【Redis场景4】单机环境下秒杀问题
单机环境下的秒杀问题
全局唯一ID
为什么要使用全局唯一ID:
当用户抢购时,就会生成订单并保存到订单表中,而订单表如果使用数据库自增ID就存在一些问题:
- 受单表数据量的限制
- id的规律性太明显
场景分析一:如果我们的id具有太明显的规则,用户或者说商业对手很容易猜测出来我们的一些敏感信息,比如商城在一天时间内,卖出了多少单,这明显不合适。
场景分析二:随着我们商城规模越来越大,mysql的单表的容量不宜超过500W,数据量过大之后,我们要进行拆库拆表,但拆分表了之后,他们从逻辑上讲他们是同一张表,所以他们的id是不能一样的, 于是乎我们需要保证id的唯一性。
场景分析三:如果全部使用数据库自增长ID,那么多张表都会出现相同的ID,不满足业务需求。
在分布式系统下全局唯一ID需要满足的特点:
- 唯一性
- 递增性
- 安全性
- 高可用(服务稳定)
- 高性能(生成速度够快)
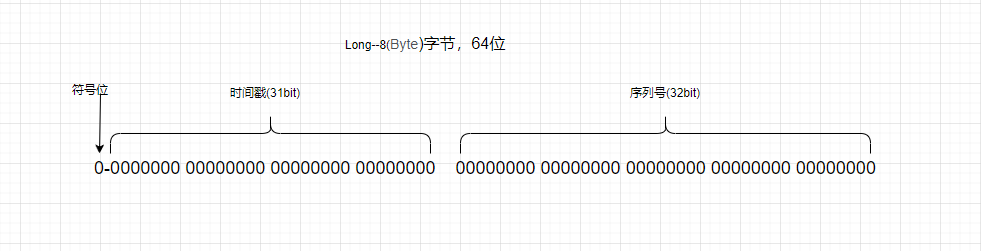
为了提高数据库性能,这里采用Java中的数值类型(Long--8(Byte)字节,64位),
- ID的组成部分:符号位:1bit,永远为0
- 时间戳:31bit,以秒为单位,可以使用69年
- 序列号:32bit,秒内的计数器,支持每秒产生2^32个不同ID
类雪花算法开发
我们的生成策略是基于redis的自增长,及序列号部分,在实现的时候需要传入不同的前缀(即不同业务不同序列号)
我们开始实现时间戳位数,先设置一个基准值,即某一时间的秒数,使用的时候用当前时间秒数-基准时间=所得秒数即时间戳;
基准值计算:这里我是用2023/1/1 0:0:0;秒数为:1672531200
public static void main(String[] args) {LocalDateTime time = LocalDateTime.of(2023, 1, 1, 0, 0, 0);//设置时区long l = time.toEpochSecond(ZoneOffset.UTC);System.out.println(l);}
开始生成时间戳:获得当前时间的秒数-基准值(BEGIN_TIMESTAMP=1672531200)
LocalDateTime dateTime = LocalDateTime.now();//秒数设置时区long nowSecond = dateTime.toEpochSecond(ZoneOffset.UTC);long timestamp = nowSecond - BEGIN_TIMESTAMP;
然后生成序列号,采用Redis的自增操作实现。keyPrefix业务Key(传入的)
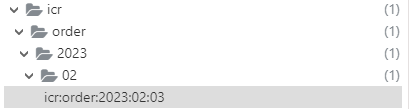
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix);
这一行代码的使用问题是,同一个业务使用的同一个key,但是redis的自增上上限为2^64,总有时候会超过32位,所以最好是让其同一业务也要有不同的key值,这里我们可以加上当前时间。
