在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs
我们很高兴正式发布 trl 与 peft 的集成,使任何人都可以更轻松地使用强化学习进行大型语言模型 (LLM) 微调!在这篇文章中,我们解释了为什么这是现有微调方法的有竞争力的替代方案。
请注意, peft 是一种通用工具,可以应用于许多 ML 用例,但它对 RLHF 特别有趣,因为这种方法特别需要内存!
如果你想直接深入研究代码,请直接在 TRL 的文档页面 直接查看示例脚本。
介绍
LLMs & RLHF
LLM 结合 RLHF (人类反馈强化学习) 似乎是构建非常强大的 AI 系统 (例如 ChatGPT) 的下一个首选方法。
使用 RLHF 训练语言模型通常包括以下三个步骤:
- 在特定领域或指令和人类示范语料库上微调预训练的 LLM;
- 收集人类标注的数据集,训练一个奖励模型;
- 使用 RL (例如 PPO),用此数据集和奖励模型进一步微调步骤 1 中的 LLM。
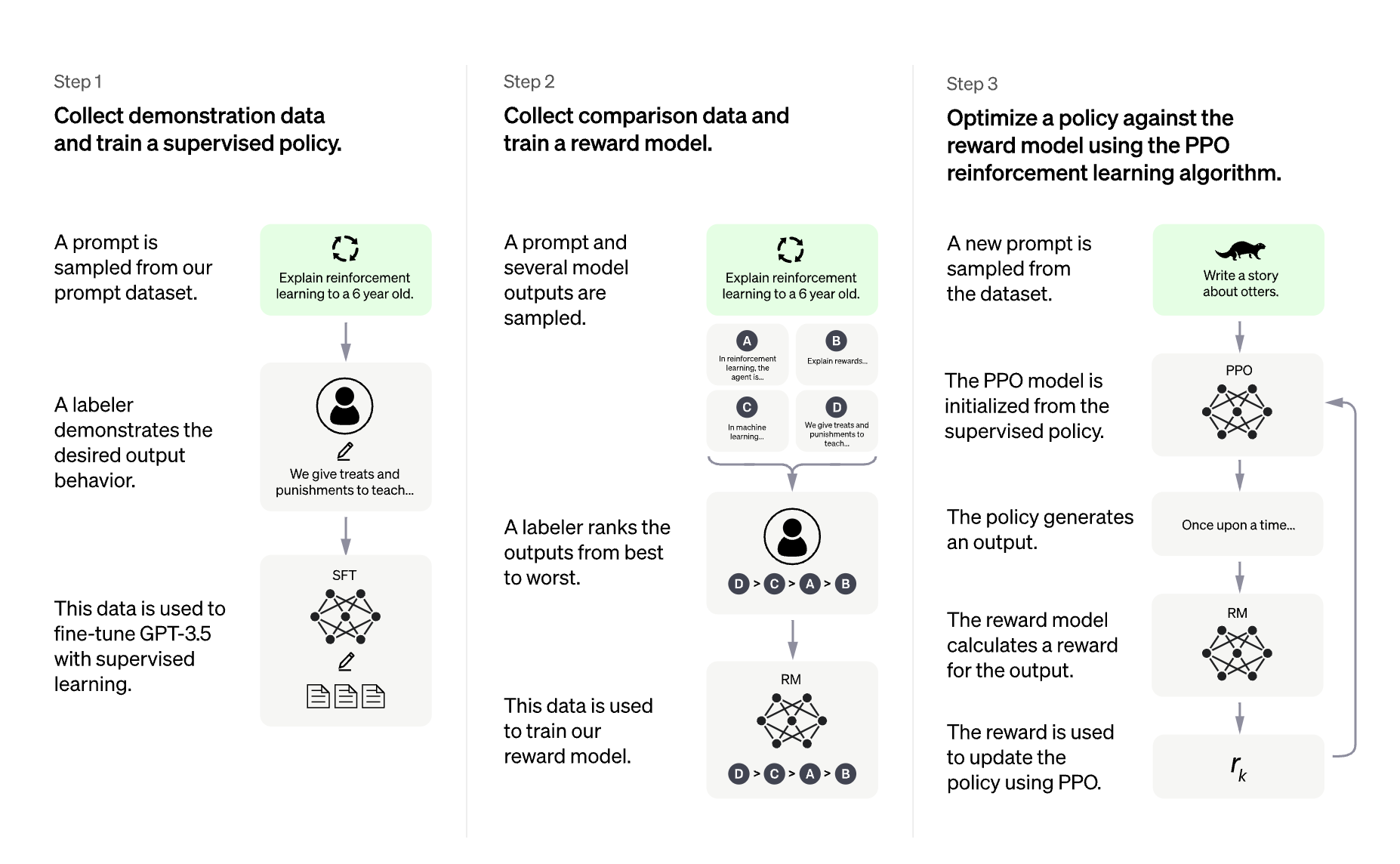
ChatGPT 的训练协议概述,从数据收集到 RL 部分。 资料来源: OpenAI 的 ChatGPT 博文
基础 LLM 的选择在这里是至关重要的。在撰写本文时,可以“开箱即用”地用于许多任务的“最佳”开源 LLM 是指令微调 LLMs。著名的模型有: BLOOMZ Flan-T5、Flan-UL2 和 OPT-IML。这些模型的缺点是它们的尺寸。要获得一个像样的模型,你至少需要玩 10B+ 级别的模型,在全精度情况下这将需要高达 40GB GPU 内存,只是为了将模型装在单个 GPU 设备上而不进行任何训练!
什么是 TRL?
