Elasticsearch中的一些重要概念:cluster, node, index, document, shards及replica
首先,我们来看下一下如下的这个图:
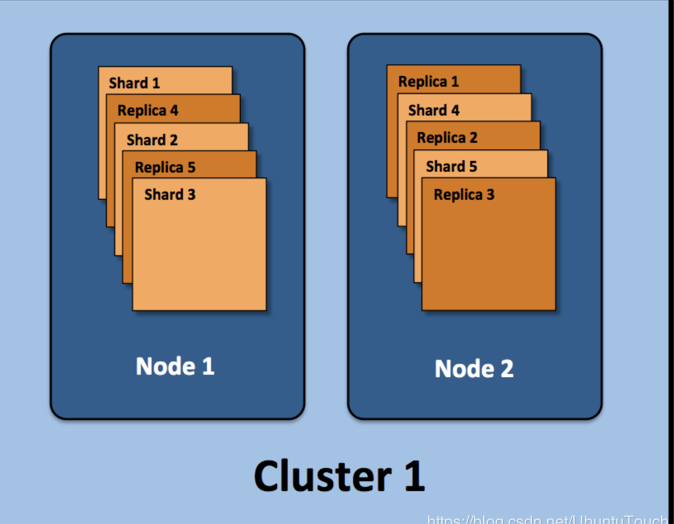
Cluster
Cluster也就是集群的意思。Elasticsearch集群由一个或多个节点组成,可通过其集群名称进行标识。通常这个Cluster 的名字是可以在Elasticsearch里的配置文件中设置的。在默认的情况下,如我们的Elasticsearch已经开始运行,那么它会自动生成一个叫做“elasticsearch”的集群。我们可以在config/elasticsearch.yml里定制我们的集群的名字
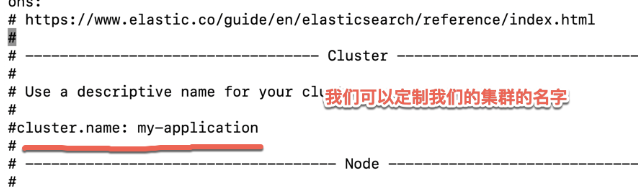
一个Elasticsearch的集群就像是下面的一个布局:
带有NGINX代理及Balancer的架构图是这样的:

可以通过GET _cluster/state来获取整个cluster的状态。这个状态只能被master node所改变。
node
单个Elasticsearch实例。 在大多数环境中,每个节点都在单独的盒子或虚拟机上运行。一个集群由一个或多个node组成。在测试的环境中,我可以把多个node运行在一个server上。在实际的部署中,大多数情况还是需要一个server上运行一个node。
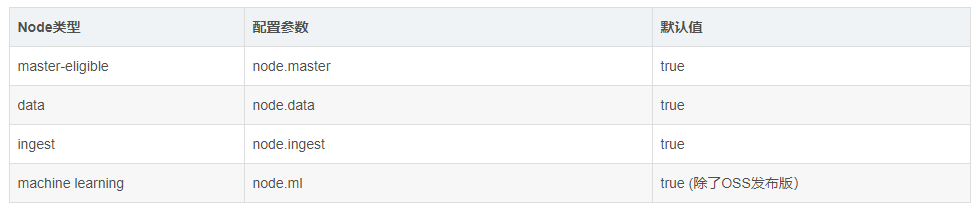
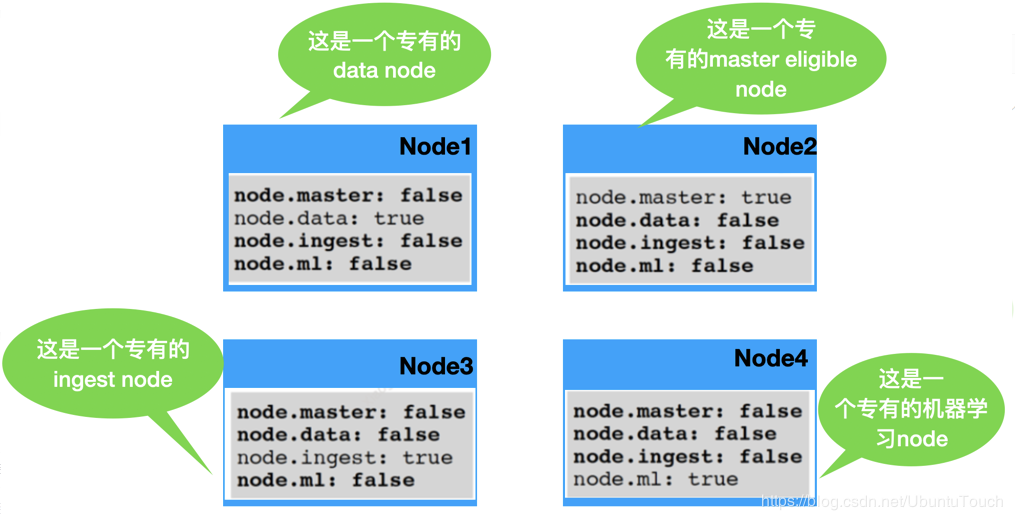
根据node的作用,可以分为如下的几种:
- master-eligible:可以作为主node。一旦成为主node,它可以管理整个cluster的设置及变化:创建,更新,删除index;添加或删除node;为node分配shard
- data:数据node
- ingest: 数据接入(比如 pipepline)
- machine learning (Gold/Platinum License)
一般来说,一个node可以具有上面的一种或几种功能。我们可以在命令行或者Elasticsearch的配置文件(Elasticsearch.yml)来定义:
也可以让一node做专有的功能及角色。如果上面node配置参数没有任何配置,那么我们可以认为这个node是作为一个Coordinating node。在这种情况下,它可以接受外部的请求,并转发到相应的节点来处理。
在实际的使用中,我们可以把请求发送给data节点,而不能发送给master节点。
我们可以通过对elasticsearch.yml文件中配置来定义一个node在集群中的角色:
在有些情况中,我们可以通过设置node.voting_only为true从而使得一个node在node.master为真的情况下,只作为参加voting的功能,而不当选为master node。这种情况为了避免脑裂情况发生。它通常可以使用一个CPU性能较低的node来担当。
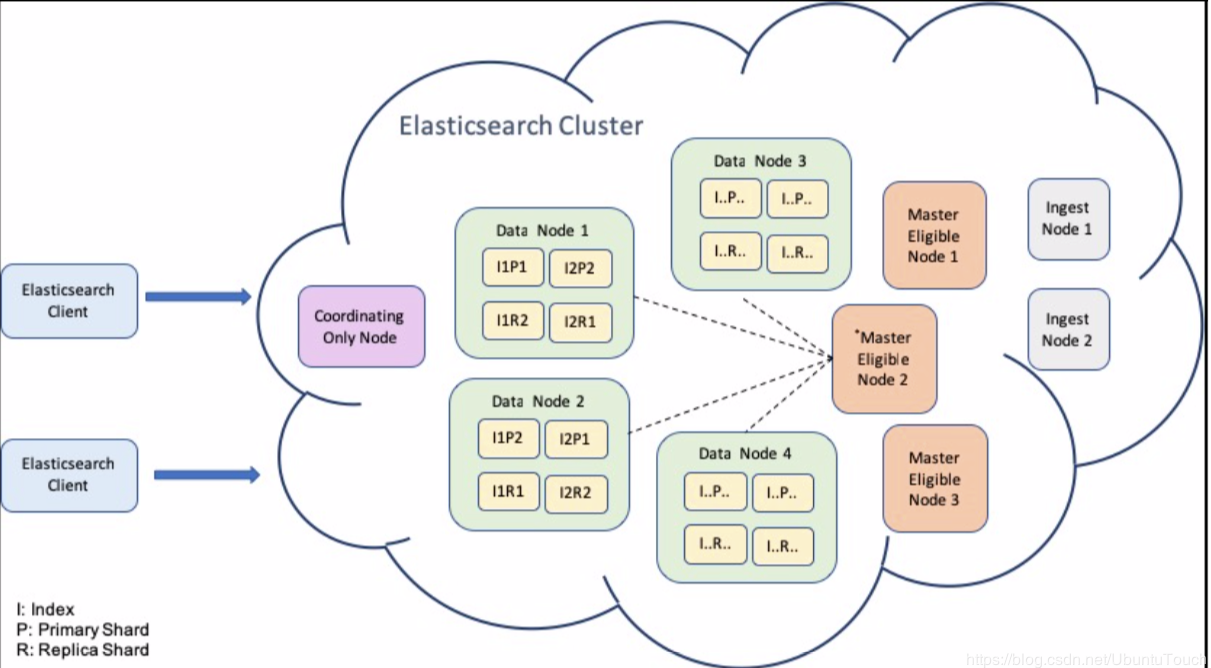
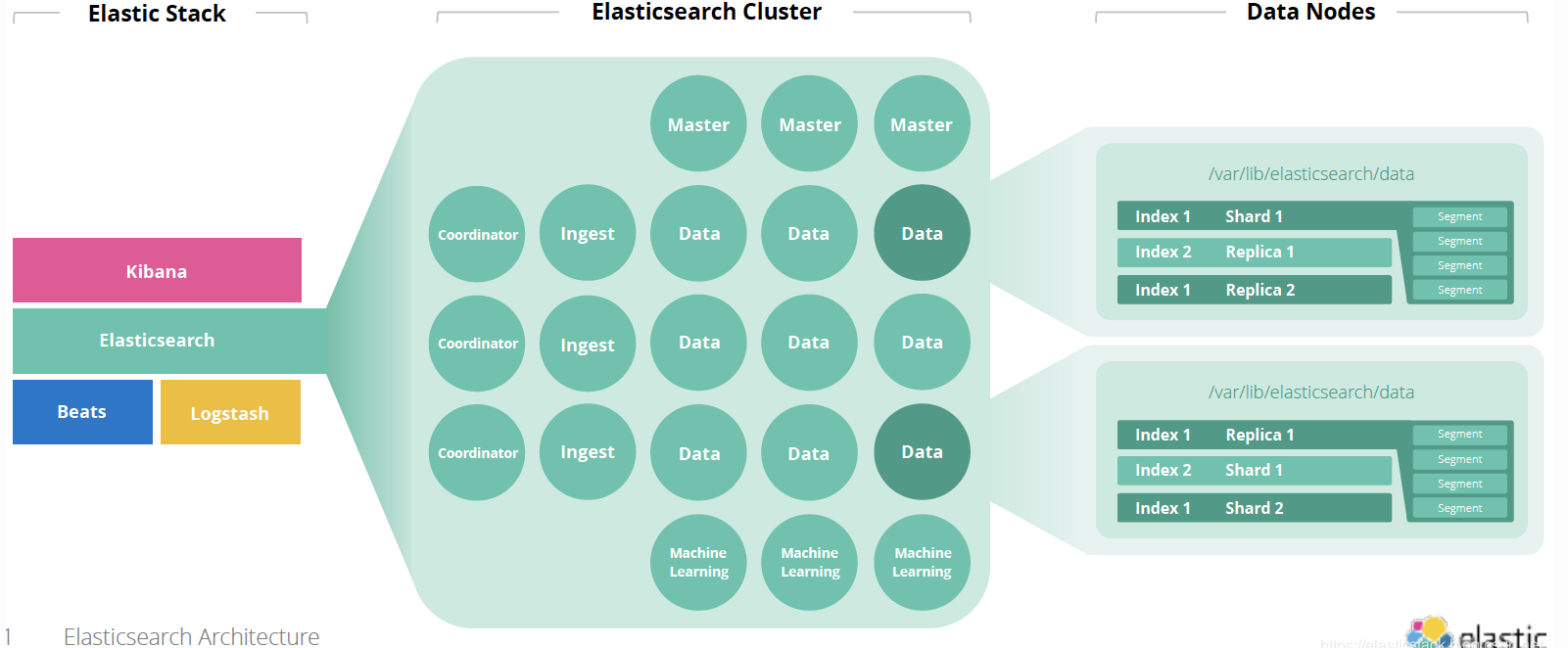
在整个Elastic的架构中,Data Node和Cluster的关系表述如下:
Document
Elasticsearch是面向文档的,这意味着您索引或搜索的最小数据单元是文档。文档在Elasticsearch中有一些重要的属性:
- 它是独立的。文档包含字段(名称)及其值。
- 它可以是分层的。可以将其视为文档中的文档。字段的值可以很简单,就像位置字段的值可以是字符串一样。它还可以包含其他字段和值。例如,位置字段可能包含城市和街道地址。
- 结构灵活。您的文档不依赖于预定义的架构。例如,并非所有事件都需要描述值,因此可以完全省略该字段。但它可能需要新的字段,例如位置的纬度和经度。
文档通常是数据的JSON表示形式。JSON over HTTP是与Elasticsearch进行通信的最广泛使用的方式.
很多人认为document相比较于关系数据库,它相应于其中每个record。

type
类型是文档的逻辑容器,类似于表是行的容器。 您将具有不同结构(模式)的文档放在不同类型中。 例如,您可以使用一种类型来定义聚合组,并在人们聚集时为事件定义另一种类型。
