pandas常用操作详解(复制别人的)——数据透视表操作:pivot_table()
原文链接:https://www.cnblogs.com/Yanjy-OnlyOne/p/11195621.html
一文看懂pandas的透视表pivot_table
一、概述
1.1 什么是透视表?
透视表是一种可以对数据动态排布并且分类汇总的表格格式。或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table。
1.2 为什么要使用pivot_table?
- 灵活性高,可以随意定制你的分析计算要求
- 脉络清晰易于理解数据
- 操作性强,报表神器
二、如何使用pivot_table
首先读取数据,数据集是火箭队当家球星James Harden某一赛季比赛数据作为数据集进行讲解。数据地址。
先看一下官方文档中pivot_table的函数体:pandas.pivot_table - pandas 0.21.0 documentation
pivot_table(data, values=None, index=None, columns=None,aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
pivot_table有四个最重要的参数index、values、columns、aggfunc,本文以这四个参数为中心讲解pivot操作是如何进行。
2.1 读取数据
- import pandas as pd
- import numpy as np
- df = pd.read_csv('h:/James_Harden.csv',encoding='utf8')
- df.tail()
数据格式如下:
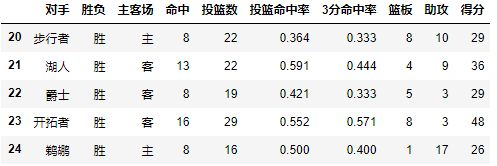
2.2 Index
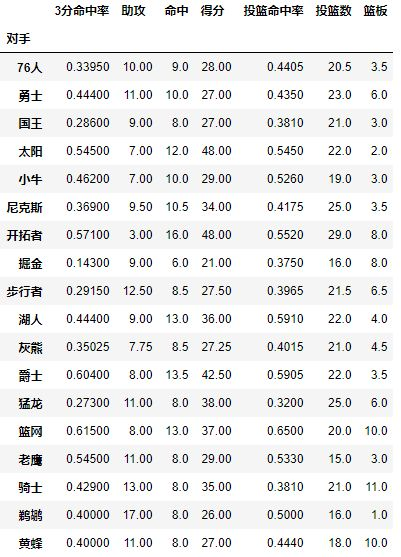
每个pivot_table必须拥有一个index,如果想查看哈登对阵每个队伍的得分,首先我们将对手设置为index:
pd.pivot_table(df,index=[u'对手'])
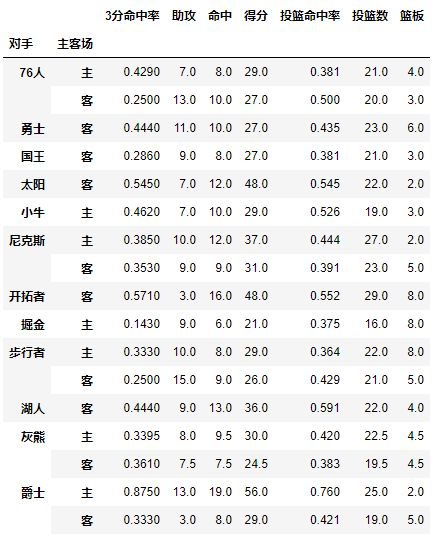
对手成为了第一层索引,还想看看对阵同一对手在不同主客场下的数据,试着将对手与胜负与主客场都设置为index,其实就变成为了两层索引
pd.pivot_table(df,index=[u'对手',u'主客场'])
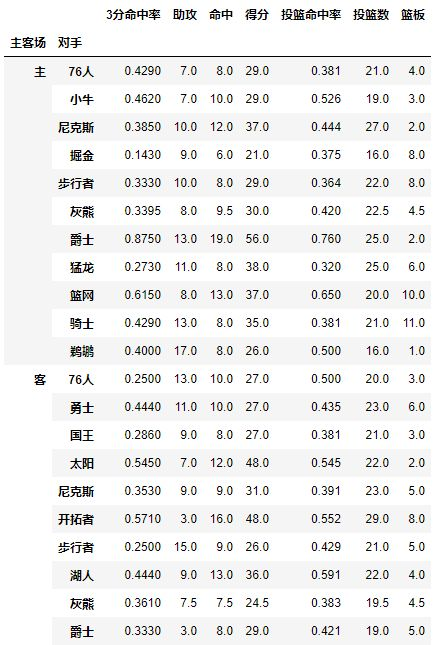
试着交换下它们的顺序,数据结果一样:
pd.pivot_table(df,index=[u'主客场',u'对手'])
看完上面几个操作,Index就是层次字段,要通过透视表获取什么信息就按照相应的顺序设置字段,所以在进行pivot之前你也需要足够了解你的数据。
2.3 Values
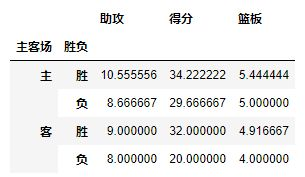
通过上面的操作,我们获取了james harden在对阵对手时的所有数据,而Values可以对需要的计算数据进行筛选,如果我们只需要james harden在主客场和不同胜负情况下的得分、篮板与助攻三项数据:
pd.pivot_table(df,index=[u'主客场',u'胜负'],values=[u'得分',u'助攻',u'篮板'])
