从GP6.0后,使用gpbackup命令来实现备份。但GP里是不自带的,需要自己重新下载并编译和安装。
一、安装
(1)master上go下载并配置profile环境变量
go下载地址 :https://go.dev/dl/
环境变量:
/etc/profile文件增加
export GOPATH=/data/tools/go
export PATH=$PATH:/data/tools/diskquota/build/cmake-3.25.1-linux-x86_64/bin:$GOPATH/bin
[root@gp-mdw bin]# go version
go version go1.19.4 linux/amd64
(2)下载gpbackup并编译
下载地址:https://github.com/greenplum-db/gpbackup
编译:
进入
make depend
make build
(3)编译完后在go环境下会发现编译产生的三个包
[root@gp-mdw bin]# ls -la
total 51776
drwxr-xr-x 2 gpadmin gpadmin 85 Dec 14 17:04 .
drwxr-xr-x 10 gpadmin gpadmin 222 Dec 2 02:16 ..
-rwxr-xr-x 1 gpadmin gpadmin 15308131 Dec 2 02:15 go
-rwxr-xr-x 1 gpadmin gpadmin 3386565 Dec 2 02:15 gofmt
-rwxr-xr-x 1 root root 14873102 Dec 14 17:04 gpbackup
-rwxr-xr-x 1 root root 6027034 Dec 14 17:04 gpbackup_helper
-rwxr-xr-x 1 root root 13414262 Dec 14 17:04 gprestore
[root@gp-mdw bin]# pwd
/data/tools/go/bin
[root@gp-mdw bin]#
二、使用
[root@gp-mdw bin]# gpbackup --help
gpbackup is the parallel backup utility for Greenplum
Usage:
gpbackup [flags]
Flags:
--backup-dir string The absolute path of the directory to which all backup files will be written 指定备份目录
--compression-level int Level of compression to use during data backup. Range of valid values depends on compression type (default 1)
--compression-type string Type of compression to use during data backup. Valid values are 'gzip', 'zstd' (default "gzip")
--copy-queue-size int number of COPY commands gpbackup should enqueue when backing up using the --single-data-file option (default 1)
--data-only Only back up data, do not back up metadata
--dbname string The database to be backed up 指定备份数据库
--debug Print verbose and debug log messages
--exclude-schema stringArray Back up all metadata except objects in the specified schema(s). --exclude-schema can be specified multiple times.
--exclude-schema-file string A file containing a list of schemas to be excluded from the backup
--exclude-table stringArray Back up all metadata except the specified table(s). --exclude-table can be specified multiple times.
--exclude-table-file string A file containing a list of fully-qualified tables to be excluded from the backup
--from-timestamp string A timestamp to use to base the current incremental backup off
--help Help for gpbackup
--include-schema stringArray Back up only the specified schema(s). --include-schema can be specified multiple times.
--include-schema-file string A file containing a list of schema(s) to be included in the backup
--include-table stringArray Back up only the specified table(s). --include-table can be specified multiple times.
--include-table-file string A file containing a list of fully-qualified tables to be included in the backup
--incremental Only back up data for AO tables that have been modified since the last backup
--jobs int The number of parallel connections to use when backing up data (default 1)
--leaf-partition-data For partition tables, create one data file per leaf partition instead of one data file for the whole table
--metadata-only Only back up metadata, do not back up data
--no-compression Skip compression of data files
--plugin-config string The configuration file to use for a plugin
--quiet Suppress non-warning, non-error log messages
--single-data-file Back up all data to a single file instead of one per table
--verbose Print verbose log messages
--version Print version number and exit
--with-stats Back up query plan statistics
--without-globals Skip backup of global metadata
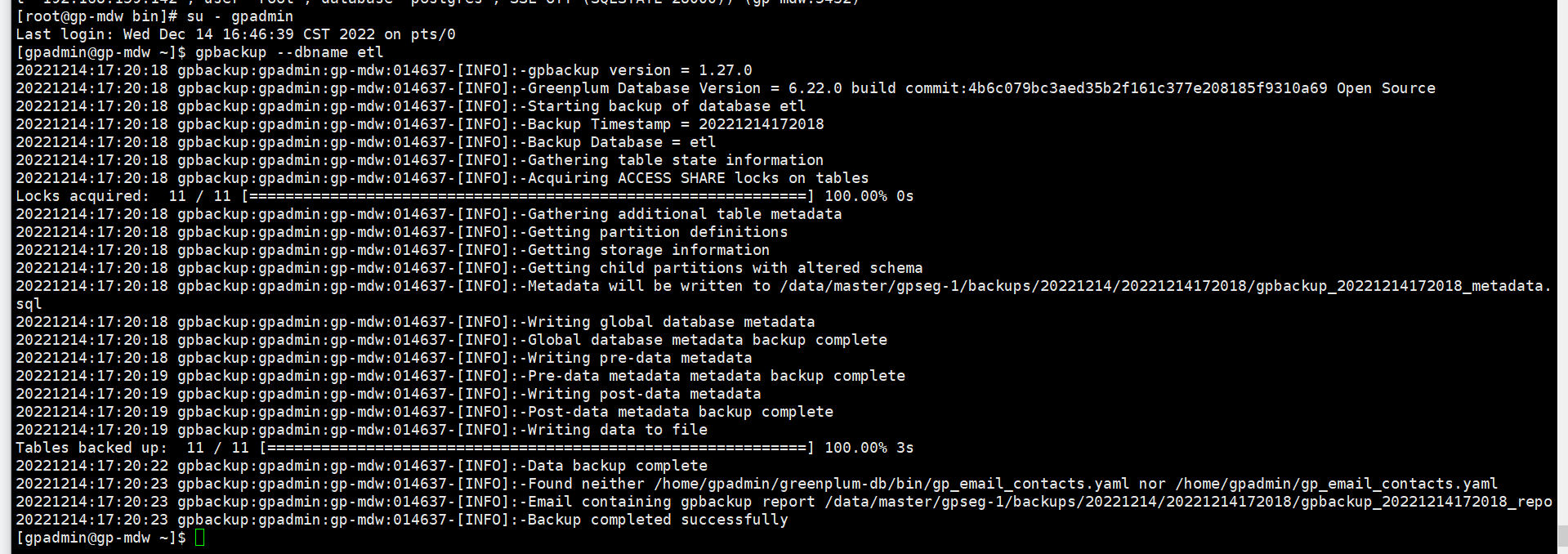
实验总结:
如果只指定数据库名称,会将这个数据库的所有对象都进行备份,例如:元数据、表数据、资源队列、资源组、角色等。
元数据存储在Master节点的
$MASTER_DATA_DIRECTORY/backups/YYYYMMDD/YYYYMMDDhhmmss/
20221214:17:20:18 gpbackup:gpadmin:gp-mdw:014637-[INFO]:-Metadata will be written to /data/master/gpseg-1/backups/20221214/20221214172018/gpbackup_20221214172018_metadata.sql
20221214:17:20:23 gpbackup:gpadmin:gp-mdw:014637-[INFO]:-Found neither /home/gpadmin/greenplum-db/bin/gp_email_contacts.yaml nor /home/gpadmin/gp_email_contacts.yaml
