深入理解 MySQL 的事务隔离级别和 MVCC 机制
前言
我们都知道 MySQL 实现了 SQL 标准中的四个隔离级别,但是具体是如何实现的可能还一知半解,本篇博客将会从代码层面讲解隔离级别的实现方式,下面进入正题。
事务
考虑这样一个场景:博主向硝子酱的微信转了 520 块钱,在余额充足的正常情况下博主的账户余额会少 520 块,而硝子酱则会多 520 块钱,接着硝子酱就可以用这 520 块钱开开心心地购物去了。但是假设某一次微信扣了博主 520 块钱之后服务器就宕机了,而没有给硝子酱加上 520 块,博主少了 520 块事小,硝子酱不能购物就很难受了。所以微信必须有一个机制能够保证转账之后双方账户余额总额不变,要是宕机了,就必须保证重启后能还给博主 520 块钱,这就引出了事务的概念。
事务(transaction)是一组原子性的SQL查询,或者说一个独立的工作单元,事务内的语句,要么全部执行成功,要么全部执行失败。
MySQL 官方提供了两种支持事务的存储引擎:InnoDB 和 NDB Cluster,除此之外一些第三方存储引擎也支持事务,包括 XtraDB 和 PBXT。可以看到下表清楚地写在 InnoDB 存储引擎支持事务、行级锁和外键,而 MyISAM 不支持事务。
mysql> show engines;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.00 sec)
ACID
一个合格的事务处理系统,应该具备四个性质:原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)。
原子性
一个事务是一个不可分割的最小工作单元,事务中的操作要么全部提交成功,要么全部执行失败然后回滚回事务之前的状态。
一致性
数据库总是从一个一致性的状态转换到另一个一致性的状态,不可能处于中间态。以之前的例子为例,微信零钱系统要么处于博主扣除520块、硝子得到520块的状态,要么处于博主没有扣除520块,硝子也没有得到520块的状态,不可能处于博主扣了520块而硝子没有得到520块的状态。
隔离性
一个活跃的事务(还没提交或者回滚)对数据库所做的系统对于其他的活跃事务应该是不可见的,可以通过加锁来实现。但是一旦加了锁会导致并发性能的下降,这时候可以通过牺牲一部分隔离性来换取并发性,牺牲的程度取决于后续介绍的隔离级别。
持久性
事务一旦提交,就必须保证所做的修改永久保存到数据库中。看到这个也许你会产生一些疑问,既然我的事务都提交了,所做的修改不是立即就反映到了数据库系统中了吗,怎么会有持久化的问题呢?
实际上为了减少频繁随机 I/O 带来的性能影响,数据库中会有一个缓冲池(放在内存中)用来暂存被修改的页,我们称之为脏页,等到时机成熟(比如缓冲池满了或者数据库服务器关了)才会将这些脏页刷到磁盘上。也就是说即使你的事务提交了,也还没被保存到磁盘上,这时候要是服务器宕机了,内存中的脏页也就丢失了。
所以我们一般使用预写式日志将事务所做的修改提前保存到磁盘中,而写日志的过程是顺序 I/O,速度比随机 I/O 快了不少。服务器重启之后会将日志中记录的但是没有实际执行的修改重新执行一遍,这样就保证了持久性。更多关于预写式日志的实现方式可以参见《CMU15445 (Fall 2019) 之 Project#4 - Logging & Recovery 详解》。
