Nebula Graph 在企查查的应用
{kind=link}

背景
企查查是企查查科技有限公司旗下的一款企业信用查询工具,旨在为用户提供快速查询企业工商信息、法院判决信息、关联企业信息、法律诉讼、失信信息、被执行人信息、知识产权信息、公司新闻、企业年报等服务。
为更好地展现企业之间的法律诉讼、风险信息、股权信息、董监高法等信息,我们抽取结构化/非结构化的企业数据构建企业知识图谱,为用户提供真实可靠的服务。
图数据库选择
在最初的时候,我们用的是 Neo4j HA cluster 作为存储端。随着数据和业务规模的不断扩展,要求我们需要一个读写性能良好,分布式的图数据库作支撑。经过几番调研,在 Dgraph、Nebula、Galaxybase、HugeGraph 中进行选择,最终选择了 Nebula Graph。
关于选型维度,我们相对侧重社区活跃度、资料获取难易程度、和最基本的读写、子图查询性能等方面。
具体的测评因为没有社区其他用户之前分享的文章那么详实,这里就不展开了。这里附上之前美团的测评链接:美团传送门。
Nebula Graph 简介
Nebula Graph 是什么
Nebula Graph 是一款开源的、分布式的、易扩展的原生图数据库,能够承载数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。
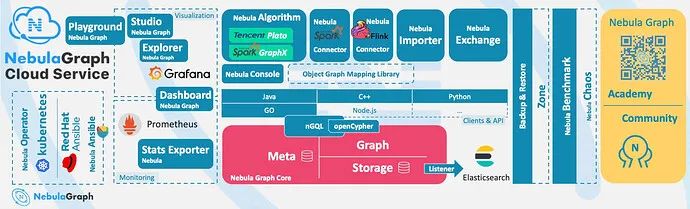
基于图数据库的特性使用 C++ 编写的 Nebula Graph,可以提供毫秒级查询。众多数据库中,Nebula Graph 在图数据服务领域展现了卓越的性能,数据规模越大,Nebula Graph 优势就越大。
Nebula Graph 采用 shared-nothing 架构,支持在不停数据库服务的情况下扩缩容。
Nebula Graph 开放了越来越多的原生工具,例如 Nebula Studio、Nebula Console、Nebula Exchange 等,更多工具可以查看生态工具概览。
此外,Nebula Graph 还具备与 Spark、Flink、HBase 等产品整合的能力,在这个充满挑战与机遇的时代,大大增强了自身的竞争力。
上面内容来源于 Nebula Graph 文档站点
Nebula Graph 架构
Nebula Graph 由三种服务构成:Graph 服务、Meta 服务和 Storage 服务,是一种存储与计算分离的架构。
每个服务都有可执行的二进制文件和对应进程,用户可以使用这些二进制文件在一个或多个计算机上部署 Nebula Graph 集群。
下图展示了 Nebula Graph 集群的经典架构。
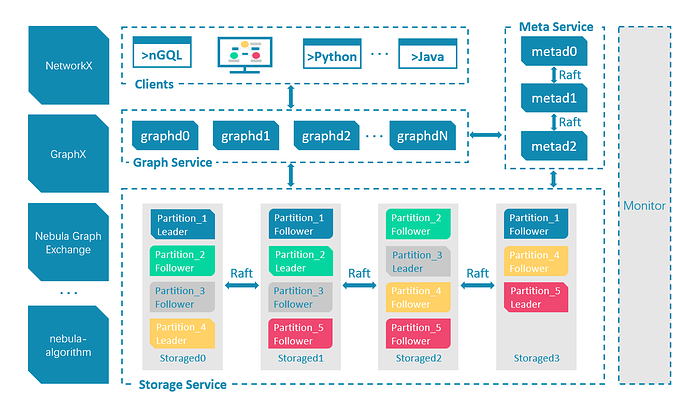
上面内容来源于 Nebula Graph 文档站点
流程优化
Nebula Graph 的数据导入
