【babel+小程序】记“编写babel插件”与“通过语法解析替换小程序路由表”的经历
话不多说先上图,简要说明一下干了些什么事。图可能太模糊,可以点svg看看
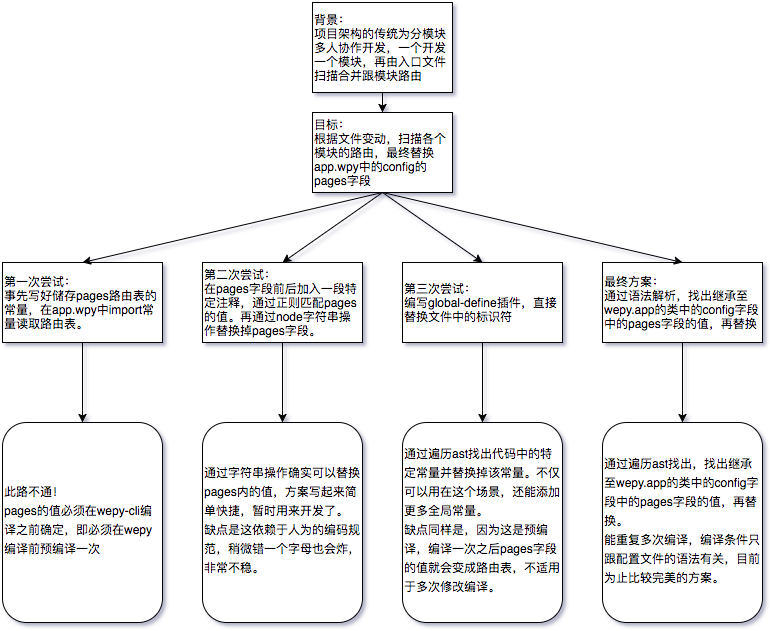
背景
最近公司开展了小程序的业务,派我去负责这一块的业务,其中需要处理的一个问题是接入我们web开发的传统架构--模块化开发。
我们来详细说一下模块化开发具体是怎么样的。
我们的git工作流采用的是git flow。一个项目会拆分成几个模块,然后一人负责一个模块(对应git flow的一个feature)独立开发。模块开发并与后端联通后再合并至develop进行集成测试,后续经过一系列测试再发布版本。
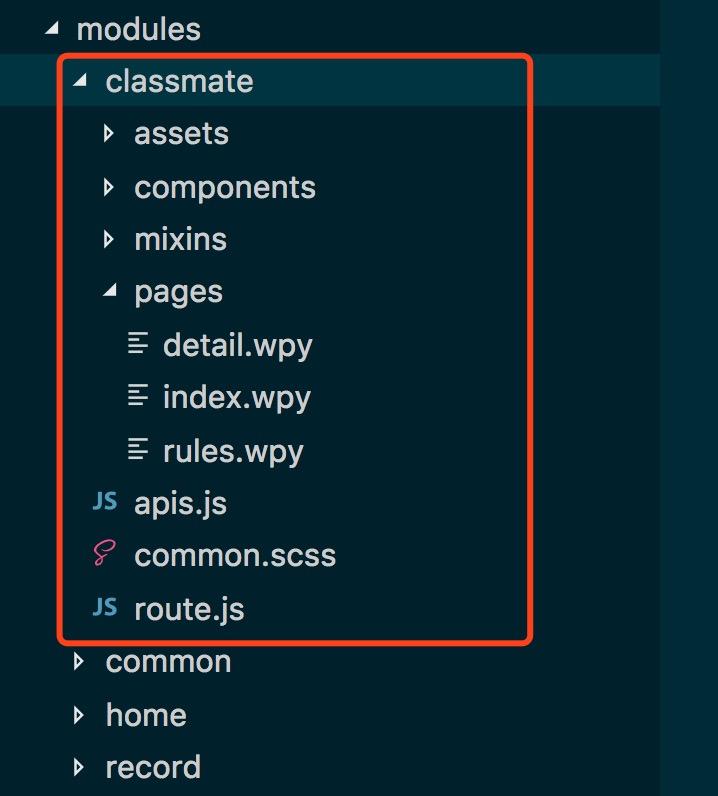
目录结构大体如图所示,一个模块包含了他自己的pages / components / assets / model / mixins / apis / routes / scss等等。
这种开发模式的好处不言而喻,每个人都可以并行开发,大大提升开发速度。这次就是要移植这种开发模式到小程序中。
目标
背景说完了,那么来明确一下我们的目标。
我采用的是wepy框架,类vue语法的开发,开发体验非常棒。在vue中,一个组件就是单文件,包含了js、html、css。wepy采用vue的语法,但由与vue稍稍有点区别,wepy的组件分为三种--wepy.app类,wepy.page类,wepy.component类。
对应到我们的目录结构中,每个模块实际上就是一系列的page组件。要组合这一系列的模块,那么很简单,我们要做的就是把这一系列page的路由扫描成一个路由表,然后插入到小程序的入口--app.json中。对应wepy框架那即是app.wpy中的pages字段。
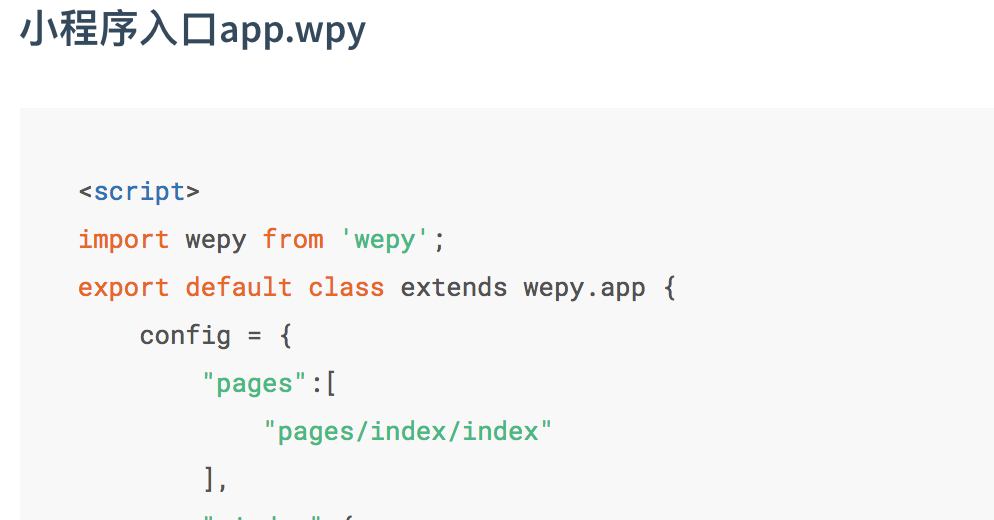
{kind=link}
扫描路由表
第一步!先得到所有pages的路由并综合成一个路由表!
我的方案是,在每个模块中新建一份routes文件,相当于注册每个需要插入到入口的page的路由,不需要接入业务的page就不用注册啦。是不是很熟悉呢,对的,就是参考vue-router的注册语法。
//routes.jsmodule.exports = [{name: 'home-detail',//TODO: name先占位,后续再尝试通过读name跳转某页page: 'detail',//需要接入入口的page的文件名。例如这里是index.wpy。相对于src/的路径就是`modules/${moduleName}/pages/index`。},{name: 'home-index',page: 'index',meta: {weight: 100//这里加了一个小功能,因为小程序指定pages数组的第一项为首页,后续我会通过这个权重字段来给pages路由排序。权重越高位置越前。}}]
而扫描各个模块并合并路由表的脚本非常简单,读写文件就ok了。