trl 库的目的是使 RL 的步骤更容易和灵活,让每个人可以在他们自己的数据集和训练设置上用 RL 微调 LM。在许多其他应用程序中,你可以使用此算法微调模型以生成 正面电影评论、进行 受控生成 或 降低模型的毒性。
使用 trl 你可以在分布式管理器或者单个设备上运行最受欢迎的深度强化学习算法之一: PPO。我们利用 Hugging Face 生态系统中的 accelerate 来实现这一点,这样任何用户都可以将实验扩大到一个有趣的规模。
使用 RL 微调语言模型大致遵循下面详述的协议。这需要有 2 个原始模型的副本; 为避免活跃模型与其原始行为/分布偏离太多,你需要在每个优化步骤中计算参考模型的 logits 。这对优化过程增加了硬约束,因为你始终需要每个 GPU 设备至少有两个模型副本。如果模型的尺寸变大,在单个 GPU 上安装设置会变得越来越棘手。
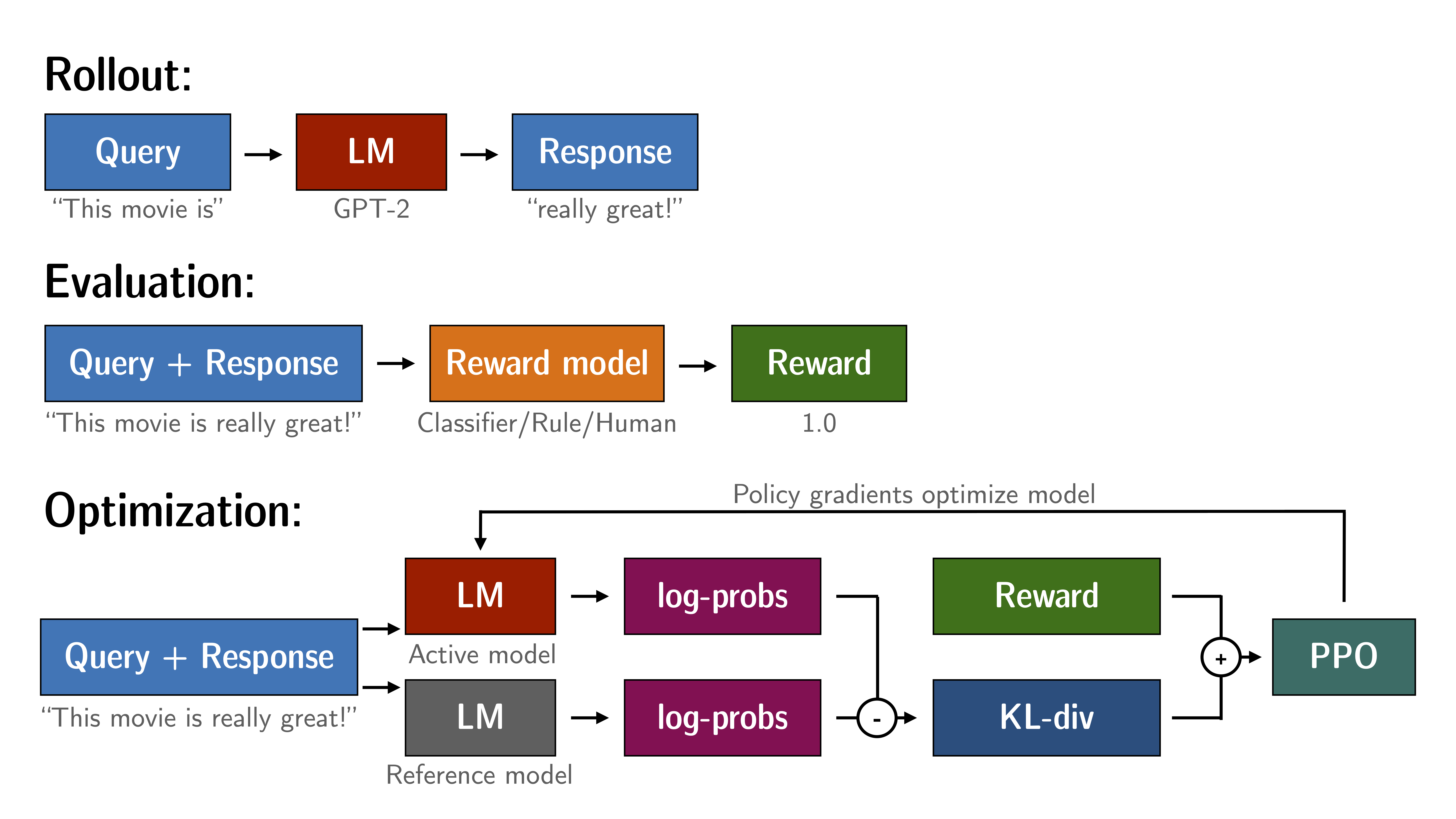
TRL 中 PPO 训练设置概述
在 trl 中,你还可以在参考模型和活跃模型之间使用共享层以避免整个副本。 模型解毒示例中展示了此功能的具体示例。
大规模训练
大规模训练是具有挑战性的。第一个挑战是在可用的 GPU 设备上拟合模型,及其优化器状态。 单个参数占用的 GPU 内存量取决于其“精度”(或更具体地说是 dtype)。 最常见的 dtype 是 float32 (32 位) 、 float16 和 bfloat16 (16 位)。 最近,“奇异的”精度支持开箱即用的训练和推理 (具有特定条件和约束),例如 int8 (8 位)。 简而言之,要在 GPU 设备上加载一个模型,每十亿个参数在 float32 精度上需要 4GB,在 float16 上需要 2GB,在 int8 上需要 1GB。 如果你想了解关于这个话题的更多信息,请查看这篇研究深入的文章: https://huggingface.co/blog/hf-bitsandbytes-integration。
如果您使用 AdamW 优化器,每个参数需要 8 个字节 (例如,如果您的模型有 1B 个参数,则模型的完整 AdamW 优化器将需要 8GB GPU 内存 来源)。
