scrapy操作mysql/批量下载图片
1.操作mysql
items.py

meiju.py
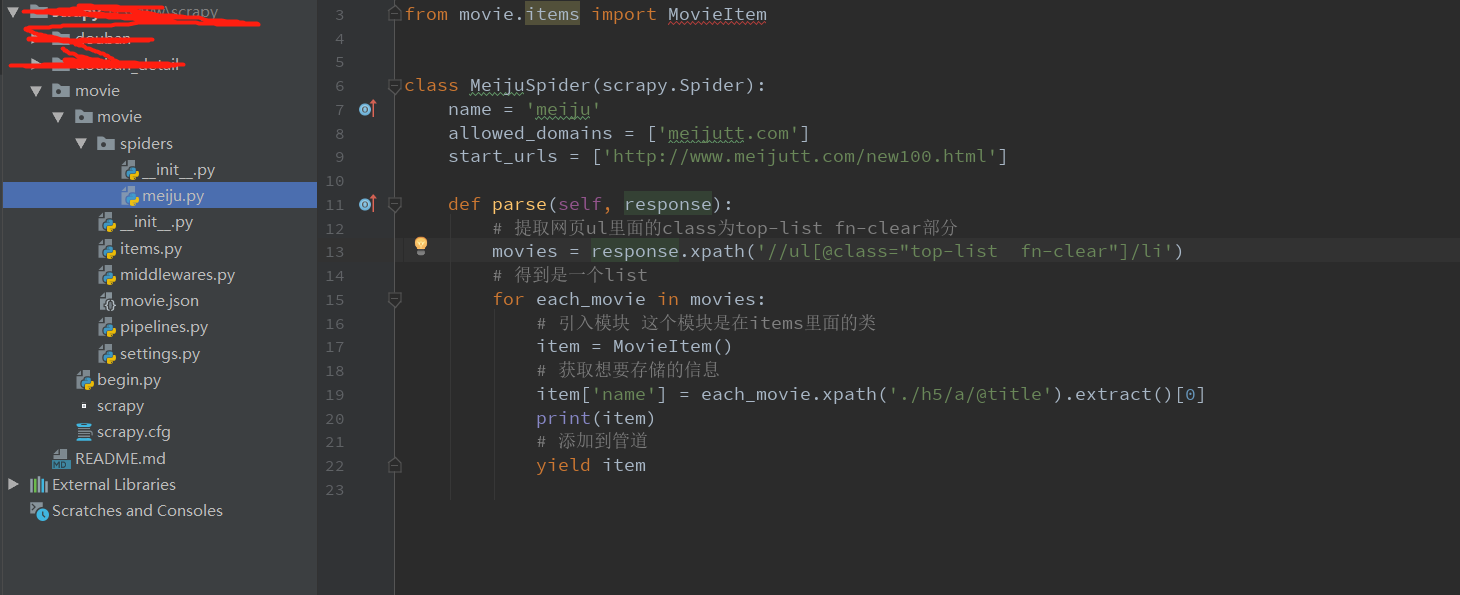
3.piplines.py

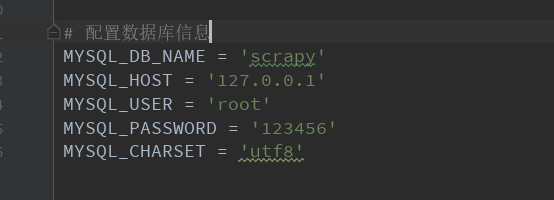
4.settings.py
--------------------------------------------------------------------------------------------------------------------------
批量下载图片。分类
网站:https://movie.douban.com/top250
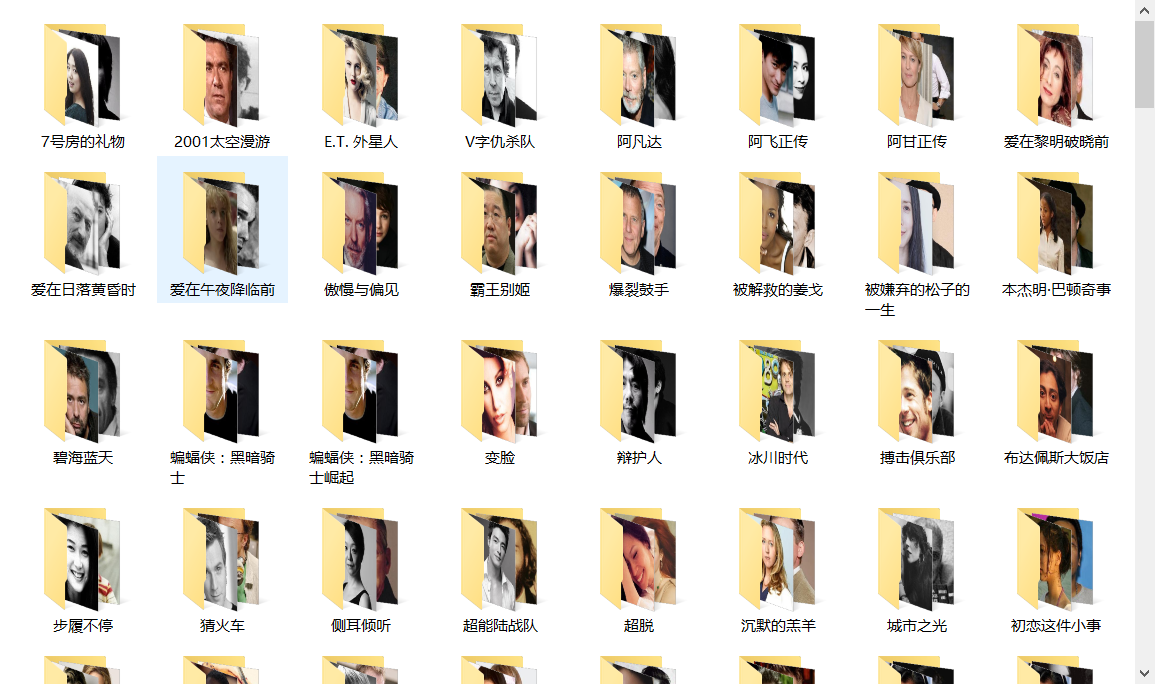
需求:按电影分类,获取里面的演职员图片。并存入各自的分类当中
效果:
代码
因为我们主要工作是下载。不存入数据库。存入数据库的话可以参考上面部分。
现在只需要修改spiders/xxx_spiders.py文件。就是开启项目适合生成的文件
我的是这个
以下是这个文件夹的代码。
# -*- coding: utf-8 -*-
import scrapy
import os
import urllib.request
import re class DoubanDetailSpidersSpider(scrapy.Spider):
name = 'douban_detail_spiders'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250'] file_path = "D:\\www\\scrapy\\douban_detail\\image\\" def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li") for i_item in movie_list:
# 封面图
master_pic_path = i_item.xpath(".//div[@class='pic']//a//img/@src").extract_first()
# 文件名
name = i_item.xpath(".//div[@class='info']//a/span[1]/text()").extract_first()
# 创建文件夹
self.fileIsBeing(name)
# 详情连接
detail_url = i_item.xpath(".//div[@class='hd']//a/@href").extract_first()
# 获取详情里面内容
# detail_link = response.xpath(".//div[@class='hd']//a/@href").extract()
# for link in detail_link:
# 这里是进入二级页面操作,在for循环里面。
yield scrapy.Request(detail_url, meta={'name': name}, callback=self.detail_parse, dont_filter=True) # 解析下一页
next_link = response.xpath("//div[@class='article']//div[@class='paginator']//span[@class='next']/link/@href").extract()
print(next_link)
