MySQL Mock大量数据做查询响应测试
上个迭代版本发布后,生产环境业务同事反馈仓配订单查询的页面加载时间过长。
因为页面原来是有的,这次开发是在原来基础上改的,因此没有额外做性能。测试环境只调用接口请求了少量数据去验证功能。在对比该迭代添加功能后,定位到问题应该是这次新加的一些字段获取太慢了,当单日有数万条数据,都分别从中台不同接口去取数时,因为中台接口是单个订单查询,而不支持批量查询。开发同事于是用每个订单去分别请求这些不同接口,就发生了业务反馈的问题。有中台路由组的轨迹接口,有中台订单组的派前电联接口,订单组的订单状态接口,数据量大时请求过慢。
让开发同事写了个定时任务,每隔15分钟执行,将订单向中台发请求的结果返回的数据缓存到redis里做异步处理,然后在从redis取数,理论上就能解决该问题。在用redisDesktopManager验证订单请求结果拿到了以后,自己不放心,再mock了5w条数据简单看看页面查询和翻页性能。
下面记录下生成数据的部分,备将来再次使用。可以利用mysql内存表插入速度快的特点,先利用函数和存储过程在内存表中生成数据,然后再从内存表插入普通表中,这种方案插入数据是非常快的。
首先copy订单表的ddl,将ENGINE从InnoDB改成MEMORY,建一张内存表。
CREATE TABLE `o_order_main_memory` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '订单',
`order_id` varchar(50) COLLATE utf8mb4_bin DEFAULT '' COMMENT '订单号(货主单号)',
`waybill_no` varchar(50) COLLATE utf8mb4_bin DEFAULT '' COMMENT '运单号',
`client_id` varchar(50) COLLATE utf8mb4_bin DEFAULT '' COMMENT '客户id',
`order_time` datetime DEFAULT NULL COMMENT '下单时间',
`order_type` varchar(10) COLLATE utf8mb4_bin DEFAULT '' COMMENT ' ',
`order_carrier` varchar(50) COLLATE utf8mb4_bin DEFAULT '' COMMENT '承运商',
`order_status` int NOT NULL DEFAULT '0' COMMENT '-1-取消,0-待揽收,14-揽件, 9-始发分拨,18-出分拨,10-签收,,11-异常',
`sender_name` varchar(50) COLLATE utf8mb4_bin DEFAULT '' COMMENT '发件人',
`sender_phone` varchar(50) COLLATE utf8mb4_bin DEFAULT '' COMMENT '发件人手机号',
`sender_province_code` varchar(64) COLLATE utf8mb4_bin DEFAULT '' COMMENT '发货区域省份编码',
`sender_city_code` varchar(64) COLLATE utf8mb4_bin DEFAULT '' COMMENT '发货区域城市编码',
`sender_country_code` varchar(64) COLLATE utf8mb4_bin DEFAULT '' COMMENT '发货区域区县编码',
`sender_address` varchar(255) COLLATE utf8mb4_bin DEFAULT '' COMMENT '发件人地址',
`receive_name` varchar(50) COLLATE utf8mb4_bin DEFAULT '' COMMENT '收件人姓名',
`receive_phone` varchar(50) COLLATE utf8mb4_bin DEFAULT '' COMMENT '收件人手机号',
`receiver_province_code` varchar(64) COLLATE utf8mb4_bin DEFAULT '' COMMENT '收货区域省份编码',
`receiver_city_code` varchar(64) COLLATE utf8mb4_bin DEFAULT '' COMMENT '收货区域城市编码',
`receiver_country_code` varchar(64) COLLATE utf8mb4_bin DEFAULT '' COMMENT '收货区域区县编码',
`receive_address` varchar(255) COLLATE utf8mb4_bin DEFAULT '' COMMENT '收件人地址',
`warehouse_id` varchar(50) COLLATE utf8mb4_bin DEFAULT '' COMMENT '仓库id',
`gmt_create` datetime DEFAULT NULL COMMENT '创建时间',
`gmt_modified` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
`user_create` bigint DEFAULT NULL COMMENT '创建人',
`user_modified` bigint DEFAULT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `un_order_id` (`order_id`) USING BTREE
) ENGINE=MEMORY AUTO_INCREMENT=10000 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
————————————————
创建生成n个随机数字的函数
#生成n个随机数字
DELIMITER $$
CREATE FUNCTION randNum(n int) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str varchar(20) DEFAULT '0123456789';
DECLARE return_str varchar(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str = concat(return_str,substring(chars_str , FLOOR(1 + RAND()*10 ),1));
SET i = i +1;
END WHILE;
RETURN return_str;
END $$
DELIMITER;
————————————————
创建生成号码函数
#生成随机手机号码