每种类型的字段定义称为映射。 例如,name将映射为字符串,但location下的geolocation字段将映射为特殊的geo_point类型。 (我们探讨如何使用附录A中的地理空间数据。)每种字段的处理方式都不同。 例如,您在名称字段中搜索单词,然后按位置搜索组以查找位于您居住地附近的组。
很多人认为Elasticsearch是schemaless的。大家都甚至认为Elasticsearch中的数据库是不需要mapping的。其实这是一个错误的概念。schemaless在Elasticsearch中正确的理解是,我们不需要事先定义一个类型关系数据库中的table才使用数据库。在Elasticsearch中,我们可以不开始定义一个mapping,而直接写入到我们指定的index中。这个index的mapping是动态生成的。其中的数据项的每一个数据类型是动态识别的。比如时间,字符串等,虽然有些的数据类型还是需要我们手动调整,比如geo_point等地理位置数据。另外,它还有一个含义,同一个type,我们在以后的数据输入中,可能增加新的数据项,从而生产新的mapping。这个也是动态调整的。
由于一些原因,在Elasticsearch 6.0以后,一个Index只能含有一个type。这其中的原因是:相同index的不同映射type中具有相同名称的字段是相同; 在Elasticsearch索引中,不同映射type中具有相同名称的字段在Lucene中被同一个字段支持。在默认的情况下是_doc。在未来8.0的版本中,type将被彻底删除。
index
在Elasticsearch中,索引是文档的集合。
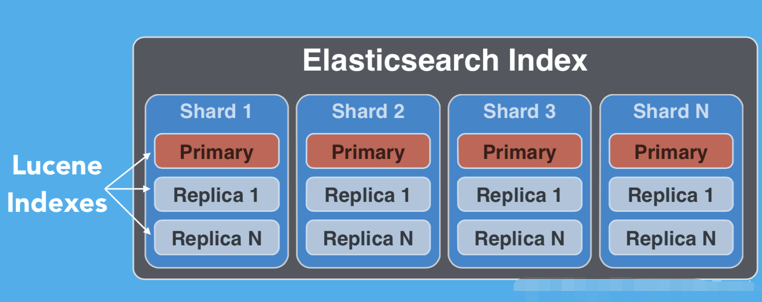
每个Index是有一个或许多的documents组成,并且这些document可以分布于不同的shard之中。
很多人认为index类似于关系数据库中的database。这中说法是有些道理,但是并不完全相同。其中很重要的一个原因是,在Elasticsearch中的文档可以有object及nested结构。一个index是一个逻辑命名空间,它映射到一个或多个主分片,并且可以具有零个或多个副本分片。
每当一个文档进来后,根据文档的id会自动进行hash计算,并存放于计算出来的shard实例中,这样的结果可以使得所有的shard都比较有均衡的存储,而不至于有的shard很忙。