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250" + next_link, callback=self.parse) # 判断文件是否存在
# 不存在则创建
def fileIsBeing(self, name):
path = self.file_path + name
bool = os.path.exists(path)
if not(bool):
os.mkdir(path)
return path # 解析详情里面的数据 获取二级页面内容操作。主要获取图片
def detail_parse(self, response):
name = response.meta['name']
print(name)
movie_prople_list = response.xpath("//div[@id='celebrities']//ul[@class='celebrities-list from-subject __oneline']//li")
for i_mov_item in movie_prople_list:
background_img = i_mov_item.xpath(".//div[@class='avatar']/@style").extract_first()
user_name = i_mov_item.xpath(".//div[@class='info']//a/@title").extract_first()
img_file_name = "%s.jpg" % user_name # 工作人员
img_url = self.txt_wrap_by('(', ')', background_img) # 图片地址
print(img_file_name)
file_path = os.path.join(self.file_path+name, img_file_name)
urllib.request.urlretrieve(img_url, file_path)
# print(img_file_name) # 截取字符串中间部分
def txt_wrap_by(self, start_str, end, html):
start = html.find(start_str)
if start >= 0:
start += len(start_str)
end = html.find(end, start)
if end >= 0:
return html[start:end].strip()
码云:https://gitee.com/chenrunxuan/scrapy
scrapy操作mysql/批量下载图片的更多相关文章
- scrapy批量下载图片
# -*- coding: utf-8 -*- import scrapy from rihan.items import RihanItem class RihanspiderSpider(scra ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 【Python】nvshens按目录批量下载图片爬虫1.00(单线程版)
# nvshens按目录批量下载图片爬虫1.00(单线程版) from bs4 import BeautifulSoup import requests import datetime import ...
- javaWeb 批量下载图片
批量下载网页图片 CreateTime--2017年9月26日15:40:43 Author:Marydon 所用技术:javascript.java 测试浏览器:chrome 开发工具:Ecli ...