隔离级别
假设同时存在多个活跃的事务,如果这些事务都只执行读操作,那么就比起相安无事,毕竟读不会改变数据库的内容,但是一旦有一个不安分的事务使用 update、insert 或者 delete 语句,就会带来并发问题。要解决并发问题,最简单粗暴的方法就是加锁,同一时间只能有一个事务在读写数据库,但是这样会造成其他事务的阻塞排队,极大降低了并发性能。正如算法中的空间换时间,我们也可以用隔离性换 读-写 并发性。
SQL标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做的修改,哪些在事务内和事务间是可见的,哪些是不可见的。较低级别的隔离通常可以执行更高的并发,系统的开销也更低。
InnoDB 存储引擎实现了这四种隔离级别,分别是 READ UNCOMMITTED(读未提交)、READ COMMITTED(读已提交)、REPEATABLE READ(可重复读)和 SERIALIZABLE(可串行化)。其中可串行化隔离性最好,但是并发性也最差,InnoDB 默认使用 REPEATABLE READ 隔离级别。
查看和修改隔离级别
隔离级别作用域包括全局级别(global)、会话级别(session)和仅对下一个事务生效级别(the next transaction only)。MySQL 5.7.20 版本之后我们可以使用下述语句查看这三种作用域的隔离级别分别是什么:
mysql> select @@global.transaction_isolation, @@session.transaction_isolation, @@transaction_isolation;
+--------------------------------+---------------------------------+-------------------------+
| @@global.transaction_isolation | @@session.transaction_isolation | @@transaction_isolation |
+--------------------------------+---------------------------------+-------------------------+
| REPEATABLE-READ | REPEATABLE-READ | REPEATABLE-READ |
+--------------------------------+---------------------------------+-------------------------+
1 row in set (0.00 sec)
或者使用 set 语句修改 transaction_isolation 变量的值:
mysql> set global transaction isolation level READ UNCOMMITTED;
Query OK, 0 rows affected (0.00 sec)
mysql> set session transaction isolation level READ UNCOMMITTED;