2.4 Aggfunc
aggfunc参数可以设置我们对数据聚合时进行的函数操作。
当我们未设置aggfunc时,它默认aggfunc='mean'计算均值。我们还想要获得james harden在主客场和不同胜负情况下的总得分、总篮板、总助攻时:
pd.pivot_table(df,index=[u'主客场',u'胜负'],values=[u'得分',u'助攻',u'篮板'],aggfunc=[np.sum,np.mean])

2.5 Columns
Columns类似Index可以设置列层次字段,它不是一个必要参数,作为一种分割数据的可选方式。
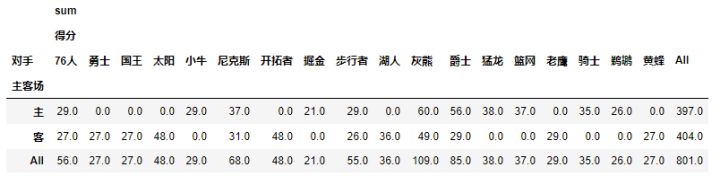
- #fill_value填充空值,margins=True进行汇总
- pd.pivot_table(df,index=[u'主客场'],columns=[u'对手'],values=[u'得分'],aggfunc=[np.sum],fill_value=0,margins=1)
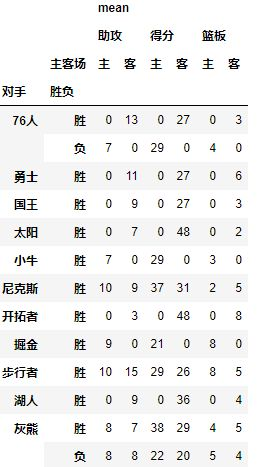
现在我们已经把关键参数都介绍了一遍,下面是一个综合的例子:
table=pd.pivot_table(df,index=[u'对手',u'胜负'],columns=[u'主客场'],values=[u'得分',u'助攻',u'篮板'],aggfunc=[np.mean],fill_value=0)
结果如下:
aggfunc也可以使用dict类型,如果dict中的内容与values不匹配时,以dict中为准。
table=pd.pivot_table(df,index=[u'对手',u'胜负'],columns=[u'主客场'],values=[u'得分',u'助攻',u'篮板'],aggfunc={u'得分':np.mean, u'助攻':[min, max, np.mean]},fill_value=0)
结果就是助攻求min,max和mean,得分求mean,而篮板没有显示。
pandas常用操作详解(复制别人的)——数据透视表操作:pivot_table()的更多相关文章
- 小白学 Python 数据分析(12):Pandas (十一)数据透视表(pivot_table)
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
- 【Excle数据透视表】如何复制数据透视表
左边创建完数据透视表,右边是复制过去的部分数据透视表---显示数值状态的内容,为什么复制过来的不是数据透视表呢? 解决办法: 全选定数据透视表再进行粘贴复制 步骤一 单击数据透视表任意单元格→分析→操 ...
- pandas常用操作详解——info()与descirbe()
概述 df.info():主要介绍数据集各列的数据类型,是否为空值,内存占用情况: df.describe(): 主要介绍数据集各列的数据统计情况(最大值.最小值.标准偏差.分位数等等). df.in ...
- VC++常用数据类型及其操作详解
原文地址:http://blog.csdn.net/ithomer/article/details/5019367 VC++常用数据类型及其操作详解 一.VC常用数据类型列表 二.常用数据类型转化 2 ...