许多技术已经被采用以应对大规模训练上的挑战。最熟悉的范式是管道并行、张量并行和数据并行。
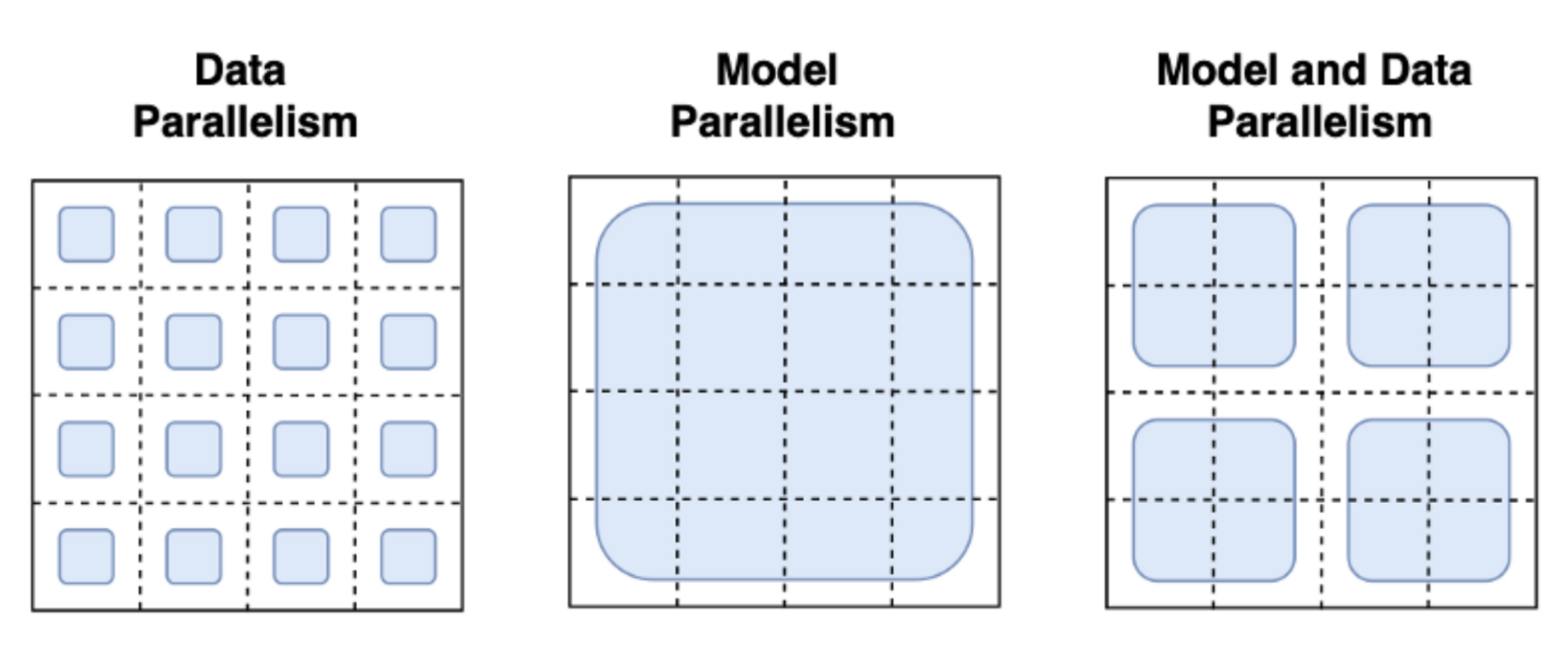
图片来自 这篇博文
通过数据并行性,同一模型并行托管在多台机器上,并且每个实例都被提供不同的数据批次。 这是最直接的并行策略,本质上是复制单 GPU 的情况,并且已经被 trl 支持。 使用管道并行和张量并行,模型本身分布在机器上: 在管道并行中,模型按层拆分,而张量并行则跨 GPU 拆分张量操作 (例如矩阵乘法)。使用这些模型并行策略,你需要将模型权重分片到许多设备上,这需要你定义跨进程的激活和梯度的通信协议。 这实现起来并不简单,可能需要采用一些框架,例如 Megatron-DeepSpeed 或 Nemo。其他对扩展训练至关重要的工具也需要被强调,例如自适应激活检查点和融合内核。 可以在 扩展阅读 找到有关并行范式的进一步阅读。
因此,我们问自己下面一个问题: 仅用数据并行我们可以走多远?我们能否使用现有的工具在单个设备中适应超大型训练过程 (包括活跃模型、参考模型和优化器状态)? 答案似乎是肯定的。 主要因素是: 适配器和 8 位矩阵乘法! 让我们在以下部分中介绍这些主题:
8 位矩阵乘法
高效的 8 位矩阵乘法是论文 LLM.int8() 中首次引入的一种方法,旨在解决量化大规模模型时的性能下降问题。 所提出的方法将在线性层中应用的矩阵乘法分解为两个阶段: 在 float16 中将被执行的异常值隐藏状态部分和在 int8 中被执行的“非异常值”部分。
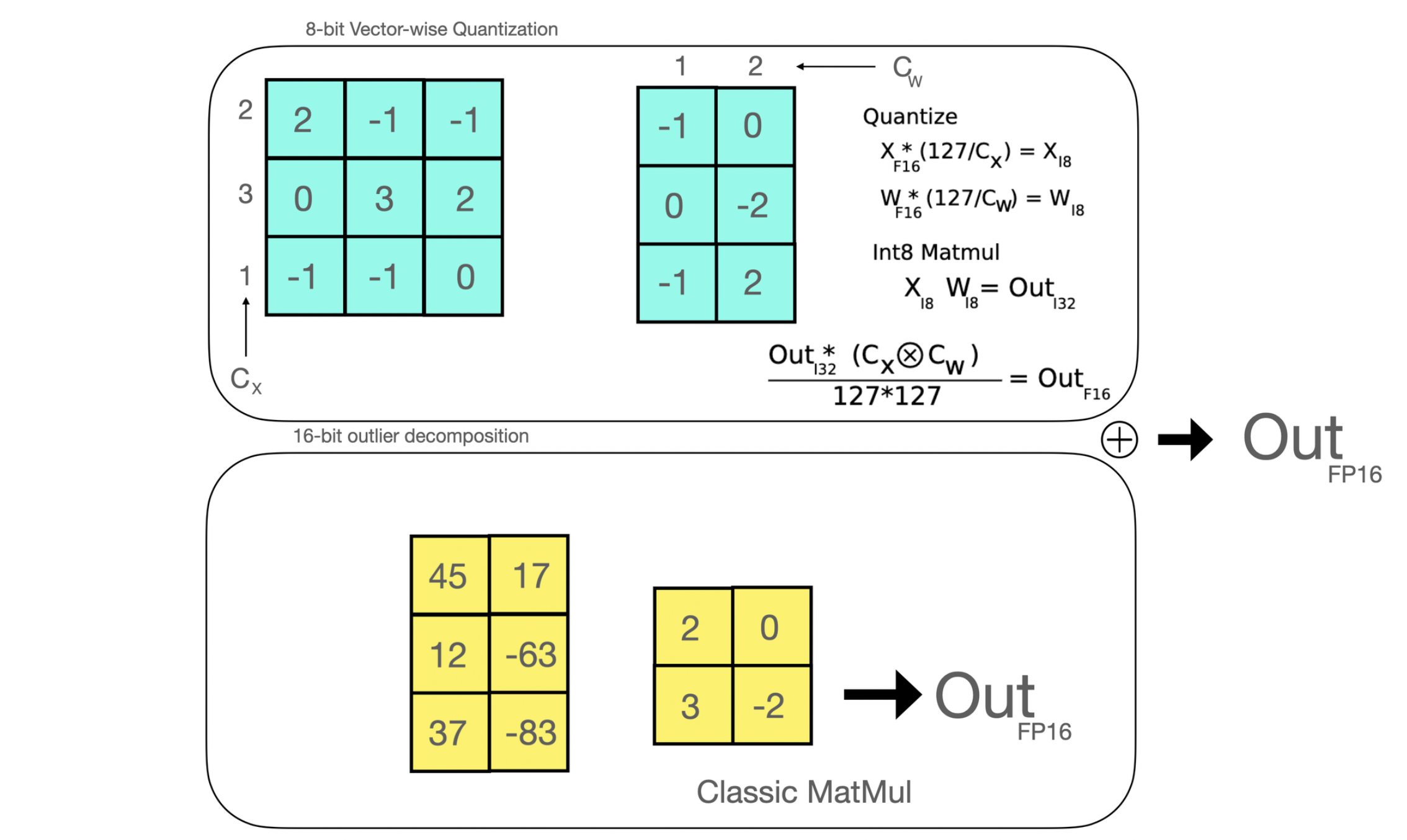
高效的 8 位矩阵乘法是论文 LLM.int8() 中首次引入的一种方法,旨在解决量化大规模模型时的性能下降问题。 所提出的方法将在线性层中应用的矩阵乘法分解为两个阶段: 在 float16 中被执行的异常值隐藏状态部分和在 int8 中被执行的“非异常值”部分。