shard_num = hash(_routing) % num_primary_shards
在默认的情况下,上面的_routing既是文档的_id。如果有routing的参与,那么这些文档可能只存放于一个特定的shard,这样的好处是对于一些情况,我们可以很快地综合我们所需要的结果而不需要跨node去得到请求。
从上面的公式我们也可以看出来,我们的shard数目是不可以动态修改的,否则之后也找不到相应的shard号码了。必须指出的是,replica的数目是可以动态修改的。
shard
由于Elasticsearch是一个分布式搜索引擎,因此索引通常会拆分为分布在多个节点上的称为分片的元素。 Elasticsearch自动管理这些分片的排列。 它还根据需要重新平衡分片,因此用户无需担心细节。
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片(shard)。当你创建一个索引的时候,你可以指定你想要的分片(shard)的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片之所以重要,主要有两方面的原因:
- 允许你水平分割/扩展你的内容容量
- 允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量
有两种类型的分片:primary shard和replica shard。
- Primary shard: 每个文档都存储在一个Primary shard。 索引文档时,它首先在Primary shard上编制索引,然后在此分片的所有副本上(replica)编制索引。索引可以包含一个或多个主分片。 此数字确定索引相对于索引数据大小的可伸缩性。 创建索引后,无法更改索引中的主分片数。
- Replica shard: 每个主分片可以具有零个或多个副本。 副本是主分片的副本,有两个目的:
- 增加故障转移:如果主要故障,可以将副本分片提升为主分片
- 提高性能:get和search请求可以由主shard或副本shard处理。
默认情况下,每个主分片都有一个副本,但可以在现有索引上动态更改副本数。 永远不会在与其主分片相同的节点上启动副本分片。