const fs = require('fs')const path = require('path')const routeDest = path.join(__dirname, '../src/config/routes.js')const modulesPath = path.join(__dirname, '../src/modules')let routes = []fs.readdirSync(modulesPath).forEach(module => {if(module.indexOf('.DS_Store') > -1) returnconst route = require(`${modulesPath}/${module}/route`)route.forEach(item => {item.page = `modules/${module}/pages/${item.page.match(/\/?(.*)/)[1]}`})routes = routes.concat(route)})fs.writeFileSync(routeDest,`module.exports = ${JSON.stringify(routes)}`, e => {console.log(e)})
路由排序策略
const strategies = {sortByWeight(routes) {routes.sort((a, b) => {a.meta = a.meta || {}b.meta = b.meta || {}const weightA = a.meta.weight || 0const weightB = b.meta.weight || 0return weightB - weightA})return routes}}
最后得出路由表
const Strategies = require('../src/lib/routes-model')const routes = Strategies.sortByWeight(require('../src/config/routes'))const pages = routes.map(item => item.page)console.log(pages)//['modules/home/pages/index', 'modules/home/pages/detail']
替换路由数组
So far so good...问题来了,如何替换入口文件中的路由数组。我如下做了几步尝试。
直接引入
我第一感觉就是,这不很简单吗?在wepy编译之前,先跑脚本得出路由表,再import这份路由表就得了。
import routes from './routes'export default class extends wepy.app {config = {pages: routes,//['modules/home/pages/index']window: {backgroundTextStyle: 'light',navigationBarBackgroundColor: '#fff',navigationBarTitleText: '大家好我是渣渣辉',navigationBarTextStyle: 'black'}}//...}
然而这样小程序肯定会炸啦,pages字段的值必须是静态的,在小程序运行之前就配置好,动态引入是不行的!不信的话诸君可以试试。那么就是说,划重点---我们必须在wepy编译之前再预编译一次---事先替换掉pages字段的值!