# 定义常用的手机头 130 131 132 133 134 135 136 137 138 139 186 187 189 151 157
#SET starts = 1+floor(rand()*15)*4; 截取字符串的开始是从 1、5、9、13 ...开始的。floor(rand()*15)的取值范围是0~14
#SET head = substring(bodys,starts,3);在字符串bodys中从starts位置截取三位
DELIMITER $$
CREATE FUNCTION generatePhone() RETURNS varchar(20)
BEGIN
DECLARE head char(3);
DECLARE phone varchar(20);
DECLARE bodys varchar(100) default "130 131 132 133 134 135 136 137 138 139 186 187 189 151 157";
DECLARE starts int;
SET starts = 1+floor(rand()*15)*4;
SET head = trim(substring(bodys,starts,3));
SET phone = trim(concat(head,randNum(8)));
RETURN phone;
END $$
DELIMITER ;
————————————————
创建随机字符串函数
#创建随机字符串和随机时间的函数
DELIMITER $$
CREATE FUNCTION `randStr`(n INT) RETURNS varchar(255) CHARSET utf8mb4
DETERMINISTIC
BEGIN
DECLARE chars_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
DECLARE return_str varchar(255) DEFAULT '' ;
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str = concat(return_str, substring(chars_str, FLOOR(1 + RAND() * 62), 1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END$$
DELIMITER;
————————————————
创建插入内存表数据的存储过程
# 创建插入内存表数据存储过程 入参n是多少就插入多少条数据
DELIMITER $$
CREATE DEFINER=`dev`@`%` PROCEDURE `add_o_order_main_memory`(IN n int)
BEGIN
DECLARE i INT DEFAULT 300;
WHILE (i <= n) DO
INSERT into o_order_main_memory (id,order_id,waybill_no,client_id,order_time,order_type,order_carrier,order_status,sender_name,sender_phone,sender_province_code,sender_city_code,sender_country_code,sender_address,receive_phone,receiver_province_code,receiver_city_code,receiver_country_code,receive_address,warehouse_id,gmt_create,gmt_modified,user_create,user_modified) VALUEs (NULL,randStr(20),randNum(15),'SNERP001','2022-03-22 08:03:05','CAINIAO','YUNDA','0','张三',generatePhone(),'420000','420100','420112','上海市青浦区华新镇111号','李四',generatePhone(),'320000','320200','320282','江苏省盐城市射阳县四明镇222号','cangku004',now(),now(),'111','111');
SET i = i + 1;
END WHILE;
END $$
DELIMITER ;
————————————————
调用存储过程插入数据
#先调用存储过程往内存表插入一万条数据,然后再把内存表的一万条数据插入普通表
CALL add_o_order_main_memory(10000);
#一次性把内存表的数据插入到普通表,这个过程是很快的
INSERT into o_order_main SELECT * from o_order_main_memory;
#清空内存表数据
delete from o_order_main_memory;
————————————————
因为我没有更改数据库内存表内存大小,所以单次插入内存表一万条数据是没问题的,但是单次插入内存表十万条数据就不行了,会报内存表已满的异常。如下图所示
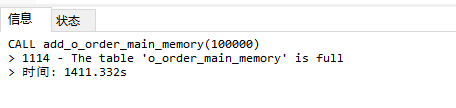
要么修改内存表存储大小,要么分批执行
方法一:
修改内存表存储大小
SET GLOBAL tmp_table_size=2147483648;
SET GLOBAL max_heap_table_size=2147483648;
方法二:
调用我写的另一个存储过程 add_o_order_main_memory_to_outside
这个存储过程就是通过不断循环插入内存表,再从内存表获取数据插入普通表,最后删除内存表,以此循环直至循环结束。
#循环100次,每次生成10000条数据 总共生成一百万条数据
CALL add_o_order_main_memory_to_outside(100,10000);
过程中遇到的一个问题
执行创建函数的sql语句时,提示:This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled
在MySQL中创建函数时出现这种错误的解决方法:
在mysql数据库中执行以下语句 (临时生效,重启后失效)
set global log_bin_trust_function_creators=TRUE;
MySQL Mock大量数据做查询响应测试的更多相关文章
- Oracle、MySql、SQLServer 数据分页查询
最近简单的对oracle,mysql,sqlserver2005的数据分页查询作了研究,把各自的查询的语句贴出来供大家学习..... (一). mysql的分页查询 mysql的分页查询是最简单的,借 ...
- 转Oracle、MySql、SQLServer 数据分页查询
最近简单的对oracle,mysql,sqlserver2005的数据分页查询作了研究,把各自的查询的语句贴出来供大家学习..... (一). mysql的分页查询 mysql的分页查询是最简单的,借 ...