Query OK, 0 rows affected (0.00 sec)
mysql> set transaction isolation level READ UNCOMMITTED;
Query OK, 0 rows affected (0.00 sec)
mysql> select @@global.transaction_isolation, @@session.transaction_isolation, @@transaction_isolation;
+--------------------------------+---------------------------------+-------------------------+
| @@global.transaction_isolation | @@session.transaction_isolation | @@transaction_isolation |
+--------------------------------+---------------------------------+-------------------------+
| READ-UNCOMMITTED | READ-UNCOMMITTED | READ-UNCOMMITTED |
+--------------------------------+---------------------------------+-------------------------+
1 row in set (0.00 sec)
数据准备
在演示四种隔离级别的效果之前,我们先来创建一张 tbl_user 表,里面只有两条记录。
mysql> create table user (
-> id INT PRIMARY KEY,
-> name VARCHAR(255),
-> age INT);
Query OK, 0 rows affected (0.04 sec)
mysql> INSERT INTO tbl_user VALUES (1, '硝子', 16), (2, '之一', 17) ;
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from tbl_user;
+----+------+------+
| id | name | age |
+----+------+------+
| 1 | 硝子 | 16 |
| 2 | 之一 | 17 |
+----+------+------+
2 rows in set (0.00 sec)
READ UNCOMMITTED
在 READ UNCOMMITTED 级别,事务中的修改,即使没有提交,对其他事务也都是可见的。事务可以读取未提交的数据,被称为脏读(Dirty Read),脏读会导致很多问题,从性能上来说,READ UNCOMMITTED 不会比其他的级别好太多,在实际应用中一般很少使用。
现在有两个活跃的事务 T1 和 T2,在 T1 隔离级别为 READ UNCOMMITTED 的情况下查询结果如下图所示,可以看到 T1 读到了 T2 更新了但是还没提交的第二条记录。