简而言之,如果使用 8 位矩阵乘法,则可以将全精度模型的大小减小到 4 分之一 (因此,对于半精度模型,可以减小 2 分之一)。
低秩适配和 PEFT
在 2021 年,一篇叫 LoRA: Low-Rank Adaption of Large Language Models 的论文表明,可以通过冻结预训练权重,并创建查询和值层的注意力矩阵的低秩版本来对大型语言模型进行微调。这些低秩矩阵的参数远少于原始模型,因此可以使用更少的 GPU 内存进行微调。 作者证明,低阶适配器的微调取得了与微调完整预训练模型相当的结果。
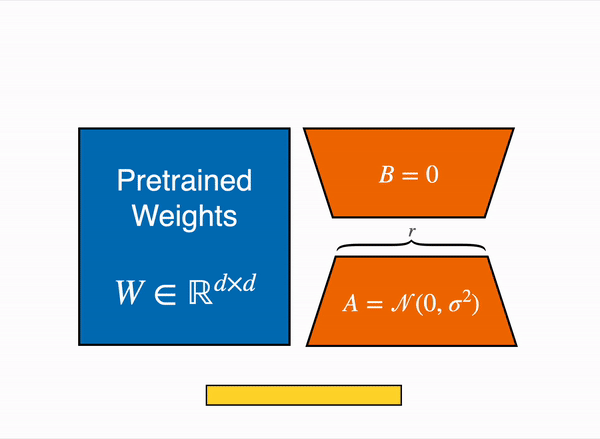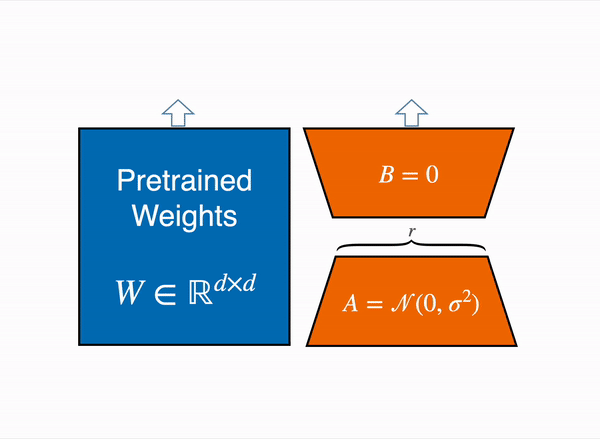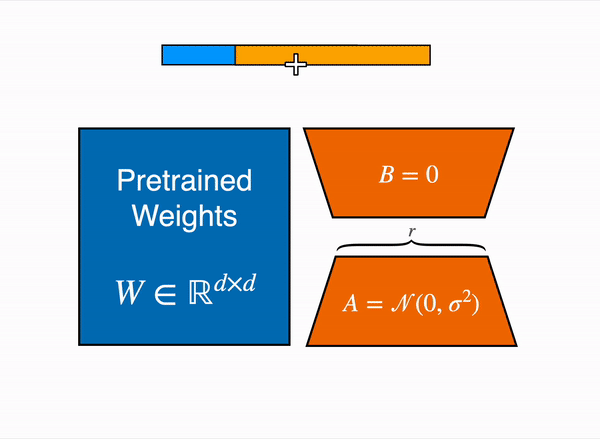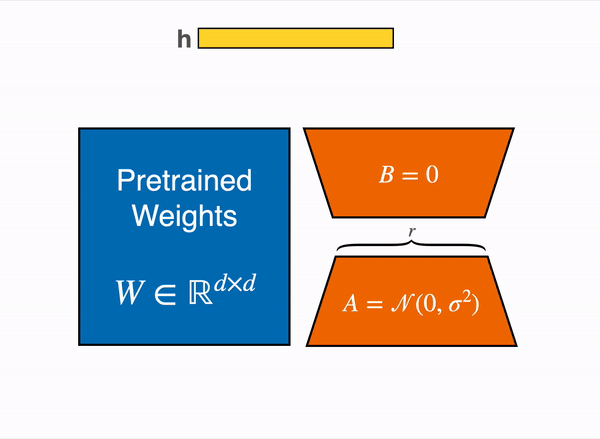
原始 (冻结的) 预训练权重 (左) 的输出激活由一个由权重矩阵 A 和 B 组成的低秩适配器 (右) 增强。
这种技术允许使用一小部分内存来微调 LLM。 然而,也有一些缺点。由于适配器层中的额外矩阵乘法,前向和反向传递的速度大约是原来的两倍。
什么是 PEFT?
Parameter-Efficient Fine-Tuning (PEFT) 是一个 Hugging Face 的库,它被创造出来以支持在 LLM 上创建和微调适配器层。 peft 与 Accelerate 无缝集成,用于利用了 DeepSpeed 和 Big Model Inference 的大规模模型。
此库支持很多先进的模型,并且有大量的例子,包括:
- 因果语言建模
- 条件生成
- 图像分类
- 8 位 int8 训练
- Dreambooth 模型的低秩适配
- 语义分割
- 序列分类
- 词符分类
该库仍在广泛和积极的开发中,许多即将推出的功能将在未来几个月内公布。
使用低质适配器微调 20B 参数量的模型
现在先决条件已经解决,让我们一步步过一遍整个管道,并用图说明如何在单个 24GB GPU 上使用上述工具使用 RL 微调 20B 参数量的 LLM!
