【Kaggle】如何有效避免OOM(out of memory)和漫长的炼丹过程
本文介绍一些避免transformers的OOM以及训练等流程太漫长的方法,主要参考了kaggle notebook Optimization approaches for Transformers | Kaggle,其中梯度累积Gradient Accumulation,冻结Freezing已经在之前的博客中介绍过,本文会依次介绍混合精度训练Automatic Mixed Precision, 8-bit Optimizers, and 梯度检查点Gradient Checkpointing, 然后介绍一些NLP专用的方法,比如Dynamic Padding, Uniform Dynamic Padding, and Fast Tokenizers.
Automatic Mixed Precision
作用:不损失最终质量的情况下减少内存消耗和训练时间
关键思想:是使用较低的精度将模型的梯度和参数保持在memory中,即不是使用全精度 (例如float32),而是使用半精度 (例如float16) 将张量保持在memory中。但是,当以较低的精度计算梯度时,某些值可能很小,以至于它们被视为零,这种现象称为 “overflow”。为了防止 “overflow溢出”,原始论文的作者提出了一种梯度缩放方法。
PyTorch提供了一个具有必要功能 (从降低精度到梯度缩放) 的软件包,用于使用自动混合精度,称为torch.cuda.amp。自动混合精度可以轻松地将其插入训练和推理代码中。
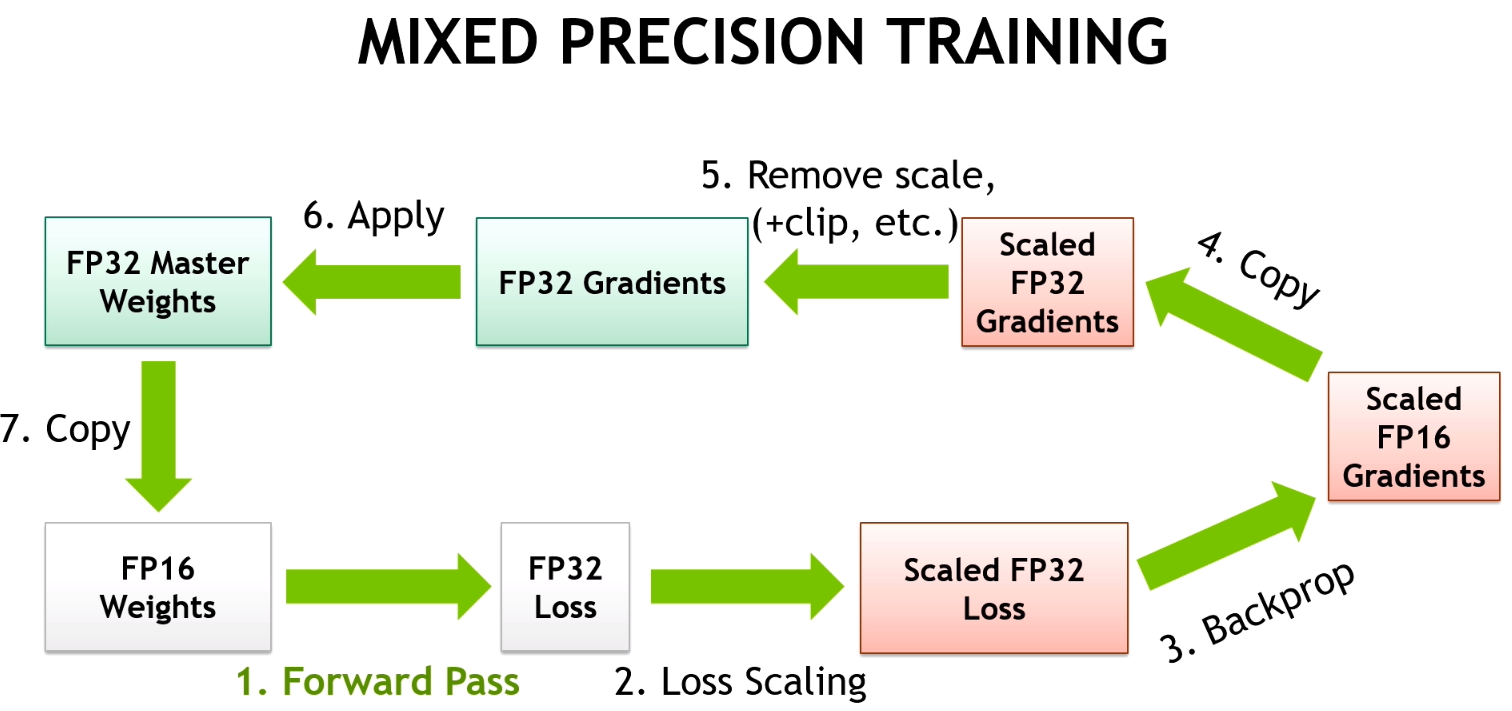
Vanilla training loop
for step, batch in enumerate(loader, 1):