正则匹配替换
既然要事先替换,那就是要精准定位pages字段的值,然后再替换掉。难点在于如果精准定位pages字段的值呢?
最捞然而最快的方法:正则匹配。
事先定好编码规范,在pages字段的值的前后添加/* __ROUTES__ */的注释
脚本如下:
const fs = require('fs')const path = require('path')import routes from './routes'function replace(source, arr) {const matchResult = source.match(/\/\* __ROUTE__ \*\/([\s\S]*)\/\* __ROUTE__ \*\//)if(!matchResult) {throw new Error('必须包含/* __ROUTE__ */标记注释')}const str = arr.reduce((pre, next, index, curArr) => {return pre += `'${curArr[index]}', `}, '')return source.replace(matchResult[1], str)}const entryFile = path.join(__dirname, '../src/app.wpy')let entry = fs.readFileSync(entryFile, {encoding: 'UTF-8'})entry = replace(entry, routes)fs.writeFileSync(entryFile, entry)
app.wpy的变化如下:
//beforeexport default class extends wepy.app {config = {pages: [/* __ROUTE__ *//* __ROUTE__ */],window: {backgroundTextStyle: 'light',navigationBarBackgroundColor: '#fff',navigationBarTitleText: '大家好我是渣渣辉',navigationBarTextStyle: 'black'}}//...}//afterexport default class extends wepy.app {config = {pages: [/* __ROUTE__ */'modules/home/pages/index', /* __ROUTE__ */],window: {backgroundTextStyle: 'light',navigationBarBackgroundColor: '#fff',navigationBarTitleText: '大家好我是渣渣辉',navigationBarTextStyle: 'black'}}//...}
行吧,也总算跑通了。因为项目很赶,所以先用这个方案开发了一个半星期。开发完之后总觉得这种方案太难受,于是密谋着换另一种各精准的自动的方案。。。
babel插件替换全局常量
1.思路
想必大家肯定很熟悉这种模式
let host = 'http://www.tanwanlanyue.com/'if(process.env.NODE_ENV === 'production'){host = 'http://www.zhazhahui.com/'}
通过这种只在编译过程中存在的全局常量,我们可以做很多值的匹配。
因为wepy已经预编译了一层,在框架内的业务代码是读取不了process.env.NODE_ENV的值。我就想着要不做一个类似于webpack的DefinePlugin的babel插件吧。具体的思路是babel编译过程中访问ast时匹配需要替换的标识符或者表达式,然后替换掉相应的值。例如:
In
export default class extends wepy.app {config = {pages: __ROUTE__,window: {backgroundTextStyle: 'light',navigationBarBackgroundColor: '#fff',navigationBarTitleText: '大家好我是渣渣辉',navigationBarTextStyle: 'black'}}//...}
Out
export default class extends wepy.app {config = {pages: ['modules/home/pages/index',],window: {backgroundTextStyle: 'light',navigationBarBackgroundColor: '#fff',navigationBarTitleText: '大家好我是渣渣辉',navigationBarTextStyle: 'black'}}//...}
2.学习如何编写babel插件
在这里先要给大家推荐几份学习资料:
首先是babel官网推荐的这份迷你编译器的代码,读完之后基本能理解编译器做的三件事:解析,转换,生成的过程了。
其次是编写Babel插件入门手册。基本涵盖了编写插件的方方面面,不过由于babel几个工具文档的缺失,在写插件的时候需要去翻查代码中的注释阅读api用法。
然后是大杀器AST转换器--astexplorer.net。我们来看一下,babel的解析器--babylon的文档,涵盖的节点类型这么多,脑绘一张AST树不现实。我在编写脚本的时候会先把代码放在转换器内生成AST树,再一步一步走。
编写babel插件之前先要理解抽象语法树这个概念。编译器做的事可以总结为:解析,转换,生成。具体的概念解释去看入门手册可能会更好。这里讲讲我自己的一些理解。
解析包括词法分析与语法分析。
解析过程吧。其实按我的理解(不知道这样合适不合适= =)抽象语法树跟DOM树其实很类似。词法分析有点像是把html解析成一个一个的dom节点的过程,语法分析则有点像是将dom节点描述成dom树。