第 1 步: 在 8 位精度下加载你的活跃模型
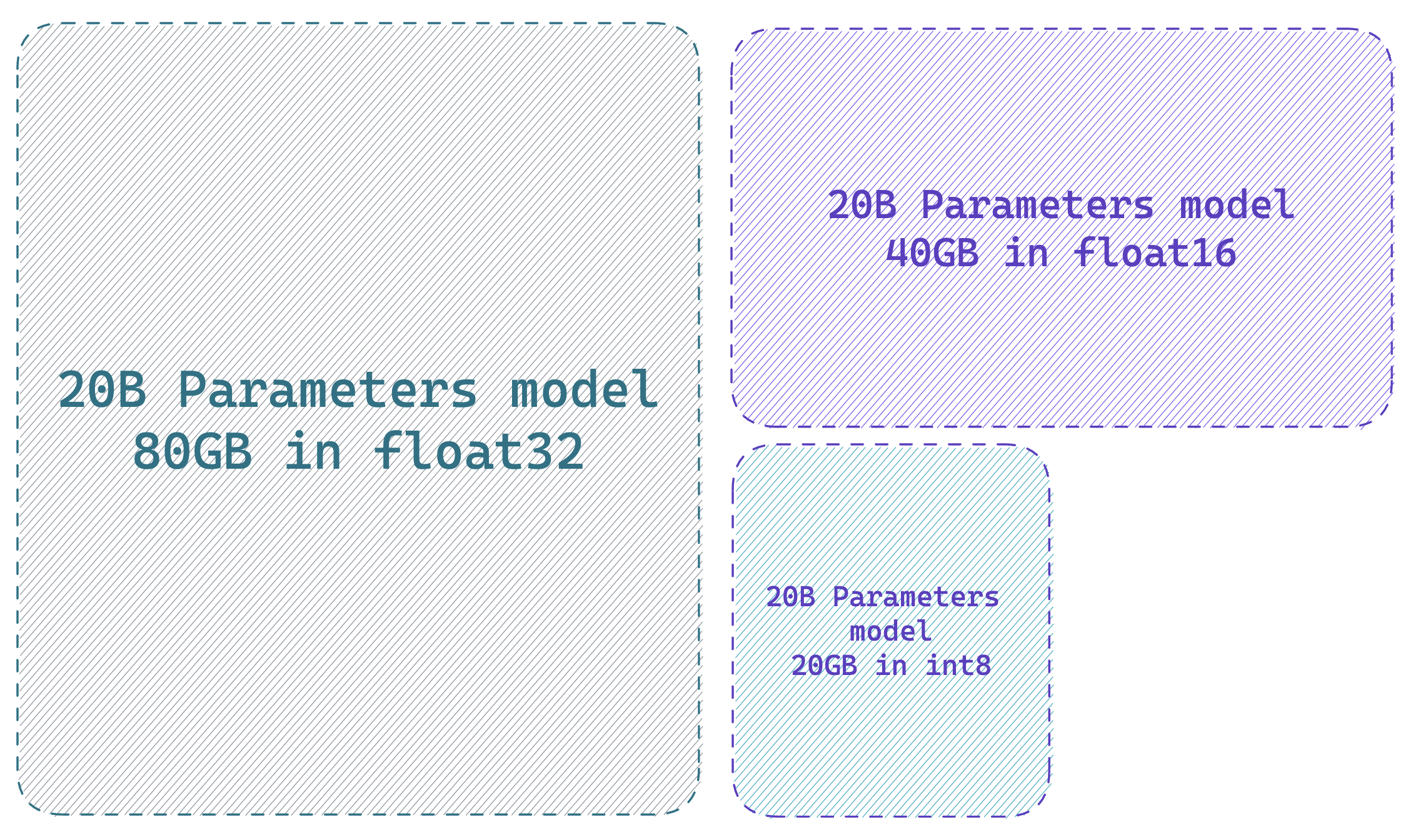
与全精度模型相比,以 8 位精度加载模型最多可节省 4 倍的内存
使用 transformers 减少 LLM 内存的“免费午餐”是使用 LLM.int8 中描述的方法,以 8 位精度加载模型。 这可以通过在调用 from_pretrained 方法时简单地添加标志 load_in_8bit=True 来执行 (你可以在 文档中 阅读更多相关信息)。
如前一节所述,计算加载模型所需的 GPU 内存量的“技巧”是根据“十亿个参数量”进行思考。 由于一个字节需要 8 位,因此全精度模型 (32 位 = 4 字节) 每十亿个参数需要 4GB,半精度模型每十亿个参数需要 2GB,int8 模型每十亿个参数需要 1GB。
所以首先,我们只加载 8 位的活跃模型。 让我们看看第二步需要做什么!
第 2 步: 使用 peft 添加额外可训练的适配器
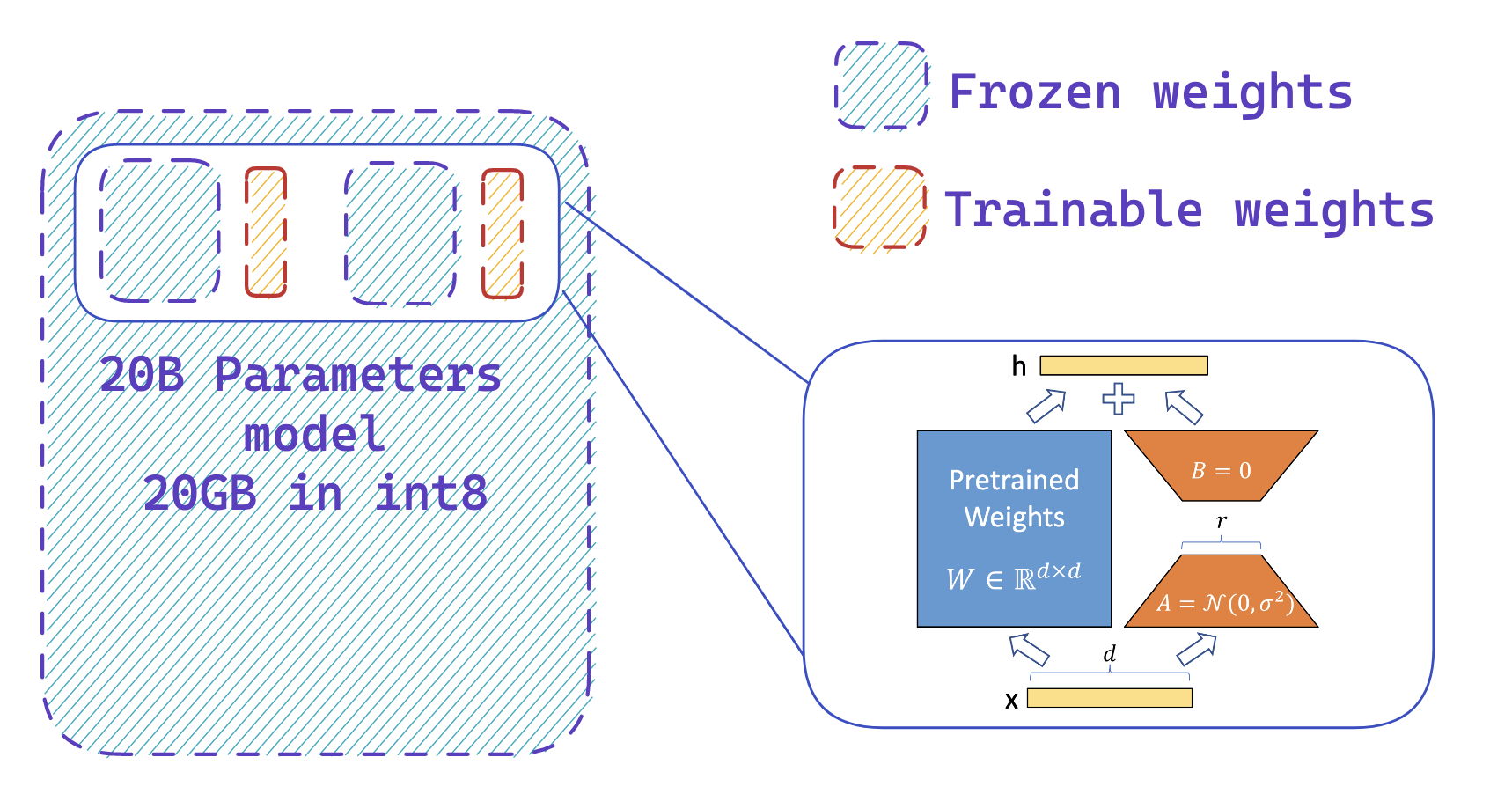
您可以轻松地在冻结的 8 位模型上添加适配器,从而通过训练一小部分参数来减少优化器状态的内存需求
第二步是在模型中加载适配器并使这些适配器可训练。 这可以大幅减少活跃模型所需的可训练权重的数量。 此步骤利用 peft 库,只需几行代码即可执行。 请注意,一旦适配器经过训练,您就可以轻松地将它们推送到 Hub 以供以后使用。
第 3 步: 使用同样的模型得到参考和活跃 logits
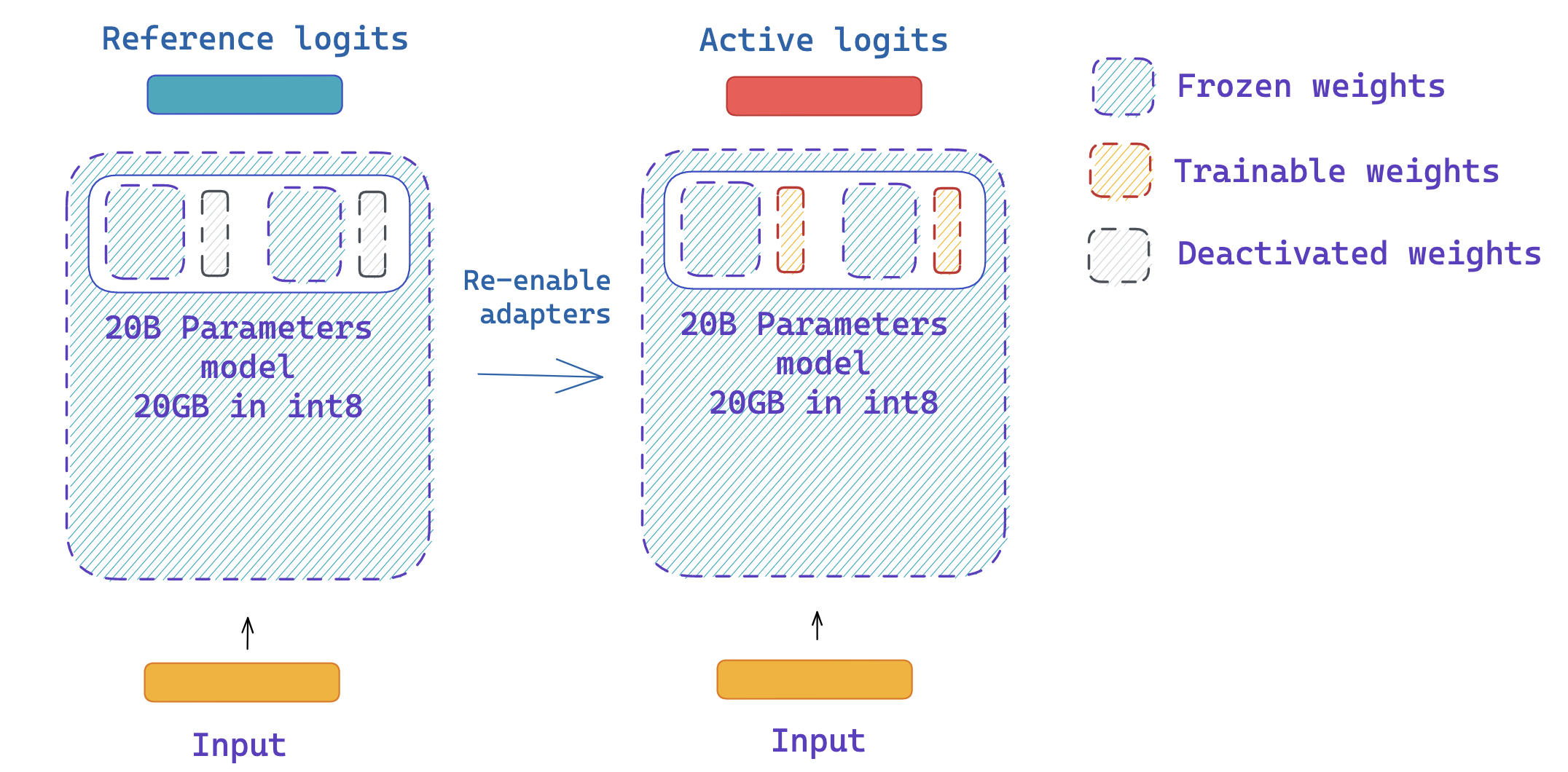
你可以方便地使用 peft 关闭和使能适配器
由于适配器可以停用,我们可以使用相同的模型来获取 PPO 的参考和活跃的 logits 值,而无需创建两个相同的模型副本! 这利用了 peft 库中的一个功能,即 disable_adapters 上下文管理器。
训练脚本概述