# prepare inputs and targets for the model and loss function respectively.
# forward pass
outputs = model(inputs)
# computing loss
loss = loss_fn(outputs, targets)
# backward pass
loss.backward()
# perform optimization step
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
optimizer.step()
model.zero_grad()
Training loop with Automatic Mixed Precision
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for step, batch in enumerate(loader, 1):
# prepare inputs and targets for the model and loss function respectively.
# forward pass with `autocast` context manager!!
with autocast(enabled=True):
outputs = model(inputs)
# computing loss
loss = loss_fn(outputs, targets)
# scale gradint and perform backward pass!!
scaler.scale(loss).backward()
# before gradient clipping the optimizer parameters must be unscaled.!!
scaler.unscale_(optimizer)
# perform optimization step
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
scaler.step(optimizer)
scaler.update()
8-bit Optimizers
8位优化器的思想类似于自动混合精度,其中模型的参数和梯度保持在较低的精度,但8位优化器还将优化器的状态保持在较低的精度。https://arxiv.org/abs/2110.02861作者表明8位优化器显著降低了内存利用率,略微加快了训练速度。此外,作者研究了不同超参数设置的影响,并表明8位优化器对不同的学习速率、beta和权重衰减参数的选择是稳定的,不会损失性能或损害收敛性。因此,作者为8位优化器提供了一个高级库,称为bitsandbytes。
Initializing optimizer via PyTorch API
import torch
from transformers import AutoConfig, AutoModel
# initializing model
model_path = "microsoft/deberta-v3-base"
config = AutoConfig.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path, config=config)
# selecting parameters, which requires gradients
model_parameters = filter(lambda parameter: parameter.requires_grad, model.parameters())
# initializing optimizer
optimizer = torch.optim.AdamW(params=model_parameters, lr=2e-5, weight_decay=0.0)
print(f"32-bit Optimizer:\n\n{optimizer}")
32-bit Optimizer:
AdamW (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.999)
eps: 1e-08
lr: 2e-05
maximize: False
weight_decay: 0.0
)
Initializing optimizer via bitsandbytes API
!pip install -q bitsandbytes-cuda110
def set_embedding_parameters_bits(embeddings_path, optim_bits=32):
"""
https://github.com/huggingface/transformers/issues/14819#issuecomment-1003427930
"""
embedding_types = ("word", "position", "token_type")
for embedding_type in embedding_types:
attr_name = f"{embedding_type}_embeddings"
if hasattr(embeddings_path, attr_name):
bnb.optim.GlobalOptimManager.get_instance().register_module_override(
getattr(embeddings_path, attr_name), 'weight', {'optim_bits': optim_bits}
)
import bitsandbytes as bnb
# selecting parameters, which requires gradients
model_parameters = filter(lambda parameter: parameter.requires_grad, model.parameters())
# initializing optimizer
bnb_optimizer = bnb.optim.AdamW(params=model_parameters, lr=2e-5, weight_decay=0.0, optim_bits=8)
# bnb_optimizer = bnb.optim.AdamW8bit(params=model_parameters, lr=2e-5, weight_decay=0.0) # equivalent to the above line
# setting embeddings parameters
set_embedding_parameters_bits(embeddings_path=model.embeddings)
print(f"8-bit Optimizer:\n\n{bnb_optimizer}")
8-bit Optimizer:
AdamW (
Parameter Group 0
betas: (0.9, 0.999)
eps: 1e-08
lr: 2e-05
weight_decay: 0.0
)
Gradient Checkpointing