READ COMMITTED
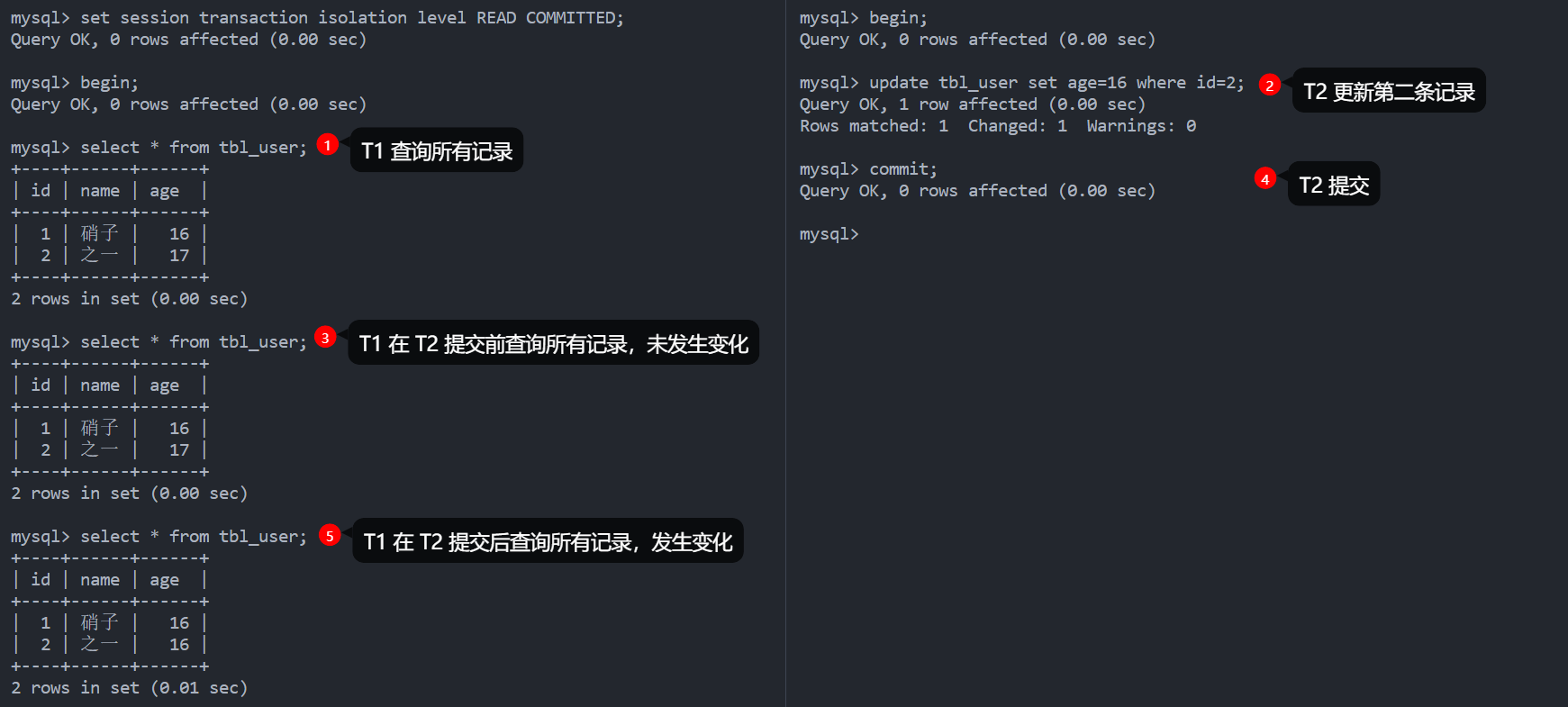
READ COMMITTED 满足前面提到的隔离性的简单定义:一个事务开始时,只能看见已经提交的事务所做的修改。换句话说,一个事务在提交之前所做的任何修改对其他事务都是不可见的。这个级别也被称为不可重复读(nonrepeatable read),因为另一个事务两次执行同样的查询,可能会得到不一样的结果,第二次查询会得到刚提交的事务所修改的值。
如下图所示,在 READ COMMITTED 隔离级别下,T1 不会读到 T2 未提交的记录最新值,但是一旦 T2 提交,T1 就会读到第二条记录的最新值,这个最新值和之前的不一样,所以被称为不可重复读。
REPEATABLE READ
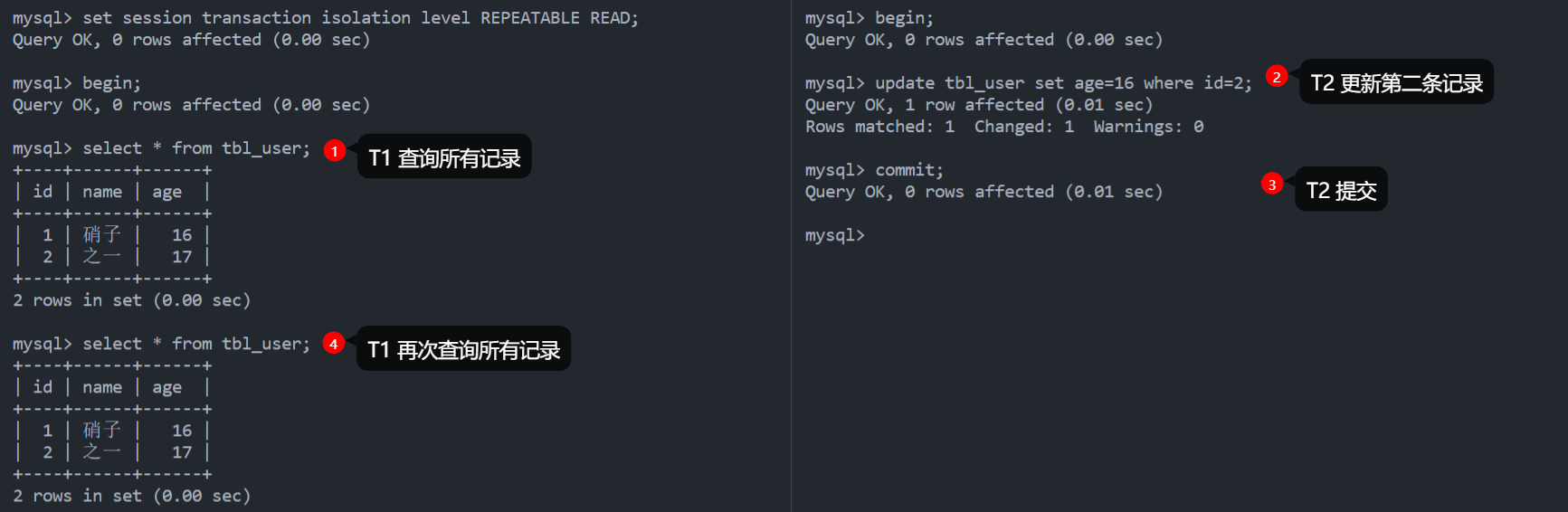
REPEATABLE READ 解决了不可重复读的问题,保证了在同一个事务中多次读取同样记录的结果是一致的。如下图所示,即使 T2 提交了,T1 读到的记录也没有发生变化。
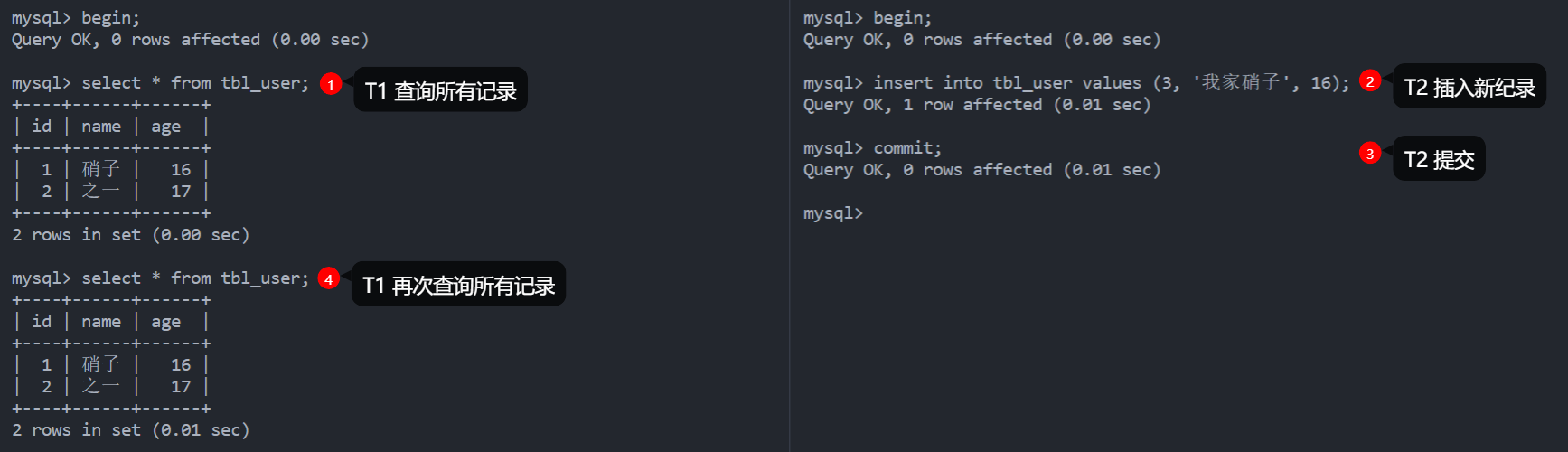
REPEATABLE READ 在某些情况下仍然会出现幻读的问题。所谓幻读,指的是当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录时,会读到新的数据,这些数据称为幻行(Phantom Row)。实际上 InnoDB 存储引擎通过多版本并发控制 (MVCC,Multiversion Concurrency Control) 和 next-key lock 分别解决了事务中全是快照读(select * from XX)或全是当前读(select * from XX for update,看做写操作)的幻读问题,但是当快照读和当前读混合使用时仍然会产生幻读问题。
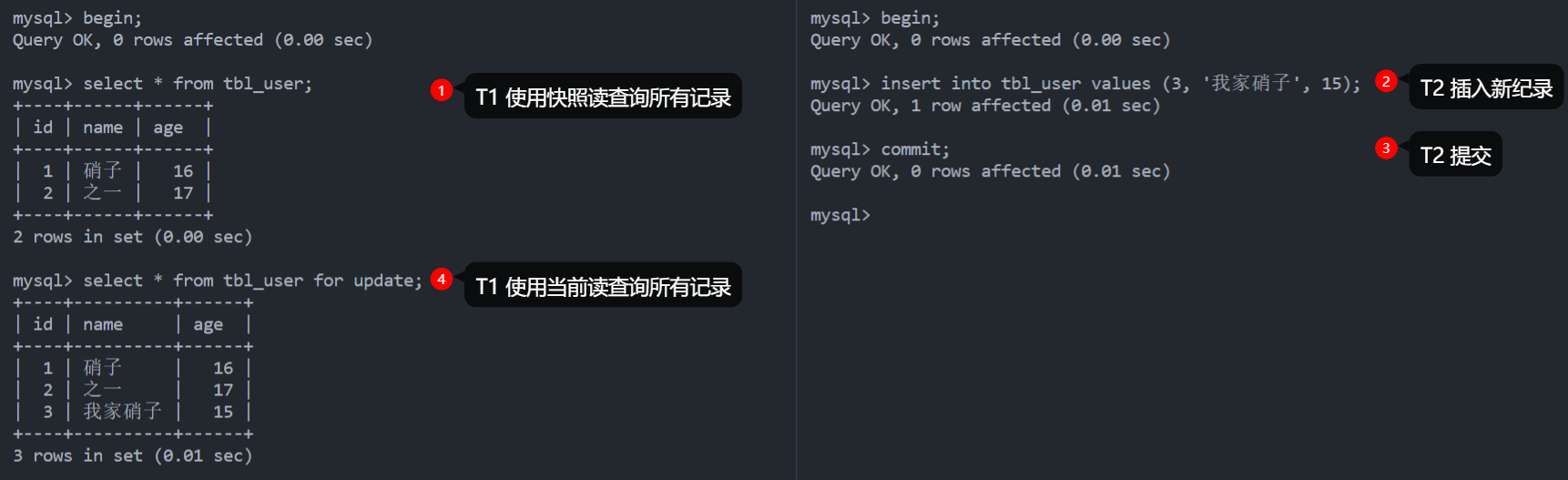
下图演示了全是快照读的情况,可以看到即使 T2 插入了新纪录并提交,T1 也不会看到幻行:
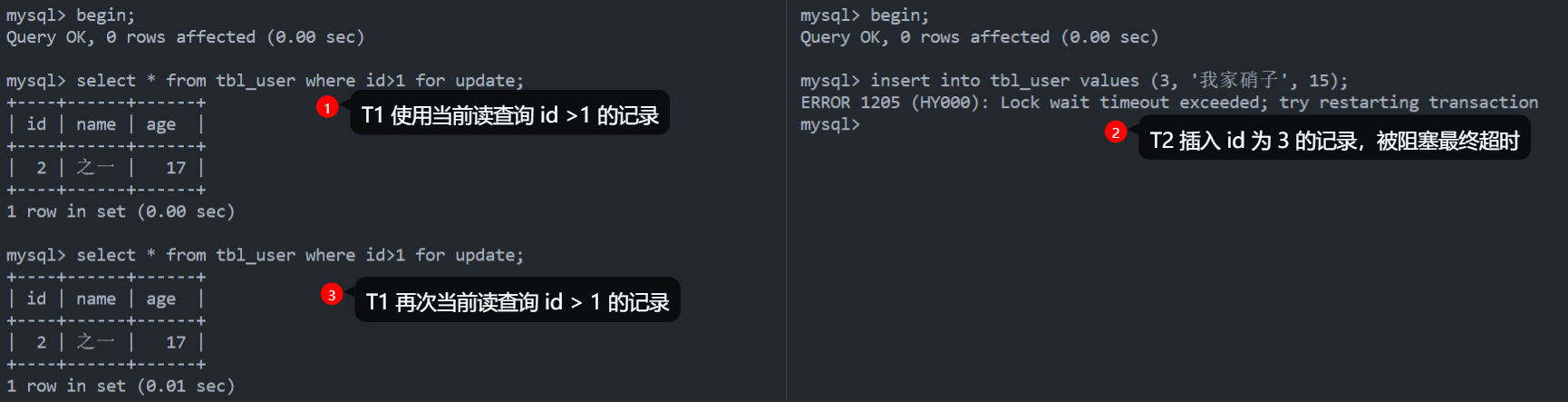
下图演示了全是当前读的情况,此时 T1 锁住了 \([2, +\infty]\) 范围内的 id,无法在此范围插入新数据,T2 企图插入 id 为 3 的记录结果被阻塞并最终因为超时而失败。
前面两种情况都没发生幻读,下面看看混合使用快照读和当前读的情况,可以看到当前读比快照读多读到了一行记录,因为当前读读取到就是数据库的最新数据:
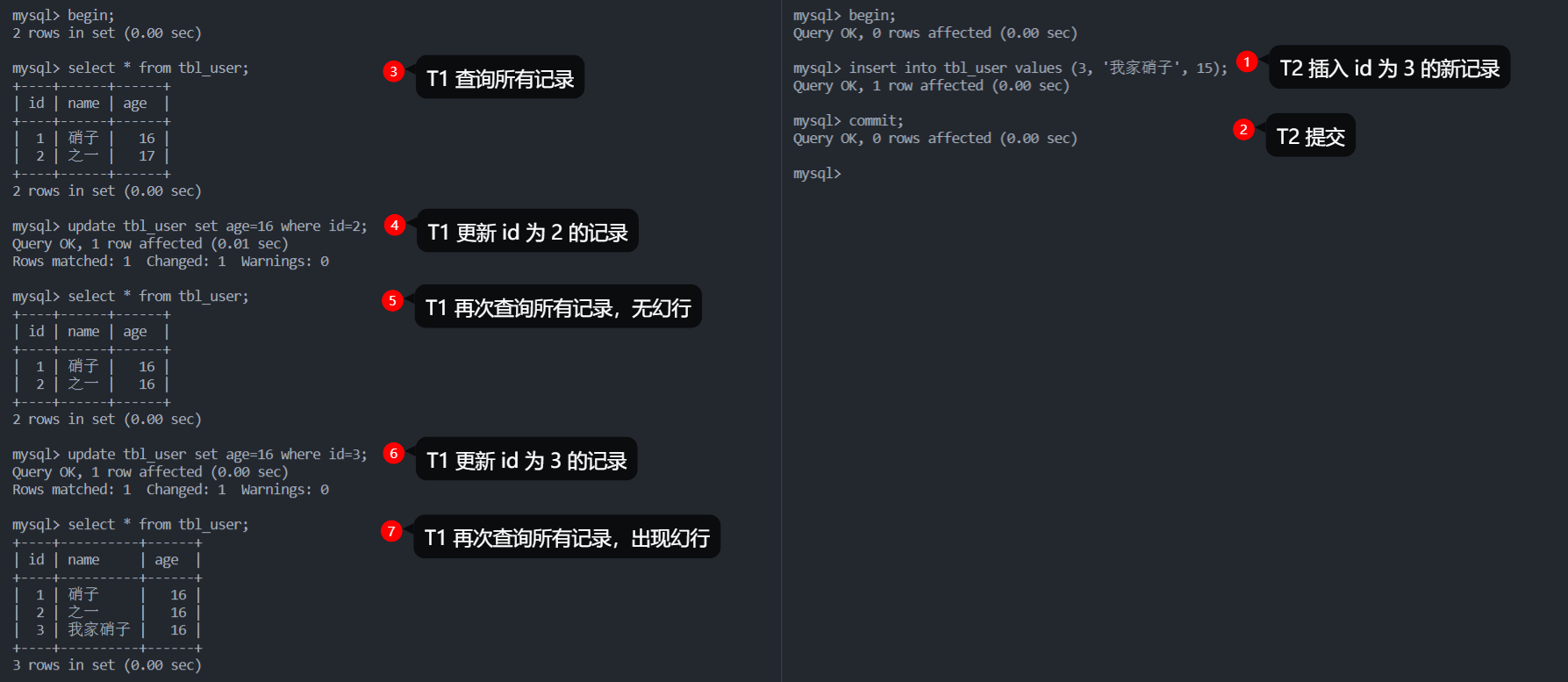
前面也提到了当前读可以看做写操作,所以这里再给出一个写操作引发幻读的例子。可以看到 T1 第一次写操作后再次查询没有出现幻行,但是第二次写操作后就出现了幻行,原因将在 MVCC 小节给出。
SERIALIZABLE
SERIALIZABLE 是最高的隔离级别。它通过强制事务串行执行,避免了幻读的问题。简单来说,SERIALIZABLE 会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁争用的问题。只有在非常需要确保数据的一致性而且可以接受没有并发的情况下,才考虑采用该级别。