- Pandas 常见操作详解
Pandas 常见操作详解 很多人有误解,总以为Pandas跟熊猫有点关系,跟gui叔创建Python一样觉得Pandas是某某奇葩程序员喜欢熊猫就以此命名,简单介绍一下,Pandas的命名来自于面板 ...
- Linux Shell数组常用操作详解
Linux Shell数组常用操作详解 1数组定义: declare -a 数组名 数组名=(元素1 元素2 元素3 ) declare -a array array=( ) 数组用小括号括起,数组元 ...
- SQLAlchemy02 /SQLAlchemy对数据的增删改查操作、属性常用数据类型详解
SQLAlchemy02 /SQLAlchemy对数据的增删改查操作.属性常用数据类型详解 目录 SQLAlchemy02 /SQLAlchemy对数据的增删改查操作.属性常用数据类型详解 1.用se ...
- SQLAlchemy(二):SQLAlchemy对数据的增删改查操作、属性常用数据类型详解
SQLAlchemy02 /SQLAlchemy对数据的增删改查操作.属性常用数据类型详解 目录 SQLAlchemy02 /SQLAlchemy对数据的增删改查操作.属性常用数据类型详解 1.用se ...
- [Android新手区] SQLite 操作详解--SQL语法
该文章完全摘自转自:北大青鸟[Android新手区] SQLite 操作详解--SQL语法 :http://home.bdqn.cn/thread-49363-1-1.html SQLite库可以解 ...
随机推荐
- UDP数据包最大传输长度
概念以太网(Ethernet)数据帧的长度必须在46-1500字节之间,这是由以太网的物理特性决定的.这个1500字节被称为链路层的MTU(最大传输单元). 但这并不是指链路层的长度被限制在1500字 ...
- Java中静态变量与非静态变量的区别
感谢大佬:https://www.cnblogs.com/liuhuijie/p/9175167.html ①java类的成员变量有俩种: 一种是被static关键字修饰的变量,叫类变量或者静态变量 ...
- jdk1.5出现的新特性---->增强for循环
import java.util.HashMap; import java.util.HashSet; import java.util.Iterator; import java.util.Map; ...
- iOS组件化之-给自己的组件添加资源文件
在 podspec 中,利用 source_files 可以指定要编译的源代码文件.可是,当我们需要把图片.音频.NIB等资源打包进 Pod 时该怎么办呢? 1.如何把资源文件打包为.bundle文件 ...
- Keycloak 团队宣布他们正在弃用大多数 Keycloak 适配器,包括Spring Security和Spring Boot
2月14日,Keycloak 团队宣布他们正在弃用大多数 Keycloak 适配器. 其中包括Spring Security和Spring Boot的适配器,这意味着今后Keycloak团队将不再提供 ...
- Solution -「AGC 003D」「AT 2004」Anticube
\(\mathcal{Description}\) Link. 给定 \(n\) 个数 \(a_i\),要求从中选出最多的数,满足任意两个数之积都不是完全立方数. \(n\le10^5\) ...
- 探针配置失误,线上容器应用异常死锁后,kubernetes集群未及时响应自愈重启容器?
探针配置失误,线上容器应用异常死锁后,kubernetes集群未及时响应自愈重启容器? 探针配置失误,线上容器应用异常死锁后,kubernetes集群未及时响应自愈重启容器? 线上多个服务应用陷入了死 ...
- Linux-CPU优化之平均负载率
一.平均负载率定义 平均负载是指单位时间内,系统处于可运行状态 和不可中断状态 的平均进程数,也就是平均活跃进程数,它和CPU 使用率并没有直接关系. 可运行状态的进程:是指正在使用 CPU 或者正在 ...
- 简述LSM-Tree
LSM-Tree 1. 什么是LSM-Tree LSM-Tree 即 Log Structrued Merge Tree,这是一种分层有序,硬盘友好的数据结构.核心思想是利用磁盘顺序写性能远高于随机写 ...
- CobaltStrike逆向学习系列(6):Beacon sleep_mask 分析
这是[信安成长计划]的第 6 篇文章 关注微信公众号[信安成长计划] 0x00 目录 0x01 C2Profile 分析 0x02 set userwx "true" 0x03 s ...