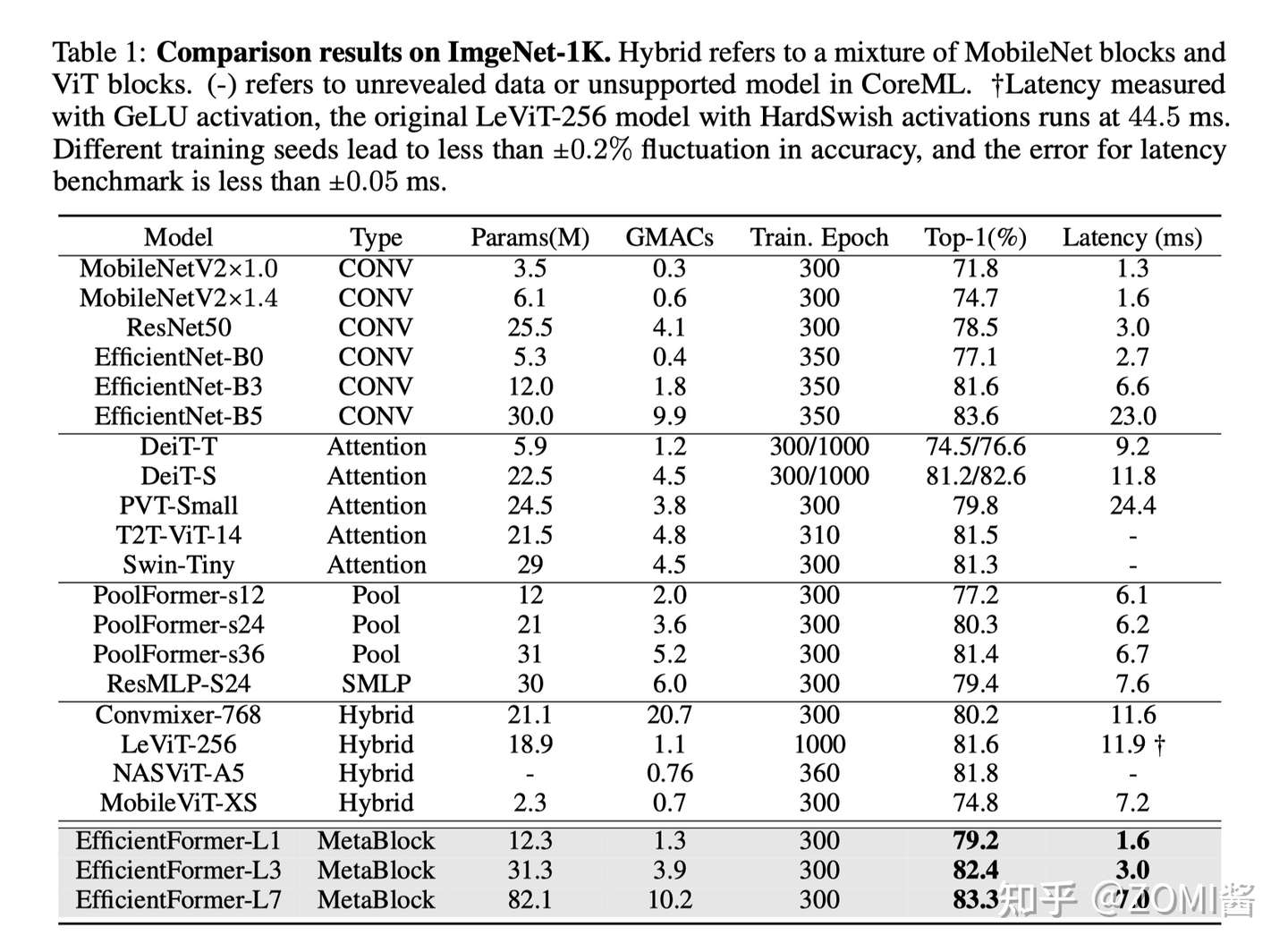
实验结果
总的来说呢,EfficientFormer-L1 在 ImageNet-1K 分类任务上实现了 79.2% 的 top-1 准确率,推理时间仅为 1.6 ms,与 MobileNetV2 相比,延迟降低了 6%,top-1 准确率提高了 7.4%。延迟不是 ViT 在端侧部署的障碍。
另外,EfficientFormer-L7 实现了 83.3% 的准确率,延迟仅为 7.0 ms,大大优于 ViT×MobileNet 混合设计(MobileViT-XS,74.8%,7.2ms)。

最后通过使用 EfficientFormer 作为图像检测和分割基准的 Backbone,性能也是非常赞的。ViTs 确实可以实现超快的推理速度和强大的性能。
小结
MobileViT 结构上基本基于 MobileNet V2 而改进增加了 MobileViT block,但是同样能够实现一个不错的精度表现,文章实验部分大量的对比了 MobileViT 跟 CNN 和 ViT 模型的参数量和模型大小,不过值得一提的是在端侧除了模型大小以外,更加重视模型的性能,只能说这篇文章经典之处是开创了 CNN 融合 ViT 在端侧的研究。
引用
[1] Li, Yanyu, et al. "EfficientFormer: Vision Transformers at MobileNet Speed." arXiv preprint arXiv:2206.01191 (2022).
[2] EfficientFormer | 苹果手机实时推理的Transformer模型,登顶轻量化Backbone之巅
[3] CVer计算机视觉:EfficientFormer:MobileNet 速度下的视觉Transformer
EfficientFormer:轻量化ViT Backbone的更多相关文章
- CNN结构演变总结(二)轻量化模型
CNN结构演变总结(一)经典模型 导言: 上一篇介绍了经典模型中的结构演变,介绍了设计原理,作用,效果等.在本文,将对轻量化模型进行总结分析. 轻量化模型主要围绕减少计算量,减少参数,降低实际运行时间 ...