隔离级别小结
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| read uncommitted | 可能 | 可能 | 可能 |
| read committed | 不可能 | 可能 | 可能 |
| repeatable read | 不可能 | 不可能 | 可能 |
| serializable | 不可能 | 不可能 | 不可能 |
MVCC
为了实现 READ COMMITTED 以及 REPEATABLE READ,我们需要保证不同的事务在某一时刻只能看到一部分历史数据或者自己所修改的数据,而多版本并发控制(Multiversion concurrency control)通过 undo log 组成的版本链以及 ReadView 帮我们实现了这一点。
undo log
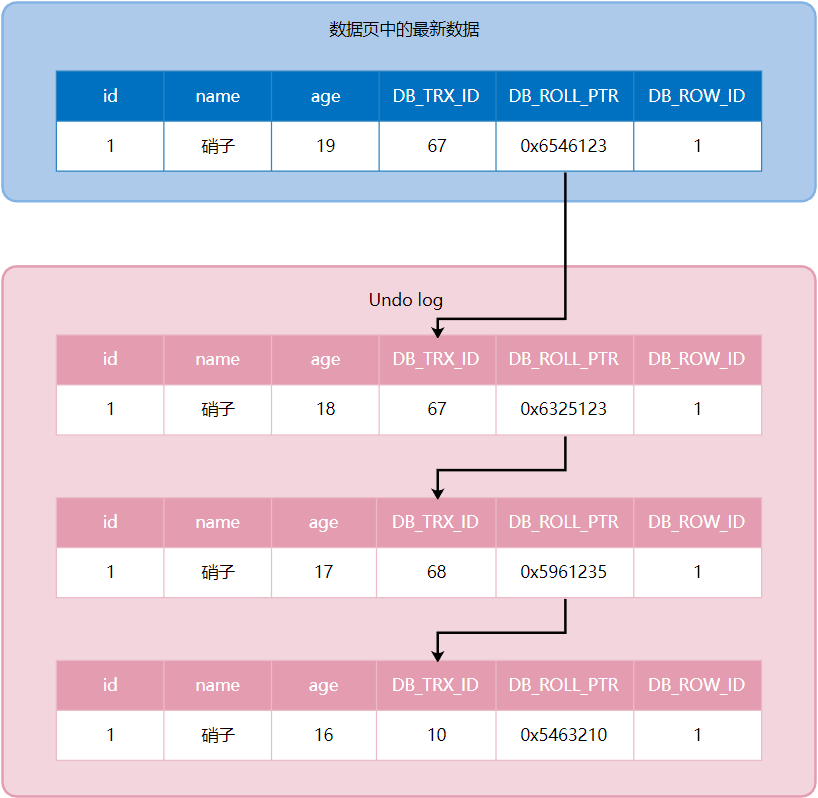
对于使用 InnoDB 存储引擎的表来说,每行记录后面会有三个隐藏字段:
DB_TRX_ID:表示最后一次修改本记录的事务 ID,占用 6 字节DB_ROLL_PTR:回滚指针,指向undo log中本记录的上一个版本,可以通过回滚指针将所有记录串成了一个版本链DB_ROW_ID:自增 ID,如果表没有定义主键或者没有列是唯一非空的,就会生成这个隐藏列,对于我们的tbl_user表不存在这个隐藏列
为了实现原子性,每当事务修改一条记录(INSERT、UPDATE 或者 DELETE)时,都会在类型为 FIL_PAGE_UNDO_LOG 的页中添加一条 undo log,之后可以通过遍历日志实现回滚操作,关于 undo log 的详细结构介绍可以参见 《第22章 后悔了怎么办-undo日志(上)》。
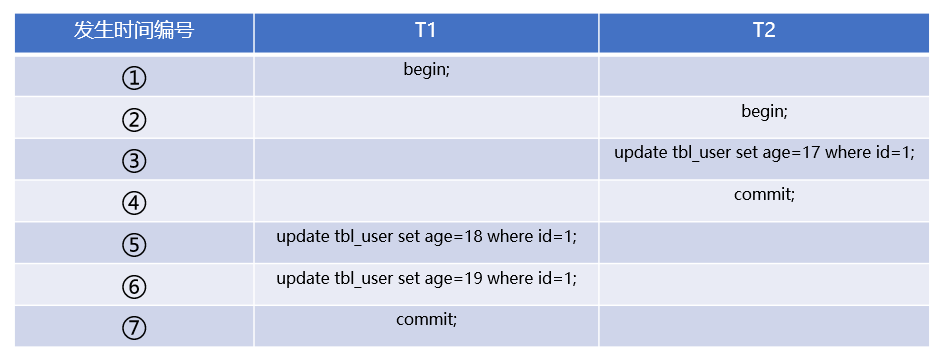
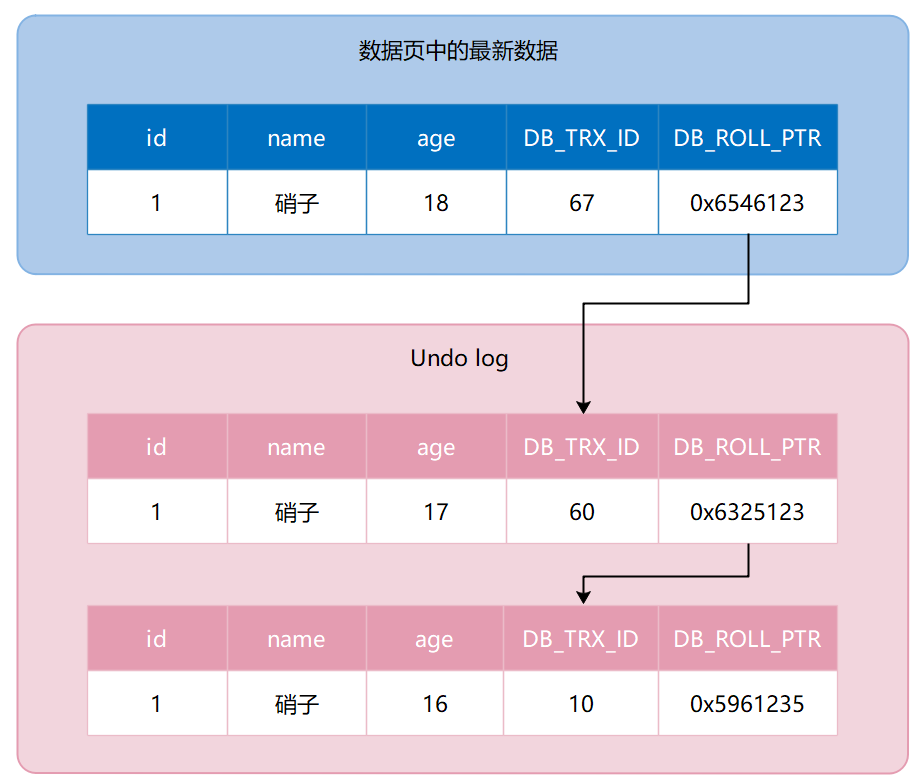
假设我们有 T1 和 T2 两个事务,事务 ID 分别为 67 和 68,执行了下述操作:
最后生成的版本链如下图所示,可以看到只要沿着版本链一直往后找,就能找到最初的记录:
Read View
前面提到过,在 READ COMMITTED 和 REPEATABLE READ 隔离级别下读不到未提交的记录,MySQL 通过 SELECT 时生成的 ReadView 快照来决定哪些记录对于当前事务可见。MySQL 8.0 中 ReadView 的代码主要结构如下所示:
/** Read view lists the trx ids of those transactions for which a consistent
read should not see the modifications to the database. */
class ReadView
{
/** This is similar to a std::vector but it is not a drop
in replacement. It is specific to ReadView. */
class ids_t
{
};
private:
/** The read should not see any transaction with trx id >= this
value. In other words, this is the "high water mark". */
trx_id_t m_low_limit_id;
/** The read should see all trx ids which are strictly
smaller (<) than this value. In other words, this is the
low water mark". */
trx_id_t m_up_limit_id;
/** trx id of creating transaction, set to TRX_ID_MAX for free
views. */
trx_id_t m_creator_trx_id;
/** Set of RW transactions that was active when this snapshot
was taken */
ids_t m_ids;
/** The view does not need to see the undo logs for transactions
whose transaction number is strictly smaller (<) than this value:
they can be removed in purge if not needed by other views */
trx_id_t m_low_limit_no;
};
可以看到 ReadView 中主要有以下几个数据成员:
m_low_limit_id:DB_TRX_ID大于等于m_low_limit_id的记录对于当前查询不可见m_up_limit_id:DB_TRX_ID小于m_up_limit_id的记录对于当前查询可见m_creator_trx_id:创建了ReadView的事务,也就是当前执行了SELECT语句的事务m_ids:创建ReadView时仍处于活跃状态的事务列表
ReadView::changes_visible 用来鉴定一个记录对于当前查询是否可见,分为以下几种情况:
- 如果
id小于m_up_limit_id,说明记录在快照创建之前就已提交,可见 - 如果
id等于m_creator_trx_id,说明这条记录被当前事务所修改,可见 - 如果
id大于等于m_low_limit_id,说明这条记录是在快照创建之后被修改的,不可见 - 如果
id在 [m_up_limit_id,m_low_limit_id) 之间,需要判断id在不在活跃事务列表中,如果在说明这条记录还没被提交则不可见,不在的话就是已被提交的记录则可见
/** Check whether the changes by id are visible.
@param[in] id transaction id to check against the view
@param[in] name table name
@return whether the view sees the modifications of id. */