我们现在将描述如何使用 transformers 、 peft 和 trl 训练 20B 参数量的 gpt-neox 模型。 这个例子的最终目标是微调 LLM 以在内存受限的设置中生成积极的电影评论。类似的步骤可以应用于其他任务,例如对话模型。
整体来看有三个关键步骤和训练脚本:
脚本 1 - 在冻结的 8 位模型上微调低秩适配器,以便在 imdb 数据集上生成文本。
脚本 2 - 将适配器层合并到基础模型的权重中并将它们存储在 Hub 上。
脚本 3 - 对低等级适配器进行情感微调以创建正面评价。
我们在 24GB NVIDIA 4090 GPU 上测试了这些步骤。虽然可以在 24 GB GPU 上执行整个训练过程,但在 研究集群上的单个 A100 上无法进行完整的训练过程。
训练过程的第一步是对预训练模型进行微调。 通常这需要几个高端的 80GB A100 GPU,因此我们选择训练低阶适配器。 我们将其视为一种因果语言建模设置,并针从 imdb 数据集中训练了一个 epoch 的示例,该数据集具有电影评论和指明积极还是消极情绪的标签。
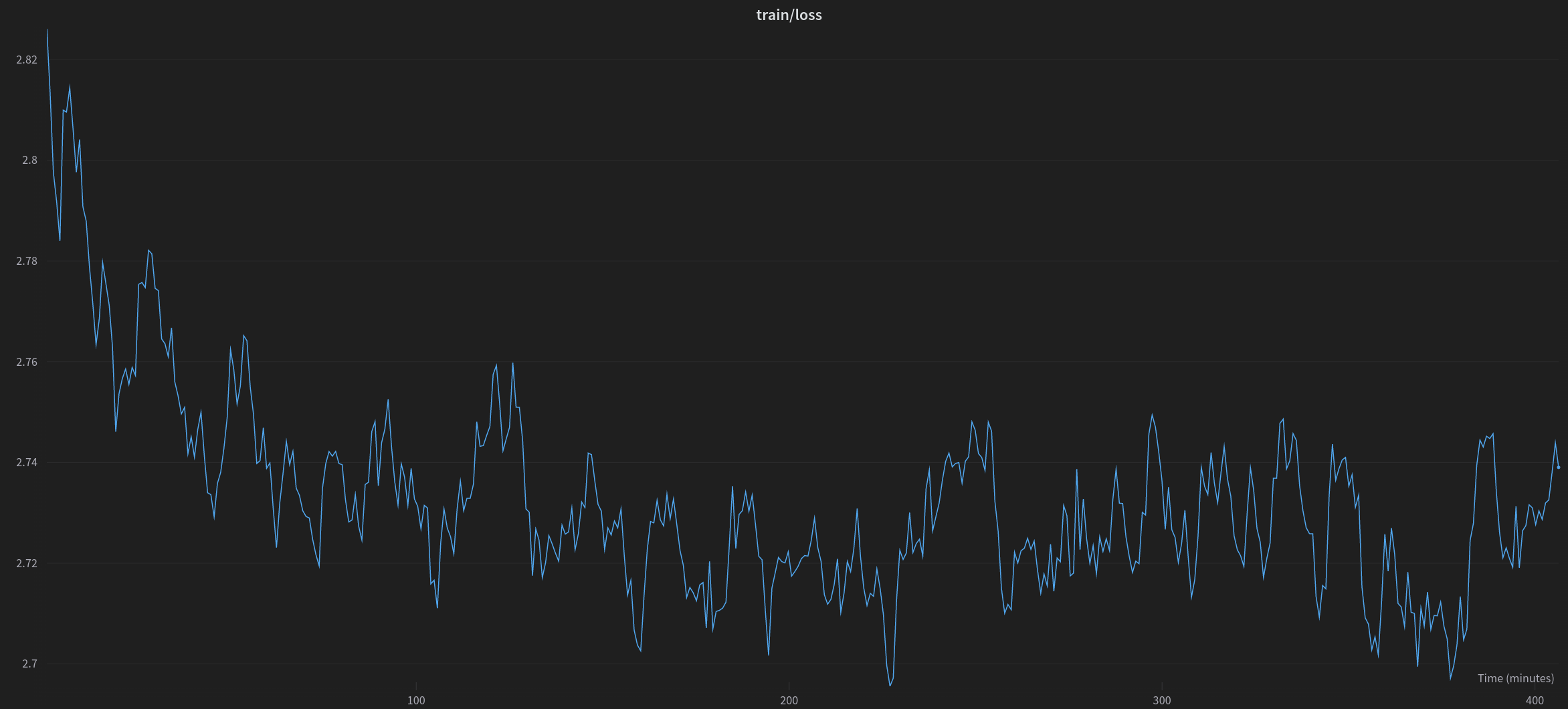
在 imdb 数据集上训练 gpt-neox-20b 模型一个 epoch 期间的训练损失
为了利用已经适配了的模型并使用 RL 执行进一步微调,我们首先需要组合自适应权重,这是通过加载预训练模型和 16 位浮点精度的适配器并且加和权重矩阵 (应用适当的缩放比例) 来实现的。
最后,我们可以在冻结的、用 imdb 微调过的模型之上微调另一个低秩适配器。我们使用一个 imdb 情感分类器 来为 RL 算法提供奖励。
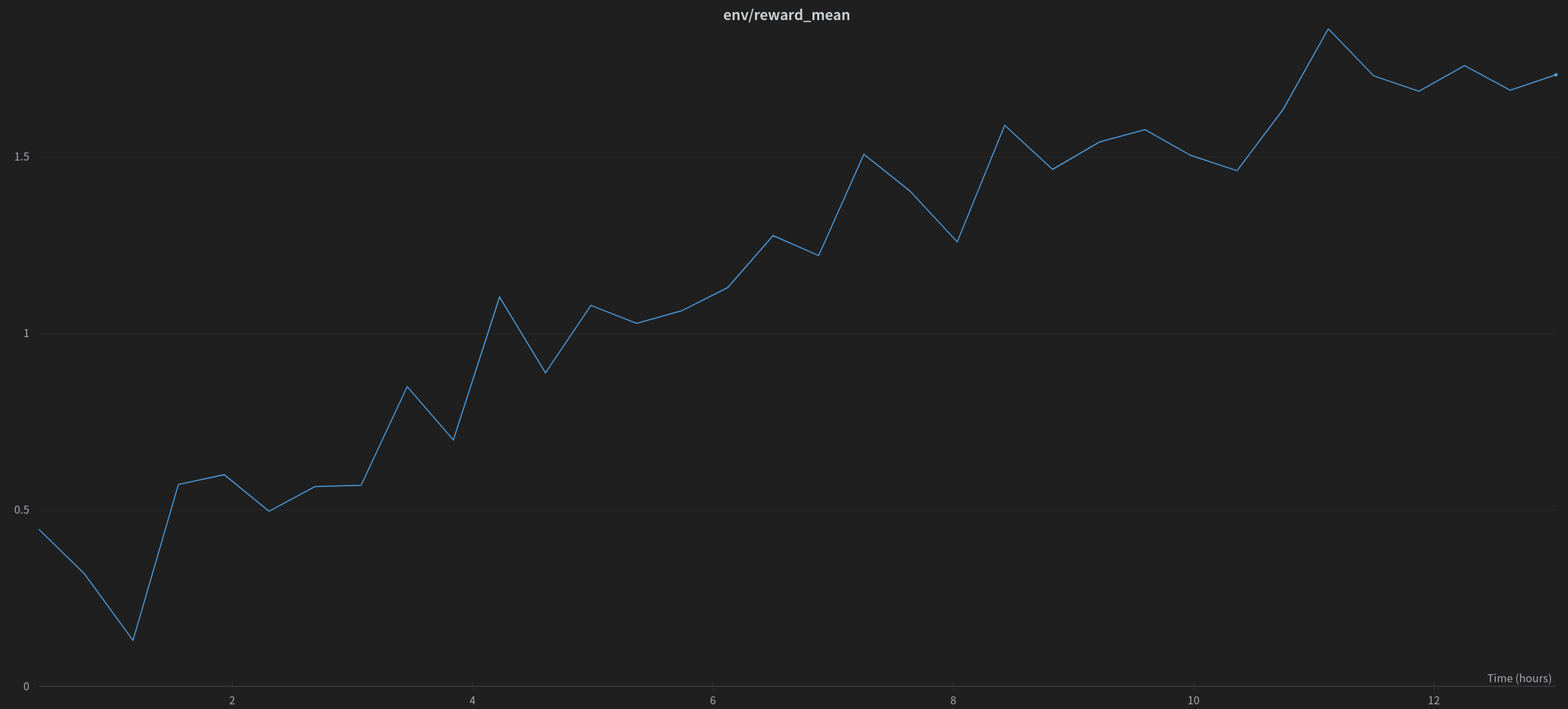
RL 微调 peft 适配过的 20B 参数量的模型以生成积极影评时的奖励均值。
如果您想查看更多图表和文本生成,可在 链接处 获取此实验的完整权重和偏差报告。
结论
我们在 trl 中实现了一项新功能,允许用户利用 peft 和 bitsandbytes 库以合理的成本使用 RLHF 微调大型语言模型。 我们证明了可以在 24GB 消费级 GPU 上微调 gpt-neo-x (以 bfloat16 精度需要 40GB!),我们期望社区将广泛使用此集成来微调利用了 RLHF 的大型模型,并分享出色的工件。