//获取当日日期,精确到天String date = dateTime.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));//自增长上限2^64long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
这样做的好处是:
- 在redis中缓存是分层的,方便查看,也方便统计每天、每月的订单量或者其他数据等
- 不会超过Redis的自增长的值,安全性提高
最后将时间戳和序列号进行拼接即可,位运算。COUNT_BITS=32
timestamp << COUNT_BITS | count;
首先将时间戳左移32位,低处补零,然后进行或运算(遇1得1),这样实现整个的全局唯一ID。
测试
在同一个业务中使用全局唯一ID生成。
/*** 测试全局唯一ID生成器* @throws InterruptedException*/@Testpublic void testIdWorker() throws InterruptedException {CountDownLatch countDownLatch = new CountDownLatch(300);ExecutorService executorService = Executors.newFixedThreadPool(300);Runnable task = ()->{for (int i = 0; i < 100; i++) {long id = redisIdWorker.nextId("order");System.out.println("id:"+id);}//计数-1countDownLatch.countDown();};long begin = System.currentTimeMillis();for (int i = 0; i < 300; i++) {executorService.submit(task);}//等待子线程结束countDownLatch.await();long endTime = System.currentTimeMillis();System.out.println("time= "+(endTime-begin));}
time= 2608ms=2.68s,生成数量:30000
取两个相近的十进制转为二进制对比:
id : 148285184708444304
0010 0000 1110 1101 0000 1001 0111 0000 0000 0000 0000 0000 0000 1001 0000
id : 148285184708444305
0010 0000 1110 1101 0000 1001 0111 0000 0000 0000 0000 0000 0000 1001 0001
短码生成策略
仅支持很小的调用量,用于生成活动配置类编号,保证全局唯一
import java.util.Calendar;import java.util.Random;/*** @author xbhog* @describe:短码生成策略,仅支持很小的调用量,用于生成活动配置类编号,保证全局唯一* @date 2022/9/18*/@Slf4j@Componentpublic class ShortCode implements IIdGenerator {@Overridepublic synchronized