[[nodiscard]] bool changes_visible(trx_id_t id, const table_name_t &name) const
{
ut_ad(id > 0);
if (id < m_up_limit_id || id == m_creator_trx_id)
{
return (true);
}
// Check whether transaction id is valid.
check_trx_id_sanity(id, name);
if (id >= m_low_limit_id)
{
return (false);
}
else if (m_ids.empty())
{
return (true);
}
const ids_t::value_type *p = m_ids.data();
return (!std::binary_search(p, p + m_ids.size(), id));
}
READ COMMITTED
在 READ COMMITTED 隔离级别下,每次 SELECT 都会创建一个新的 ReadView,所以它可以读取到所有已提交的记录。如下图所示,我们创建了三个事务 T1、T2 和 T3,他们的事务号分别为 67、60 和 70。T2 修改了硝子年龄并提交,T1 也修改了年龄但是没有提交,此时 T3 读到的年龄是 T2 修改后的版本:

根据上述过程画出版本链,根据版本链可以分析 T3 执行 SELECT 语句的过程:
- 生成
ReadView,其中m_low_limit_id为 71(这个值等于下一个待分配的事务的 ID),m_up_limit_id为 67,m_ids为[ 67, ],m_creator_trx_id为 70 - 从版本链的表头开始,第一条记录内容为
1, 硝子, 18,DB_TRX_ID为 67,位于m_ids里面,说明事务还没提交,不可见 - 第二条记录为
1 硝子 17,DB_TRX_ID为 60,小于m_up_limit_id,说明事务已提交,可见,返回该条记录
REPEATABLE READ
REPEATABLE READ 与 READ COMMITTED 本质区别在于: READ COMMITTED 每次 SELECT 都会生成一个新的 ReadView,而 REPEATABLE READ 只在事务的第一次 SELECT 时生成 ReadView,之后不会生成新的快照,所以即使 m_ids 里面的事务提交了,id 仍然保留在列表中就会被判定为不可见。
再回到上面的例子,之所以 update 之后出现了幻行,是因为被 update 的记录 DB_TRX_ID 变成了当前事务的 id,这就导致 ReadView 的 m_creator_trx_id 等于 id 使得记录可见。
后记
至此,事务的隔离级别和 MVCC 机制的实现方式已全部介绍完毕,如果想要更加深入地了解实现细节可以自行阅读 MySQL 的源代码,以上~
深入理解 MySQL 的事务隔离级别和 MVCC 机制的更多相关文章
- 一文读懂MySQL的事务隔离级别及MVCC机制
回顾前文: 一文学会MySQL的explain工具 一文读懂MySQL的索引结构及查询优化 (同时再次强调,这几篇关于MySQL的探究都是基于5.7版本,相关总结与结论不一定适用于其他版本) 就软件开 ...