- 提高MYSQL百万条数据的查询速度
提高MYSQL百万条数据的查询速度 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 nul ...
- Oracle、MySql、SQLServer数据分页查询
看过此博文后Oracle.MySql.SQLServer 数据分页查询,在根据公司的RegionRes表格做出了 SQLserver的分页查询语句: 别名.字段 FROM( SELECT row_nu ...
- MySql数据库列表数据分页查询、全文检索API零代码实现
数据条件查询和分页 前面文档主要介绍了元数据配置,包括表单定义和表关系管理,以及表单数据的录入,本文主要介绍数据查询和分页在crudapi中的实现. 概要 数据查询API 数据查询主要是指按照输入条件 ...
- MySQL多表数据记录查询详解
在实际应用中,经常需要实现在一个查询语句中显示多张表的数据,这就是所谓的多表数据记录连接查询,简称来年将诶查询. 在具体实现连接查询操作时,首先将两个或两个以上的表按照某个条件连接起来,然后再查询到所 ...
- mysql的大数据量的查询
mysql的大数据量查询分页应该用where 条件进行分页,limit 100000,100,mysql先查询100100数据量,查询完以后,将 这些100000数据量屏蔽去掉,用100的量,但是如果 ...
- 通过读取excel数据和mysql数据库数据做对比(二)-代码编写测试
通过上一步,环境已搭建好了. 下面开始实战, 首先,编写链接mysql的函数conn_sql.py import pymysql def sql_conn(u,pwd,h,db): conn=pymy ...
- mysql千万级测试1亿数据的分页分析测试
本文为本人最近利用几个小时才分析总结出的原创文章,希望大家转载,但是要注明出处 http://blog.sina.com.cn/s/blog_438308750100im0e.html 有什么问题可以 ...
- 大数据量查询容易OOM?试试MySQL流式查询
一.前言 程序访问 MySQL 数据库时,当查询出来的数据量特别大时,数据库驱动把加载到的数据全部加载到内存里,就有可能会导致内存溢出(OOM). 其实在 MySQL 数据库中提供了流式查询,允许把符 ...
随机推荐
- 上传镜像到harbor
https://blog.csdn.net/weixin_45335305/article/details/123817541
- [2010年NOIP普及组] 接水问题
学校里有一个水房,水房里一共装有 m 个龙头可供同学们打开水,每个龙头每秒钟的供水量相等,均为 1. 现在有 n 名同学准备接水,他们的初始接水顺序已经确定.将这些同学按接水顺序从1到n编号,i 号同 ...
- Android 系统完整的权限列表
访问登记属性 android.permission.ACCESS_CHECKIN_PROPERTIES ,读取或写入登记check-in数据库属性表的权限 获取错略位置 android.perm ...
- Typora的下载和MarkDown的相关操作
MarkDown 作为程序员就要会写blog(网络日记),那么怎么让你的笔记写的排版舒适清晰?我们可以通过MarkDown来写笔记 首先我们要下载Typora,因为现在官网的Typora要付费,所以可 ...
- 解决idea中按退格键(Backspace)回到上一行问题
开始学习java时,第一次用idea,该问题困扰一上午,网上也没有解决方案,最后自己摸索如下.打开File-> Settings->Editor->Smart Keys,将To pr ...
- protobuf协议 待整理
https://blog.51cto.com/wangjichuan/5691192 https://blog.csdn.net/lizhichao410/article/details/126032 ...
- Python 使用json存储数据
一.前言 很多程序都要求用户输入某种信息,如让用户存储游戏首选项或提供要可视化的数据.不管专注的是什么,程序都把用户提供的信息存储在列表和字典等数据结构中.用户关闭程序时,你几乎总是要保存他们提供的信 ...
- sync同步工具使用
sync详解 sync概述: rsync是一个提供快速增量文件传输的开源工具.rsync在GNU通用公共许可证下免费提供,目前由Wayne Davison维护.传输前进行压缩,适合做备份使用. 命令格 ...
- 洛谷P1203 坏掉的项链
洛谷P1203 坏掉的项链 首先看到这题的数据样例,3<=n<=350,不是水水暴搜就过了嘛 不难想到暴力解,先破环成链 因为可能有全部都可换成一种颜色的情况,考虑每次遇到s[i]==s[ ...
- ybtoj 12F
求值的话改为求解前缀和的值,通过两个前缀和相减即可得到每个值. 每次询问相当于给一个方程. 一共有 $n$ 个未知数,因此需要 $n$ 个方程,同时每个数都必须至少在方程中出现一次. 最小生成树求解即 ...