long nextId() {Calendar calendar = Calendar.getInstance();int year = calendar.get(Calendar.YEAR);int week = calendar.get(Calendar.WEEK_OF_YEAR);int day = calendar.get(Calendar.DAY_OF_WEEK);int hour = calendar.get(Calendar.HOUR_OF_DAY);log.info("年:{},周:{},日:{},小时:{}",year, week,day,hour);//打乱顺序:2020年为准 + 小时 + 周期 + 日 + 三位随机数StringBuilder idStr = new StringBuilder();idStr.append(year-2020);idStr.append(hour);idStr.append(String.format("%02d",week));idStr.append(day);idStr.append(String.format("%03d",new Random().nextInt(1000)));log.info("查看拼接之后的值:{}",idStr);return Long.parseLong(idStr.toString());}public static void main(String[] args) {long l = new ShortCode().nextId();System.out.println(l);}}
日志记录:
14:40:22.336 [main] INFO ShortCode - 年:2023,周:5,日:7,小时:1414:40:22.341 [main] INFO ShortCode - 查看拼接之后的值:314057012314057012
秒杀下单功能及并发测试
完整代码GitHub:https://github.com/xbhog/hm-dianping/tree/20230130-xbhog-redisSpike
秒杀条件分析:
- 秒杀是否开始或结束,如果尚未开始或已经结束则无法下单
- 库存是否充足,不足则无法下单
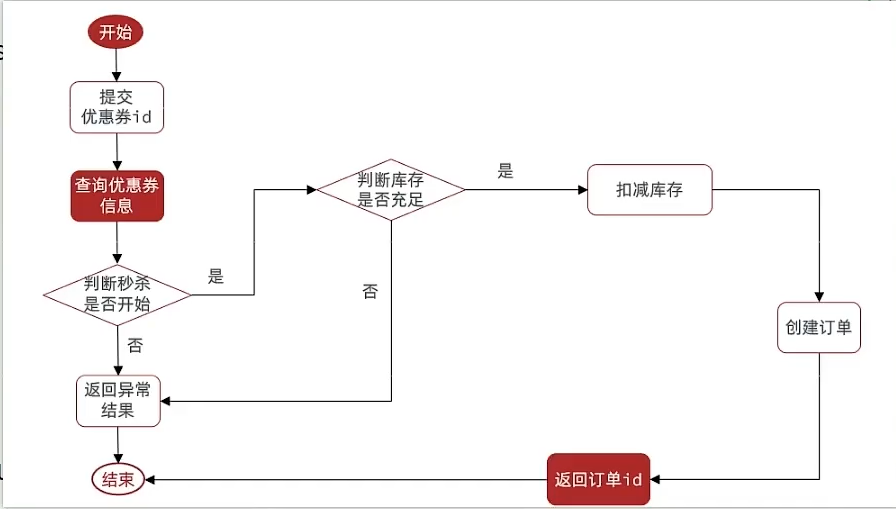
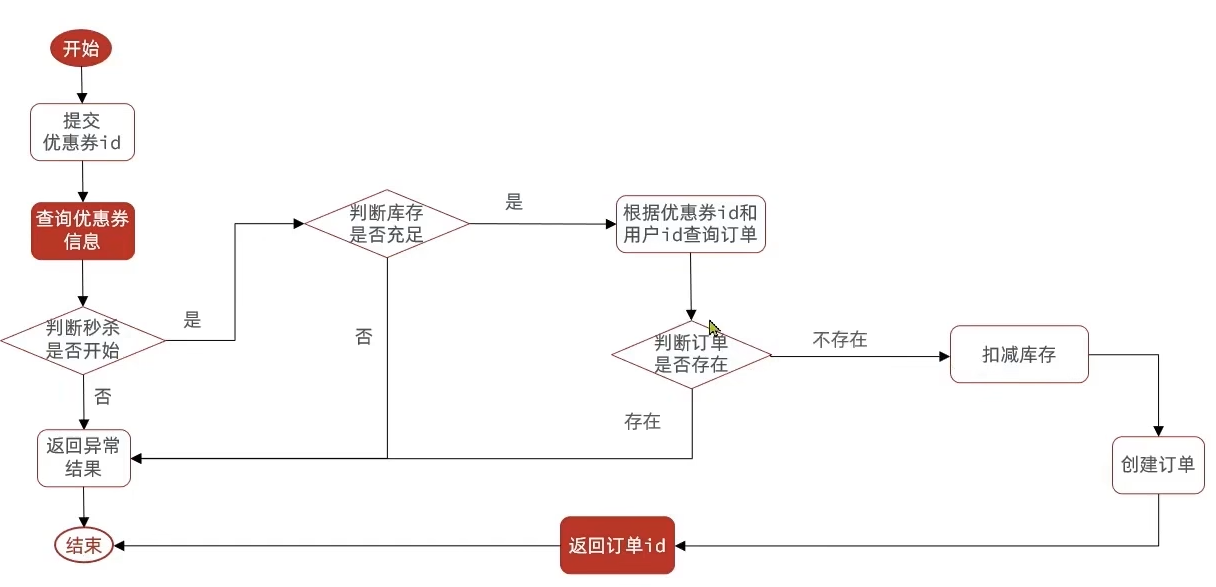
业务流程图:
开发流程:
优惠卷订单服务处理流程
查询优惠卷
判断用户是否在秒杀时间段内
判断是否库存充足
- 不足:返回异常信息
- 充足:执行步骤4
创建优惠卷订单
落库
返回订单ID
流程比较简单,这里需要注意的点是在库存扣减这部分
@Overridepublic Result seckillVoucher(Long voucherId) {// 1.查询优惠券// 2.判断秒杀是否开始// 3.判断秒杀是否已经结束// 4.判断库存是否充足if (voucher.getStock() < 1) {// 库存不足return Result.fail("库存不足!");}//5,扣减库//update tb_seckill_voucher set stock=stock -1 where voucher_id = #{voucherId}boolean success = seckillVoucherMapper.updateDateByVoucherId(voucherId);if (!success) {//扣减库存return Result.fail("库存不足!");}//6.