有时,即使使用小批量和其他优化技术,例如梯度累积、冻结或自动精度训练,我们仍然可能耗尽内存,尤其是在模型足够大的情况下。作者证明了梯度检查点可以显著地将内存利用率从\(O(n)\)降低到\(O(\sqrt{n})\),其中n是模型中的层数。这种方法实现了在单个GPU上训练大型模型,或提供更多内存以增加批处理大小,从而更好更快地收敛。
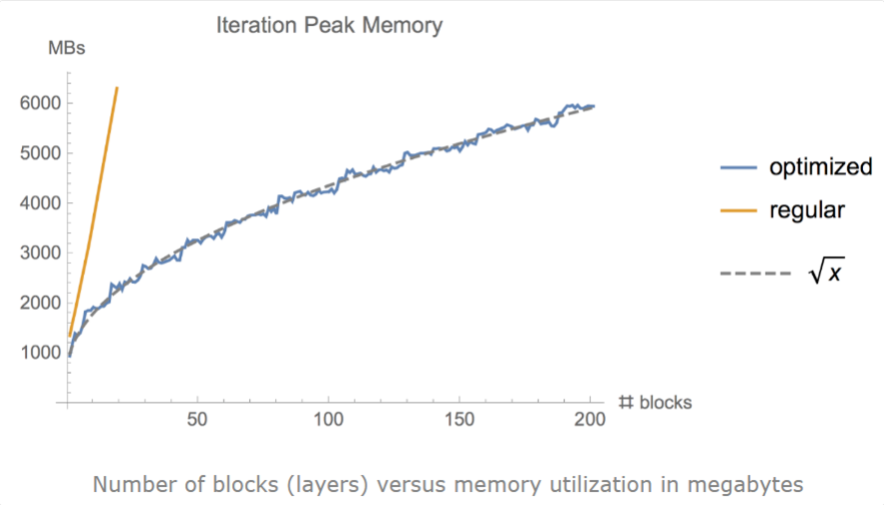
梯度检查点背后的思想是计算小块中的梯度,同时在正向和反向传播过程中从内存中删除不必要的梯度,从而降低内存利用率,尽管这种方法需要更多的计算步骤来再现整个反向传播计算图。
pytorch提供了torch.utils.checkpoint.checkpoint 和 torch.utils.checkpoint.checkpoint_sequential 函数来实现梯度检查点。
"Specifically, in the forward pass, function will run in torch.no_grad() manner, i.e., not storing the intermediate activations. Instead, the forward pass saves the inputs tuple and the function parameter. In the backwards pass, the saved inputs and function is retrieved, and the forward pass is computed on function again, now tracking the intermediate activations, and then the gradients are calculated using these activation values."
另外,huggingface同样支持梯度检查点,可以对PreTrainedModel instance使用gradient_checkpointing_enable 方法。
代码实现
from transformers import AutoConfig, AutoModel
# https://github.com/huggingface/transformers/issues/9919
from torch.utils.checkpoint import checkpoint
# initializing model
model_path = "microsoft/deberta-v3-base"
config = AutoConfig.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path, config=config)
# gradient checkpointing
model.gradient_checkpointing_enable()
print(f"Gradient Checkpointing: {model.is_gradient_checkpointing}")
Gradient Checkpointing: True
Fast Tokenizers
base和fast tokenizer的区别:fast是在rust编写的,因为python在循环中非常慢,fast可以让我们在tokenize时获得额外的加速。下图是tokenize工作的原理示意,Tokenizer类型可以通过更改 transformers.AutoTokenizer from_pretrained 将 use_fast 属性设为True。

代码实现
from transformers import AutoTokenizer
# initializing Base version of Tokenizer
model_path = "microsoft/deberta-v3-base"
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
print(f"Base version Tokenizer:\n\n{tokenizer}", end="\n"*3)
# initializing Fast version of Tokenizer
fast_tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=True)
print(f"Fast version Tokenizer:\n\n{fast_tokenizer}")
Base version Tokenizer:
PreTrainedTokenizer(name_or_path='microsoft/deberta-v3-base', vocab_size=128000, model_max_len=1000000000000000019884624838656, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'bos_token': '[CLS]', 'eos_token': '[SEP]', 'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'})
Fast version Tokenizer:
PreTrainedTokenizerFast(name_or_path='microsoft/deberta-v3-base', vocab_size=128000, model_max_len=1000000000000000019884624838656, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'bos_token': '[CLS]', 'eos_token': '[SEP]', 'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'})
Dynamic Padding
即对输入的mini batch动态进行padding,将batch的输入填充到该batch的最大输入长度,可以将训练速度提高35%甚至50%,注意,pad token不应包括在某些任务(比如MLM和NER)的损失计算过程中。
Uniform Dynamic Padding
这是基于动态填充的方法,其思想是预先按文本的相应长度对文本进行排序,在训练或推理期间比动态填充需要更少的计算。但不建议在训练期间使用统一的动态填充,因为训练意味着输入的shuffle。
【Kaggle】如何有效避免OOM(out of memory)和漫长的炼丹过程的更多相关文章
- mat 使用 分析 oom 使用 Eclipse Memory Analyzer 进行堆转储文件分析
概述 对于大型 JAVA 应用程序来说,再精细的测试也难以堵住所有的漏洞,即便我们在测试阶段进行了大量卓有成效的工作,很多问题还是会在生产环境下暴露出来,并且很难在测试环境中进行重现.JVM 能够记录 ...
- Android中内存泄露与如何有效避免OOM总结
一.关于OOM与内存泄露的概念 我们在Android开发过程中经常会遇到OOM的错误,这是因为我们在APP中没有考虑dalvik虚拟机内存消耗的问题. 1.什么是OOM OOM:即OutOfMemoe ...