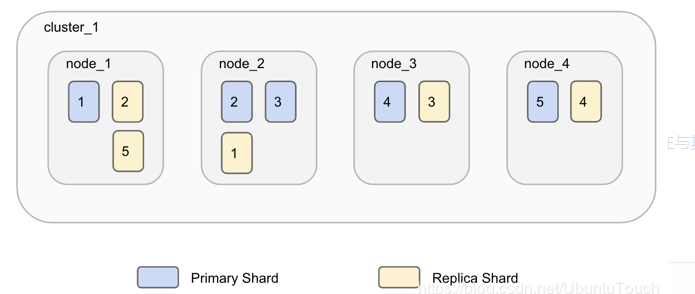
下面的图表示的是一个index有5个shard及1个replica:
可以为每个index设置相应的shard数值:
curl -XPUT http://localhost:9200/another_user?pretty -H 'Content-Type: application/json' -d '
{
"settings" : {
"index.number_of_shards" : 2,
"index.number_of_replicas" : 1
}
}
比如在上面的 REST接口中,我们为another_user这个index设置了2个shards,并且有一个replica。一旦设置好shard的数量,我们就不可以修改了。这是因为Elasticsearch会已经这个数量,会依据每个document的id及shard的数量来把相应的document分配到相应的shard中。如果这个数量以后修改的话,那么每次搜索的时候,可能会找不到相应的shard。
replica
默认情况下,Elasticsearch为每个索引创建一个主分片和一个副本。这意味着每个索引将包含一个主分片,每个分片将具有一个副本。
分配多个分片和副本是分布式搜索功能设计的本质,提供高可用性和快速访问索引中的文档。主副本和副本分片之间的主要区别在于只有主分片可以接受索引请求。副本和主分片都可以提供查询请求。
在上图中,我们有一个Elasticsearch集群,由默认分片配置中的两个节点组成。 Elasticsearch自动排列分割在两个节点上的五个主分片。有一个副本分片对应于每个主分片,但这些副本分片的排列与主分片的排列完全不同。再次,思考分配。
请允许我们澄清一下:请记住,number_of_shards值与索引有关,而不是与整个群集有关。此值指定每个索引的分片数(不是群集中的主分片总数)。
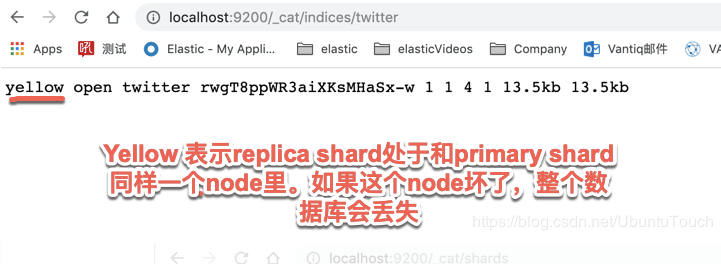
可以通过如下的接口来获得一个index的健康情况:
http://localhost:9200/_cat/indices/twitter
上面的接口可以返回如下的信息:
http://localhost:9200/_cat/shards