创建订单// 6.1.全局唯一ID生成:订单idlong orderId = redisIdWorker.nextId("order");voucherOrder.setId(orderId);// 6.2.用户idLong userId = UserHolder.getUser().getId();voucherOrder.setUserId(userId);// 6.3.代金券idvoucherOrder.setVoucherId(voucherId);save(voucherOrder);return Result.ok(orderId);}
jmeter进行测试:
条件:线程200,循环一次,查看汇总报告可以看出:
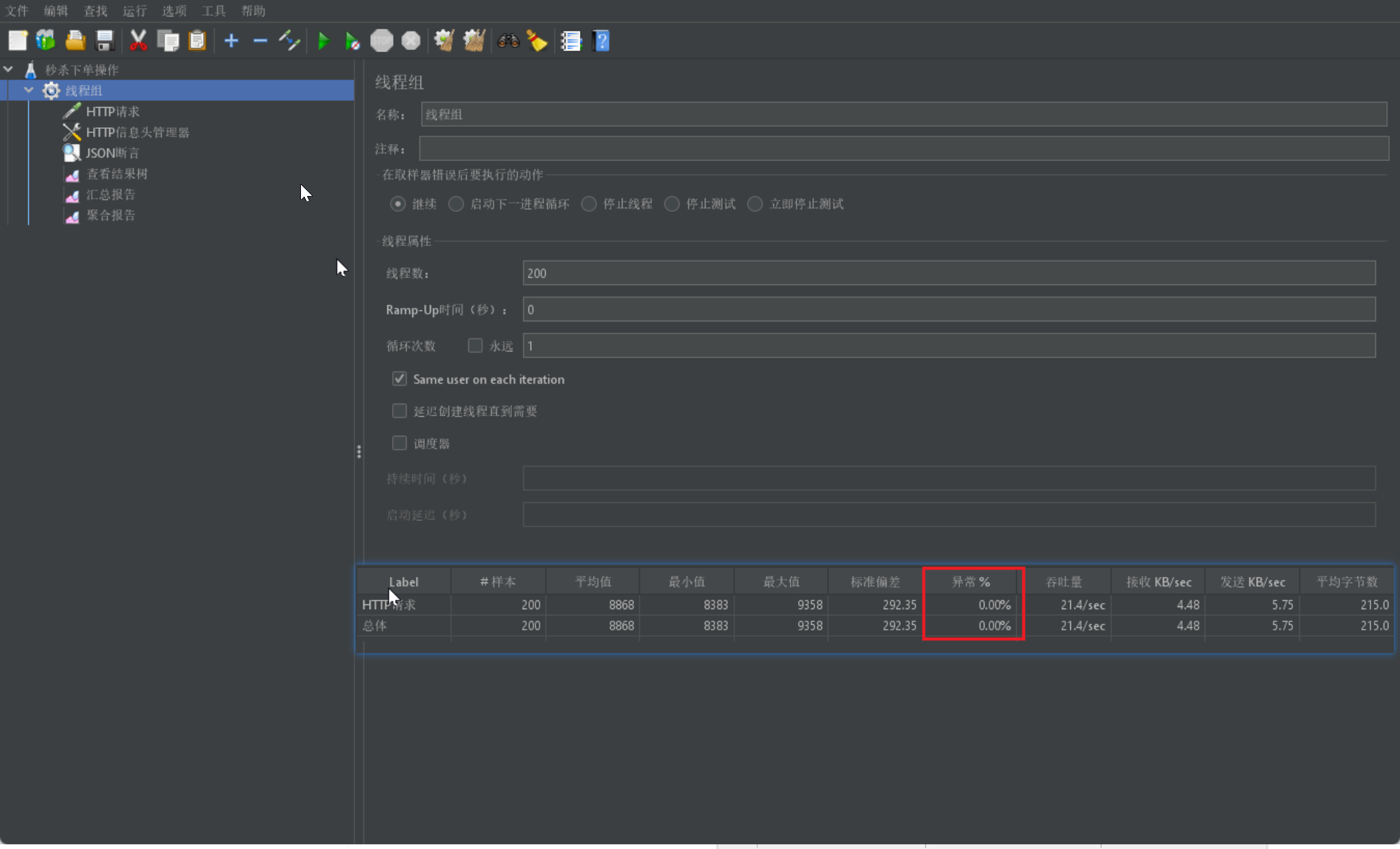
预期结果应该为异常是50%,但是这里显示为0%,查看数据库可以看出生成订单200个,库存为-100;
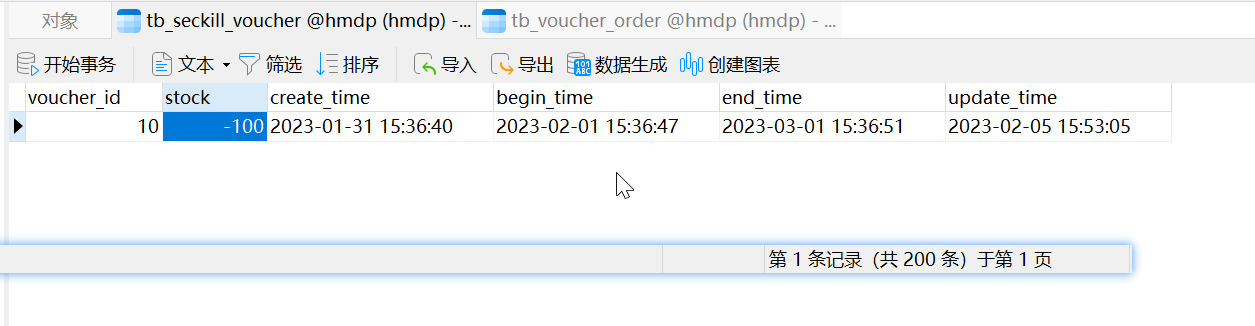
原因分析:
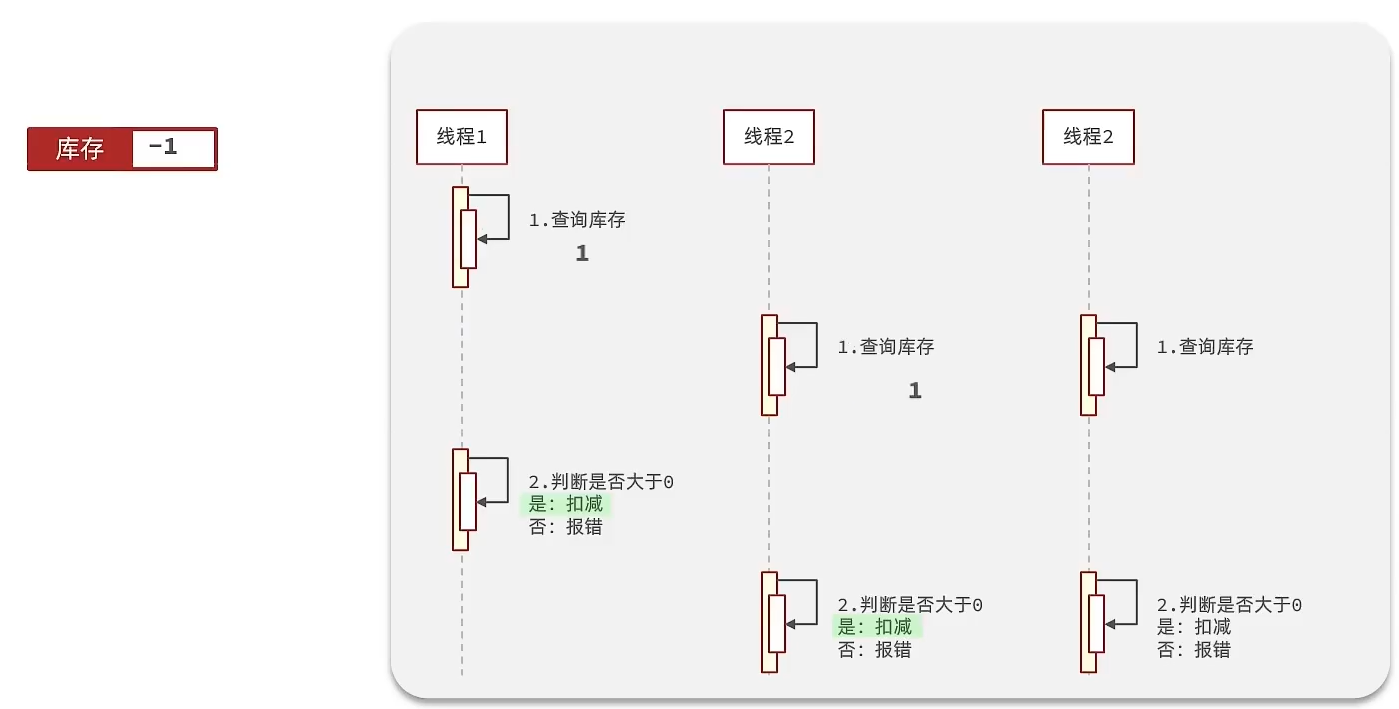
假设线程1过来查询库存,判断出来库存大于1,正准备去扣减库存,但是还没有来得及去扣减,此时线程2过来,线程2也去查询库存,发现这个数量一定也大于1,那么这两个线程都会去扣减库存,最终多个线程相当于一起去扣减库存,由此就会出现库存的超卖问题。
锁解决超卖问题
完整代码GitHub:https://github.com/xbhog/hm-dianping/tree/20230130-xbhog-redisSpike
解决方式
- 悲观锁:可以实现对于数据的串行化执行,比如syn,和lock都是悲观锁的代表,同时,悲观锁中又可以再细分为公平锁,非公平锁,可重入锁,等等
- 乐观锁:会有一个版本号,每次操作数据会对版本号+1,再提交回数据时,会去校验是否比之前的版本大1 ,如果大1 ,则进行操作成功,这套机制的核心逻辑在于,如果在操作过程中,版本号只比原来大1 ,那么就意味着操作过程中没有人对他进行过修改,他的操作就是安全的,如果不大1,则数据被修改过,当然乐观锁还有一些变种的处理方式比如cas
采用乐观锁解决超卖问题:
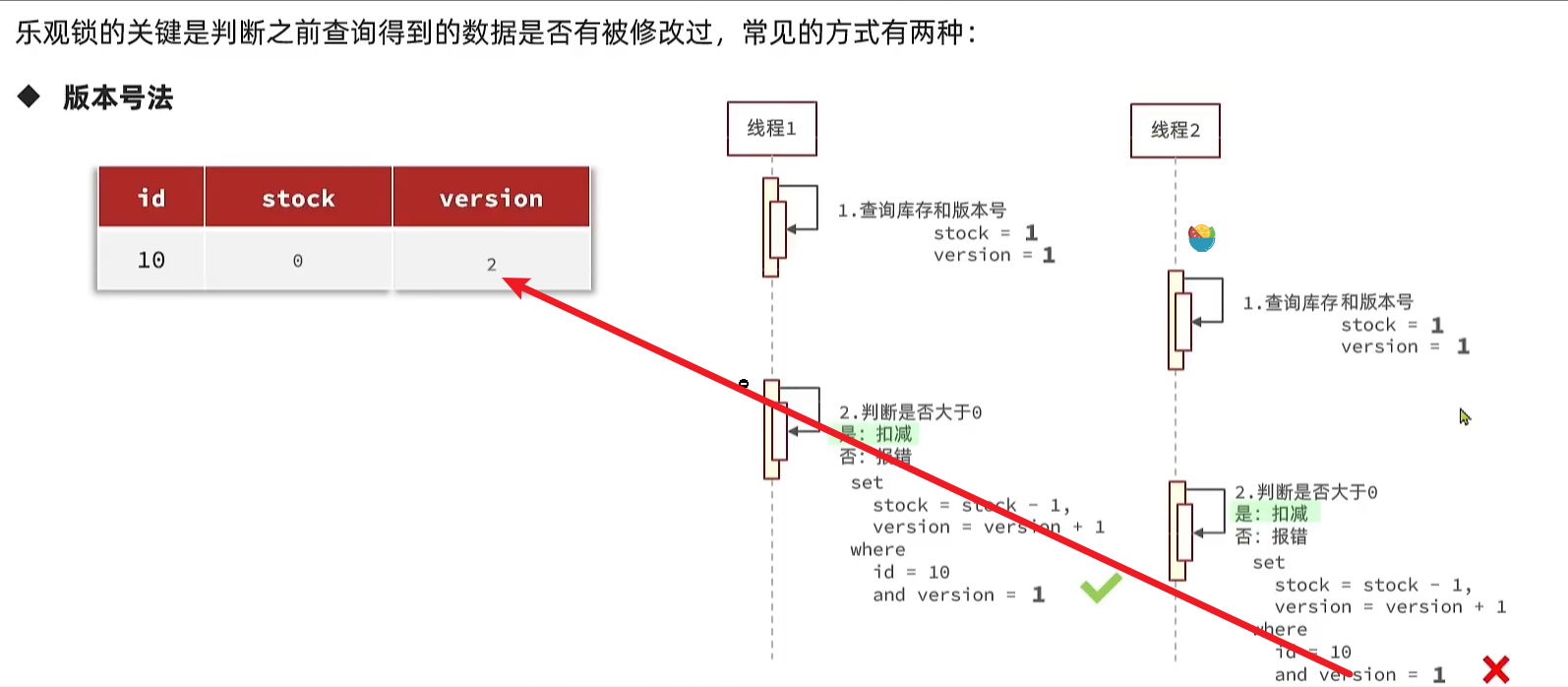
在操作时,对版本号进行+1 操作,然后要求version 如果是1 的情况下,才能操作,那么第一个线程在操作后,数据库中的version变成了2,但是他自己满足version=1 ,所以没有问题,此时线程2执行,线程2 最后也需要加上条件version =1 ,但是现在由于线程1已经操作过了,所以线程2,操作时就不满足version=1 的条件了,所以线程2无法执行成功。
修改上述代码有两种修改方式:
- 只要我扣减库存时的库存和之前我查询到的库存是一样的,就意味着没有人在中间修改过库存,那么此时就是安全的。
- 判断条件为库存数stock>0即可(解决问题)