转换过程是编译器最复杂逻辑最集中的地方。首先要理解“树形遍历”与“访问者模式”两个概念。
“树形遍历”如手册中所举例子:
假设有这么一段代码:
function square(n) {return n * n;}
那么有如下的树形结构:
- FunctionDeclaration- Identifier (id)- Identifier (params[0])- BlockStatement (body)- ReturnStatement (body)- BinaryExpression (argument)- Identifier (left)- Identifier (right)
进入
FunctionDeclaration- 进入
Identifier (id) - 走到尽头
- 退出
Identifier (id) - 进入
Identifier (params[0]) - 走到尽头
- 退出
Identifier (params[0]) 进入
BlockStatement (body)进入
ReturnStatement (body)进入
BinaryExpression (argument)- 进入
Identifier (left) - 退出
Identifier (left) - 进入
Identifier (right) - 退出
Identifier (right)
- 进入
- 退出
BinaryExpression (argument)
- 退出
ReturnStatement (body)
- 退出
BlockStatement (body)
- 进入
“访问者模式”则可以理解为,进入一个节点时被调用的方法。例如有如下的访问者:
const idVisitor = {Identifier() {//在进行树形遍历的过程中,节点为标识符时,访问者就会被调用console.log("visit an Identifier")}}
结合树形遍历来看,就是说每个访问者有进入、退出两次机会来访问一个节点。
而我们这个替换常量的插件的关键之处就是在于,访问节点时,通过识别节点为我们的目标,然后替换他的值!
3.动手写插件
话不多说,直接上代码。这里要用到的一个工具是babel-types,用来检查节点。
难度其实并不大,主要工作在于熟悉如何匹配目标节点。如匹配memberExpression时使用matchesPattern方法,匹配标识符则直接检查节点的name等等套路。最终成品及用法可以见我的github
const memberExpressionMatcher = (path, key) => path.matchesPattern(key)//复杂表达式的匹配条件const identifierMatcher = (path, key) => path.node.name === key//标识符的匹配条件const replacer = (path, value, valueToNode) => {//替换操作的工具函数path.replaceWith(valueToNode(value))if(path.parentPath.isBinaryExpression()){//转换父节点的二元表达式,如:var isProp = __ENV__ === 'production' ===> var isProp = trueconst result = path.parentPath.evaluate()if(result.confident){path.parentPath.replaceWith(valueToNode(result.value))}}}export default function ({ types: t }){//这里需要用上babel-types这个工具return {visitor: {MemberExpression(path, { opts: params }){//匹配复杂表达式Object.keys(params).forEach(key => {//遍历Optionsif(memberExpressionMatcher(path, key)){replacer(path, params[key], t.valueToNode)}})},Identifier(path, { opts: params }){//匹配标识符Object.keys(params).forEach(key => {//遍历Optionsif(identifierMatcher(path, key)){replacer(path, params[key], t.valueToNode)}})},}}}
4.结果
当然啦,这块插件不可以写在wepy.config.js中配置。因为必须在wepy编译之前执行我们的编译脚本,替换pages字段。所以的方案是在跑wepy build --watch
之前跑我们的编译脚本,具体操作是引入babel-core来转换代码
const babel = require('babel-core')//...省略获取app.wpy过程,待会会谈到。//...省略编写visitor过程,语法跟编写插件略有一点点不同。const result = babel.transform(code, {parserOpts: {//babel的解析器,babylon的配置。记得加入classProperties,否则会无法解析app.wpy的类语法sourceType: 'module',plugins: ['classProperties']},plugins: [[{visitor: myVistor//使用我们写的访问者}, {__ROUTES__: pages//替换成我们的pages数组}],],})
当然最终我们是转换成功啦,这个插件也用上了生产环境。但是后来没有采用这方案替换pages字段。暂时只替换了__ENV__: process.env.NODE_ENV与__VERSION__: version两个常量。
为什么呢?