更进一步的查询,我们可以看出:
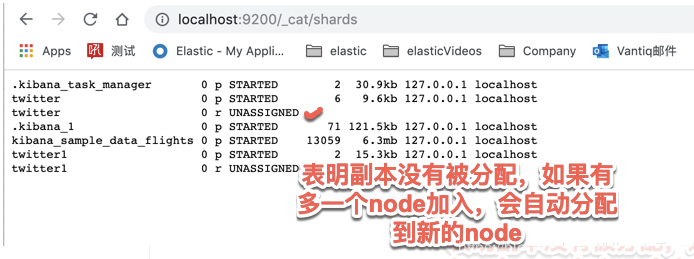
如果一个index显示的是红色,表面这个index至少有一个primary shard没有被正确分配,并且有的shard及其相应的replica已经不能正常访问。
如果是绿色,表明index的每一个shard都有备份,并且其备份也成功复制在相应的replica shard之中。如果其中的一个node坏了,相应的另外一个node的replica或其primary shard将起作用,从而不会造成数据的丢失。
shard 健康:
- 红色:集群中未分配至少一个主分片
- 黄色:已分配所有主副本,但未分配至少一个副本
- 绿色:分配所有分片
Elasticsearch中的一些重要概念:cluster, node, index, document, shards及replica的更多相关文章
- elasticsearch中的几个概念总结
1.Geo spatial search : 地理空间搜索,可以在搜索查询中指定的某一距离内查找所要的内容.也可以返回以当前为圆心,逐渐添加圆的半径.直到找到所匹配到的内容. 參考:http://ww ...
- 002 elasticsearch中的一些概念
在本文中,主要是ES7中的核心概念. ElasticSearch是一个实时分布式开源全文搜索和分析引擎.它可以从RESTful网络服务接口访问,并使用无模式JSON (JavaScript对象符号)文 ...
- 【分布式搜索引擎】Elasticsearch中的基本概念
一.Elasticsearch中的基本概念 以下概念基于这个例子:存储员工数据,每个文档代表一个员工 1)索引(index) 在Elasticsearch中存储数据的行为就叫做索引(indexing ...
- Elasticsearch 在 7.X版本中去除type的概念
背景说明 Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎.无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进.性能最好的.功能最全的搜索引擎库. El ...