测试第一种方式:100线程并发;数据库订单数为1,库存99(预期时库存0)。
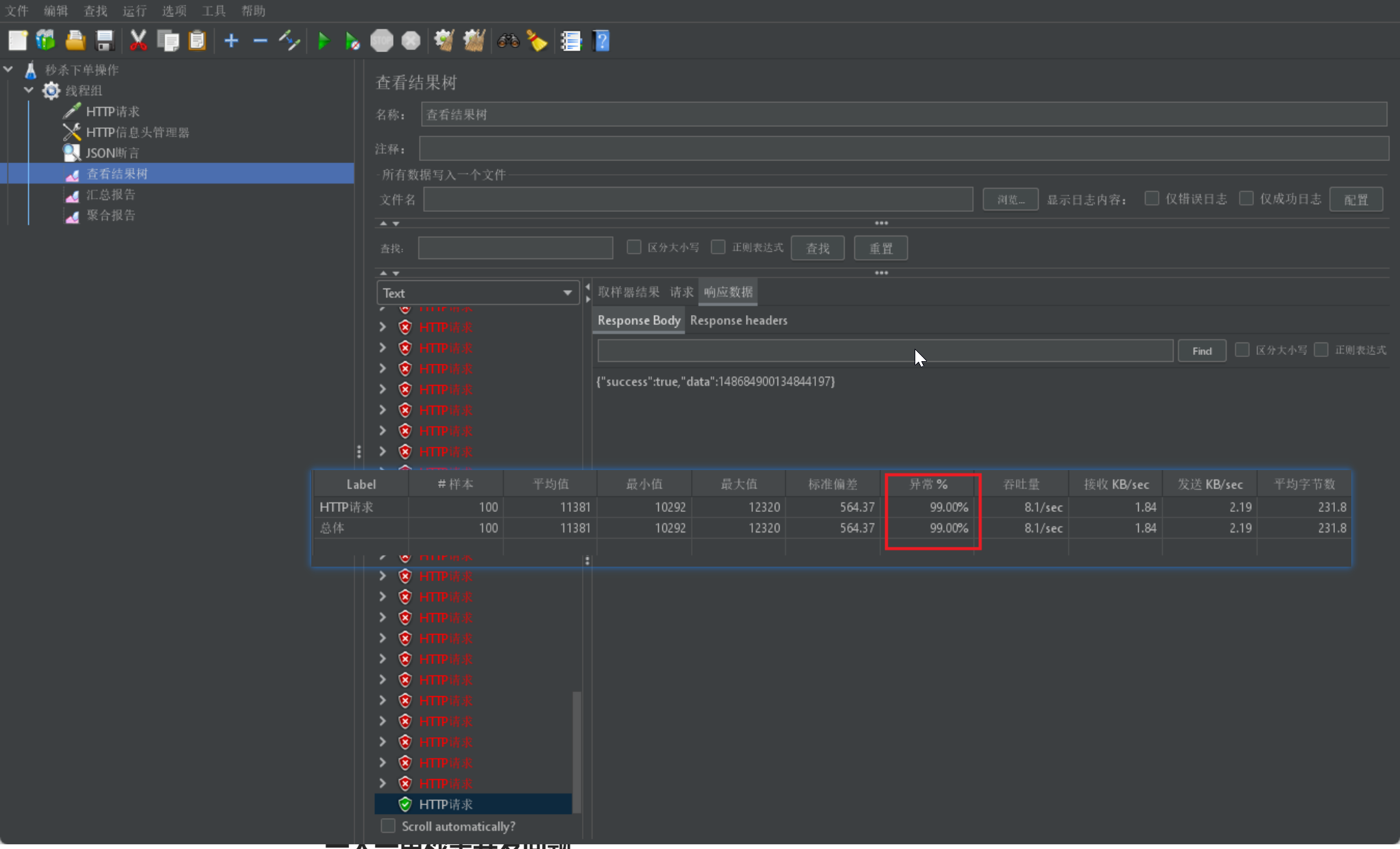
通过测试发现会有99%失败的情况,跟我们预计的0%失败率来说相差很远,失败的原因在于:在使用乐观锁过程中假设100个线程同时都拿到了100的库存,然后大家一起去进行扣减,但是100个人中只有1个人能扣减成功,其他的人在处理时,他们在扣减时,库存已经被修改过了,所以此时其他线程都会失败。
解决方式就是修改库存数条件为stock>0
一人一单秒杀并发问题
完整代码GitHub:https://github.com/xbhog/hm-dianping/tree/20230130-xbhog-redisSpike
上述秒杀订单有一个问题,一个用户可以秒杀多次;优惠卷是为了引流,但是目前的情况是,一个人可以无限制的抢这个优惠卷,所以我们应当增加一层逻辑,让一个用户只能下一个单,而不是让一个用户下多个单。
相关流程图如下:
在原来的代码上增加用户判断:
// 5.一人一单逻辑// 5.1.用户idLong userId = UserHolder.getUser().getId();int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();// 5.2.判断是否存在if (count > 0) {// 用户已经购买过了return Result.fail("用户已经购买过一次!");}
存在问题:现在的问题还是和之前一样,并发过来,查询数据库,都不存在订单,所以我们还是需要加锁,但是乐观锁比较适合更新数据,而现在是插入数据,所以我们需要使用悲观锁操作
当前注意点:
- 线程安全实现
- 锁的范围(颗粒度)
- 事务问题
处理线程安全问题,将对数据库更新和插入的操作单独作为一个方法进行封装:
@Transactionalpublic synchronized Result createVoucherOrder(Long voucherId) {Long userId = UserHolder.getUser().getId();// 5.1.查询订单int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();// 5.2.判断是否存在if (count > 0) {// 用户已经购买过了return Result.fail("用户已经购买过一次!");}// 6.扣减库存//开始扣减库存(通过乐观锁--->对应数据库中行锁实现)boolean success = seckillVoucherMapper.updateDateByVoucherId(voucherId);if (!success) {// 扣减失败return Result.fail("库存不足!");}// 7.创建订单VoucherOrder voucherOrder = new VoucherOrder();// 7.1.订单idlong orderId = redisIdWorker.nextId("order");voucherOrder.setId(orderId);// 7.2.用户idvoucherOrder.setUserId(userId);// 7.3.代金券idvoucherOrder.setVoucherId(voucherId);save(voucherOrder);// 7.返回订单idreturn Result.ok(orderId);}