20221214:17:20:23 gpbackup:gpadmin:gp-mdw:014637-[INFO]:-Email containing gpbackup report /data/master/gpseg-1/backups/20221214/20221214172018/gpbackup_20221214172018_report
目录下,会生成4个文件,其中:config.yaml 记录gpbackup 运行时的参数配置项;report记录备份下来的数据库对象信息,主要是对象数量;toc.yaml 记录元数据之间的依赖关系;metadata.sql 记录表结构DDL的详细信息。
[gpadmin@gp-mdw 20221214172018]$ ll
total 28
-r--r--r-- 1 gpadmin gpadmin 949 Dec 14 17:20 gpbackup_20221214172018_config.yaml
-r--r--r-- 1 gpadmin gpadmin 6376 Dec 14 17:20 gpbackup_20221214172018_metadata.sql
-r--r--r-- 1 gpadmin gpadmin 1811 Dec 14 17:20 gpbackup_20221214172018_report
-r--r--r-- 1 gpadmin gpadmin 10147 Dec 14 17:20 gpbackup_20221214172018_toc.yaml
[gpadmin@gp-mdw 20221214172018]$ pwd
/data/master/gpseg-1/backups/20221214/20221214172018
[gpadmin@gp-mdw 20221214172018]$
[gpadmin@gp-mdw 20221214172018]$ cat gpbackup_20221214172018_config.yaml
backupdir: ""
backupversion: 1.27.0
compressed: true
compressiontype: gzip
databasename: etl
databaseversion: 6.22.0 build commit:4b6c079bc3aed35b2f161c377e208185f9310a69 Open
Source
segmentcount: 6
dataonly: false
datedeleted: ""
excluderelations: []
excludeschemafiltered: false
excludeschemas: []
excludetablefiltered: false
includerelations: []
includeschemafiltered: false
includeschemas: []
includetablefiltered: false
incremental: false
leafpartitiondata: false
metadataonly: false
plugin: ""
pluginversion: ""
restoreplan:
- timestamp: "20221214172018"
tablefqns:
- public.t1
- public.testdblink
- employees.department
- employees.department_employee
- employees.department_manager
- employees.employee
- employees.salary
- employees.title
- public.sales
- public.t2
- public.t3
singledatafile: false
timestamp: "20221214172018"
endtime: "20221214172023"
withoutglobals: false
withstatistics: false
status: Success
[gpadmin@gp-mdw 20221214172018]$ cat gpbackup_20221214172018_report
Greenplum Database Backup Report
timestamp key: 20221214172018
gpdb version: 6.22.0 build commit:4b6c079bc3aed35b2f161c377e208185f9310a69 Open Source
gpbackup version: 1.27.0
database name: etl
command line: gpbackup --dbname etl
compression: gzip
plugin executable: None
backup section: All Sections
object filtering: None
includes statistics: No
data file format: Multiple Data Files Per Segment
incremental: False
start time: Wed Dec 14 2022 17:20:18
end time: Wed Dec 14 2022 17:20:23
duration: 0:00:05
backup status: Success
database size: 464 MB
segment count: 6
count of database objects in backup:
aggregates 0
casts 0
collations 0
constraints 13
conversions 0
default privileges 0
database gucs 0
event triggers 0
extensions 0
foreign data wrappers 0
foreign servers 0
functions 0
indexes 2
operator classes 0
operator families 0
operators 0
procedural languages 0
protocols 0
resource groups 2
resource queues 1
roles 1
rules 0
schemas 2
sequences 1
tables 11
tablespaces 0
text search configurations 0
text search dictionaries 0
text search parsers 0
text search templates 0
triggers 0
types 2
user mappings 0
views 0
[gpadmin@gp-mdw 20221214172018]$ cat gpbackup_20221214172018_toc.yaml
globalentries:
- schema: ""
name: ""
objecttype: SESSION GUCS
referenceobject: ""
startbyte: 0
endbyte: 31
- schema: ""
name: pg_default
objecttype: RESOURCE QUEUE
referenceobject: ""
startbyte: 31
endbyte: 93
- schema: ""
name: admin_group
objecttype: RESOURCE GROUP
referenceobject: ""
startbyte: 93
endbyte: 149
- schema: ""
name: admin_group
objecttype: RESOURCE GROUP
referenceobject: ""
startbyte: 149
endbyte: 203
- schema: ""
name: default_group
objecttype: RESOURCE GROUP
referenceobject: ""
startbyte: 203
endbyte: 261
- schema: ""
name: default_group
objecttype: RESOURCE GROUP
referenceobject: ""
startbyte: 261
endbyte: 317
- schema: ""
name: default_group
objecttype: RESOURCE GROUP
referenceobject: ""
startbyte: 317
endbyte: 373
- schema: ""
name: default_group
objecttype: RESOURCE GROUP
referenceobject: ""
startbyte: 373
endbyte: 437
- schema: ""
name: default_group