因为每次编译之后标识符__ROUTES__都会被转换成我们的路由表,那么下次我想替换的时候难道要手动删掉然后再加上__ROUTES__吗?我当然不会干跟我们自动化工程化的思想八字不合的事情啦。
不过写完这个插件之后收获还是挺大的,基本了解该如何通过编译器寻找并替换我们的目标节点了。
编写babel脚本识别pages字段
1.思路
- 首先获取到源代码:app.wpy是类vue单文件的语法。js都在script标签内,那么怎么获取这部分代码呢?又正则?不好吧,太捞了。通过阅读wepy-cli的源码,使用
xmldom这个库来解析,获取script标签内的代码。 - 编写访问者遍历并替换节点:首先是找到继承自
wepy.app的类,再找到config字段,最后匹配key为pages的对象的值。最后替换目标节点 - babel转换为代码后,通过读写文件替换目标代码。大业已成!done!
2.成果
最终脚本:
/*** @author zhazheng* @description 在wepy编译前预编译。获取app.wpy内的pages字段,并替换成已生成的路由表。*/const babel = require('babel-core')const t = require('babel-types')//1.引入路由const Strategies = require('../src/lib/routes-model')const routes = Strategies.sortByWeight(require('../src/config/routes'))const pages = routes.map(item => item.page)//2.解析script标签内的js,获取codeconst xmldom = require('xmldom')const fs = require('fs')const path = require('path')const appFile = path.join(__dirname, '../src/app.wpy')const fileContent = fs.readFileSync(appFile, { encoding: 'UTF-8' })let xml = new xmldom.DOMParser().parseFromString(fileContent)function getCodeFromScript(xml){let code = ''Array.prototype.slice.call(xml.childNodes || []).forEach(child => {if(child.nodeName === 'script'){Array.prototype.slice.call(child.childNodes || []).forEach(c => {code += c.toString()})}})return code}const code = getCodeFromScript(xml)// 3.在遍历ast树的过程中,嵌套三层visitor去寻找节点//3.1.找class,父类为wepy.appconst appClassVisitor = {Class: {enter(path, state) {const classDeclaration = path.get('superClass')if(classDeclaration.matchesPattern('wepy.app')){path.traverse(configVisitor, state)}}}}//3.2.找configconst configVisitor = {ObjectExpression: {enter(path, state){const expr = path.parentPath.nodeif(expr.key && expr.key.name === 'config'){path.traverse(pagesVisitor, state)}}}}//3.3.找pages,并替换const pagesVisitor = {ObjectProperty: {enter(path, { opts }){const isPages = path.node.key.name === 'pages'if(isPages){path.node.value = t.valueToNode(opts.value)}}}}// 4.转换并生成codeconst result = babel.transform(code, {parserOpts: {sourceType: 'module',plugins: ['classProperties']},plugins: [[{visitor: appClassVisitor}, {value: pages}],],})// 5.替换源代码fs.writeFileSync(appFile, fileContent.replace(code, result.code))
3.使用方法
只需要在执行wepy build --watch之前先执行这份脚本,就可自动替换路由表,自动化操作。监听文件变动,增加模块时自动重新跑脚本,更新路由表,开发体验一流~
结语
把代码往更自动化更工程化的方向写,这样的过程收获还是挺大的。但是确实这份脚本仍有不足之处,起码匹配节点这部分的代码是不大严谨的。
另外插播一份广告
我司风变科技正招聘前端开发:
- 应届、一年经验,熟悉Vue的前端小鲜肉
- 三年经验的前端大佬
我!们!都!想!要!
我们开发团队不仅代码写的好,而且男程序员还拥有着100%的脱单率!!快来加入我们吧!
邮箱:nicolas_refn@foxmail.com
【babel+小程序】记“编写babel插件”与“通过语法解析替换小程序路由表”的经历的更多相关文章
- Linux打包免安装的Qt程序(编写导出依赖包的脚本copylib.sh,程序启动脚本MyApp.sh)
本文介绍如何打包Qt程序,使其在没有安装Qt的系统可以运行. 默认前提:另外一个系统和本系统是同一个系统版本. 1,编写导出依赖包的脚本copylib.sh #!/bin/bash LibDir=$P ...
- 使用Qt编写模块化插件式应用程序
动态链接库技术使软件工程师们兽血沸腾,它使得应用系统(程序)可以以二进制模块的形式灵活地组建起来.比起源码级别的模块化,二进制级别的模块划分使得各模块更加独立,各模块可以分别编译和链接,模块的升级不会 ...
- 这款 IDE 插件再次升级,让「小程序云」的开发部署提速 8 倍
今年3月份,在阿里云北京峰会上,阿里巴巴正式发布了“阿里巴巴小程序繁星计划”,截至当前,已经有成千上万的开发者加入这个计划,使得小程序得到蓬勃发展,然而不可避免的是,这些服务加重了对云端的开发部署.运 ...