在我们接触 Nebula Graph 初期,当时周边工具不够完善。我们对 Nebula Graph 数据的导入不管全量还是增量都是采用 Hive 表推到 Kafka,消费 Kafka 批量写入 Nebula Graph 的方式。后来随着越来越多的数据和业务切换到 Nebula Graph,发现当前的方式存在三个较大问题:
- 全量导入的时长增多,到了难以接受的地步
- 增量数据消费由于 Kafka 多个分区,部分时序性无法保证
- 时间较长后如何减少增量数据进入 Nebula Graph 后整体数据的偏差
针对以上问题,我们针对各个 Space 的业务特性,由实时性的需求不同,做不同的优化方案。
- 在尝试 Nebula Spark Connector 和 Nebula Importer 之后,由便于维护和迁移多方面考虑,采用
hive table -> csv -> nebula server -> importer的方式进行全量的导入,整体耗时时长也有较大的提升。 - 经过拆分,测试把增量由多个分区合并到一个分区中消费。这样不会影响实时性,实时的误差可以保证在 1min 内,可以接受
- 对不同字段设置 TTL 属性,定期导入全量校正数据,同时补消费导入全量期间的数据,以免数据覆盖导致的错误数据。
服务的故障发现
当前我们已经升级到 v2.6.1,在最初的 v1 和 v2.0.1 存在部分 bug,经常容易出现的就是 OOM 导致 graph down。当时为了尽可能减少 graph down 的影响,做了相关脚本监控进程,出现宕机会立刻重启。
此外,为了提高整体服务的可用性,对集群节点的CPU,内存,硬盘,TCP等做了相应监控与告警。Nebula Graph 服务层的部分指标也接入了 Grafana,比较重要的几个告警指标如下:
nebula_metad_heartbeat_latency_us_avg_60 > 200000
nebula_graphd_num_slow_queries_rate_60 > 60
nebula_graphd_slow_query_latency_us_avg_60 >400000
nebula_graphd_slow_query_latency_us_p95_60 > 900000
nebula_graphd_num_query_errors_rate_60 > 10
nebula_storaged_add_edges_latency_us_avg_60 > 90000
nebula_storaged_add_vertices_latency_us_avg_60 > 90000
nebula_storaged_delete_edges_latency_us_avg_60 > 90000
nebula_storaged_delete_vertices_latency_us_avg_60 > 90000
nebula_storaged_get_neighbors_latency_us_avg_60 > 200000