- C++ 根据图片url 批量 下载图片
最近需要用到根据图片URL批量下载到本地的操作.查找了相关资料,记录在这儿. 1.首先在CSV文件中提取出url ifstream fin("C:\\Users\\lenovo\\Deskt ...
- 用python批量下载图片
一 写爬虫注意事项 网络上有不少有用的资源, 如果需要合理的用爬虫去爬取资源是合法的,但是注意不要越界,前一阶段有个公司因为一个程序员写了个爬虫,导致公司200多个人被抓,所以先进入正题之前了解下什么 ...
- python——批量下载图片
前言 批量下载网页上的图片需要三个步骤: 获取网页的URL 获取网页上图片的URL 下载图片 例子 from html.parser import HTMLParser import urllib.r ...
- 利用Node 搭配uglify-js压缩js文件,批量下载图片到本地
Node的便民技巧-- 压缩代码 下载图片 压缩代码 相信很多前端的同学都会在上线前压缩JS代码,现在的Gulp Webpack Grunt......都能轻松实现.但问题来了,这些都不会,难道就要面 ...
- scrapy中的ImagePipeline下载图片到本地、并提取本地的保存地址
通过scrapy内置到ImagePipeline下载图片到本地 在settings中打开 ITEM_PIPELINES的注释,并在这里面加入 'scrapy.pipelines.images.Imag ...
随机推荐
- MybatisPlus——实现多数据源操作
多数据源 适用:一般工作时候会有多个数据库,每个库对应不同的业务数据.程序如果每次数据都访问同一个数据库,该数据库压力很大访问会很慢. 官方文档:https://baomidou.com/(建议多看看 ...
- 逻辑判断与if and while循环结构
逻辑判断与if and while循环结构 逻辑判断 逻辑运算符在进行逻辑判断时遇到打印输出命令时 and 当碰到一个条件为False时那么整个条件即为False,当碰到第一个为True时如果之后的值 ...
- mybatisplus-sql注入器
sql注入器 使用mybatisplus只需要继承BaseMapper接口即可使用:但是有新的需求需要扩展BaseMapper里面的功能时可使用sql注入器. 扩展BaseMapper里面的功能 点击 ...
- 基于Anacoda搭建虚拟环境cudnn6.0+cuda8.0+python3.6+tensorflow-gpu1.4.0
!一定要查准cudnn,cuda,tensorflow-gpu对应的版本号再进行安装,且本文一切安装均在虚拟环境中完成. 下文以笔者自己电脑为例,展开安装教程阐述(省略anaconda安装教程): 1 ...
- 青源Talk第8期|苗旺:因果推断,观察性研究和2021年诺贝尔经济学奖
biobank 英国的基金数据因果推断和不同的研究互相论证,而非一个研究得到的接了就行.数据融合,data fusion,同一个因果问题不同数据不同结论,以及历史上的数据,来共同得到更稳健.更高效的推 ...
- vscode 快速注释和撤回快捷键
好家伙,天天忘,建议先练个十遍上手 1.快捷行注释 Ctrl + / 2.快捷块注释 Alt + Shift + A 3.撤回 Ctrl + Z 4.恢复撤回(撤回你的撤回) Ctrl + Shift ...
- kingbaseES V8R3数据安全案例之---审计记录清除案例
案例说明: 对于KingbaseES V8R3数据库,默认用户无权限删除审计记录,只有对审计记录做了转储以后会自动清理审计记录. 适用版本: KingbaseES V8R3 本案例数据库版本: S ...
- KingbaseES 数据库Windows环境下注册失败分析
关键字: KingbaseES.Java.Register.服务注册 一.安装前准备 1.1 软件环境要求 金仓数据库管理系统KingbaseES V8.0支持微软Windows 7.Windows ...
- 【读书笔记】C#高级编程 第五章 泛型
(一)泛型概述 泛型不仅是C#编程语言的一部分,而且与程序集中的IL代码紧密地集成.泛型不仅是C#语言的一种结构,而且是CLR定义的.有了泛型就可以创建独立于被包含类型的类和方法了. 1.性能 泛型的 ...
- 第一篇博客:HTML:background的使用
开篇 我是一名程序员小白,这是我写的第一篇博客,在学习的路上难免会遇到难以解决的问题,我将会在这里写下我遇到的问题并附上解决方法 希望可以对各位有所帮助!! 我们在html中经常会遇到这样的问题 例如 ...