objecttype: RESOURCE GROUP
referenceobject: ""
startbyte: 437
endbyte: 499
- schema: ""
name: default_group
objecttype: RESOURCE GROUP
referenceobject: ""
startbyte: 499
endbyte: 555
- schema: ""
name: default_group
objecttype: RESOURCE GROUP
referenceobject: ""
startbyte: 555
endbyte: 614
- schema: ""
name: admin_group
objecttype: RESOURCE GROUP
referenceobject: ""
startbyte: 614
endbyte: 669
- schema: ""
name: admin_group
objecttype: RESOURCE GROUP
referenceobject: ""
startbyte: 669
endbyte: 731
- schema: ""
name: admin_group
objecttype: RESOURCE GROUP
referenceobject: ""
startbyte: 731
endbyte: 791
- schema: ""
name: admin_group
objecttype: RESOURCE GROUP
referenceobject: ""
startbyte: 791
endbyte: 845
- schema: ""
name: admin_group
objecttype: RESOURCE GROUP
referenceobject: ""
startbyte: 845
endbyte: 902
- schema: ""
name: gpadmin
objecttype: ROLE
referenceobject: ""
startbyte: 902
endbyte: 1244
- schema: ""
name: etl
objecttype: DATABASE
referenceobject: ""
startbyte: 1246
endbyte: 1287
- schema: ""
name: etl
objecttype: DATABASE METADATA
referenceobject: ""
startbyte: 1287
endbyte: 1326
predataentries:
- schema: employees
name: employees
objecttype: SCHEMA
referenceobject: ""
startbyte: 1326
endbyte: 1352
- schema: employees
name: employees
objecttype: SCHEMA
referenceobject: ""
startbyte: 1352
endbyte: 1395
- schema: public
name: public
objecttype: SCHEMA
referenceobject: ""
startbyte: 1395
endbyte: 1396
- schema: public
name: public
objecttype: SCHEMA
referenceobject: ""
startbyte: 1396
endbyte: 1452
- schema: public
name: public
objecttype: SCHEMA
referenceobject: ""
startbyte: 1452
endbyte: 1492
- schema: public
name: public
objecttype: SCHEMA
referenceobject: ""
startbyte: 1492
endbyte: 1654
- schema: employees
name: employee_gender
objecttype: TYPE
referenceobject: ""
startbyte: 1656
endbyte: 1720
- schema: employees
name: employee_gender
objecttype: TYPE
referenceobject: ""
startbyte: 1720
endbyte: 1777
- schema: public
name: gender
objecttype: TYPE
referenceobject: ""
startbyte: 1777
endbyte: 1829
- schema: public
name: gender
objecttype: TYPE
referenceobject: ""
startbyte: 1829
endbyte: 1874
- schema: employees
name: id_employee_seq
objecttype: SEQUENCE
referenceobject: ""
startbyte: 1874
endbyte: 2054
- schema: employees
name: id_employee_seq
objecttype: SEQUENCE
referenceobject: ""
startbyte: 2054
endbyte: 2115
- schema: public
name: t1
objecttype: TABLE
referenceobject: ""
startbyte: 2115
endbyte: 2191
- schema: public
name: t1
objecttype: TABLE
referenceobject: ""
startbyte: 2191
endbyte: 2233
- schema: public
name: testdblink
objecttype: TABLE
referenceobject: ""
startbyte: 2233
endbyte: 2310
- schema: public
name: testdblink
objecttype: TABLE
referenceobject: ""
startbyte: 2310
endbyte: 2360
- schema: employees
name: department
objecttype: TABLE
referenceobject: ""
startbyte: 2360
endbyte: 2490
- schema: employees
name: department
objecttype: TABLE
referenceobject: ""
startbyte: 2490
endbyte: 2543
- schema: employees
name: department_employee
objecttype: TABLE
referenceobject: ""
startbyte: 2543
endbyte: 2739
- schema: employees
name: department_employee
objecttype: TABLE
referenceobject: ""
startbyte: 2739
endbyte: 2801
- schema: employees
name: department_manager
objecttype: TABLE
referenceobject: ""
startbyte: 2801
endbyte: 2996
- schema: employees
name: department_manager
objecttype: TABLE
referenceobject: ""
startbyte: 2996
endbyte: 3057
- schema: employees
name: employee
objecttype: TABLE
referenceobject: ""
startbyte: 3057
endbyte: 3377
- schema: employees
name: employee
objecttype: TABLE
referenceobject: ""
startbyte: 3377
endbyte: 3428
- schema: employees
name: salary
objecttype: TABLE
referenceobject: ""
startbyte: 3428
endbyte: 3598
- schema: employees
name: salary
objecttype: TABLE
referenceobject: ""
startbyte: 3598
endbyte: 3647
- schema: employees
name: title
objecttype: TABLE
referenceobject: ""
startbyte: 3647
endbyte: 3821
- schema: employees
name: title
objecttype: TABLE