当前操作虽然可以解决线程安全,但是效率太低,每个进来的线程都要锁一下,这里我们可以尝试以用户ID来作为锁条件,但是使用userId.toString(),是重新new了一个对象,这就造成每个线程进来都不一样,锁不住。
public static String toString(long i) {if (i == Long.MIN_VALUE)return "-9223372036854775808";int size = (i < 0) ? stringSize(-i) + 1 : stringSize(i);char[] buf = new char[size];getChars(i, size, buf);return new String(buf, true);}
这里我们使用userId.toString().intern()从常量池中查找数据。解决锁对象不一致的问题。
Long userId = UserHolder.getUser().getId();synchronized(userId.toString().intern()){.......}@Transactionalpublic Result createVoucherOrder(Long voucherId) {Long userId = UserHolder.getUser().getId();synchronized(userId.toString().intern()){log.info("开始进行用户秒杀活动:{}",userId);//一人一单逻辑Integer count = voucherOrderService.query().eq("voucher_id", voucherId).eq("user_id", userId).count();if(count > 0){return Result.fail("该用户已参加活动。");}//开始扣减库存(通过乐观锁--->对应数据库中行锁实现)boolean success = seckillVoucherMapper.updateDateByVoucherId(voucherId);if(!success){return Result.fail("库存不足,正在补充!");}//创建订单VoucherOrder voucherOrder = new VoucherOrder();long orderId = redisIdWorker.nextId("order");voucherOrder.setId(orderId);voucherOrder.setUserId(userId);voucherOrder.setVoucherId(voucherId);voucherOrderService.save(voucherOrder);return Result.ok(orderId);}//这里事务还没有提交事务,但是锁已经释放了。}
但是! 以上代码还是存在问题;
问题的原因在于当前方法被spring的事务控制,如果你在方法内部加锁,可能会导致当前方法事务还没有提交,但是锁已经释放也会导致问题.