- 微信小程序开发--富文本插件wxParse的使用
昨天一位网友问我小程序怎么解析富文本.他尝试过把html转出小程序的组件,但是还是不成功,我说可以把内容剥离出来.但是这两种方法都是不行了.后来找到了wxParse-微信小程序富文本解析组件. 特性 ...
- Babel(1)认识Babel
阅读文档 Babel中文网 关于 Babel 你必须知道的 如何写好.babelrc?Babel的presets和plugins配置解析 不容错过的 Babel 7 知识汇总 一口(很长的)气了解 b ...
- 微信小程序全面实战,架构设计 && 躲坑攻略(小程序入门捷径教程)
最近集中开发了两款微信小程序,分别是好奇心日历(每天一条辞典+一个小投票)和好奇心日报(轻量版),直接上图: Paste_Image.png 本文将结合具体的实战经验,主要介绍微信小程序的基础知识.开 ...
- 【AST篇】教你如何编写 Eslint 插件
前言 虽然现在已经有很多实用的 ESLint 插件了,但随着项目不断迭代发展,你可能会遇到已有 ESLint 插件不能满足现在团队开发的情况.这时候,你需要自己来创建一个 ESLint 插件. 本文我 ...
- Go - 如何编写 ProtoBuf 插件(二)?
目录 前言 定义插件 使用插件 获取自定义选项 小结 推荐阅读 前言 上篇文章<Go - 如何编写 ProtoBuf 插件 (一) >,分享了使用 proto3 的 自定义选项 可以实现插 ...
- Go - 如何编写 ProtoBuf 插件 (三) ?
目录 前言 演示代码 小结 推荐阅读 前言 上篇文章<Go - 如何编写 ProtoBuf 插件 (二) >,分享了基于 自定义选项 定义了 interceptor 插件,然后在 hell ...
随机推荐
- cmd:WIN7操作系统下cmd窗口下的复制粘贴
1.右击cmd的顶部栏,点开属性 2.在 选项 下,勾选"快速编辑模式" 3.按住鼠标左键标注需要复制的区域 再点击一下右键,则上文的标记区域就已经被复制了,可以通过ctrl+v进 ...
- gvim 配置vimrc
##################################################################### normal setup################## ...
- Markdown语法浅学
typora语法使用 1.字体 *斜体*,_斜体_ **粗体** ***加粗斜体*** ~~删除线~~ <u>下划线</u> ***分割线 , --- 2.标题 # 一级标题 ...
- JZ-040-数组中只出现一次的数字
数组中只出现一次的数字 题目描述 一个整型数组里除了两个数字之外,其他的数字都出现了两次.请写程序找出这两个只出现一次的数字. 题目链接: 数组中只出现一次的数字 代码 /** * 标题:数组中只出现 ...
- 『现学现忘』Docker基础 — 13、通过脚本安装Docker
Docker官方提供方便用户操作的安装脚本,用起来是非常方便.但是要注意的是,使用脚本安装Docker,是安装最新版本的Docker. 注意:不建议在生产环境中使用安装脚本.因为在生产环境中一定不要最 ...
- Python:pyglet学习(1):想弄点3D,还发现了pyglet
某一天,我突然喜欢上了3D,在一些scratch教程中见过一些3D引擎,找了一个简单的,结果z轴太大了,于是网上一搜,就发现了pyglet 还是先讲如何启动一个窗口 先看看官网: Creating a ...
- python程序的三种执行结构
一.分支结构:根据条件判断的真假去执行不同分支对应的子代码 1.1 if判定 完整语法如下: if 条件1: #条件可以是任意表达式,如果条件1为True,则依次执行代码. 代码1 代码2 ... e ...
- Fiddler抓取https协议的证书导入过程
fildder抓取https的设置以及证书导出 打开fiddler界面,选择左上角菜单栏Tools-Options 出现Options界面后,选择HTTPS选项卡 勾选上Capture HTTPS C ...
- 【UML】统一建模语言及工具
共四个 Chapter,持续输出中. 参考资料: UML软件建模技术-基于IBM RSA工具(清华大学出版社) UML2.0基础与RSA建模实例教程(人民邮电) 面向对象葵花宝典(李运华)(电子工业出 ...
- maven——使用阿里云镜像
1.在本地的仓库目录下找到settings.xml文件,添加 <mirrors> <mirror> <id>alimaven</id> <name ...