referenceobject: ""
startbyte: 3821
endbyte: 3869
- schema: public
name: sales
objecttype: TABLE
referenceobject: ""
startbyte: 3869
endbyte: 3999
- schema: public
name: sales
objecttype: TABLE
referenceobject: ""
startbyte: 3999
endbyte: 4044
- schema: public
name: t2
objecttype: TABLE
referenceobject: ""
startbyte: 4044
endbyte: 4163
- schema: public
name: t2
objecttype: TABLE
referenceobject: ""
startbyte: 4163
endbyte: 4205
- schema: public
name: t3
objecttype: TABLE
referenceobject: ""
startbyte: 4205
endbyte: 4302
- schema: public
name: t3
objecttype: TABLE
referenceobject: ""
startbyte: 4302
endbyte: 4344
- schema: employees
name: idx_16979_primary
objecttype: CONSTRAINT
referenceobject: employees.department
startbyte: 4344
endbyte: 4435
- schema: employees
name: idx_16982_primary
objecttype: CONSTRAINT
referenceobject: employees.department_employee
startbyte: 4435
endbyte: 4559
- schema: employees
name: idx_16985_primary
objecttype: CONSTRAINT
referenceobject: employees.department_manager
startbyte: 4559
endbyte: 4682
- schema: employees
name: idx_16988_primary
objecttype: CONSTRAINT
referenceobject: employees.employee
startbyte: 4682
endbyte: 4771
- schema: employees
name: idx_16991_primary
objecttype: CONSTRAINT
referenceobject: employees.salary
startbyte: 4771
endbyte: 4878
- schema: employees
name: idx_16994_primary
objecttype: CONSTRAINT
referenceobject: employees.title
startbyte: 4878
endbyte: 4991
- schema: public
name: t2_pkey
objecttype: CONSTRAINT
referenceobject: public.t2
startbyte: 4991
endbyte: 5061
- schema: employees
name: dept_emp_ibfk_2
objecttype: CONSTRAINT
referenceobject: employees.department_employee
startbyte: 5061
endbyte: 5243
- schema: employees
name: dept_manager_ibfk_2
objecttype: CONSTRAINT
referenceobject: employees.department_manager
startbyte: 5243
endbyte: 5428
- schema: employees
name: dept_emp_ibfk_1
objecttype: CONSTRAINT
referenceobject: employees.department_employee
startbyte: 5428
endbyte: 5606
- schema: employees
name: dept_manager_ibfk_1
objecttype: CONSTRAINT
referenceobject: employees.department_manager
startbyte: 5606
endbyte: 5787
- schema: employees
name: salaries_ibfk_1
objecttype: CONSTRAINT
referenceobject: employees.salary
startbyte: 5787
endbyte: 5952
- schema: employees
name: titles_ibfk_1
objecttype: CONSTRAINT
referenceobject: employees.title
startbyte: 5952
endbyte: 6114
- schema: employees
name: id_employee_seq
objecttype: SEQUENCE OWNER
referenceobject: employees.employee
startbyte: 6114
endbyte: 6189
postdataentries:
- schema: employees
name: idx_16982_dept_no
objecttype: INDEX
referenceobject: employees.department_employee
startbyte: 6189
endbyte: 6283
- schema: employees
name: idx_16985_dept_no
objecttype: INDEX
referenceobject: employees.department_manager
startbyte: 6283
endbyte: 6376
statisticsentries: []
dataentries:
- schema: public
name: t1
oid: 16391
attributestring: (tid,info)
rowscopied: 2000
partitionroot: ""
isreplicated: false
- schema: public
name: testdblink
oid: 16858
attributestring: (a,b)
rowscopied: 2
partitionroot: ""
isreplicated: false
- schema: employees
name: department
oid: 16941
attributestring: (id,dept_name)
rowscopied: 9
partitionroot: ""
isreplicated: false
- schema: employees
name: department_employee
oid: 16944
attributestring: (employee_id,department_id,from_date,to_date)
rowscopied: 331603
partitionroot: ""
isreplicated: false
- schema: employees
name: department_manager
oid: 16947
attributestring: (employee_id,department_id,from_date,to_date)
rowscopied: 24
partitionroot: ""
isreplicated: false
- schema: employees
name: employee
oid: 16950
attributestring: (id,birth_date,first_name,last_name,gender,hire_date)
rowscopied: 300024
partitionroot: ""
isreplicated: false
- schema: employees
name: salary
oid: 16955
attributestring: (employee_id,amount,from_date,to_date)
rowscopied: 2844047
partitionroot: ""
isreplicated: false
- schema: employees
name: title
oid: 16958
attributestring: (employee_id,title,from_date,to_date)