- 【干货】Kaggle 数据挖掘比赛经验分享(mark 专业的数据建模过程)
简介 Kaggle 于 2010 年创立,专注数据科学,机器学习竞赛的举办,是全球最大的数据科学社区和数据竞赛平台.笔者从 2013 年开始,陆续参加了多场 Kaggle上面举办的比赛,相继获得了 C ...
- 由Kaggle竞赛wiki文章流量预测引发的pandas内存优化过程分享
pandas内存优化分享 缘由 最近在做Kaggle上的wiki文章流量预测项目,这里由于个人电脑配置问题,我一直都是用的Kaggle的kernel,但是我们知道kernel的内存限制是16G,如下: ...
- Android 内存管理 &Memory Leak & OOM 分析
转载博客:http://blog.csdn.net/vshuang/article/details/39647167 1.Android 进程管理&内存 Android主要应用在嵌入式设备当中 ...
- Android 内存管理 &Memory Leak & OOM 分析
1.Android 流程管理&内存 Android主要应用在嵌入式设备其中.而嵌入式设备因为一些众所周知的条件限制,通常都不会有非常高的配置,特别是内存是比較有限的. 假设我们编写的代 码其中 ...
- Linux 理解Linux的memory overcommit 与 OOM Killer
Memory Overcommit的意思是操作系统承诺给进程的内存大小超过了实际可用的内存.一个保守的操作系统不会允许memory overcommit,有多少就分配多少,再申请就没有了,这其实有些浪 ...
- Java 性能优化实战记录(3)--JVM OOM的分析和原因追查
前言: C/C++的程序员渴望Java的自由, Java程序员期许C/C++的约束. 其实那里都是围城, 外面的人想进来, 里面的人想出去. 背景: 作为Java程序员, 除了享受垃圾回收机制带来的便 ...
- 深挖android low memory killer
对于PC来说,内存是至关重要.如果某个程序发生了内存泄漏,那么一般情况下系统就会将其进程Kill掉.Linux中使用一种名称为OOM(Out Of Memory,内存不足)的机制来完成这个任务,该机制 ...
随机推荐
- BGP路由协议详解(完整版)
(免责声明:来源于网络,版权原作者所有,转载仅为了传播.学习交流使用,如需删除请私信联系,严禁其他用途.) END 关注「开源Linux」加星标,提升IT技能 好文章,分享.点赞.在看三连哦️↓↓↓
- 老生常谈系列之Aop--AspectJ
老生常谈系列之Aop--AspectJ 这篇文章的目的是大概讲解AspectJ是什么,所以这个文章会花比较长的篇幅去解释一些概念(这对于日常开发来说没一点卵用,但我就是想写),本文主要参考Aspect ...
- MyCat 使用中问题记录
MyCat问题记录: Unknown charsetIndex:255 异常消息: jvm 1 | 2022-04-27 14:09:13,337 [WARN ][$_NIOREACTOR-13-RW ...
- 使用requests爬取梨视频、bilibili视频、汽车之家,bs4遍历文档树、搜索文档树,css选择器
今日内容概要 使用requests爬取梨视频 requests+bs4爬取汽车之家 bs4遍历文档树 bs4搜索文档树 css选择器 内容详细 1.使用requests爬取梨视频 # 模拟发送http ...
- Java学习笔记-基础语法Ⅹ-进程线程
学习快一个月了,现在学到了黑马Java教程的300集 打印流的特点: 只负责输出数据,不负责读取数据 有自己的特有方法 字节打印流:PrintStream,使用指定的文件名创建新的打印流 import ...
- map计算
map理解 参考1: https://github.com/rafaelpadilla/Object-Detection-Metrics 参考2:https://github.com/rafaelpa ...
- 【ACM程序设计】动态规划 第二篇 LCS&LIS问题
动态规划 P1439 [模板]最长公共子序列 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题目描述 给出 1,2,-,n 的两个排列 P1 和 P2 ,求它们的最长公共子序列. ...
- HTML5续集
H5 input新增属性 1.color 拾色器 2.Email 电子邮件 3.tel 电话 4.datetime-local 本地日期和时间 5.range 范围 6.url 路径,地址 7.sea ...
- Spring Security整合企业微信的扫码登录,企微的API震惊到我了
本文代码: https://gitee.com/felord/spring-security-oauth2-tutorial/tree/wwopen/ 现在很多企业都接入了企业微信,作为私域社群工具, ...
- ExtJS 布局-Anchor 布局(Anchor layout)
更新记录: 2022年5月30日 发布本篇 1.说明 anchor布局类似auto布局从上到下进行堆叠,但不同的是其可以指定每个元素相对于容器大小的比例. 当调整父容器大小,容器根据指定的规则调整所有 ...