- Elasticsearch 为何要在 7.X版本中 去除type 的概念
背景说明 Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎.无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进.性能最好的.功能最全的搜索引擎库. El ...
- Elasticsearch学习之基本核心概念
在Elasticsearch中有许多术语和概念 1. 核心概念 Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包 ...
- ElasticSearch(二)核心概念
elasticsearch核心概念 (1)Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒):基于es执行搜索和分析可以达到秒级 (2)Clu ...
- WebLogic中的一些基本概念
WebLogic中的一些基本概念 WebLogic 中的基本概念 上周参加了单位组织的WebLogic培训,为了便于自己记忆,培训后,整理梳理了一些WebLogic的资料,会陆续的发出来,下面是一 ...
- ELASTICSEARCH 中暂时移除一个节点
ELASTICSEARCH 中暂时移除一个节点 版权声明 本站原创文章 由 萌叔 发表 转载请注明 萌叔 | http://vearne.cc 前言 在维护ES集群的过程中,我们会经常遇到将某个ES实 ...
随机推荐
- HMS Core安全检测服务如何帮助大学新生防范电信诈骗?
一年一度的高考结束了,很多学生即将离开父母,一个人踏入大学生活,但由于人生阅历较少,容易被不法分子盯上. 每年开学季也是大一新生遭受诈骗的高峰期,以下是一些常见的案例.有的骗子会让新生下载注册一些恶意 ...
- 查询postgresql表结构和索引
通过系统数据字典查询表结构 selectcol.table_schema,col.table_name,col.ordinal_position,col.column_name,col.data_ty ...
- 06 MySQL_数据冗余
数据冗余--拆分表 如果表设计不合理,可能会出现大量的重复数据,这种现象被称为数据冗余,通过拆分表的形式可以解决此问题 保存集团总部下财务部里面的财务A部的张三工资8000 年龄18 保存集团总部下研 ...
- 多人共用一个Linux用户, 实现Bash配置文件独立
本文中提到的 账户, 用户 均表示同一概念. 例如 ssh wbourne@192.168.xxx.101, 账户, 用户 指的均是 wbourne. 背景 在工作中, 我们经常会连接Linux服务器 ...
- github碰到的问题
下载问题 自己编译一下 mvn clear mvn compile mvn package 自己编译之后的文件,然后解压即可,第一次自己傻傻的,直接用源码跑,少报错! 项目预览问题 添加1s即可 下载 ...
- 基于gRPC编写golang简单C2远控
概述 构建一个简单的远控木马需要编写三个独立的部分:植入程序.服务端程序和管理程序. 植入程序是运行在目标机器上的远控木马的一部分.植入程序会定期轮询服务器以查找新的命令,然后将命令输出发回给服务器. ...
- 基于mpvue的框架开发微信小程序(搭建环境)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_103 美团很早就开源了mpvue这个项目,如此看来,美团可不仅仅是一家团购网站,真正的技术驱动型企业,使得我们多了一种用来开发微信 ...
- 小白之Python基础(一)
一.数字类型: 1.整形 十进制:默认为十进制:(如:99,100.......) 十六进制: 0x,0X开头的表示16进制数 二进制:0b,0B开头的表示2进制数 八进制: 0o,0O开头的表示8进 ...
- vue-cli 启动项目时空白页面
vue-cli 启动项目时空白页面 在启动项目时 npm run serve / npm run dev 启动 vue 项目空白页:且终端及控制台都未报错 通过各种查阅发现在项目根目录中 vue-co ...
- Apache SeaTunnel (Incubating) 2.1.0 发布,内核重构、全面支持 Flink
2021 年 12 月 9 日,SeaTunnel (原名 Waterdrop) 成功加入 Apache 孵化器,进入孵化器后,SeaTunnel 社区花费了大量时间来梳理整个项目的外部依赖以确保整个 ...