- 【mysql】- 事务隔离级别和MVCC篇
概念 术语 脏写( Dirty Write ): 如果一个事务修改了另一个未提交事务修改过的数据,那就意味着发了脏写 脏读( Dirty Read ) : 如果一个事务读到了另一个未提交事务修改过的数 ...
- MySQL之事务隔离级别和MVCC
事务隔离级别 事务并发可能出现的问题 脏写 事务之间对增删改互相影响 脏读 事务之间读取其他未提交事务的数据 不可重复读 一个事务在多次执行一个select读到的数据前后不相同.因为被别的未提交事务修 ...
- MySQL之事务隔离级别--转载
转自:http://793404905.blog.51cto.com/6179428/1615550 本文通过实例展示MySQL事务的四种隔离级别. 1 概念阐述 1)Read Uncommitted ...
- 重新学习MySQL数据库8:MySQL的事务隔离级别实战
重新学习Mysql数据库8:MySQL的事务隔离级别实战 在Mysql中,事务主要有四种隔离级别,今天我们主要是通过示例来比较下,四种隔离级别实际在应用中,会出现什么样的对应现象. Read unco ...
- mysql事务之一:MySQL数据库事务隔离级别(Transaction Isolation Level)及锁的实现原理
一.数据库隔离级别 数据库隔离级别有四种,应用<高性能mysql>一书中的说明: 然后说说修改事务隔离级别的方法: 1.全局修改,修改mysql.ini配置文件,在最后加上 1 #可选参数 ...
- MySQL实战 | 03 - 谁动了我的数据:浅析MySQL的事务隔离级别
原文链接:这一次,带你搞清楚MySQL的事务隔离级别! 使用过关系型数据库的,应该都事务的概念有所了解,知道事务有 ACID 四个基本属性:原子性(Atomicity).一致性(Consistency ...
- 【MySQL】事务隔离级别及ACID
注:begin或start transaction并不是一个事务的起点,而是在执行它们之后的第一个操作InnoDB表的语句,事务才真正开始.start transaction with consist ...
- 【Java面试】请你简单说一下Mysql的事务隔离级别
一个工作了6年的粉丝,去阿里面试,在第一面的时候被问到"Mysql的事务隔离级别". 他竟然没有回答上来,一直在私信向我诉苦. 我说,你只能怪年轻时候的你,那个时候不够努力导致现在 ...
- MySQL数据库事务隔离级别(Transaction Isolation Level)
转自: http://www.cnblogs.com/zemliu/archive/2012/06/17/2552301.html 数据库隔离级别有四种,应用<高性能mysql>一书中的 ...
随机推荐
- Centos7主机安装Cockpit管理其他主机
前提条件:需要管理的每台服务器上都需要安装cockpit 假设Centos7主机安装Cockpit的为A,其他主机为B 如果B上有A的公钥,那么直接连接至B,否则,输入B的用户名密码连接. 问题:在A ...
- Elasticsearch 集群健康值红色终极解决方案
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247483905&idx=1&sn=acaff63 ...
- 分布式ID详解(5种分布式ID生成方案)
分布式架构会涉及到分布式全局唯一ID的生成,今天我就来详解分布式全局唯一ID,以及分布式全局唯一ID的实现方案@mikechen 什么是分布式系统唯一ID 在复杂分布式系统中,往往需要对大量的数据和消 ...
- C++面向对象编程之类模板、函数模板等一些补充
1.static数据 和 static函数: 对于 非static函数 在内存中只有一份,当类对象调用时,其实会有该对象的this pointer传进去,那个函数就知道要对那个对象进行操作: stat ...
- java中的自动拆装箱与缓存(Java核心技术阅读笔记)
最近在读<深入理解java核心技术>,对于里面比较重要的知识点做一个记录! 众所周知,Java是一个面向对象的语言,而java中的基本数据类型却不是面向对象的!为了解决这个问题,Java为 ...
- Pytest进阶使用
fixture 特点: 命令灵活:对于setup,teardown可以省略 数据共享:在conftest.py配置里写方法可以实现数据共享,不需要import导入,可以跨文件共享 scope的层次及神 ...
- 【算法】Tarjan
参考资料: 图论相关概念 - OI WIKI | 强连通分量 - OI WIKI 初探tarjan算法 | Tarjan,你真的了解吗 一.概念 • 子图: 对一张图 \(G=(V,E)\),若存在另 ...
- 前端框架Vue------>第一天学习(2) v-if
API:https://cn.vuejs.org/v2/api/#key 文章目录 5.条件渲染 5.1 . v-if 5.2 . v-else-if 6 .列表渲染 7 .事件监听 5.条件渲染 5 ...
- git-secret:在 Git 存储库中加密和存储密钥(下)
在之前的文章中(点击此处查看上一篇文章),我们了解了如何识别包含密钥的文件,将密钥添加到 .gitignore ,通过 git-secret 进行加密,以及将加密文件提交到存储库.在本篇文章中,将带你 ...
- vue2 解决跨域
vue2.x 解决跨域 通过devServer将接口代理到本地在开发的时候,需要请求同局域网内的接口,发现直接使用http://对方的ip地址/接口路径,会出现类似下图的跨域报错 找到并打开vue.c ...