我们已经为接下来的步骤确定了一些有趣的方向,以挑战这种集成的极限:
- 这将如何在多 GPU 设置中扩展? 我们将主要探索这种集成将如何根据 GPU 的数量进行扩展,是否可以开箱即用地应用数据并行,或者是否需要在任何相关库上采用一些新功能。
- 我们可以利用哪些工具来提高训练速度? 我们观察到这种集成的主要缺点是整体训练速度。 在未来,我们将持续探索使训练更快的可能方向。
参考
- 并行范式: https://hf.co/docs/transformers/v4.17.0/en/parallelism
transformers中的 8 位集成: https://hf.co/blog/hf-bitsandbytes-integration- LLM.int8 论文: https://arxiv.org/abs/2208.07339
- 梯度检查点解释: https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-checkpointing.html
英文原文: https://hf.co/blog/trl-peft
作者: Edward Beeching、Younes Belkada、Leandro von Werra、Sourab Mangrulkar、Lewis Tunstall、Kashif Rasul
译者: AIboy1993 (李旭东)
审校、排版: zhongdongy (阿东)
在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs的更多相关文章
- [转帖]Intel要提供2.5G的消费级以太网 价格2.4刀
千兆网已成过去!Intel将全面普及2.5Gbps以太网 https://news.cnblogs.com/n/641736/ 硬件发展突飞猛进 投递人 itwriter 发布于 2019-10-02 ...