解决:把用户ID放入外部.将当前方法整体包裹起来,确保事务不会出现问题
@Slf4j@Servicepublic class VoucherOrderServiceImpl extends ServiceImpl<VoucherOrderMapper, VoucherOrder> implements IVoucherOrderService {@Resourceprivate ISeckillVoucherService seckillVoucherService;@Resourceprivate SeckillVoucherMapper seckillVoucherMapper;@Resourceprivate IVoucherOrderService voucherOrderService;@Resourceprivate RedisIdWorker redisIdWorker;@Overridepublic Result seckillVoucher(Long voucherId) {//查询优惠卷库存信息SeckillVoucher voucher = seckillVoucherService.getById(voucherId);log.info("查询秒杀优惠卷:{}",voucher);//判断秒杀是否开始:开始时间,结束时间if(voucher.getBeginTime().isAfter(LocalDateTime.now())){return Result.fail("活动暂未开始,敬请期待!");}if(voucher.getEndTime().isBefore(LocalDateTime.now())){return Result.fail("活动已结束,请关注下次活动!");}//判断库存是否充足if(voucher.getStock() < 1){return Result.fail("库存不足,正在补充!");}Long userId = UserHolder.getUser().getId();//这一步有问题synchronized (userId.toString().intern()){return this.createVoucherOrder(voucherId);}}@Override@Transactionalpublic Result createVoucherOrder(Long voucherId) {Long userId = UserHolder.getUser().getId();log.info("开始进行用户秒杀活动:{}",userId);//一人一单逻辑Integer count = voucherOrderService.query().eq("voucher_id", voucherId).eq("user_id", userId).count();if(count > 0){return Result.fail("该用户已参加活动。");}//开始扣减库存(通过乐观锁--->对应数据库中行锁实现)boolean success = seckillVoucherMapper.updateDateByVoucherId(voucherId);if(!success){return Result.fail("库存不足,正在补充!");}//创建订单VoucherOrder voucherOrder = new VoucherOrder();long orderId = redisIdWorker.nextId("order");voucherOrder.setId(orderId);voucherOrder.setUserId(userId);voucherOrder.setVoucherId(voucherId);voucherOrderService.save(voucherOrder);return Result.ok(orderId);}}
但是但是!还是有问题。
因为我们调用的方法,其实是this.的方式调用的,事务想要生效,还得利用代理来生效,所以这个地方,我们需要获得原始的事务对象, 来操作事务。
代理使用需要进行配置和包的引入:
<dependency><groupId>org.aspectj</groupId><artifactId>aspectjweaver</artifactId></dependency>
在启动类中加入:@EnableAspectJAutoProxy(exposeProxy = true);暴露代理对象,不设置无法获取代理对象;
在调用时,通过AopContext来获取当前代理对象。
synchronized (userId.toString().intern()){//获取原始事务代理对象IVoucherOrderService iVoucherOrderService = (IVoucherOrderService) AopContext.currentProxy();return iVoucherOrderService.createVoucherOrder(voucherId);}
Jmeter测试条件:100线程,循环1次,查看结果树和汇总报告可以看出;
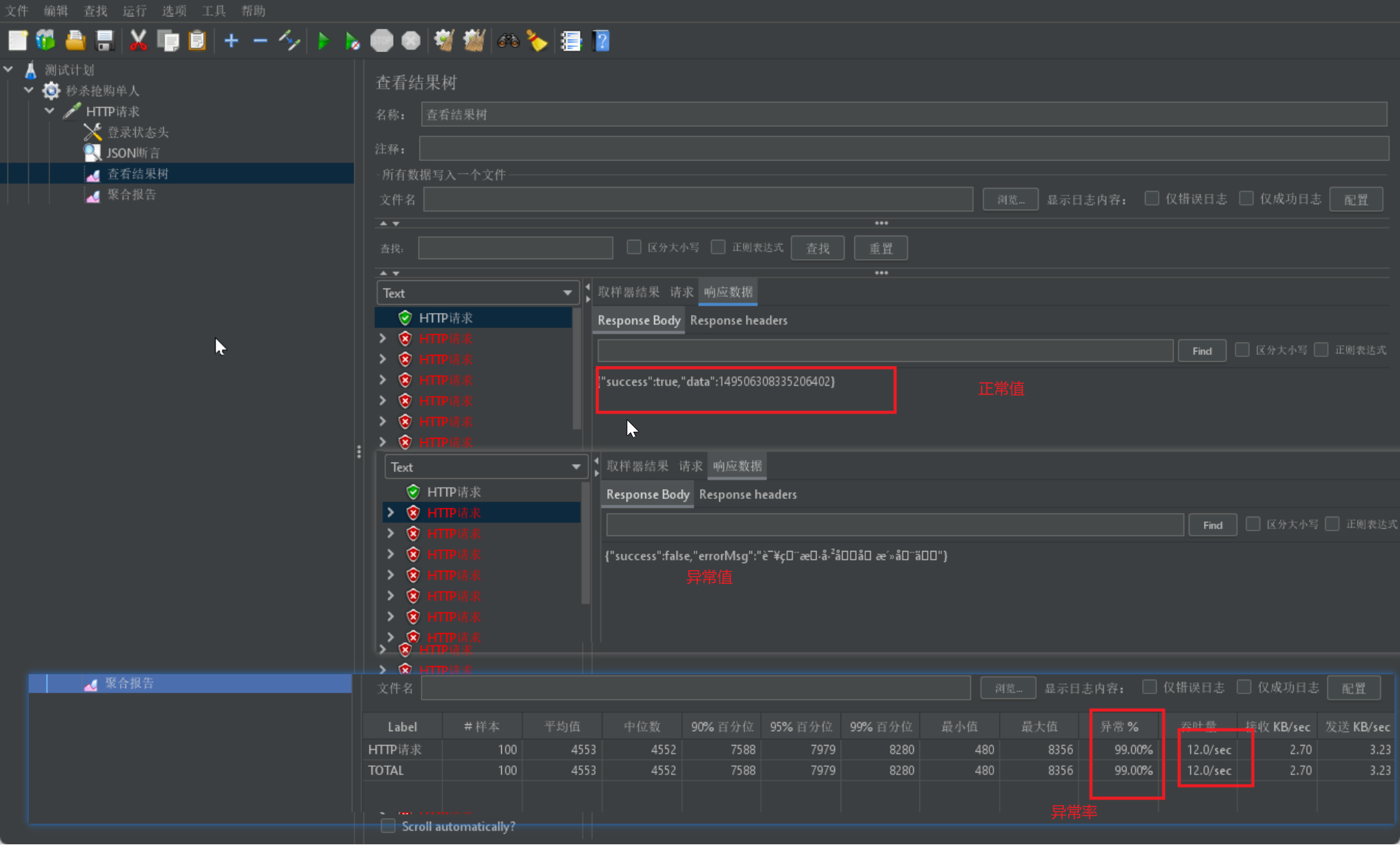
查看数据库,一个用户秒杀成功一个订单,对比异常率,满足我们的需求。
【Redis场景4】单机环境下秒杀问题的更多相关文章
- BizTalk开发系列(三) 单机环境下的BizTalk Server 2006 R2安装
大部分的开发环境都是在单机环境下进行的,今天整理了一下BizTalk Server 2006 R2在单机环境下的安装步骤. 1. 软件需求 在独立服务器中完整安装BizTalk Server 2006 ...