同时应用层的接口做了慢查询和流量监控告警:
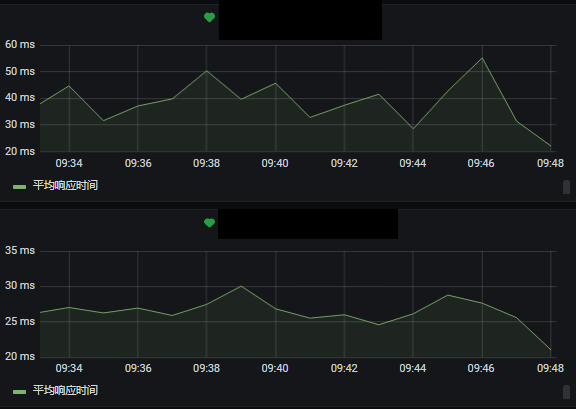
后来 Nebula 官方自己推出了 Nebula Dashboard 用于各个方面指标的监控, 不过貌似暂时没有告警(企业版有告警功能)。
经过前面的介绍,我们这边 Nebula Graph 的基本框架流程如下图:
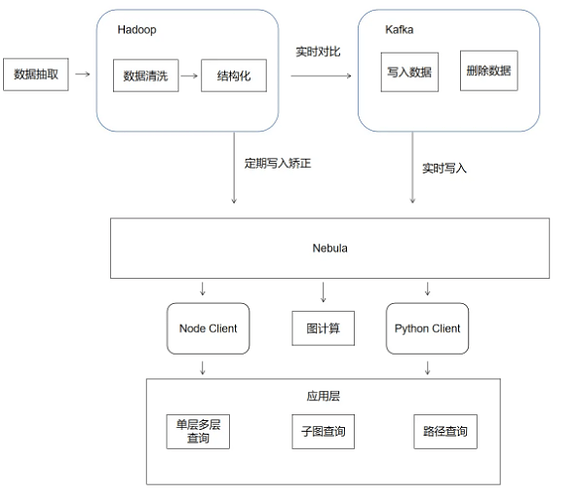
Nebula Graph 在企查查的经典业务
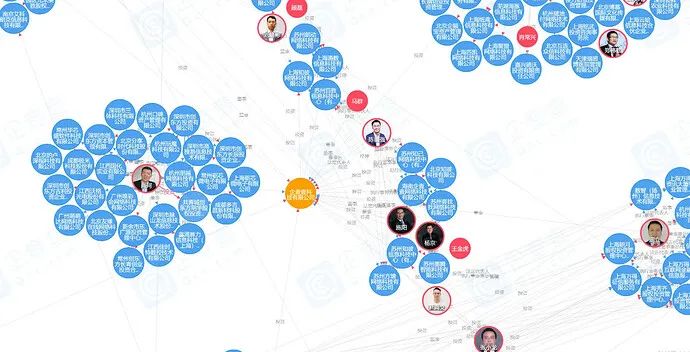
- 子图查询
业务需求:展示某公司/个人两跳以内的企业关系(例如:董监高法),以图的形式直观展示。
更多、更详细的信息可以访问企查查官网查看,有更多、更全面的企业 / 个人关系图谱、风险图谱、股东关系穿透等。传送门
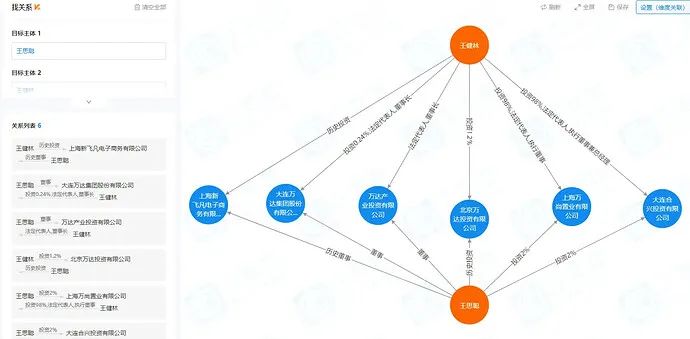
- 找关系
业务需求: 寻找任意两个或者多个实体(公司或者人)之间的关系,关系包括不限于董监高法,控股,历史董监高法,历史控股。
遗憾的是 Nebula Graph 目前官方的路径查询,经过多轮交叉对比测试,发现切过来后性能损失较大,暂时无法满足业务需求。我们目前还没有从 Neo4j 切到 Nebula Graph,经过多次沟通提了issue。目前在enhancement list中期待官方的优化,我们会持续跟进。
展望
Nebula 目前提供了超强的读写能力和丰富的生态,以及优秀的社区活跃度、官方支持等。但是在复杂的查询表达能力和路径查找及其节点过滤上还有待加强,期望社区越做越强,尽快完善相关功能,我们也方便都切到 Nebula Graph,不必维护两套数据库。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
{kind=link}
Nebula Graph 在企查查的应用的更多相关文章
- 12.通过微信小程序端访问企查查(采集工商信息)
需要注意的问题: 一.1.微信端访问企查查小程序需要登录.2.访问抓包获取的url是有时效性的过一段时间就不能用了. http://xcx.qichacha.com/wxa/v1/base/getEn ...
- 11.采集手机端app企查查上司公司数据(未成功)
---恢复内容开始--- 采集企查查手机端app数据: 1.首先手机端安装app并usb连接电脑端,fiddler监控手机请求数据对数据进行分析抓取. 手机端界面与fiddler界面参照: 2.对获取 ...
- 6.requests编写企查查爬虫
(为编写完善能拿下来数据) 企查查代码数据如下: #encoding:utf-8 import requests from lxml import etree import random import ...