- 再战希捷:西部数据透露96层闪存已用于消费级SSD
导读 96层堆叠3D NAND闪存已经成为行业主流,包括西部数据这样的传统机械硬盘大厂,也在逐步普及96层闪存,并已经用于消费级SSD. 96层堆叠3D NAND闪存已经成为行业主流,包括西部数据这样 ...
- 软件架构自学笔记-- 转载“虎牙在全球 DNS 秒级生效上的实践”
虎牙在全球 DNS 秒级生效上的实践 这次分享的是全球 DNS 秒级生效在虎牙的实践,以及由此产生的一些思考,整体上,分为以下 5 各部分: 背景介绍: 方案设计和对比: 高可用: 具体实践和落地: ...
- Spark 灰度发布在十万级节点上的成功实践 CI CD
原创文章,转载请务必将下面这段话置于文章开头处. 本文转发自技术世界,原文链接 http://www.jasongj.com/spark/ci_cd/ 本文所述内容基于某顶级互联网公司数万节点下 Sp ...
- 虎牙在全球 DNS 秒级生效上的实践 集群内通过 raft 协议同步数据,毫秒级别完成同步。
https://mp.weixin.qq.com/s/9bEiE4QFBpukAfNOYhmusw 虎牙在全球 DNS 秒级生效上的实践 原创: 周健&李志鹏 阿里巴巴中间件 今天
- 十几张表的join(千万级/百万级表) 7hours-->5mins
================START============================== 来了一个mail说是job跑得很慢,调查下原因 先来看下sql: SELECT h.order_ ...
- 虎牙在全球 DNS 秒级生效上的实践
本文整理自虎牙中间件团队在 Nacos Meetup 的现场分享,阿里巴巴中间件受权发布. 这次分享的是全球 DNS 秒级生效在虎牙的实践,以及由此产生的一些思考,整体上,分为以下5各部分: 背景介绍 ...
- js 取父级 页面上的元素
var bb=window.opener.frames["contentIframe"].document.all["my:费用类别"][0].value; / ...
- dubbo多网卡时,服务提供者的错误IP注册到注册中心导致消费端连接不上
使用了虚拟机之后,启动了dubbo服务提供者应用,又连了正式环境的注册中心: 一旦dubbo获取的ip错误后, 这种情况即使提供者服务停掉,目前dubbo没有能力清除这类错误的提供者: (需要修改源码 ...
- 2016/2/24 css画三角形 border的上右下左的调整 以及内区域的无限变小 边界透明
网页因为 CSS 而呈现千变万化的风格.这一看似简单的样式语言在使用中非常灵活,只要你发挥创意就能实现很多比人想象不到的效果.特别是随着 CSS3 的广泛使用,更多新奇的 CSS 作品涌现出来. 今天 ...
随机推荐
- 我的第二次JAVA作业
1. Java包含哪两大类数据类型?其中基本类型的每种类型的取值范围和默认值分别是多少?请编程验证. Java 的两大数据类型: 基本类型 引用类 基本数据类型: 整数类型: byte: byte 数 ...
- bzoj 3532
很好的一道题,对理解最小割有很大帮助 首先,不难发现本题与网络流24题中的某一道很类似,我们可以先跑一次dp求出每个节点的LIS,然后拆点,拆出的两点之间连流量为删除的代价的边,剩下的点之间按dp的转 ...
- pytest之conftest.py
一.conftest.py的特点 1.可以跨.py文件调用,有多个.py文件调用时,可让conftest.py只调用了一次fixture,或调用多次fixture 2.conftest.py与运行的用 ...
- 【APT】响尾蛇(SideWinder)Hta文件自动解密C2
前言 一个用于从SideWinder APT组织常用的hat文件中解密C2链接地址的Python脚本,示例代码对一些老的hat文件效果比较好,新的样本可能需要根据实际情况修改下,最初是用于对VT上命中 ...
- 【peewee】Python使用peewee时where中不同类型比较的问题
问题 以学生表为例,TableStudents表中age字段是TextField类型,想要筛选出18岁以上的学生 TableStudents.select().where(TableStudents. ...
- 一种典型的不知循环次数的c语言循环问题
问题如图 代码如下 1 #define _CRT_SECURE_NO_WARNINGS 1 2 #include<stdio.h> 3 int main() 4 { 5 puts(&quo ...
- GPS数据处理
GPS数据处理 题目内容: NMEA-0183协议是为了在不同的GPS(全球定位系统)导航设备中建立统一的BTCM(海事无线电技术委员会)标准,由美国国家海洋电子协会(NMEA-The Nationa ...
- uni-app中调用高德地图去设置点和轨迹
盒子部分 <view style="width: 100%; height: 100%" id="busContainer"> </view& ...
- OSIDP-并发:死锁和饥饿-06
死锁原理 死锁:一组相互竞争系统资源或者进行通信的进程间"永久"阻塞的现象. 资源分为两类:可重用资源和可消耗资源. 可重用资源:一次只能被一个进程使用且不会被耗尽的资源.如处理器 ...
- MySQL数据库sql_mode导致varchar字段超过长度被截断插入
django数据库设置sql_mode MySQL的sql_mode解析与设置 mysql中sql_mode的修改 sql_mode:它定义了MySQL应该支持的sql语法,对数据的校验等等. 问题 ...