- 在Windows中单机环境下创建RabbitMQ集群
本文根据:http://www.360doc.com/content/15/0312/17/20874412_454622619.shtml整理而来 RabbitMQ具有很好的消息传递性能,同时又是开 ...
- Linux单机环境下HDFS伪分布式集群安装操作步骤v1.0
公司平台的分布式文件系统基于Hadoop HDFS技术构建,为开发人员学习及后续项目中Hadoop HDFS相关操作提供技术参考特编写此文档.本文档描述了Linux单机环境下Hadoop HDFS伪分 ...
- MySQL数据库管理(二)单机环境下MySQL Cluster的安装
上文<MySQL数据库管理(一)MySQL Cluster集群简单介绍>对MySQL Cluster集群做了简要介绍.本文将教大家一步步搭建单机环境下的MySQL数据库集群. 一.单机环境 ...
- windows单机环境下配置tomcat集群
场景:我们在平常联系中,需要涉及到tomcat中,但是电脑不够怎么办,肯定是在自己的电脑上模拟集群,就是装多个tomcat,这时候需要稍微配置下.如果是多个服务器,那不用配置,直接怼!!! 这里介绍的 ...
- 科谱,如何单机环境下合理的备份mssql2008数据库
前言: 终于盼来了公司的自用服务器:1U.至强CPU 1.8G 4核.16G内存.500G硬盘 X 2 (RAID1);装了64位win2008,和64位mssql2008.仔细把玩了一天把新老业务系 ...
- 高并发关于微博、秒杀抢单等应用场景在PHP环境下结合Redis队列延迟入库
第一步:创建模拟数据表. CREATE TABLE `test_table` ( `id` int(11) NOT NULL AUTO_INCREMENT, `uid` int(11) NOT NUL ...
- 初探Redis+Net在Windows环境下的使用
Redis官网地址:https://redis.io/:Redis官方暂时不支持Windows环境,但是MicroSoft Open Tech group开发了一个Windows平台下运行的版本. R ...
- spark单机环境下运行一些解决问题
ERROR1.hadoop依赖 [ERROR] - Failed to locate the winutils binary in the hadoop binary path java.io.I ...
- 在tomcat集群环境下redis实现分布式锁
上篇介绍了redis在集群环境下如何解决session共享的问题.今天来讲一下如何解决分布式锁的问题 什么是分布式锁? 分布式锁就是在多个服务器中,都来争夺某一资源.这时候我们肯定需要一把锁是不是 , ...
随机推荐
- python 的time、datetime模块
python 时间模块 import datetime res = datetime.datetime.now() print(res) # 2022-08-07 16:47:07.120459 ...
- 达梦-DBLINK数据库链接
aliases: [达梦 DBlink] tags: [数据库,DM,Blog] link: date: 2022-09-06 说明:DM-Oracle指的是在DM中创建链接至Oracle的Dblin ...
- perl中sprintf函数的用法
对于某些字符串,需要输入为特定的格式,通过sprintf可以很方便的完成,不需要专门进行其他处理. 转载 perl中sprintf函数的使用方法.
- 【云原生 · DevOps】DevOps 解决方案
DevOps 解决方案 1.1 容器化 CI/CD 1.2 容器化流水线 1.3 深度集成 Jenkins 1.4 灰度发布 1.5 制品库设计 1.6 DevOps 安全 1.6.1 CI/CD 安 ...
- 把Mybatis Generator生成的代码加上想要的注释
作者:王建乐 1 前言 在日常开发工作中,我们经常用Mybatis Generator根据表结构生成对应的实体类和Mapper文件.但是Mybatis Generator默认生成的代码中,注释并不是我 ...
- ES文件浏览器局域网传输文件分析
软件下载链接 1.前言 我之前从手机上传输到电脑上一些apk进行分析,都是使用es文件浏览器这款软件获取 app,传输方面使用QQ,这样很麻烦,走外网流量暂且不提,总是感觉浪费掉了局域网这个环境.简单 ...
- oracle 分析函数——ration_to_report 求占有率(百分比)
oracle 的分析函数有很多,但是这个函数总是会忘记,我想通过这种方式能让自己记起来,不至于下次还要百度. 创表.表数据(平时练手的表): prompt PL/SQL Developer impor ...
- day16 异常处理生成器
day16 异常处理生成器 今日内容概要 异常处理 异常处理实战应用 生成器对象 生成器对象实现range方法 生成器表达式 今日内容详细 一.异常处理 1.异常常见类型 SyntaxError语法错 ...
- 在 win11 下搭建并使用 ubuntu 子系统(同时测试 win10)——(附带深度学习环境搭建)
对于一个深度学习从事者来说,Windows训练模型有着诸多不便,还好现在Windows的Ubuntu子系统逐渐完善,近期由于工作需求,配置了Windows的工作站,为了方便起见,搭建了Ubuntu子系 ...
- PostgreSQL常用操作合辑:时间日期、系统函数、正则表达式、库表导入导出、元数据查询、自定义函数、常用案例
〇.参考地址 1.pg官方文档 http://www.postgres.cn/docs/9.6/index.html 2.腾讯云仓pg文档 https://cloud.tencent.com/docu ...