rowscopied: 443308
partitionroot: ""
isreplicated: false
- schema: public
name: sales
oid: 17007
attributestring: (item,year,quantity)
rowscopied: 7
partitionroot: ""
isreplicated: false
- schema: public
name: t2
oid: 17010
attributestring: (id,balance,status)
rowscopied: 0
partitionroot: ""
isreplicated: false
- schema: public
name: t3
oid: 17018
attributestring: (name,amount)
rowscopied: 5
partitionroot: ""
isreplicated: false
incrementalmetadata:
ao: {}
[gpadmin@gp-mdw 20221214172018]$ cat gpbackup_20221214172018_metadata.sql
SET client_encoding = 'UTF8';
ALTER RESOURCE QUEUE pg_default WITH (ACTIVE_STATEMENTS=20);
ALTER RESOURCE GROUP admin_group SET CPU_RATE_LIMIT 1;
ALTER RESOURCE GROUP admin_group SET MEMORY_LIMIT 1;
ALTER RESOURCE GROUP default_group SET CPU_RATE_LIMIT 1;
ALTER RESOURCE GROUP default_group SET MEMORY_LIMIT 1;
ALTER RESOURCE GROUP default_group SET MEMORY_LIMIT 0;
ALTER RESOURCE GROUP default_group SET MEMORY_SHARED_QUOTA 80;
ALTER RESOURCE GROUP default_group SET MEMORY_SPILL_RATIO 0;
ALTER RESOURCE GROUP default_group SET CONCURRENCY 20;
ALTER RESOURCE GROUP default_group SET CPU_RATE_LIMIT 30;
ALTER RESOURCE GROUP admin_group SET MEMORY_LIMIT 10;
ALTER RESOURCE GROUP admin_group SET MEMORY_SHARED_QUOTA 80;
ALTER RESOURCE GROUP admin_group SET MEMORY_SPILL_RATIO 0;
ALTER RESOURCE GROUP admin_group SET CONCURRENCY 10;
ALTER RESOURCE GROUP admin_group SET CPU_RATE_LIMIT 10;
CREATE ROLE gpadmin;
ALTER ROLE gpadmin WITH SUPERUSER INHERIT CREATEROLE CREATEDB LOGIN REPLICATION PASSWORD 'md5b44a9b06d576a0b083cd60e5f875cf48' RESOURCE QUEUE pg_default RESOURCE GROUP admin_group CREATEEXTTABLE (protocol='http') CREATEEXTTABLE (protocol='gpfdist', type='readable') CREATEEXTTABLE (protocol='gpfdist', type='writable');
CREATE DATABASE etl TEMPLATE template0;
ALTER DATABASE etl OWNER TO gpadmin;
CREATE SCHEMA employees;
ALTER SCHEMA employees OWNER TO gpadmin;
COMMENT ON SCHEMA public IS 'standard public schema';
ALTER SCHEMA public OWNER TO gpadmin;
REVOKE ALL ON SCHEMA public FROM PUBLIC;
REVOKE ALL ON SCHEMA public FROM gpadmin;
GRANT ALL ON SCHEMA public TO PUBLIC;
GRANT ALL ON SCHEMA public TO gpadmin;
CREATE TYPE employees.employee_gender AS ENUM (
'M',
'F'
);
ALTER TYPE employees.employee_gender OWNER TO gpadmin;
CREATE TYPE public.gender AS ENUM (
'M',
'F'
);
ALTER TYPE public.gender OWNER TO gpadmin;
CREATE SEQUENCE employees.id_employee_seq
START WITH 1
INCREMENT BY 1
NO MAXVALUE
NO MINVALUE
CACHE 1;
SELECT pg_catalog.setval('employees.id_employee_seq', 499999, true);
ALTER SEQUENCE employees.id_employee_seq OWNER TO gpadmin;
CREATE TABLE public.t1 (
tid integer,
info text
) DISTRIBUTED BY (tid);
ALTER TABLE public.t1 OWNER TO gpadmin;
CREATE TABLE public.testdblink (
a integer,
b text
) DISTRIBUTED BY (a);
ALTER TABLE public.testdblink OWNER TO gpadmin;
CREATE TABLE employees.department (
id character(4) NOT NULL,
dept_name character varying(40) NOT NULL
) DISTRIBUTED BY (id);
ALTER TABLE employees.department OWNER TO gpadmin;
CREATE TABLE employees.department_employee (
employee_id bigint NOT NULL,
department_id character(4) NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL
) DISTRIBUTED BY (employee_id);
ALTER TABLE employees.department_employee OWNER TO gpadmin;
CREATE TABLE employees.department_manager (
employee_id bigint NOT NULL,
department_id character(4) NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL
) DISTRIBUTED BY (employee_id);
ALTER TABLE employees.department_manager OWNER TO gpadmin;
CREATE TABLE employees.employee (
id bigint DEFAULT (nextval('employees.id_employee_seq'::regclass)) NOT NULL,
birth_date date NOT NULL,
first_name character varying(14) NOT NULL,
last_name character varying(16) NOT NULL,
gender employees.employee_gender NOT NULL,
hire_date date NOT NULL
) DISTRIBUTED BY (id);
ALTER TABLE employees.employee OWNER TO gpadmin;
CREATE TABLE employees.salary (
employee_id bigint NOT NULL,
amount bigint NOT NULL,