- 轻量化模型系列--GhostNet:廉价操作生成更多特征
前言 由于内存和计算资源有限,在嵌入式设备上部署卷积神经网络 (CNN) 很困难.特征图中的冗余是那些成功的 CNN 的一个重要特征,但在神经架构设计中很少被研究. 论文提出了一种新颖的 Gh ...
- 轻量化ViewControllers,读文章做的总结
推荐一个网站 http://objccn.io/ 我这两天才开始看 获益匪浅 看了第一篇文章 <更轻量的View Controllers>感觉写的不错 感觉作者 原文地址 http://o ...
- 轻量化卷积神经网络MobileNet论文详解(V1&V2)
本文是 Google 团队在 MobileNet 基础上提出的 MobileNetV2,其同样是一个轻量化卷积神经网络.目标主要是在提升现有算法的精度的同时也提升速度,以便加速深度网络在移动端的应用.
- 基于WebGL/Threejs技术的BIM模型轻量化之图元合并
伴随着互联网的发展,从桌面端走向Web端.移动端必然的趋势.互联网技术的兴起极大地改变了我们的娱乐.生活和生产方式.尤其是HTML5/WebGL技术的发展更是在各个行业内引起颠覆性的变化.随着WebG ...
- 铁大Facebook轻量化界面NABCD
界面轻量化: N:满足了用户更快速.更直接.更方便寻求自己所要信息的需求,不被复杂界面以及各种广告所困扰. A:我们将会用Bootstrap工具包开发前端界面,Bootstrap是基于jQuery框架 ...
- 毕加索发布轻量化转化引擎及BIMSOP协作云平台
一直以来,杂务缠身,博客都好久没有更新了,以后还是要继续坚持总结一下.希望能有时间坚持下去 :) 月初在国家会议中的智能展会上,我分享了毕加索公司近来的工作,即自行研发的轻量化转化云平台,以及以此为基 ...
- js便签笔记(14)——用nodejs搭建最简单、轻量化的http server
1. 引言 前端程序猿主要关注的是页面,你可能根本就用不到.net,java,php等后台语言. 但是你制作出来的网页总要运行.总要测试吧?——那就免不了用到http server.我先前都是用vis ...
- 【本地服务器】用nodejs搭建最简单、轻量化的http server
1. 引言 前端程序猿主要关注的是页面,你可能根本就用不到.net,java,php等后台语言. 但是你制作出来的网页总要运行.总要测试吧?——那就免不了用到http server.我先前都是用vis ...
随机推荐
- python爬取豆瓣电影Top250(附完整源代码)
初学爬虫,学习一下三方库的使用以及简单静态网页的分析.就跟着视频写了一个爬取豆瓣Top250排行榜的爬虫. 网页分析 我个人感觉写爬虫最重要的就是分析网页,找到网页的规律,找到自己需要内容所在的地方, ...
- SQL注入到getshell
SQL注入到getshell 通过本地 pikachu来复现 前提: 1.存在SQL注入漏洞 2.web目录具有写入权限 3.找到网站的绝对路径 4.secure_file_priv没有具体值(se ...
- 5┃音视频直播系统之 WebRTC 中的协议UDP、TCP、RTP、RTCP详解
一.UDP/TCP 如果让你自己开发一套实时互动直播系统,在选择网络传输协议时,你会选择使用UDP协议还是TCP协议 假如使用 TCP 会怎样呢?在极端网络情况下,TCP 为了传输的可靠性,将会进行反 ...
- FinClip小程序+Rust(三):一个加密钱包
一个加密货币钱包,主要依赖加密算法构建.这部分逻辑无关iOS还是Android,特别适合用Rust去实现.我们看看如何实现一个生成一个模拟钱包,准备供小程序开发采用 前言 在之前的内容我们介绍了整 ...
- 好客租房25-react中的事件处理(事件对象)
3.2事件对象 可以通过事件处理程序的参数 React中的事件对象叫做:合成事件(对象) 合成事件:兼容所有浏览器 //导入react import React from 'react' ...
- DeepPrivacy: A Generative Adversarial Network for Face Anonymization阅读笔记
DeepPrivacy: A Generative Adversarial Network for Face Anonymization ISVC 2019 https://arxiv.org/pdf ...
- vue运行npm run dev时候,自动打开页面
在config/index.js找到dev:{}里面的autoOpenBrowser: 设置为true,重新npm run dev一次就自动弹出浏览器页面啦!
- App上看到就忍不住点的小红点是如何实现的?
你有没有发现,我们解锁手机后桌面上App右上角总能看到一个小红点,这就是推送角标.推送角标指的是移动设备上App图标右上角的红色圆圈,圆圈内的白色数字表示未读消息数量.角标是一种比较轻的提醒方式,通过 ...
- rpm 系 linux 系统中 repo 文件中的 $release 到底等于多少?
rpm 系 linux 系统中 repo 文件中的 $release 到底等于多少? 结论 对于 8 来说,通过以下命令 #/usr/libexec/platform-python -c 'impor ...
- MySQL 8.0 新特性梳理汇总
一 历史版本发布回顾 从上图可以看出,基本遵循 5+3+3 模式 5---GA发布后,5年 就停止通用常规的更新了(功能不再更新了): 3---企业版的,+3年功能不再更新了: 3 ---完全停止更新 ...