- 图数据库 Nebula Graph 的数据模型和系统架构设计
Nebula Graph:一个开源的分布式图数据库.作为唯一能够存储万亿个带属性的节点和边的在线图数据库,Nebula Graph 不仅能够在高并发场景下满足毫秒级的低时延查询要求,而且能够提供极高的 ...
- 企查查app (二)
企查查app sign算法破解 已删除!!!! 这次我们又找到设备id,现在就只差aXM这个了. 关注小白公众号,小白带你成长.
- 企查查app (完结)
在经历前两次探索之后,终于可以把所有的加密关键参数搞定了. 已删除!!!! 好了现在基本结束了. 根据这个我写了一自动抓取企查查每日新增数据,需要的话可以去看看 企查查app新增企业数据抓取 关注小白 ...
- 企查查app 初步探索
企查查app sign算法破解初步探索 之前有说过企查查的sign的解密,但这次是企查查app的sign算法破解,目前是初步进程. 已删除!!!! 上边一些变量已经找到了,其中就有时间戳,其余两个需要 ...
- 企查查app新增企业数据抓取
企查查每日新增企业数据抓取尚未完成的工作: 需要自行抓包获取设备id,appid,sign等等 sign和时间戳保持一致即可 把所有的数据库.redis配置 无法自动登录,账号需要独立 redis数据 ...
- Nebula Graph 技术总监陈恒:图数据库怎么和深度学习框架进行结合?
引子 Nebula Graph 的技术总监在 09.24 - 09.30 期间同开源中国·高手问答的小伙伴们以「图数据库的设计和实践」为切入点展开讨论,包括:「图数据库的存储设计」.「图数据库的计算设 ...
随机推荐
- Mysql8.0主从配置
环境Centos7.6 ,mysql8.0 Mysql主从配置 1.1 配置环境: 本人在vm下做的实验,linux版本是centos的7.0版本,然后Mysql版本为此时较新的8.0.13版本.做最 ...
- Junit4进行参数化测试
@RunWith, 当类被@RunWith注解修饰,或者类继承了一个被该注解修饰的类,JUnit将会使用这个注解所指明的运行器(runner)来运行测试,而不是JUnit默认的运行器. 要进行参数化测 ...
- 程序员的情人节「GitHub 热点速览 v.22.07」
又是一年情人日,刚好还是发文的今天.也没什么好送的,送点程序员的浪漫--代码和开源项目吧.记得在本周特推查收这份来自程序员的独有浪漫. 本周 GitHub 霸榜的项目基本上都是老项目,从老项目中挖点新 ...
- Solution -「洛谷 P6577」「模板」二分图最大权完美匹配
\(\mathcal{Description}\) Link. 给定二分图 \(G=(V=X\cup Y,E)\),\(|X|=|Y|=n\),边 \((u,v)\in E\) 有权 \(w( ...
- pypi服务器搭建
pypi服务器搭建 [root@localhost ~]# hostnamectl set-hostname --static pypi-server [root@pypi-server ~]# yu ...
- php使用CURL实现GET和POST方式请求
CURL请求,支持GET和POST两种方式,默认为GET方式,如果传第二个参数则为POST方式请求,设置了超时时间,避免程序卡死. /** 使用curl方式实现get或post请求 @param $u ...
- iptTable规范
规范之HTML 先在当前页面放入几个表格设置按钮的html(样式可能需重新调整) <div class="bottom_nav1 ta_l" style="padd ...
- vue的父与子组件的访问
父访问子 (需要掌握) this.$children 和 this.$refs this.$children 返回的是一个数组,包含父组件的所有子组件 this,$refs 返回的是一个对象,默认为空 ...
- 科普IIS是什么?IIS介绍!
1.Microsoft IIS 是允许在公共Intranet或Internet上发布信息的Web服务器.Internet Information Server通过运用超文本传输协议(HTTP)传输信息 ...
- ZCC2410同步升压变换芯片
ZCC2410???? 22V/25A同步升压变换器 ZCC2410是一种高效率.高功率密度.宽输入范围.电流模式升压变换器.该转换器集成了一个10mΩ.24V电源开关和一个同步门高转换器效率的驱动 ...