from_date date NOT NULL,
to_date date NOT NULL
) DISTRIBUTED BY (employee_id);
ALTER TABLE employees.salary OWNER TO gpadmin;
CREATE TABLE employees.title (
employee_id bigint NOT NULL,
title character varying(50) NOT NULL,
from_date date NOT NULL,
to_date date
) DISTRIBUTED BY (employee_id);
ALTER TABLE employees.title OWNER TO gpadmin;
CREATE TABLE public.sales (
item character varying(10),
year character varying(4),
quantity integer
) DISTRIBUTED BY (item);
ALTER TABLE public.sales OWNER TO gpadmin;
CREATE TABLE public.t2 (
id integer NOT NULL,
balance numeric,
status character varying(1)
) DISTRIBUTED BY (id);
ALTER TABLE public.t2 OWNER TO gpadmin;
CREATE TABLE public.t3 (
name character varying(20),
amount numeric
) DISTRIBUTED BY (name);
ALTER TABLE public.t3 OWNER TO gpadmin;
ALTER TABLE ONLY employees.department ADD CONSTRAINT idx_16979_primary PRIMARY KEY (id);
ALTER TABLE ONLY employees.department_employee ADD CONSTRAINT idx_16982_primary PRIMARY KEY (employee_id, department_id);
ALTER TABLE ONLY employees.department_manager ADD CONSTRAINT idx_16985_primary PRIMARY KEY (employee_id, department_id);
ALTER TABLE ONLY employees.employee ADD CONSTRAINT idx_16988_primary PRIMARY KEY (id);
ALTER TABLE ONLY employees.salary ADD CONSTRAINT idx_16991_primary PRIMARY KEY (employee_id, from_date);
ALTER TABLE ONLY employees.title ADD CONSTRAINT idx_16994_primary PRIMARY KEY (employee_id, title, from_date);
ALTER TABLE ONLY public.t2 ADD CONSTRAINT t2_pkey PRIMARY KEY (id);
ALTER TABLE ONLY employees.department_employee ADD CONSTRAINT dept_emp_ibfk_2 FOREIGN KEY (department_id) REFERENCES employees.department(id) ON UPDATE RESTRICT ON DELETE CASCADE;
ALTER TABLE ONLY employees.department_manager ADD CONSTRAINT dept_manager_ibfk_2 FOREIGN KEY (department_id) REFERENCES employees.department(id) ON UPDATE RESTRICT ON DELETE CASCADE;
ALTER TABLE ONLY employees.department_employee ADD CONSTRAINT dept_emp_ibfk_1 FOREIGN KEY (employee_id) REFERENCES employees.employee(id) ON UPDATE RESTRICT ON DELETE CASCADE;
ALTER TABLE ONLY employees.department_manager ADD CONSTRAINT dept_manager_ibfk_1 FOREIGN KEY (employee_id) REFERENCES employees.employee(id) ON UPDATE RESTRICT ON DELETE CASCADE;
ALTER TABLE ONLY employees.salary ADD CONSTRAINT salaries_ibfk_1 FOREIGN KEY (employee_id) REFERENCES employees.employee(id) ON UPDATE RESTRICT ON DELETE CASCADE;
ALTER TABLE ONLY employees.title ADD CONSTRAINT titles_ibfk_1 FOREIGN KEY (employee_id) REFERENCES employees.employee(id) ON UPDATE RESTRICT ON DELETE CASCADE;
ALTER SEQUENCE employees.id_employee_seq OWNED BY employees.employee.id;
CREATE INDEX idx_16982_dept_no ON employees.department_employee USING btree (department_id);
CREATE INDEX idx_16985_dept_no ON employees.department_manager USING btree (department_id);[gpadmin@gp-mdw 20221214172018]$
Flags:--backup-dir string `可选参数`, 写入备份文件的绝对路径,不能采用相对路径,如果您指定了该路径,备份操作会将所有备份文件(包括元数据文件)都放到这个目录下。如果您不指定这个选项,元数据文件会保存到Master节点的 `$MASTER_DATA_DIRECTORY/backups/YYYYMMDD/YYYYMMDDhhmmss/` 目录下,数据文件会存放在segment主机的 `<seg_dir>/backups/YYYYMMDD/ YYYYMMDDhhmmss/`目录下。该选项不能与 `--plugin-config` 选项共同使用。
--compression-level int `可选参数`, 压缩级别。大家需要注意,在当前随GPDB版本发布的gpbackup包中,只支持gzip压缩格式,如果您自行编译gpbackup,可以看到已经增加了 `compression-type` 类型,该类型支持其他的压缩类型。压缩级别的默认值为1,gpbackup在备份时,会默认启用gzip压缩。
--compression-type string `可选参数`, 压缩类型。有效值有 'gzip','zstd',默认为 'gzip',如果要使用 'zstd' 压缩,需要在所有服务器上安装该压缩类型以保证shell可以执行 `zstd` 命令,安装方式参考:https://github.com/facebook/zstd 。--copy-queue-size int `可选参数`, 自行编译最新版本gpbackup带有的参数,该参数只能配合 `--single-data-file` 参数一起使用,当定义了 `--single-data-file` 参数以后,通过执行 `--copy-queue-size` 参数的值来指定gpbackup命令使用COPY命令的个数,默认值为1。
--data-only `可选参数`, 只备份数据,不备份元数据。
--dbname string `必选参数`, 只要进行备份的数据库名称,必须指定,否则会报错,备份无法进行。
--debug `可选参数`, 显示备份过程中详细的debug信息,通常用在排错场景。
--exclude-schema stringArray `可选参数`, 指定备份操作要排除的数据库模式(schema), 如果要排除多个模式,需要多次定义,不支持 `--exclude-schema=schema1,schema2` 的方式。另外该参数与 '--exclude-schema-file, exclude-table, --exclude-table-file, --include-schema, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。
--exclude-schema-file string `可选参数`, 包含备份操作要排除的数据库模式的文件,每一行为一个模式名,该文件不能包含多余的符号,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。该参数与 '--exclude-schema, --exclude-table, --exclude-table-file, --include-schema, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。
--exclude-table stringArray `可选参数`, 指定备份操作中要排除的表名,该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table-file, --include-schema, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。指定表名时,必须使用 `<schema-name>.<table-name>` 的格式指定匹配到具体的模式,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。另外该参数也支持多次指定。
--exclude-table-file string `可选参数`, 指定文件包含备份操作中要排除的表名,该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table, --include-schema, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。指定表名时,必须使用 `<schema-name>.<table-name>` 的格式指定匹配到具体的模式,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。如果有多个表,需要在文件中分行多次指定。
--from-timestamp string `可选参数`, 指定增量备份的时间戳。被指定的备份必须有增量备份集,如果没有,备份操作会自动创建一个增量备份集;如果被指定的备份是一个增量备份,则备份操作会向备份集增加一个备份。使用该参数时,必须指定参数 `--leaf-partition-data`, 并且不能与`--data-only或--metadata-only`参数一起使用。如果没有任何全量备份存在,则会报错退出备份过程。
--help 显示命令行参数帮助信息。
--include-schema stringArray `可选参数`, 指定备份操作要包含的数据库模式(schema), 如果要包含多个模式,需要多次定义,不支持 `--include-schema=schema1,schema2` 的方式。另外该参数与 '--exclude-schema, --exclude-schema-file, exclude-table, --exclude-table-file, --include-schema-file, --include-table, --include-table-file' 这几个参数不能同时使用。
--include-schema-file string `可选参数`, 包含备份操作要包含的数据库模式的文件,每一行为一个模式名,该文件不能包含多余的符号,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table, --exclude-table-file, --include-schema, --include-table, --include-table-file' 这几个参数不能同时使用。
--include-table stringArray `可选参数`, 指定备份操作中要包含的表名,该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table, --exclude-table-file, --include-schema, --include-schema-file, --include-table-file' 这几个参数不能同时使用。指定表名时,必须使用 `<schema-name>.<table-name>` 的格式指定匹配到具体的模式,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。另外该参数也支持多次指定。
--include-table-file string `可选参数`, 指定文件包含备份操作中要包含的表名,该参数与 '--exclude-schema, --exclude-schema-file, --exclude-table, --exclude-table-file, --include-schema, --include-schema-file, --include-table' 这几个参数不能同时使用。指定表名时,必须使用 `<schema-name>.<table-name>` 的格式指定匹配到具体的模式,如果数据库中的模式包含除了:字母、数字和下划线以外的特殊符号,那么请在文件中用双引号进行包裹。如果有多个表,需要在文件中分行多次指定。
--incremental `可选参数`, 增量备份功能,增量备份只支持AO表的增量,Heap表不支持增量备份。指定该选项后,会在备份集合中继续增加增量备份。在GPDB里面,备份可以全部都由全量备份构成,也可以由全量备份+增量备份的方式构成,增量备份必须与前面的全量备份组成一个连续的集合,否则无法进行恢复。如果已经做了一个全量备份但是没有增量备份,那该参数会在备份时创建一个增量备份集;如果全量和增量都已经存在了,那么该参数会在现有增量备份集中增加一个最新的备份;另外也可以通过指定 '--from-timestamp' 参数来改变默认行为。
--jobs int `可选参数`, 指定进行表备份过程中的并行任务数,如果不指定,该值默认为1,gpbackup会使用一个任务(即一个数据库连接)进行备份。可以通过增加该值来提升备份速度,如果指定了大于1的值,备份操作会以表为单位进行并发操作,每个表开启一个单独的事务。需要特别注意的是,指定该参数进行并发备份时,不要进行外部程序操作,否则无法保证多表之间的事物一致性。该参数可以与 `--metadata-only,-- single-data-file,--plugin-config` 参数共同使用。
--leaf-partition-data `可选参数`, 为分区表的每一个叶子节点单独创建备份文件,而不是为整个表创建一个备份文件(默认)。使用该参数配合 `--include-table,-- include-table-file,--exclude-table,--exclude-table-file` 参数可以实现包含或排除叶子节点数据的操作。
--metadata-only `可选参数`, 仅备份元数据(即创建数据库对象的DDL语句),不备份任何实际的生产表数据。
--no-compression `可选参数`, 不启用压缩。
--plugin-config string `可选参数`, 指定plugin配置文件位置,该文件是一个有效的YAML文件,用来指定在备份过程中使用的plugin应用的配置信息。由于备份的plugin通常都是为了将备份放到远程存储,所以该选项不能与 `--backup-dir` 同时使用;例如可以使用s3的库将备份文件放到亚马逊S3存储上。也可以通过开放接口自己编写plugin,具体可以参考:https://gpdb.docs.pivotal.io/6-17/admin_guide/managing/backup-plugins.html--quiet `可选参数`, 静默模式,除了warning和error信息都不打印。
--single-data-file `可选参数`, 每个segment的数据备份成一个未见,而不是每个表备份一个文件(默认)。如果指定了该选项,在使用gprestore恢复的时候,不能使用 `--job` 选项进行并发恢复。需要特别注意,如果要使用该参数,需要配合 `gpbackup_helper` 命令一起使用,该命令与gpbackup和gpresotre一起编译生成,需要把这个命令放到所有segment host的greenplum-db/bin目录下。
--verbose `可选参数`, 打印详细日志信息。
--version 打印gpbackup的版本号并退出。
--with-stats `可选参数`, 备份查询计划统计信息。
--without-globals `可选参数`, 不备份全局对象。
- GreenPlum 大数据平台--并行备份(四)
01,并行备份(gp_dump) 1) GP同时备份Master和所有活动的Segment实例 2) 备份消耗的时间与系统中实例的数量没有关系 3) 在Master主机上备份所有DDL文件和GP相关的 ...
- GreenPlum 大数据平台--非并行备份(六)
一,非并行备份(pg_dump) 1) GP依然支持常规的PostgreSQL备份命令pg_dump和pg_dumpall 2) 备份将在Master主机上创建一个包含所有Segment数据的大的备份 ...
- Greenplum迁移到配置不同的GP系统
要使用gp_restore或gpdbrestore并行恢复操作,恢复的系统必须与备份的系统具有相同的配置(相同数量的Instance).如果想要恢复数据库对象和数据到配置不同的系统(比如系统扩展了更多 ...
- Greenplum的全量备份之gpcrondump
gpcrondump是对gp_dump的一个包装,可以直接调用或者从crontab中调用.这个命令还允许备份除了数据库和数据之外的对象,比如数据库角色和服务器配置等. gpcrondump 常用到的参 ...
- MySQL逻辑备份into outfile
MySQL 备份之 into outfile 逻辑数据导出(备份) 用法: select xxx into outfile '/path/file' from table_name; mysql> ...
- GreenPlum 大数据平台--备份-邮件配置-gpcrondump & gpdbrestore(五)
01,备份 生成备份数据库 [gpadmin@greenplum01 ~]$ gpcrondump -l /gpbackup/back2/gpcorndump.log -x postgres -v [ ...
- mysql物理备份恢复 xtrabackup 初试
听闻xtrabackup开源且强大 2018-03-06 11:54:41 在官网下载安装了最新的2.4.9版本 网上文章都用的innobackupex,但是最新版已经抛弃了,自己看看手册<Pe ...
- sde自动备份到文件gdb
本方法原理是使用python(以下简称py)调用arcmap的gp,在上再用bat调用py的方式实现.优点是能应用于所有数据库类型(包括pg,oracle等)的sde库 环境:arcmap 10.4, ...
- MySQL--11 备份的原因
目录 一.备份的原因 二.备份的类型 三.备份的方式 四.备份策略 五.备份工具 六.企业故障恢复案例 1.模拟环境 2.模拟恢复数据过程: 一.备份的原因 运维工作的核心简单概括就两件事: 1)第一 ...
- Commvault Oracle备份常用命令
在进行Oracle数据库备份的配置.发起和恢复的过程中,需要用到许多Oracle数据库本身的命令.在此章节中进行命令的梳理,供大家参考. Oracle用户和实例相关命令 Linux/Unix平台 # ...
随机推荐
- 使用docker-compose部署Django项目
先从最基本的功能开始 在一切工作开始前,需要先编辑好三个必要的文件. 第一步,因为应用将要运行在一个满足所有环境依赖的 Docker 容器里面,那么我们可以通过编辑 Dockerfile 文件来指定 ...
- 通过开启swap分区来解决小内存阿里云服务器的内存瓶颈
swap分区大小设置 阿里云的linux云服务器默认是没有启用swap分区(交换分区)的.一般情况下swapswap分区的大小可以参考以下规则进行设定: 内存大小 swap大小 MEM_SIZE &l ...
- 3.在 Kubernetes 上安装 Gitlab CI Runner
结合文章:1. 在 Kubernetes 上安装 Gitlab ,地址:https://www.cnblogs.com/sanduzxcvbnm/p/13852854.html 总结: 结合开头的文章 ...
- PHP全栈开发(八):CSS Ⅳ 文本格式及字体
文本系列属性主要是设置文本格式的,例如.... 颜色 body {color:red;} h1 {color:#00ff00;} p.ex {color:rgb(0,0,255); 可以设置文本的居中 ...
- HDU2041 超级楼梯 (线性DP)
fn[i]表示走上第i级台阶的所有走法. 方程:fn[i]=fn[i-1]+fn[i-2]; 1 #include<cstdio> 2 #define MAXN 40 3 using na ...
- C++ 栈和典型迷宫问题
C++ 栈和迷宫问题 1. 前言 栈是一种受限的数据结构,要求在存储数据时遵循先进后出(Last In First Out)的原则.可以把栈看成只有一个口子的桶子,进和出都是走的这个口子(也称为栈顶) ...
- python今日分享(内置方法)
目录 一.习题详解 二.数据类型的内置方法理论 三.整型相关操作 四.浮点型相关操作 五.字符串相关操作 六.列表相关操作 今日详解 一.习题详解 1.计算1-100所有数据之和 all_num = ...
- WiresShark
WireShark 分析数据包技巧 确定WireShark的位置[是否在公网上] 选择捕获接口,一般都是internet网络接口 使用捕获过滤器 使用显示过滤器[捕获后的数据包还是很复杂,用显示过滤器 ...
- 6.YAML文件详解、PyYaml操作
YAML简介: yaml是一种数据格式,支持注释,换行,多行字符串,裸字符串(正序,字符串) YAML作用: 用于全局的配置文件 用于测试用例编写 YAML语法规则: 区分大小写 使用缩进 ...
- python导包
我们将完成特定功能的代码块放在一个.py结尾的文件中,这个文件被称为模块.在这个模块中可能包含变量,函数,类等等内容. 当我们从外部需要用到这个模块时,就需要将这个模块导入到我们当前环境.导入方式有以 ...